Python基础入门(5)- 函数的定义与使用
定义函数
- 函数的定义
- 函数的分类
- 函数的创建方法
- 函数的返回return
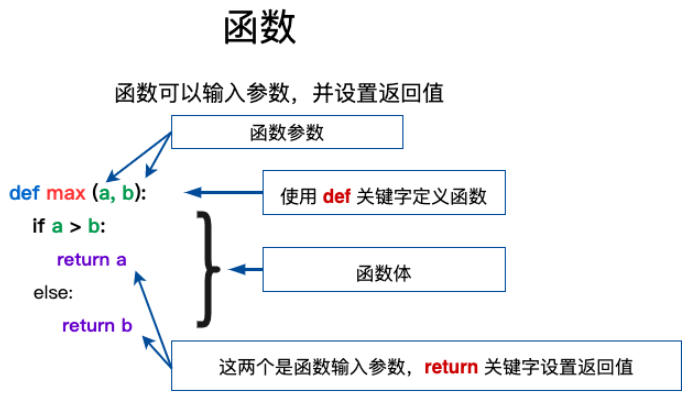
函数的定义
- 将一件事情的步骤封装在一起并得到最终结果
- 函数名代表了这个函数要做的事情
- 函数体是实现函数功能的流程
- 函数可以帮助我们重复使用功能,通过函数名我们可以知道函数的作用
函数的分类
- 内置函数:print、id、int、max、min、type....等
- 自定义函数:def 创建函数
函数的创建方法
通过关键字def来创建函数,def的作用是实现python中函数的创建
函数定义过程:
def 函数名(参数列表): 函数体# coding:utf-8 def say_Hello(): print("Hello Python")函数的调用
函数名+()小括号执行函数
# coding:utf-8 # 定义函数 def say_Hello(): print("Hello Python") # 执行函数 say_Hello() # 执行结果:Hello Python
函数的返回return
- return-将函数结果返回的关键字
- return只能在函数体内使用
- return支持返回所有的python类型
- 有返回值的函数可以赋值给一个变量
- return也有退出函数的作用
# coding:utf-8 def add(a,b): c=a+b return c result=add(1,2) print(result) # 输出结果:3
函数的参数
- 必传参数
- 默认参数
- 不确定参数
- 参数规则
必传参数
- 函数中定义的参数没有默认值,在调用函数时如果不传入则会报错
- 在定义函数的时候,参数后边没有等号与默认值
- 在定义函数的时候,没有默认值且必须在函数执行的时候传递进去的参数,且顺序与参数的顺序相同,就是必传参数
# coding:utf-8 def add(a,b): c=a+b return c result=add(1,2) print(result) # 输出结果:3
默认参数
- 在定义函数的时候,定义的参数含有默认值,通过赋值语句给他是一个默认值
- 如果默认参数在调用函数的时候传递了新的值,函数将会优先使用后传入的值进行工作
# coding:utf-8 def add(a,b=1): c=a+b return c print(add(1)) # 输出结果:2 print(add(1,3)) # 输出结果:4
不确定参数-可变参数
- 没有固定的参数名和数量(不知道要传的参数名具体是什么)
- *args代表:将无参数的值合并成元组
- **kwargs代表:将有参数与默认值的赋值语句合并成字典
# coding:utf-8 def test_args(*args,**kwargs): print(args,type(args)) print(kwargs,type(kwargs)) test_args(1,2,3,4,5,6,name="zhangsan",age=22,top=175) # 输出结果: # (1, 2, 3, 4, 5, 6) <class 'tuple'> # {'name': 'zhangsan', 'age': 22, 'top': 175} <class 'dict'># coding:utf-8 #参数是变量传递时,需要在变量前面加上*和**来区分传递的是元组还是字典,否则一律按元组*args处理 def test_args(*args,**kwargs): print(args,type(args)) print(kwargs,type(kwargs)) a=('python','java') b={"name":"zhangsan","age":22,"top":175} test_args(a,b) # 输出结果: # (('python', 'java'), {'name': 'zhangsan', 'age': 22, 'top': 175}) <class 'tuple'> # {} <class 'dict'> test_args(*a,**b) # 输出结果: # ('python', 'java') <class 'tuple'> # {'name': 'zhangsan', 'age': 22, 'top': 175} <class 'dict'>
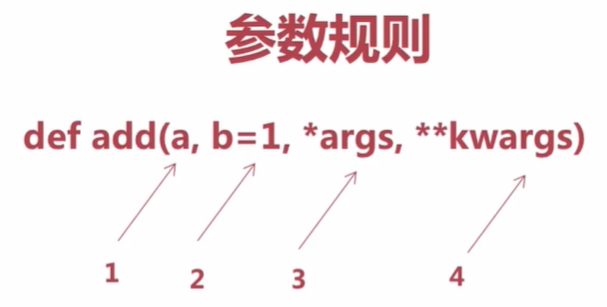
参数规则
- 参数的定义从左到右依次是:必传参数、默认参数、可变元组参数、可变字典参数
- 函数的参数传递非常灵活
- 必传参数与默认参数的传参多样化
- 传递的参数与函数定义时的参数顺序不一致时,使用赋值语句的方式传参
# coding:utf-8 def test(a,b=1,*args): print(a,b,args) s=(1,2) test(1,2,*s) #1 2 (1, 2) # test(a=1,b=2,*s) ''' Traceback (most recent call last): File "D:/WorkSpace/Python_Study/test01.py", line 8, in <module> test(a=1,b=2,*s) TypeError: test() got multiple values for argument 'a' ''' # 报错原因:当我们必选参数、默认参数与可选的元组类型参数在一起的时候,如果需要采取赋值的形式传参,则在定义函数的时候需要将可变的元组参数放在第一位,之后是必传、默认参数;这是一个特例!!! def test2(*args,a,b=1): print(a,b,args) test2(a=1,b=2,*s) #1 2 (1, 2)# coding:utf-8 def test(a,b=1,**kwargs): print(a,b,kwargs) test(1,2,name="zhangsan") # 1 2 {'name': 'zhangsan'} test(a=1,b=2,name="zhangsan") # 1 2 {'name': 'zhangsan'} test(name="zhangsan",age=33,b=2,a=1) # 1 2 {'name': 'zhangsan', 'age': 33}

函数的参数类型
- 参数类型的定义在python3.7之后可用
- 函数不会对参数类型进行验证,只是看的作用
- 函数的参数类型具体是什么,还得看方法中对参数的操作
# coding:utf-8 def test(a:int,b:int=3,*args:int,**kwargs:str): print(a,b,args,kwargs) test(1,2,3,'4',name='zhangsan') # 1 2 (3, '4') {'name': 'zhangsan'}

全局变量与局部变量
- 全局变量
- 局部变量
- global
全局变量
函数体内对全局变量只能读取,不能修改
# coding:utf-8 name="张三" age=22 def test(): name="李四" print(name) print(age) test() #李四 22 print(name) #张三
局部变量
局部变量,无法在函数体外使用
# coding:utf-8 def test(): name="李四" print(name) #报错
global
- 将全局变量可以在函数体内进行修改
- global只支持str,int,float,tuple,bool,None类型。
- 对于list,dict不需要global声明即可应用自带方法在函数体内修改。
- 不建议使用global对全局变量进行修改
# coding:utf-8 name="张三" age=22 source={"数学":"100","英语":99,"语文":80} like=["足球","篮球","乒乓球"] drink=("雪碧","可乐") eat={"汉堡","薯条"} def test(): global name,age name="zhangsan" age=18 source["英语"]=60 like[2]="羽毛球" # drink[0]="百事" 元组不可变,报错 eat.update("鸡翅") test() print("%s,%s,%s,%s,%s,%s"%(name,age,source,like,drink,eat)) # 输出结果:zhangsan,18,{'数学': '100', '英语': 60, '语文': 80},['足球', '篮球', '羽毛球'],('雪碧', '可乐'),{'薯条', '翅', '汉堡', '鸡'}


递归函数
- 递归是一种常见的数学和编程概念。它意味着函数调用自身。这样做的好处是可以循环访问数据以达成结果,类似while和for循环
- 通过return返回def()自身,即可实现递归效果
# coding:utf-8 count=0 def test(): global count if count<=5: count +=1 return test() else: print("当前计数为:{}".format(count)) test() # 输出结果为:当前计数为:6
匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- 自带return
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
# coding:utf-8 f=lambda x,y:x+y print(f(1,2)) #3 user=[{"name":"zhangsan"}, {"name":"lisi"}, {"name":"wangwu"}] user.sort(key=lambda x:x["name"]) print(user) #[{'name': 'lisi'}, {'name': 'wangwu'}, {'name': 'zhangsan'}]


