爬虫(11) - Scrapy框架(3) | 示例项目抓取并下载网站图片
前置:是接着该篇随笔https://www.cnblogs.com/gltou/p/16400449.html继续完善功能。该篇随笔增加了示例项目下载网站图片的功能
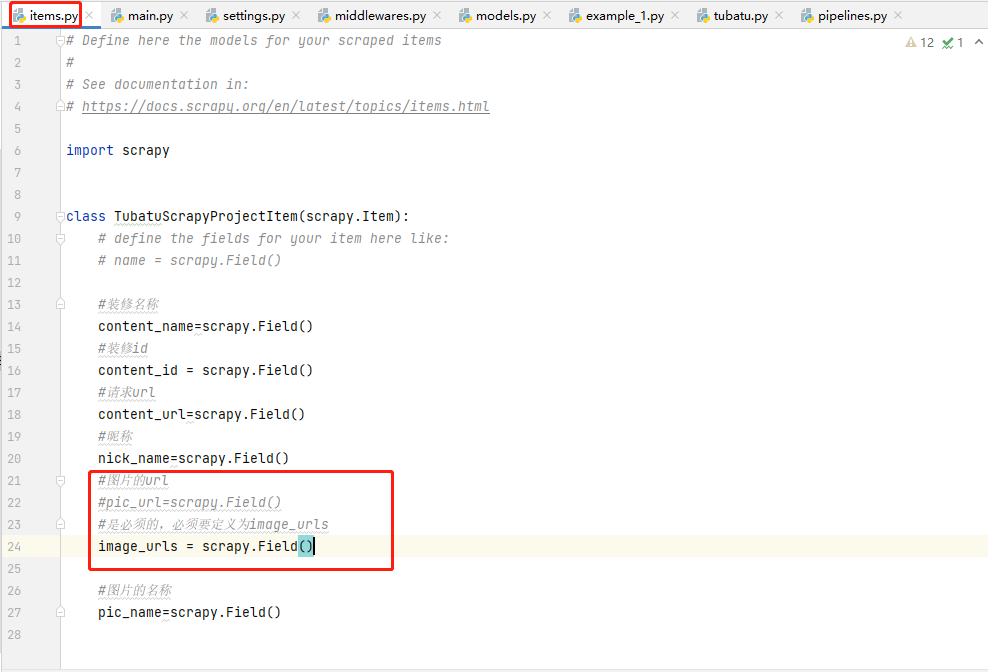
items.py
将原先的图片url变量 pic_url 注释掉,新增图片url变量 image_urls 。注意变量名必须得是这个,scrapy框架中规范好的
image_urls = scrapy.Field()
piplines.py
自定义图片下载类,自定义的下载类需要继承 ImagesPipeline 类;同时引用 DropItem ,自定义抛出异常;下载的路径 IMAGES_STORE 从settings.py文件中获取
1 from scrapy.pipelines.images import ImagesPipeline 2 from scrapy.exceptions import DropItem 3 4 #自定义的图片下载类需要继承于ImagesPipeline 5 class TubatuImagePipline(ImagesPipeline): 6 # def get_media_requests(self, item, info): 7 # #根据image_urls中指定的URL进行爬取 8 # pass 9 10 def item_completed(self, results, item, info): 11 #图片下载完毕后,处理结果的,返回是一个二元组 12 #(success,image_info_or_failure) 13 image_path = [x['path'] for ok,x in results if ok] 14 if not image_path: 15 raise DropItem('Item contains no images') 16 return item 17 18 def file_path(self, request, response=None, info=None, *, item=None): 19 #用于给下载的图片设置文件名称 20 url = request.url 21 file_name = url.split('/')[-1] 22 #aaa.jpg 23 return file_name
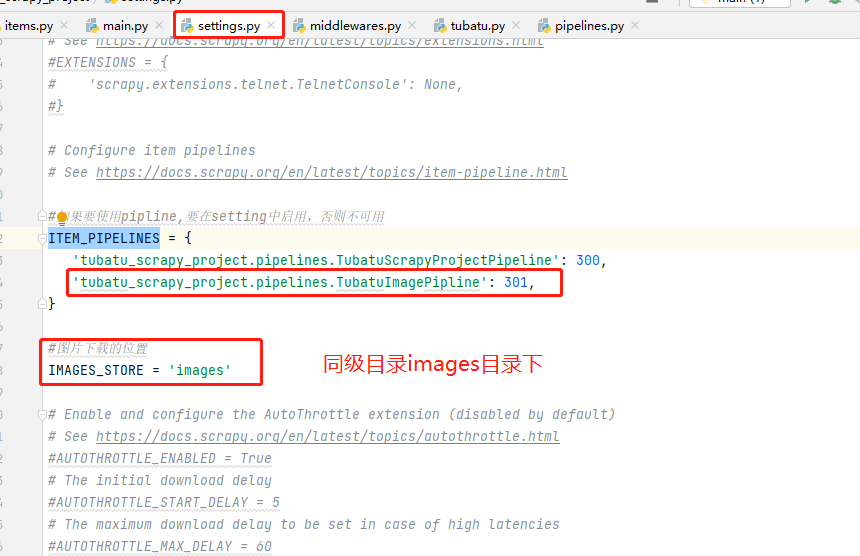
settings.py
定义图片下载位置 IMAGES_STORE 的路径;并且将piplines.py中自定义的下载类,在 ITEM_PIPELINES 中添加启用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号