爬虫(15) - Scrapy-Redis分布式爬虫(2) | 实例:分布式爬虫项目
项目背景
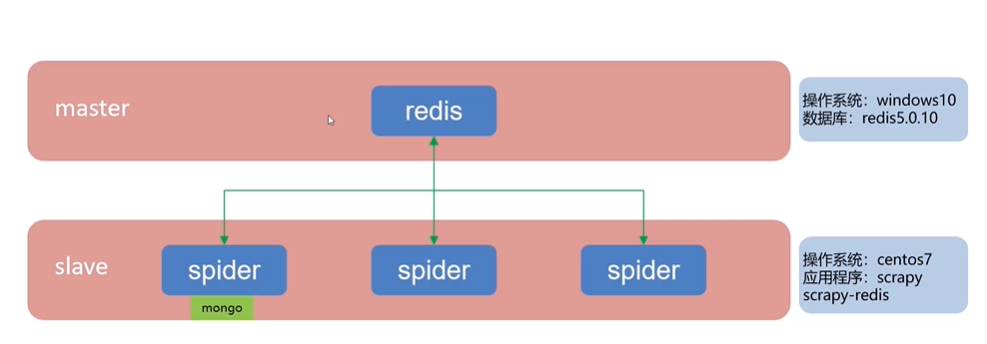
- master:是控制节点,负责管理所有的slave,进行任务调度、分发、维护爬取队列进行去重,以及新任务的添加;部署在win10上面,安装的数据库为redis5.0
- slavr:爬虫端,从master领取任务,并且去完成爬虫任务。具体为数据的抓取、数据的处理、内容的解析以及内容的存储等;部署在centos7上面,应用程序为scrapy和scrapy-redis,安装mongo
- 项目选择:将之前笔记中https://www.cnblogs.com/gltou/p/16423938.html瓜子二手车的项目改造成分布式爬虫项目
爬虫项目改造
我的slave是直接装在物理机器上的,没有用虚机,用虚机的话网络转发的还要配置下,这个就自行百度吧
step-1:项目code改动
settings.py:修改slave端安装的mongo相关配置信息,添加master主机安装redis的相关配置信息;如果设置了密码将相关注释去掉,填写相关数据
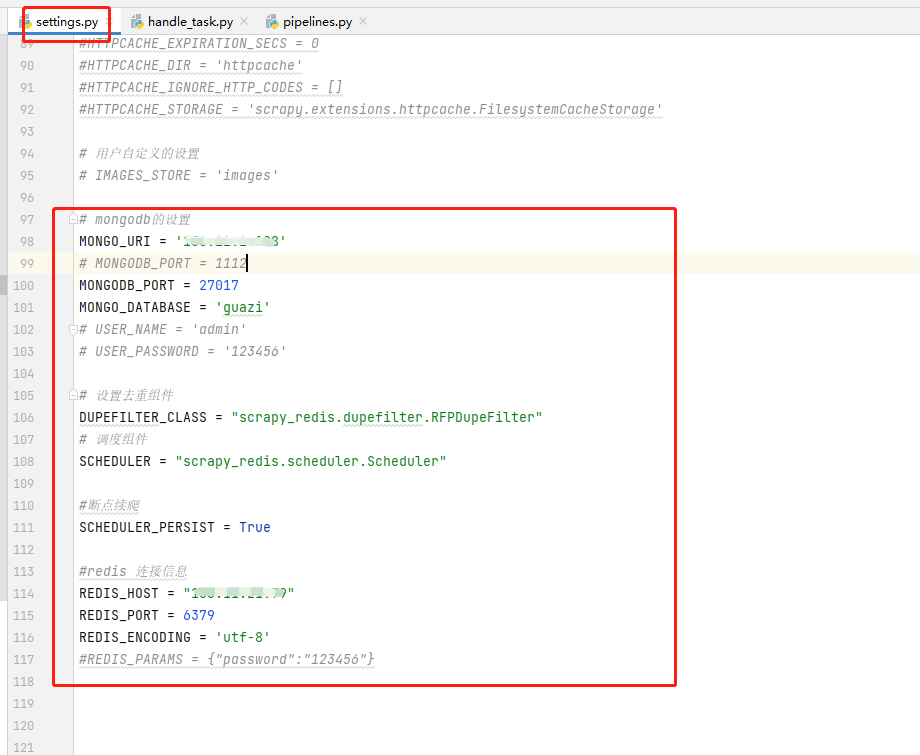

1 # mongodb的设置 2 MONGO_URI = '安装mongo的slave地址' 3 # MONGODB_PORT = 1112 4 MONGODB_PORT = 27017 5 MONGO_DATABASE = 'guazi' 6 # USER_NAME = 'admin' 7 # USER_PASSWORD = '123456' 8 9 # 设置去重组件 10 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" 11 # 调度组件 12 SCHEDULER = "scrapy_redis.scheduler.Scheduler" 13 14 #断点续爬 15 SCHEDULER_PERSIST = True 16 17 #redis 连接信息 18 REDIS_HOST = "安装redis的master地址" 19 REDIS_PORT = 6379 20 REDIS_ENCODING = 'utf-8' 21 #REDIS_PARAMS = {"password":"123456"}
guazi.py:导入 scrapy_redis 的 RedisSpider 类,并继承;注释掉 allowed_domains 和 start_urls ;添加 redis_key ,值为 guazi:start_urls ;删除start_requests方法,因为start_urls已经从redis获取了,并且我们只爬取一页,因此删除了start_requests方法
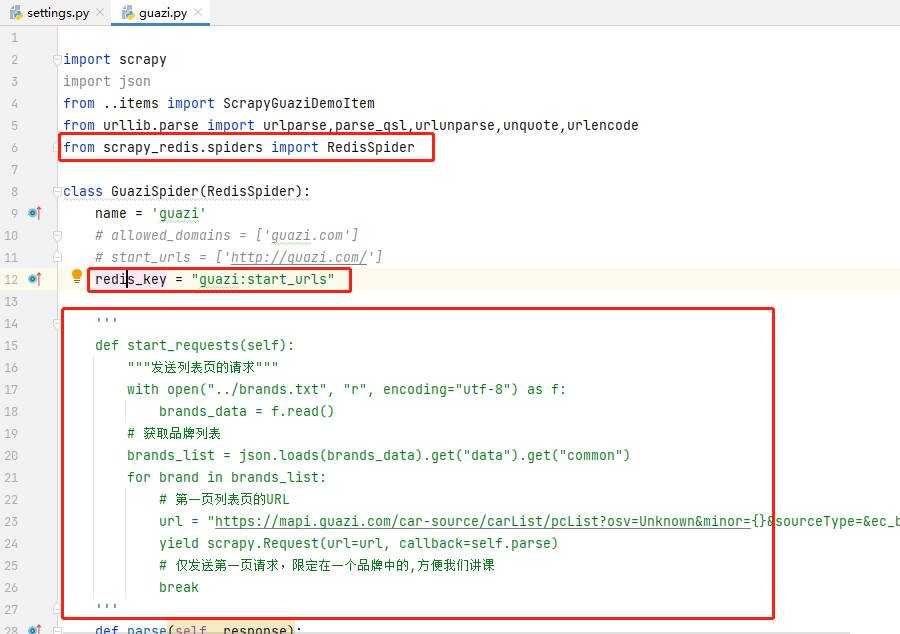
1 import scrapy 2 import json 3 from ..items import ScrapyGuaziDemoItem 4 from urllib.parse import urlparse,parse_qsl,urlunparse,unquote,urlencode 5 from scrapy_redis.spiders import RedisSpider 6 7 class GuaziSpider(RedisSpider): 8 name = 'guazi' 9 # allowed_domains = ['guazi.com'] 10 # start_urls = ['http://guazi.com/'] 11 redis_key = "guazi:start_urls" 12 13 ''' 14 def start_requests(self): 15 """发送列表页的请求""" 16 with open("../brands.txt", "r", encoding="utf-8") as f: 17 brands_data = f.read() 18 # 获取品牌列表 19 brands_list = json.loads(brands_data).get("data").get("common") 20 for brand in brands_list: 21 # 第一页列表页的URL 22 url = "https://mapi.guazi.com/car-source/carList/pcList?osv=Unknown&minor={}&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=&tag=-1&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=&emission=&car_color=&guobie=&bright_spot_config=&seat=&fuel_type=&order=7&priceRange=0,-1&tag_types=&diff_city=&intention_options=&initialPriceRange=&monthlyPriceRange=&transfer_num=&car_year=&carid_qigangshu=&carid_jinqixingshi=&cheliangjibie=&page=1&pageSize=20&city_filter=12&city=12&guazi_city=12&qpres=544352372349644800&platfromSource=wap&versionId=0.0.0.0&sourceFrom=wap&deviceId=c5f33bc0-08a6-438e-ae41-dcb6d88c2d2d".format(brand.get("value")) 23 yield scrapy.Request(url=url, callback=self.parse) 24 # 仅发送第一页请求,限定在一个品牌中的,方便我们讲课 25 break 26 ''' 27 def parse(self, response): 28 """第一页列表页请求的返回""" 29 data = response.json().get("data") 30 # 列表中每一条二手车的数据 31 guazi_items = data.get("postList") 32 for item in guazi_items: 33 detail_url="https://www.guazi.com/Detail?clueId={}".format(item.get("clue_id")) 34 yield scrapy.Request(url=detail_url,callback=self.parse_detail) 35 # break 36 # 当前页码 37 now_page=data.get("page") 38 # 总页码 39 total_page=data.get("totalPage") 40 # 判断是否超过一页 41 if total_page>1 and now_page ==1 : 42 # 从第二页开始发起请求 43 for page in range(2,total_page+1): 44 # 获取第一页的url 45 url=response.url 46 # 构造下一页 47 params={"page":str(page)} 48 # 解析url,使用urlparse返回了六个部分 49 url_parts=list(urlparse(url)) 50 # 通过parse_qsl转换为列表,keep_blank_values保留空字段 51 query=dict(parse_qsl(url_parts[4],keep_blank_values=True))#keep_blank_values=True:空值默认保留 52 # 更新页码 53 query.update(params) 54 # encode更新页码之后的url,放到了解析好的url第四个索引中 55 url_parts[4] = urlencode(query) 56 # 解码 57 page_url=unquote(urlunparse(url_parts)) 58 yield scrapy.Request(url=page_url,callback=self.parse) 59 60 def parse_detail(self,response): 61 guazi_info=ScrapyGuaziDemoItem() 62 # 车源号 63 guazi_info['car_id'] = response.xpath("//div[@class='right-carnumber']/text()").extract_first().strip() 64 # 车名字 65 guazi_info['car_name'] = response.xpath("//h1[@class='titlebox']/text()").extract_first().strip() 66 # 排量 67 guazi_info['displacement'] = response.xpath("//span[@class='assort-common']/text()").extract_first() 68 # 变速箱 69 guazi_info['transmission'] = response.xpath("//li[@class='assort-last']/span/text()").extract_first() 70 # 价格 71 guazi_info['price'] = response.xpath("//span[@class='price-num gzfont']/text()").extract_first() 72 yield guazi_info
step-2:上传爬虫项目到Linux环境
在linux用户家目录下创建scrapy_redis_test目录,将项目上传并解压到该目录;如果有多个slave机器,重复执行上述操作
step-3:分布式爬虫项目执行
slave环境安装
1)salve上安装virtualenv虚拟环境,保证服务器干净,详细以及相关命令自行转:https://www.cnblogs.com/gltou/p/15980665.html;不要嫌麻烦,实际项目都得在虚拟环境里面执行脚本!!!

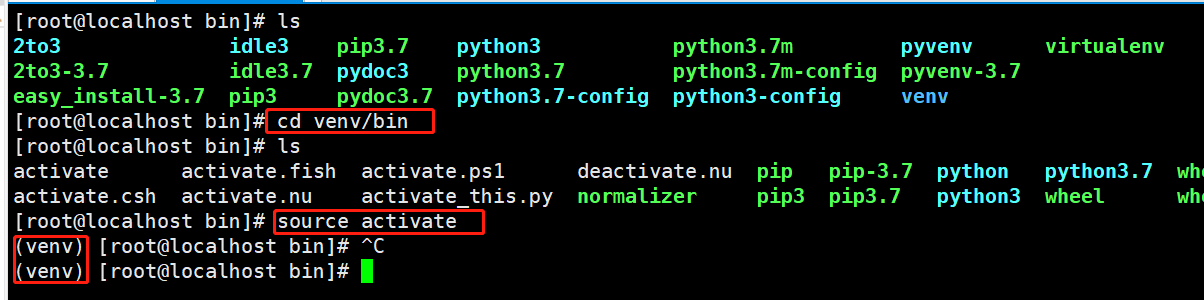
2)进入虚拟环境
cd venv/bin source activate #进入venv虚拟环境
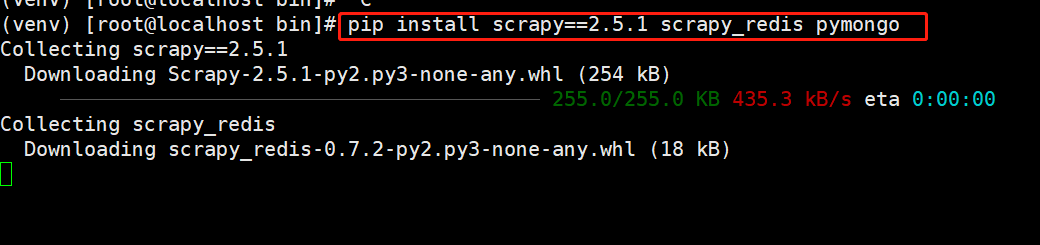
3)安装scrapy、scrapy_redis、pymongo;注意scrapy安装2.5.1版本,稳定不容易报错
pip install scrapy==2.5.1 scrapy_redis pymongo
注意:安装过程中可能会安装报错,那是由于网络原因导致的,重复执行pip install直至安装成功
master种子url注入
1)新建handle_task.py文件,用于master给salve下发种子url用的
1 import redis 2 import json 3 4 r=redis.Redis(host='127.0.0.1',port=6379,db=0) 5 6 with open("brands.txt", "r", encoding="utf-8") as f: 7 brands_data = f.read() 8 # 获取品牌列表 9 brands_list = json.loads(brands_data).get("data").get("common") 10 for brand in brands_list: 11 # 第一页列表页的URL 12 url = "https://mapi.guazi.com/car-source/carList/pcList?osv=Unknown&minor={}&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=&tag=-1&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=&emission=&car_color=&guobie=&bright_spot_config=&seat=&fuel_type=&order=7&priceRange=0,-1&tag_types=&diff_city=&intention_options=&initialPriceRange=&monthlyPriceRange=&transfer_num=&car_year=&carid_qigangshu=&carid_jinqixingshi=&cheliangjibie=&page=1&pageSize=20&city_filter=12&city=12&guazi_city=12&qpres=544352372349644800&platfromSource=wap&versionId=0.0.0.0&sourceFrom=wap&deviceId=c5f33bc0-08a6-438e-ae41-dcb6d88c2d2d".format( 13 brand.get("value")) 14 r.lpush("guazi:start_urls",url)
2)执行handle_task.py脚本,进入redis查看,发现种子url已经全部入库
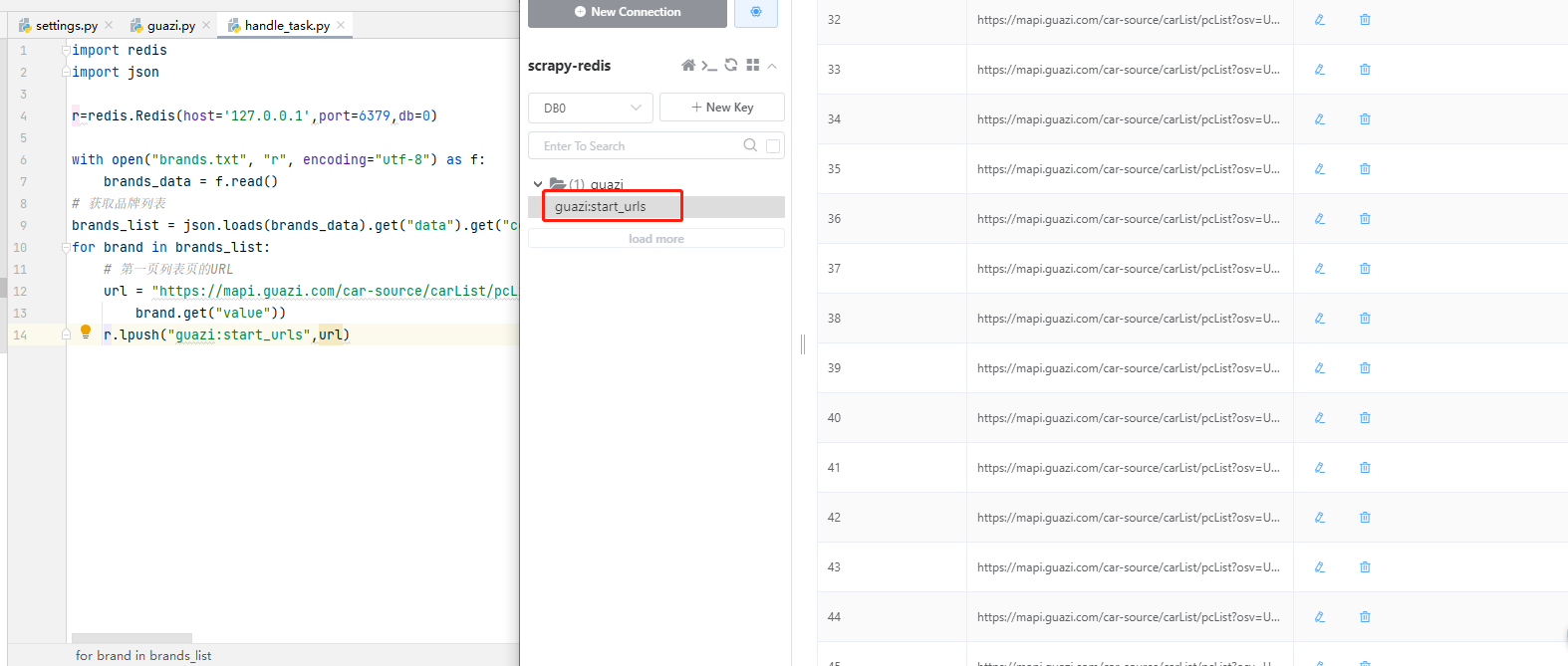
slave执行爬虫
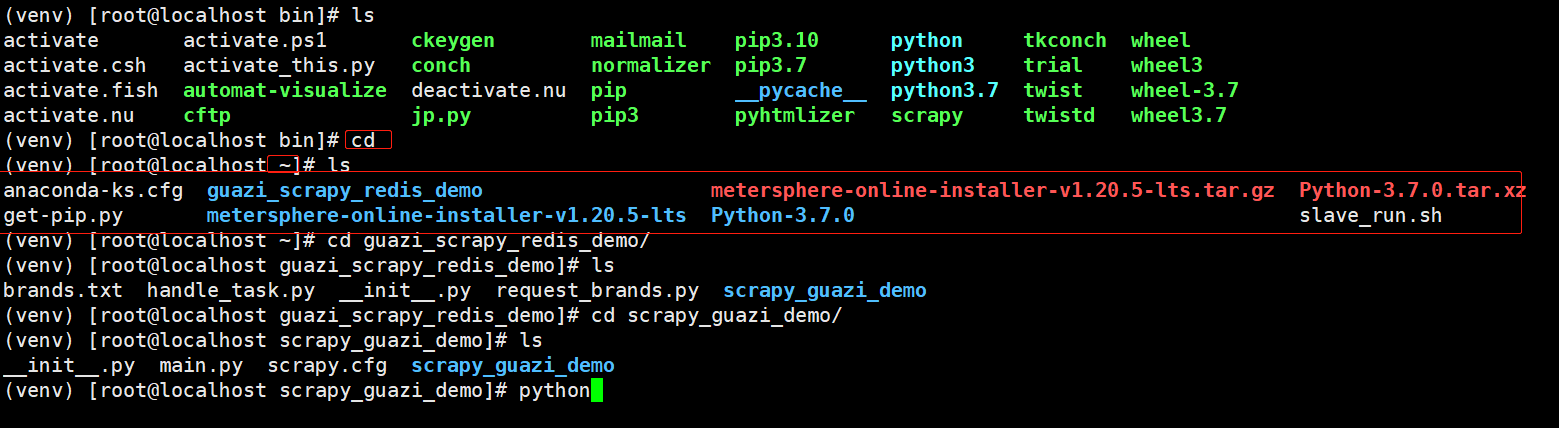
1)slave运行爬虫
前置了解:有一个点啊,爬虫项目我们是放在了用户家目录下,即/root/目录下;虚拟环境是装在了/usr/local/python3/bin/venv目录,我们是在 /usr/local/python3/bin/venv/bin目录下执行 source activate 命令进入虚拟环境。虚拟环境下cd是回到家目录下,虽然在虚拟环境里面,但是访问的目录是和在外面没有任何区别的(不管是家目录还是什么,都是一样的)
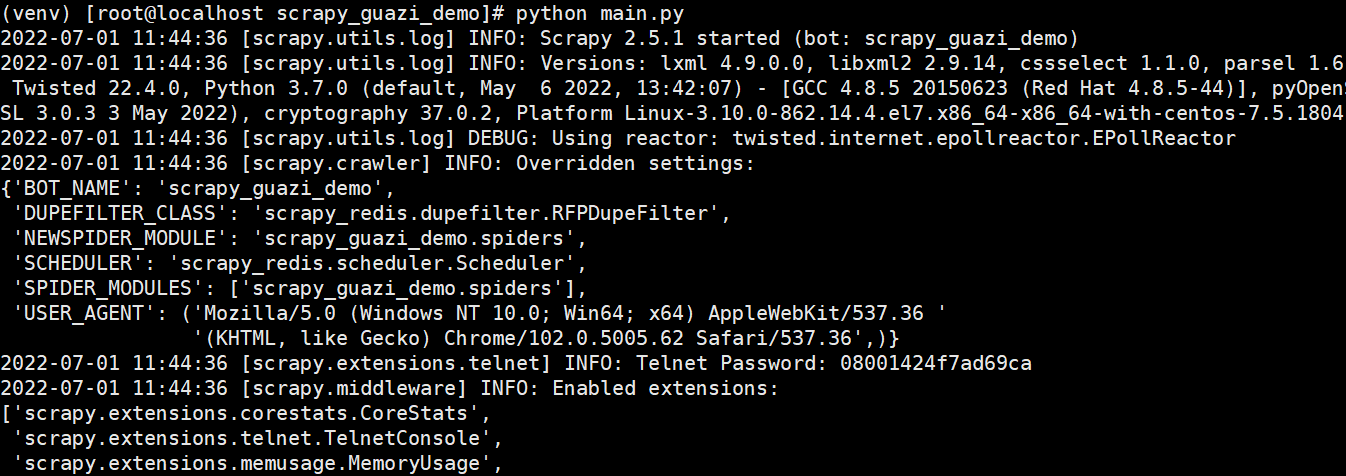
虚拟环境下,进入项目目录 cd /root/guazi_scrapy_redis_demo/scrapy_guazi_demo ,运行爬虫入口文件 python main.py

报错了:redis连接超时redis.exceptions.ConnectionError: Error:Timeout connecting to server
运行脚本,报错了,不要慌,慢慢排查问题,根据报错信息提示,首先确认代码是没有问题的;那么肯定是我环境出来问题。知道问题点了,就开始慢慢排查。
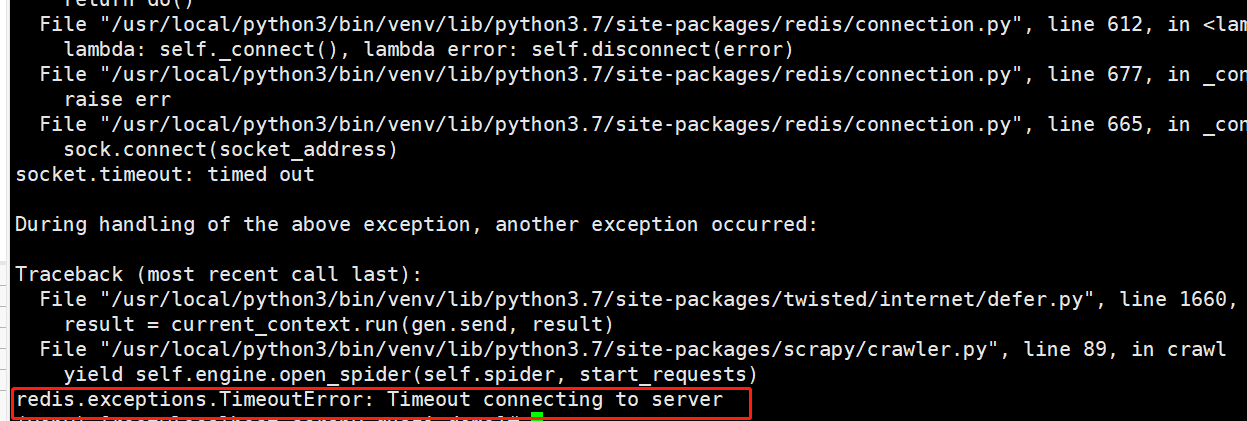
slave报错了,那master执行这个脚本会不会报错,哎,还真报错了。报错信息还不一样:redis.exceptions.ConnectionError: Error 10061 connecting to IP:6379. 由于目标计算机积极拒绝,无法连接。

报错信息很明确,计算机积极拒绝,说明就是master电脑哪边配置出了问题。排查过程就不再赘述了,总结两个问题:
- 问题一:master机器可以ping通slave机器,但是slave不能ping通master,这个排查过程比较长,花费不少时间
- 解决方案:我单独都抽出来写了,因为网上反映这个问题的人比较多,没有完善的解决方案,自行跳转:
- 问题二:redis的配置没有配置好
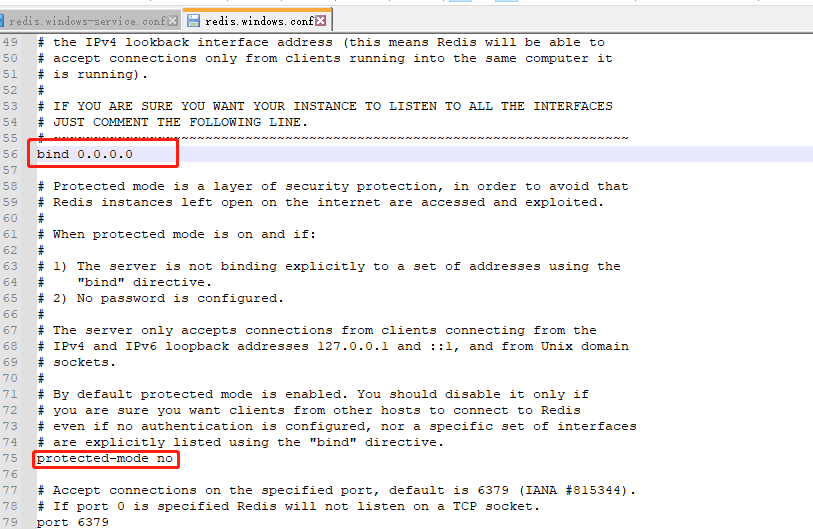
- 解决方案:redis.windows.conf和redis.windows-service.conf这两个文件中将 bind 的值改为0.0.0.0,注意可能不止一个,保留一个即可,其他的注释掉; protected-mode 的值改为no
- 解决方案:redis.windows.conf和redis.windows-service.conf这两个文件中将 bind 的值改为0.0.0.0,注意可能不止一个,保留一个即可,其他的注释掉; protected-mode 的值改为no
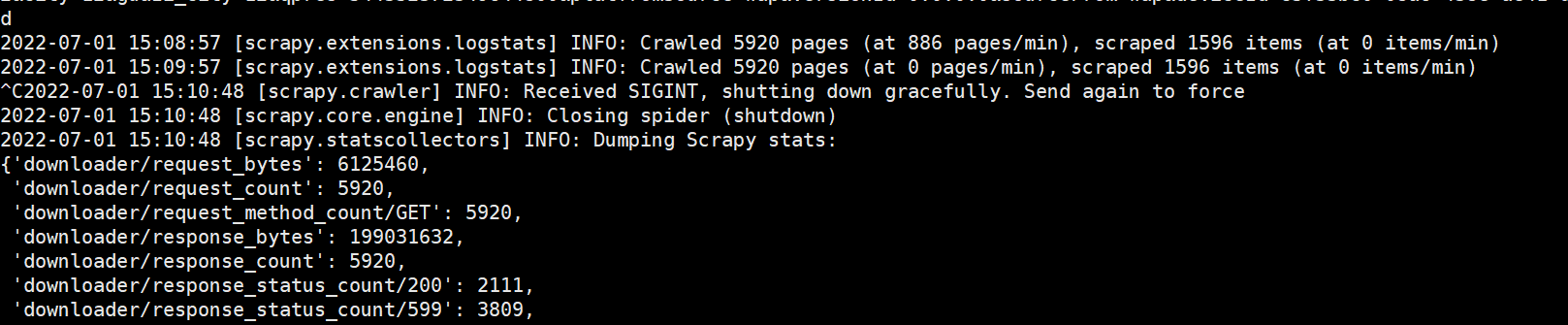
2)slave再次运行爬虫,成功了
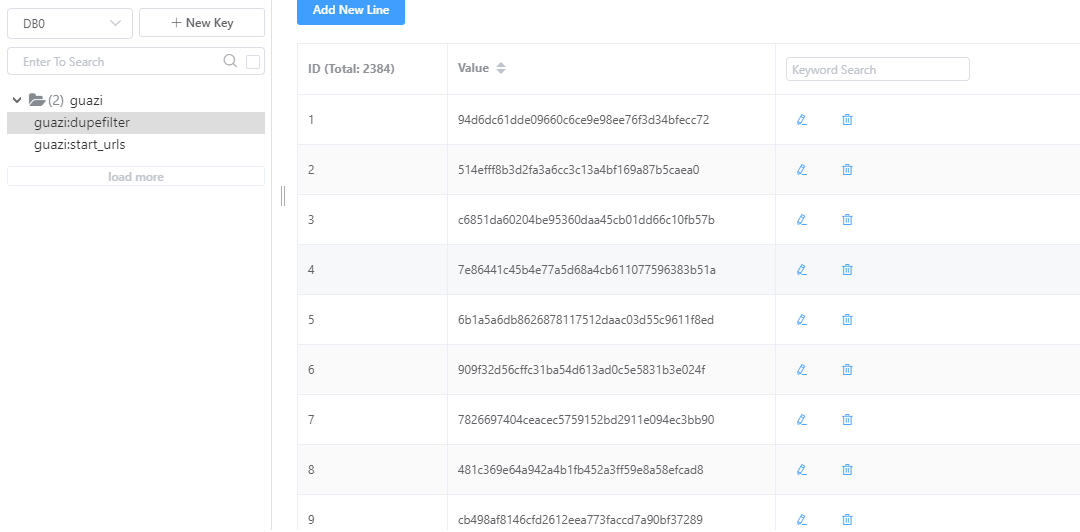
3)查看数据
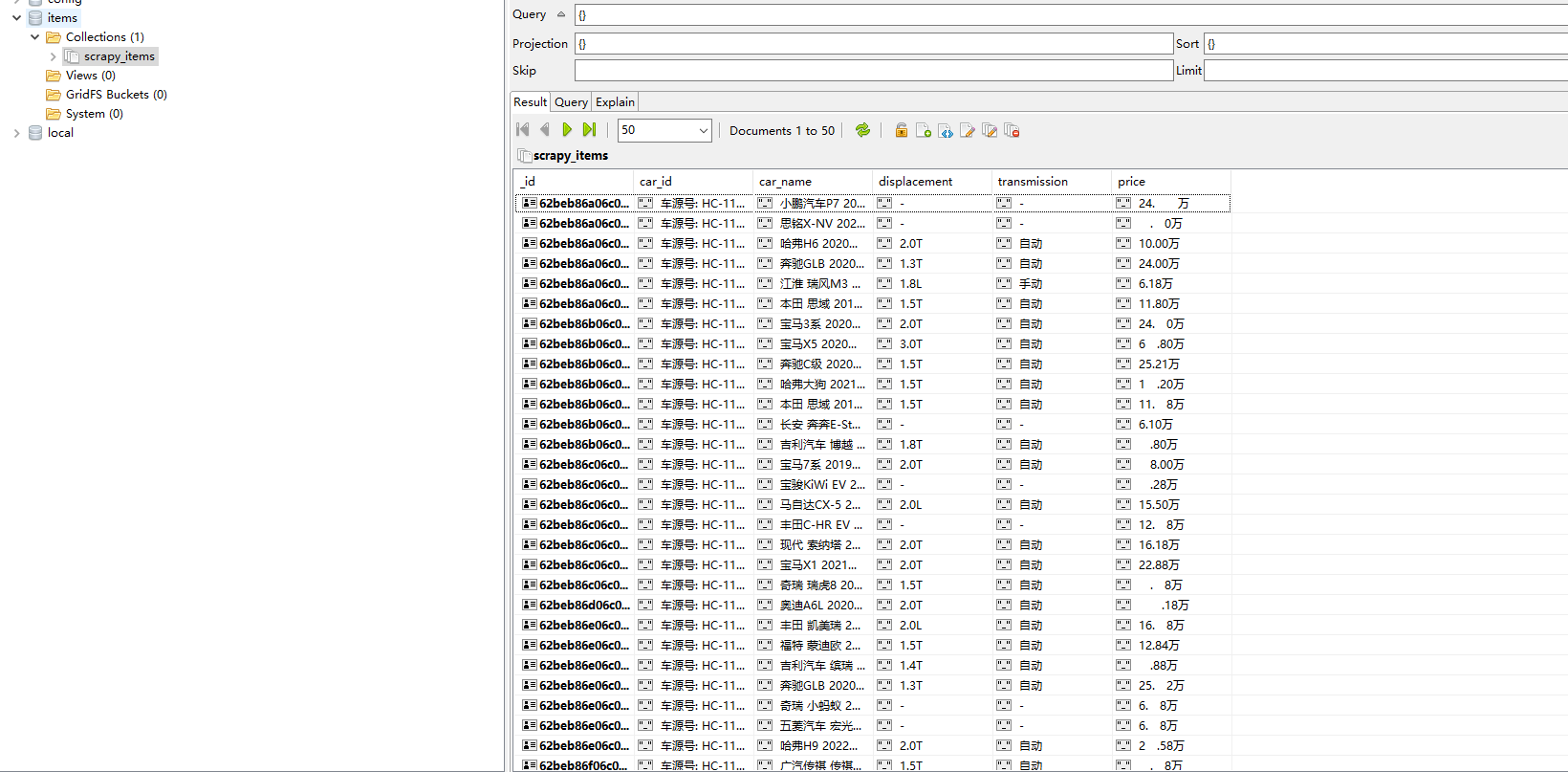
4)该项目的运行顺序整理下,便于后期自己回头看:执行handle_task.py文件,将种子url传入redis👉slave进入虚拟环境,执行爬虫入口脚本main.py,爬取结束,按Ctrl+C结束进程👉通过mongo客户端连接安装在slave上面的mongo数据库,查看抓取到的数据。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步