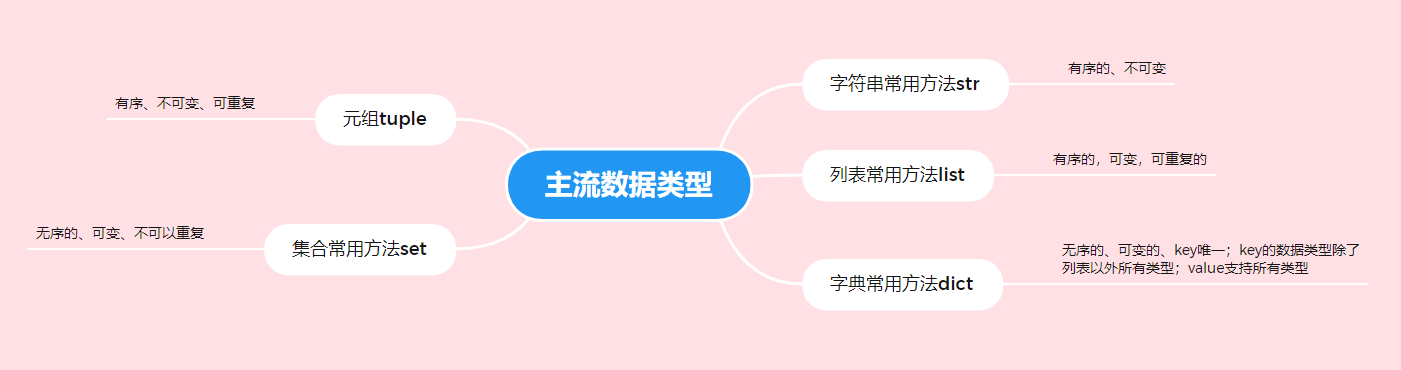
Python基础入门(3)- 主流数据类型常用方法
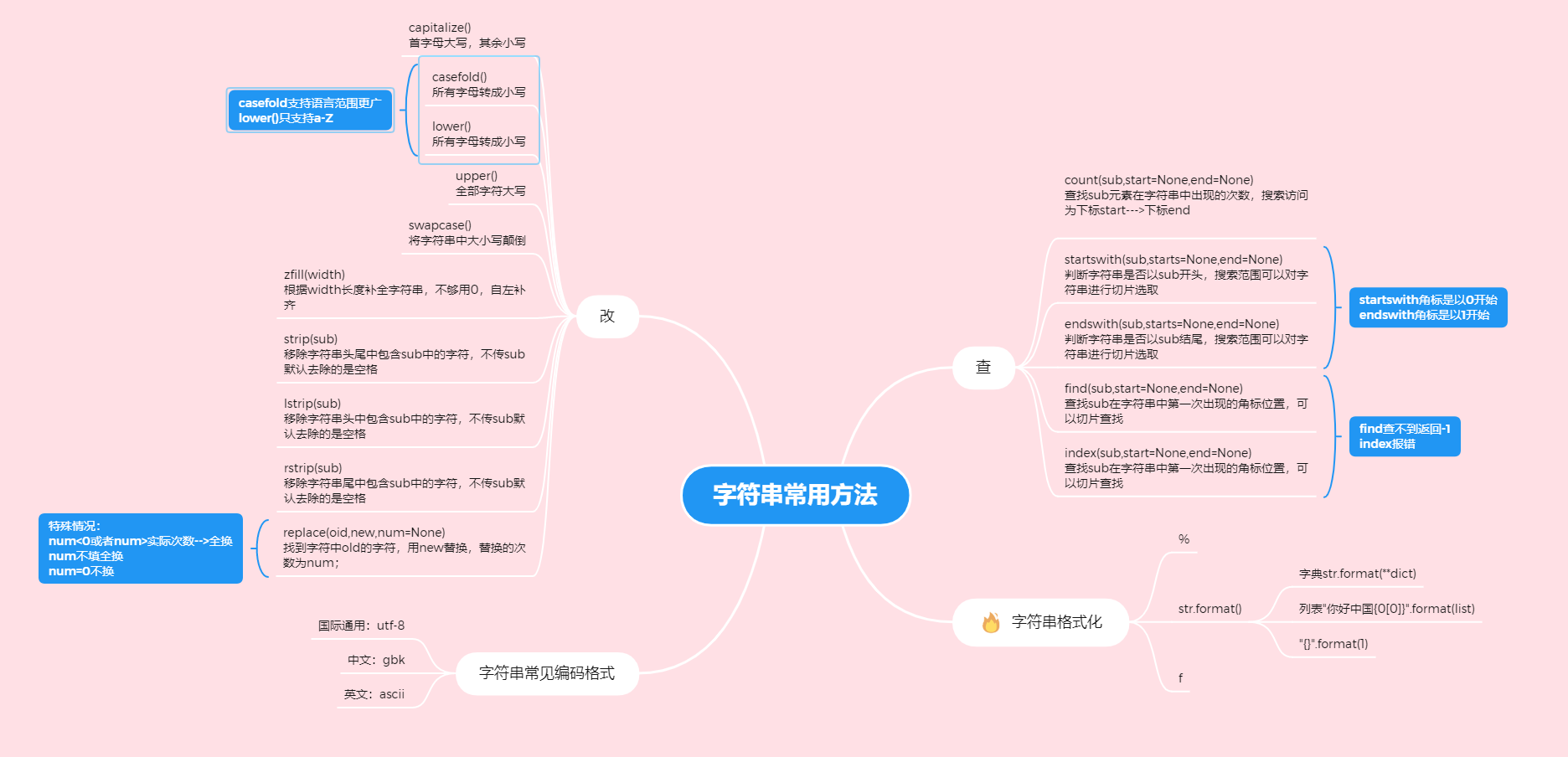
字符串常用方法
capitalize()
- 描述:capitalize()将字符串的第一个字母变成大写,其他字母变小写。
- 语法: str.capitalize()
- 参数:无
- 返回值:该方法返回一个首字母大写的字符串。
- 实例
#!/usr/bin/python3 str = "this is string....!!!" print ("str.capitalize() : ", str.capitalize()) #输出结果:str.capitalize() : This is string....!!!
- 注意事项
- 首字符会转换成大写,其余字符会转换成小写。
str='hello PYTHON'
#输出结果:Hello python
- 首字符如果是非字母,首字母不会转换成大写,其他会转换成小写。
str='# Hello PYTHON' #输出结果:# hello python
- 首字母已经是大写,首字母不变,其他字母转换成小写
str='Hello PYTHON' #输出结果:Hello python
casefold()和lower()
- 描述:casefold()和lower() 方法都是转换字符串中所有大写字符为小写。
- 语法
- casefold()方法语法: str.casefold()
- lower()方法语法: str.lower()
- 参数:两者均无。
- 返回值:两者均返回将字符串中所有大写字符转换为小写后生成的字符串。
- 实例
# coding:utf-8 str='# Hello WORLD;我爱你中国' if __name__=='__main__': print(str.casefold()) # hello world;我爱你中国 print(str.lower()) # hello world;我爱你中国
- 注意事项
- 只对字符串中的字母有效
- 已经是小写的,则无效
- casefold函数可识别更多的对象将其输出为小写,而lower函数只能完成ASCII码中A-Z之间的大写到小写的转换,当遇到其他外语语种时,大写向小写转换lower函数就无能为力
# coding:utf-8 str='ß' if __name__=='__main__': print(str.casefold()) #ss print(str.lower()) #ß
upper()
- 描述:upper()方法将字符串中的所有小写字母转为大写字母
- 语法: str.upper()
- 参数:无
- 返回值:返回小写字母转为大写字母的字符串。
- 实例
# coding:utf-8 str='# hello WORLD;我爱你中国' if __name__=='__main__': print(str.upper()) # HELLO WORLD;我爱你中国
- 注意事项
- 只对字符串中的字母有效
- 已经是大写,则无效
swapcase()
- 描述:swapcase() 方法用于对字符串的大小写字母进行转换,即将大写字母转换为小写字母,小写字母会转换为大写字母
- 语法: str.swapcase()
- 参数:无
- 返回值:返回大小写字母转换后生成的新字符串。
- 实例:
# coding:utf-8 str='# hELLo WorlD;我爱你中国' if __name__=='__main__': print(str.swapcase()) # HellO wORLd;我爱你中国
- 注意事项:只对字符串中的字母有效
zfill()
- 描述:zfill() 方法返回指定长度的字符串,如不满足,缺少的部分从左开始用0填充
- 语法:str.zfill(width)
- 参数:width -- 指定字符串的长度。如不满足,缺少的部分从左开始用0填充
- 返回值:返回指定长度的字符串。
- 实例:
# coding:utf-8 str='# hELLo WorlD;我爱你中国' if __name__=='__main__': print(len(str)) # 当前字符串长度为19 print(str.zfill(22)) # 000# hELLo WorlD;我爱你中国
- 注意事项
- 与字符串的字符无关
- 如果定义的长度小于当前字符串的长度,则不会发生变化
- 定义的长度大于当前字符串的长度,缺少的部分,从字符串左侧开始用0填充
# coding:utf-8 str='hELLo WorlD;我爱你中国' if __name__=='__main__': print(len(str)) # 当前字符串长度为17 print(str.zfill(3)) #hELLo WorlD;我爱你中国 print(str.zfill(0)) #hELLo WorlD;我爱你中国 print(str.zfill(-3)) #hELLo WorlD;我爱你中国 print(str.zfill(20.14)) #浮点型直接报错
- 相关方法:rjust(width,"0"),和zfill的区别就是可以自定义某个字符作为补充字符
# coding:utf-8 str='hELLo WorlD;我爱你中国' if __name__=='__main__': print(len(str)) # 当前字符串长度为17 print(str.rjust(20,"我")) #我我我hELLo WorlD;我爱你中国
count()
描述:count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。语法: str.count(sub, start= 0,end=len(str))
参数
sub -- 搜索的子字符串
start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置len(str)。
- start和end为可选参数,不填时,默认在整个字符串中,搜索sub
返回值:该方法返回子字符串在字符串中出现的次数。
实例
# coding:utf-8 str='Hello World' sub="o" if __name__=='__main__': print(len(str)) # 当前字符串长度为11 print(str.count(sub)) #2 print(str.count(sub,0,6)) #1 print(str.count("H",0,len(str))) #1
- 注意事项
- 如果查询的元素(成员)不存在,则返回0
- 搜索的范围是包头不包尾,即【start,end)
- 支持倒叙查找,字符串最后一个元素角标为-1
# coding:utf-8 str='Hello World' sub="o" if __name__=='__main__': print(len(str)) # 当前字符串长度为11 print(str.count("我")) #0 print(str.count(sub,2)) # 2,下标参数只填一个,由于start和end均是可选参数,因此无法识别这是开始还是结束,所以依旧搜索整个字符串 print(str.count("e",0,1)) #0,【start,end) print(str.count("e",0,2)) #1,【start,end) print(str.count("o",6,-1)) #1,即在【World)字符串中查找
startswith()
- 描述:startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
- 语法: str.startswith(substr, beg=0,end=len(str));
- 参数:
- str -- 检测的字符串。
- substr -- 指定的子字符串。
- beg -- 可选参数用于设置字符串检测的起始位置。
- end -- 可选参数用于设置字符串检测的结束位置。
- 返回值:如果检测到字符串则返回True,否则返回False。
- 实例:
# coding:utf-8 str = "Hello World" if __name__=='__main__': print(str.startswith("H")) #True print(str.index("W")) #W的下标为6 print(str.startswith("W",6,len(str))) #True print(str.startswith("W",0,6)) #False,同样是包头不包尾
endswith()
- 描述:endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回 True,否则返回 False。可选参数 "start" 与 "end" 为检索字符串的开始与结束位置。
- 语法: str.endswith(suffix[, start[, end]])
- 参数
- suffix -- 该参数可以是一个字符串或者是一个元素。
- start -- 字符串中的开始位置。可选参数
- end -- 字符中结束位置。可选参数
- 返回值:如果字符串含有指定的后缀返回 True,否则返回 False。
- 实例:
# coding:utf-8 str = "Hello World" if __name__=='__main__': print(str.endswith("rld")) #True print(str.endswith("llo",1,5)) #True
- 注意事项:
- startswith() 参数以 0 为第一个字符索引值。
- endswith() 参数以 1 为第一个字符索引值。
# coding:utf-8 str = "01234" if __name__=='__main__': print(str.endswith("234",0,4)) #False print(str.endswith("234",1,5)) #True
find
- 描述:find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
- 语法: str.find(str, beg=0, end=len(str))
- 参数:
- str -- 指定检索的字符串
- beg -- 开始索引,默认为0
- end -- 结束索引,默认为字符串的长度
- 返回值:如果包含子字符串返回开始的索引值,否则返回-1。
- 实例:
# coding:utf-8 str = "Hello World" if __name__=='__main__': print(str.find("H")) #True print(str.find("o",0,len("Hello"))) #True print(str.find("我")) #-1
index()
- 描述:index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
- 语法: str.index(str, beg=0, end=len(str))
- 参数:
- str -- 指定检索的字符串
- beg -- 开始索引,默认为0。
- end -- 结束索引,默认为字符串的长度。
- 返回值:如果包含子字符串返回开始的索引值,否则抛出异常。
- 实例:
# coding:utf-8 str = "Hello World" if __name__=='__main__': print(str.index("H")) #True print(str.index("o",0,len("Hello"))) #True print(str.index("我")) #报错
strip()、lstrip()和rstrip()
- 描述:
- strip() 方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
- lstrip() 方法用于截掉字符串左边的空格或指定字符
- rstrip() 删除 string 字符串末尾的指定字符(默认为空格)
- 语法:
- str.strip([chars]);
- str.lstrip([chars])
- str.rstrip([chars])
- 参数:chars -- 移除字符串头尾指定的字符序列。
- 返回值:返回移除字符串头尾指定的字符序列生成的新字符串。
- 实例:
# coding:utf-8 str = "1231233213212121122334==2111222333221212" str_1=str.strip("123") addr = '13@163.com' addr_1 = addr.strip('12') bddr="www.example.com" bddr_1=bddr.lstrip('cmowz.') if __name__=='__main__': print(str_1) #4== print(addr_1) #3@163.com print(bddr_1) #example.com
- 注意事项:
- 传入的元素如果不在字符串的开头或者结尾则无效
- strip()、lstrip() 和rstrip()处理的时候,如果不带参数,默认是清除两边的空白符(例如:/n, /r, /t, ' ')。
- strip()、lstrip() 和rstrip()带有参数的时候,这个参数可以理解一个要删除的字符的列表,是否会删除的前提是从字符串最开头和最结尾是不是包含要删除的字符,如果有就会继续处理,没有的话是不会删除中间的字符的。
- 注意删除多个字符时:只要头尾有对应其中的某个字符即删除,不考虑顺序,直到遇到第一个不包含在其中的字符为止
replace()
- 描述:replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
- 语法:str.replace(old, new[, max])
- 参数:
- old -- 将被替换的子字符串。
- new -- 新字符串,用于替换old子字符串。
- max -- 可选字符串, 替换不超过 max 次,不传,默认替换全部
- 返回值:返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次。
- 实例:
# coding:utf-8 str = "Hello World" if __name__=='__main__': print(str.replace("o","w")) #Hellw Wwrld
返回值为bool类型的字符串常用方法
方法 语法 描述/功能 isspace str.isspace() 检测字符串是否只由空白字符组成 istitle str.istitle() 检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写 isupper str.isupper() 检测字符串中所有的字母是否都为大写 islower str.islower() 检测字符串是否由小写字母组成
字符串编码格式
- 国际通用:utf-8
- 中文:gbk
- 英文:ascii
- 常用于头注释---> # coding: 编码格式
字符串格式化
使用操作符%格式化字符串
# coding:utf-8 str = "my name is %s,my age is %s" % ("张三",20) #超过一个变量需要格式化时,用小括号括起来 str_1 = "my name is %s" % "张三" if __name__=='__main__': print(str) #my name is 张三,my age is 20 print(str_1) #my name is 张三python 字符串格式化符号:
符 号 描述 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %u 格式化无符号整型 %o 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化浮点数字,可指定小数点后的精度 %e 用科学计数法格式化浮点数 %E 作用同%e,用科学计数法格式化浮点数 %g %f和%e的简写 %G %F 和 %E 的简写 %p 用十六进制数格式化变量的地址 格式化操作符辅助指令:
符号 功能 * 定义宽度或者小数点精度 - 用做左对齐 + 在正数前面显示加号( + ) <sp> 在正数前面显示空格 # 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') 0 显示的数字前面填充'0'而不是默认的空格 % '%%'输出一个单一的'%' (var) 映射变量(字典参数) m.n. m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) # coding:utf-8 str = "my name is %s,my age is %+.2f" % ("张三",20) if __name__=='__main__': print(str) #my name is 张三,my age is +20.00字符串格式化函数format()
- Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能
- 基本语法是通过 {} 和 : 来代替以前的 %
- format 函数可以接受不限个参数,位置可以不按顺序
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序 'hello world' >>> "{0} {1}".format("hello", "world") # 设置指定位置 'hello world' >>> "{1} {0} {1}".format("hello", "world") # 设置指定位置 'world hello world'也可以设置参数:
# coding:utf-8 print("姓名:{name}, 学号 {id}".format(name="张三", id="01")) # 通过字典设置参数 site = {"name": "张三", "id": "01","score":"100"} print("姓名:{name}, 学号:{id},成绩:{score}".format(**site)) # 通过列表索引设置参数 my_list = ['张三', '01'] print("姓名:{0[0]}, 学号 {0[1]}".format(my_list)) # "0" 是必须的也可以向 str.format() 传入对象:
# coding:utf-8 class AssignValue(object): def __init__(self, value): self.value = value my_value = AssignValue(6) print('value 为: {0.value}'.format(my_value)) # "0" 是可选的数字格式化
下表展示了 str.format() 格式化数字的多种方法:
>>> print("{:.2f}".format(3.1415926)) 3.14
数字 格式 输出 描述 3.1415926 {:.2f} 3.14 保留小数点后两位 3.1415926 {:+.2f} +3.14 带符号保留小数点后两位 -1 {:+.2f} -1.00 带符号保留小数点后两位 2.71828 {:.0f} 3 不带小数 5 {:0>2d} 05 数字补零 (填充左边, 宽度为2) 5 {:x<4d} 5xxx 数字补x (填充右边, 宽度为4) 10 {:x<4d} 10xx 数字补x (填充右边, 宽度为4) 1000000 {:,} 1,000,000 以逗号分隔的数字格式 0.25 {:.2%} 25.00% 百分比格式 1000000000 {:.2e} 1.00e+09 指数记法 13 {:>10d} 13 右对齐 (默认, 宽度为10) 13 {:<10d} 13 左对齐 (宽度为10) 13 {:^10d} 13 中间对齐 (宽度为10) 11 '{:b}'.format(11) '{:d}'.format(11) '{:o}'.format(11) '{:x}'.format(11) '{:#x}'.format(11) '{:#X}'.format(11)1011 11 13 b 0xb 0XB进制
- ^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
- + 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
- b、d、o、x 分别是二进制、十进制、八进制、十六进制。
- 此外我们可以使用大括号 {} 来转义大括号,如下实例:
print ("{} 对应的位置是 {{0}}".format("张三")) #输出结果 #张三 对应的位置是 {0}新格式化方法f"字符串{变量}"
定义一个变量,字符串前加f符号,需要格式化的元素位置是用 {变量名}
# coding:utf-8 name="张三" str = f"学生:{name}" print(str)
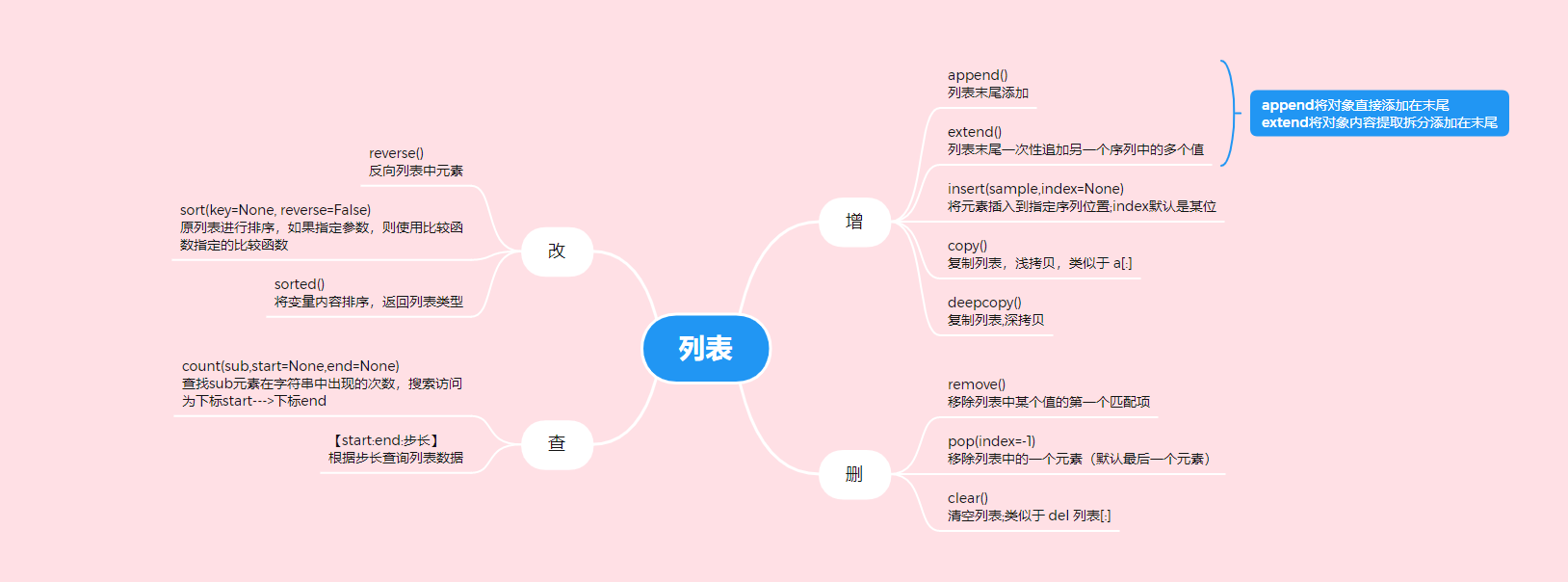
列表常用方法
append()
- 描述:append() 方法用于在列表末尾添加新的对象。
- 语法: list.append(obj)
- 参数:obj -- 添加到列表末尾的对象。
- 返回值:该方法无返回值,但是会修改原来的列表。
- 实例:
list1 = ['Python', 'Java', 'Go'] list1.append('C++') print ("更新后的列表 : ", list1) #['Python', 'Java', 'Go','C++']append() 是浅拷贝,如果在 append 一个对象时,需要特别注意:
# coding:utf-8 list1=[] world=["world"] list1.append(world) print(list1) #[['world']] print(id(list1[0])==id(world)) #True world.append(2) print(list1) #[['world', 2]]变量world值发生改变,list1也会随之改变
insert()
- 描述:insert() 函数用于将指定对象插入列表的指定位置。
- 语法:list.insert(index, obj)
- 参数
- index -- 对象obj需要插入的索引位置。
- obj -- 要插入列表中的对象。
- 返回值:该方法没有返回值,但会在列表指定位置插入对象。
- 实例:
# coding:utf-8 list1 = ['Python', 'Java', 'Go'] list1.insert(1,'C++') print ("更新后的列表 : ", list1) #更新后的列表 : ['Python', 'C++', 'Java', 'Go']对于层叠列表,使用 insert 和 append 函数有一个非常特别之处,就是如果增加的是列表中的一个元素(子列表),则新增的元素初始只作为原元素的一个镜像,这时候如果修改原元素(子列表)中的一个子元素,则新增元素同样变化,修改新元素中的子元素也是如此
# coding:utf-8 a=[[0,0],[1,1],[2,2]] b=[3,3] a.insert(len(a),b) print(a) #[[0, 0], [1, 1], [2, 2], [3, 3]] a[3][0]=4 print(a) #[[0, 0], [1, 1], [2, 2], [4, 3]] print(b) #[4, 3] b[1]=4 print(a) #[[0, 0], [1, 1], [2, 2], [4, 4]] print(b) #[4, 4]
- insert和append的区别
- append只能添加到列表的结尾,而insert可以选择任何一个位置
- 如果insert传入的位置列表中不存在,则将新元素添加到列表的结尾
count()
- 描述:count() 方法用于统计某个元素在列表(元组)中出现的次数。
- 语法: list.count(obj)
- 参数:obj -- 列表中统计的对象。
- 返回值:返回元素在列表中出现的次数。
- 实例:
#!/usr/bin/python3 aList = [123, 456, 456, 777, 123]; print ("123 元素个数 : ", aList.count(123)) #2 print ("777 元素个数 : ", aList.count(777)) #2统计字符出现的个数或列表内出现的元素次数等也可以用 Counter。一个 Counter 是一个 dict 的子类,用于计数可哈希对象。
from collections import Counter c = Counter('sadasfas') print(c) #Counter({'s': 3, 'a': 3, 'd': 1, 'f': 1}) a=['su','bu','sum','bu','sum','bu'] c = Counter(a) print(c) #Counter({'bu': 3, 'sum': 2, 'su': 1}) c.update('sadasfas') #添加 print(c) #Counter({'bu': 3, 's': 3, 'a': 3, 'sum': 2, 'su': 1, 'd': 1, 'f': 1})
remove()
- 描述:remove() 函数用于移除列表中某个值的第一个匹配项。
- 语法: list.remove(obj)
- 参数:obj -- 列表中要移除的对象。
- 返回值:该方法没有返回值但是会移除列表中的某个值的第一个匹配项。
- 实例:
#!/usr/bin/python3 list1 = ['a', 'b', 'c', 'd'] list1.remove('a') print ("列表现在为 : ", list1) #列表现在为 : ['b', 'c', 'd'] list1.remove('b') print ("列表现在为 : ", list1) #列表现在为 : ['c', 'd']
pop()
- 描述:pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
- 语法: list.pop([index=-1])
- 参数:index -- 可选参数,要移除列表元素的索引值,不能超过列表总长度,默认为 index=-1,删除最后一个列表值。
- 返回值:该方法返回从列表中移除的元素对象。
- 实例:
#!/usr/bin/python3 list1 = ['a', 'b', 'c'] list1.pop() print ("列表现在为 : ", list1) #列表现在为 : ['a', 'b'] list1.pop(1) print ("列表现在为 : ", list1) #列表现在为 : ['a']
reverse()
- 描述:reverse() 函数用于反向列表中元素。
- 语法: list.reverse()
- 参数:无
- 返回值:该方法没有返回值,但是会对列表的元素进行反向排序。
- 实例:
#!/usr/bin/python3 list1 = ['a', 'b', 'c', 'd'] list1.reverse() print ("列表反转后: ", list1) #列表反转后: ['d', 'c', 'b', 'a']
sort()
- 描述:sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
- 语法: list.sort( key=None, reverse=False)
- 参数:
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
- 返回值:该方法没有返回值,但是会对列表的对象进行排序。
- 实例:
#!/usr/bin/python aList = ['c', 'd', 'b', 'a'] aList.sort() print("List : ", aList) #List : ['a', 'b', 'c', 'd']
clear()
- 描述:clear() 函数用于清空列表,类似于 del a[:]。
- 语法: list.clear()
- 参数:无
- 返回值:该方法没有返回值。
- 实例:
#!/usr/bin/python aList = ['c', 'd', 'b', 'a'] aList.clear() bList=['c', 'd', 'b', 'a'] del bList[:] print("List : ", aList) #List : [] print("List : ", bList) #List : []
copy()
- 描述:copy() 函数用于复制列表,类似于 a[:]。
- 语法: list.copy()
- 参数:无
- 返回值:返回复制后的新列表。
- 实例:
#!/usr/bin/python3 list1 = ['a', 'b', 'c', 'd'] list2 = list1.copy() list3=list1[:] print ("list2 列表: ", list2) #list2 列表: ['a', 'b', 'c', 'd'] print ("list3 列表: ", list3) #list2 列表: ['a', 'b', 'c', 'd']copy()和直接=赋值的区别:
a=[0,1,2,3,4,5] b=a c=a.copy() del a[1] ''' 各变量值为: a=[0, 2, 3, 4, 5] b=[0, 2, 3, 4, 5] c=[0, 1, 2, 3, 4, 5] ''' b.remove(4) ''' 各变量值为: a=[0, 2, 3, 5] b=[0, 2, 3, 5] c=[0, 1, 2, 3, 4, 5] ''' c.append(9) ''' 各变量值为: a=[0, 2, 3, 5] b=[0, 2, 3, 5] c=[0, 1, 2, 3, 4, 5, 9] '''可以看出,使用=直接赋值,是引用赋值,更改一个,另一个同样会变, 例子中的a,b改变两次都影响到了对方;copy() 则顾名思义,复制一个副本,原值和新复制的变量互不影响 「a,c」
当原对象存在多层嵌套的情况下,浅拷贝copy()只拷贝了最外层的数据结构,最外层所包含的数据变化时,是不会相互影响的,但是当原数据对象内部嵌套数据中的数据发生变化后,相应的浅拷贝后的对象也会发生变化.类似于一个公司,原来有一个宿舍,通过浅拷贝,重新造了一个相同建筑架构的宿舍.里面有物理墙体,电视,电脑,床位等,电视里播放着统一的画面.当公司改变了电视里播放的画面时,所有的宿舍都会发生改变.其中物理墙体,硬件电视等相当于最外层的对象结构,而电视里的画面就是内层嵌套的数据了。
#!/usr/bin/python3 arr = [{'name': 'wcl', 'age': 23}, {'name': 'wjy', 'age': 14}] arr2 = arr.copy() del arr[1] arr[0]['age'] = 18 print('arr', arr) #arr [{'name': 'wcl', 'age': 18}] print('arr2', arr2) #arr2 [{'name': 'wcl', 'age': 18}, {'name': 'wjy', 'age': 14}]
直接赋值、浅拷贝和深度拷贝解析
直接赋值:其实就是对象的引用(别名)。
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
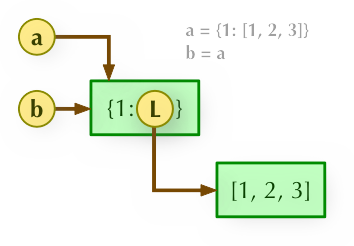
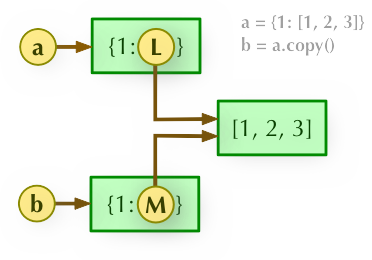
字典浅拷贝实例
>>>a = {1: [1,2,3]} >>> b = a.copy() >>> a, b ({1: [1, 2, 3]}, {1: [1, 2, 3]}) >>> a[1].append(4) >>> a, b ({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})深度拷贝需要引入 copy 模块:
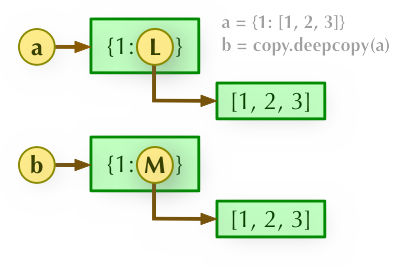
>>>import copy >>> c = copy.deepcopy(a) >>> a, c ({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]}) >>> a[1].append(5) >>> a, c ({1: [1, 2, 3, 4, 5]}, {1: [1, 2, 3, 4]})解析
1、b = a: 赋值引用,a 和 b 都指向同一个对象。
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
更多实例
以下实例是使用 copy 模块的 copy.copy( 浅拷贝 )和(copy.deepcopy ):
#!/usr/bin/python # -*-coding:utf-8 -*- import copy a = [1, 2, 3, 4, ['a', 'b']] #原始对象 b = a #赋值,传对象的引用 c = copy.copy(a) #对象拷贝,浅拷贝 d = copy.deepcopy(a) #对象拷贝,深拷贝 a.append(5) #修改对象a a[4].append('c') #修改对象a中的['a', 'b']数组对象 print( 'a = ', a ) print( 'b = ', b ) print( 'c = ', c ) print( 'd = ', d )以上实例执行输出结果为:
('a = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5]) ('b = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5]) ('c = ', [1, 2, 3, 4, ['a', 'b', 'c']]) ('d = ', [1, 2, 3, 4, ['a', 'b']])
extend()
- 描述:extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。
- 语法: list.extend(seq)
- 参数:seq -- 元素列表,可以是列表、元组、集合、字典,若为字典,则仅会将键(key)作为元素依次添加至原列表的末尾。
- 返回值:该方法没有返回值,但会在已存在的列表中添加新的列表内容。
- 实例:
#!/usr/bin/python3 # 列表 list = ['a', 'b', 'c'] # 元组 list_tuple = ('d_元组', 'e_元组') # 集合 list_set = {'f_集合', 'g_集合'} # 字典 list_dict = {'key01':'h_字典','key02':'i_字典'} # 添加元组元素到列表末尾 list.extend(list_tuple) print('新列表: ', list) #新列表: ['a', 'b', 'c', 'd_元组', 'e_元组'] # 添加集合元素到列表末尾 list.extend(list_set) print('新列表: ', list) #新列表: ['a', 'b', 'c', 'd_元组', 'e_元组', 'f_集合', 'g_集合'] # 添加字典元素,仅仅将key添加到列表末尾 list.extend(list_dict) print('新列表: ', list) #新列表: ['a', 'b', 'c', 'd_元组', 'e_元组', 'f_集合', 'g_集合', 'key01', 'key02']append、insert和extend的区别
- list.append(object) 向列表中添加一个对象object。
- list.insert(index,obj)函数用于将指定对象插入列表的指定位置。
- list.extend(sequence) 把一个序列seq的内容添加到列表中。
- append,insert对象obj,使用时候作为一个对象加入其中。
- 而extend看作一个序列,将这个序列和原列表序列合并,并放在其后面。
#!/usr/bin/python3 list=[1,2,3] list_1=[['hello','world'],('a','b','c'),{'你','好'},{'key01':'value01','key02':'value02'}] list.extend(list_1) print(list) #[1, 2, 3, ['hello', 'world'], ('a', 'b', 'c'), {'好', '你'}, {'key01': 'value01', 'key02': 'value02'}] list_1[0][1]='python' print(list_1) #[['hello', 'python'], ('a', 'b', 'c'), {'好', '你'}, {'key01': 'value01', 'key02': 'value02'}] print(list) #[1, 2, 3, ['hello', 'python'], ('a', 'b', 'c'), {'好', '你'}, {'key01': 'value01', 'key02': 'value02'}] #由结果可见extend也是一个浅拷贝
列表的索引
#!/usr/bin/python3 numbers=[1,2,3,4,5,6,7,8] #1.获取列表长度 print(len(numbers)) #8 #2.获取列表的最大索引 print(len(numbers)-1) #7 #3.获取列表所有内容 #3.1方式一 print(numbers[:]) #[1, 2, 3, 4, 5, 6, 7, 8] #3.2方式二 print(numbers[0:]) #[1, 2, 3, 4, 5, 6, 7, 8] #3.3思考numbers的id和numbers[:]在内存的id一不一样,是不是同一个对象 print(id(numbers)) #1715647274432 print(id(numbers[:])) #1715651694336 #4列表的反序 #4.1方式一 # numbers.reverse() # print(numbers) #4.2方式二 print(numbers[::-1]) #[8, 7, 6, 5, 4, 3, 2, 1] #5.根据步长获取列表内容 print(numbers[0:5:2]) #索引0-5,步长为2,取列表内容:[1, 3, 5]
字典常用方法
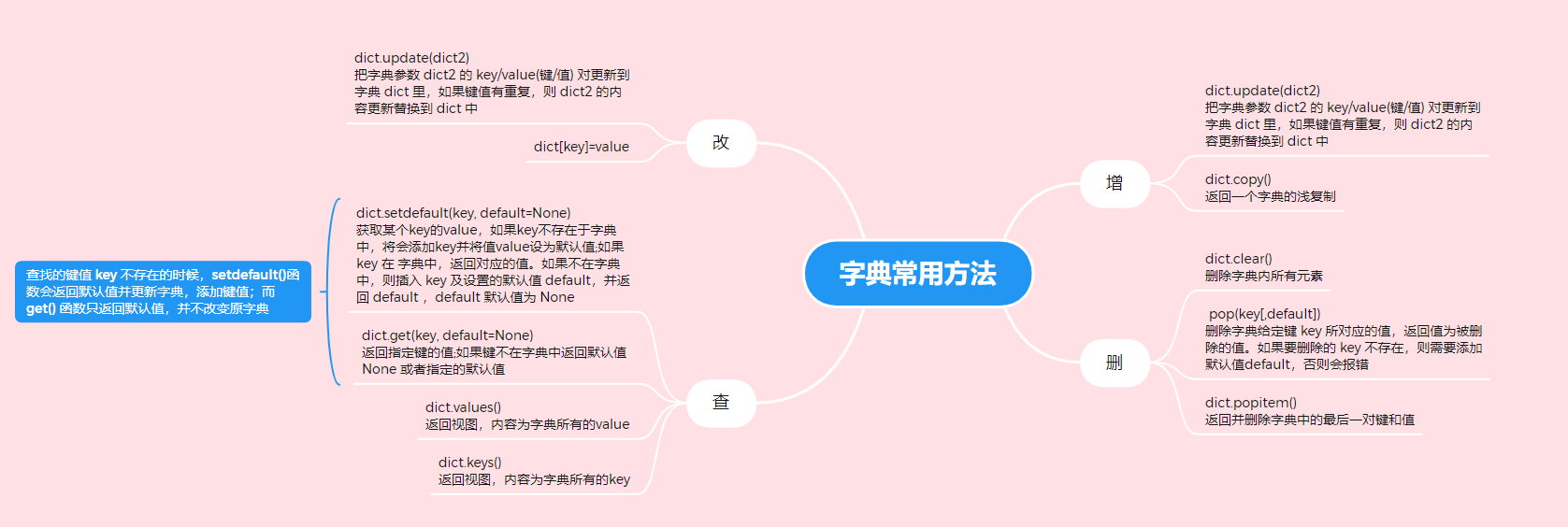
update()
- 描述:字典 update() 函数把字典参数 dict2 的 key/value(键/值) 对更新到字典 dict 里,如果键值有重复,则 dict2 的内容更新替换到 dict 中。
- 语法: dict.update(dict2)
- 参数:dict2 -- 添加到指定字典dict里的字典。
- 返回值:该方法没有任何返回值。
- 实例:
#!/usr/bin/python3 dict = {'Name': 'zhangsan', 'Age': 20} dict2 = {'Name': 'wangwu', 'Age': 20,'Top':180} dict['Name']='lisi' print(dict) #{'Name': 'lisi', 'Age': 20} dict.update(dict2) print("更新字典 dict : ", dict) #更新字典 dict : {'Name': 'wangwu', 'Age': 20, 'Top': 180}
setdefault()
- 描述:字典 setdefault() 方法和 get()方法 类似, 获取某个key的value,如果key不存在于字典中,将会添加key并将值value设为默认值。
- 语法: dict.setdefault(key, default=None)
- 参数
- key -- 查找的键值。
- default -- 键不存在时,设置的默认键值。
- 返回值:如果 key 在 字典中,返回对应的值。如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。
- 实例:
#!/usr/bin/python3 dict = {'Name': 'zhangsan', 'Age': 7} print("Age 键的值为 : %s" % dict.setdefault('Age', None)) #Age 键的值为 : 7 print(("Sex 键的值为 : {}").format(dict.setdefault('Sex', None))) #Sex 键的值为 : None print("新字典为:", dict) #新字典为: {'Name': 'zhangsan', 'Age': 7, 'Sex': None}关于字典中 get() 和 setdefault() 的区别:
主要在于当查找的键值 key 不存在的时候,setdefault()函数会返回默认值并更新字典,添加键值;而 get() 函数只返回默认值,并不改变原字典。
#!/usr/bin/python3 # get() d={} d.get('name','N/A') print(d) #{} print (d.get('name')) #None #setdefault() c={} c.setdefault('name','Jack') print(c) #{'name': 'Jack'} c.setdefault('age') print(c) #{'name': 'Jack', 'age': None}
get()
- 描述:字典 get() 函数返回指定键的值。
- 语法: dict.get(key, default=None)
- 参数
- key -- 字典中要查找的键。
- default -- 如果指定的键不存在时,返回该默认值。
- 返回值:返回指定键的值,如果键不在字典中返回默认值 None 或者指定的默认值。
- 实例:
#!/usr/bin/python3 dict = {'Name': 'zhangsan', 'Age': 27} print ("Age 值为 : %s" % dict.get('Age')) #Age 值为 : 27 print ("Sex 值为 : %s" % dict.get('Sex', "没找到")) #Sex 值为 : 没找到 print(dict) #{'Name': 'zhangsan', 'Age': 27}关于字典中 get() 和 dict[key]获取value 的区别:
- []如果获取的key不存在,则直接报错
- get如果获取的key不存在,则返回默认值
keys()
- 描述:
- 字典 keys() 方法返回一个视图对象。
- dict.keys()、dict.values() 和 dict.items() 返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
- 视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
- 我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
- 注意:Python2.x 是直接返回列表
- 语法:dict.keys()
- 参数:无
- 返回值:返回一个视图对象。
- 实例:
#!/usr/bin/python3 dict= {'a': 1, 'b': 2, 'c': 3} print(dict.keys()) #dict_keys(['a', 'b', 'c']) del dict['c'] print(dict.keys()) #dict_keys(['a', 'b']) dict_list=list(dict.keys()) print(dict_list[0]) #a
values()
- 描述:
- 字典 values() 方法返回一个视图对象。
- dict.keys()、dict.values() 和 dict.items() 返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
- 视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
- 我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
- 语法: dict.values()
- 参数:无
- 返回值:返回视图对象。
- 实例:
#!/usr/bin/python3 dict= {'a': 1, 'b': 2, 'c': 3} print(dict.values()) #dict_values([1, 2, 3]) dict_key=list(dict.keys()) dict_value=list(dict.values()) print('{0} | {1} | {2} '.format(dict_key[0],dict_key[1],dict_key[2])) print('{} | {} | {} '.format(dict_value[0],dict_value[1],dict_value[2])) ''' a | b | c 1 | 2 | 3 '''
items()
- 描述
- 字典 items() 方法以列表返回视图对象,是一个可遍历的key/value 对。
- dict.keys()、dict.values() 和 dict.items() 返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
- 视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
- 我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
- 语法: dict.items()
- 参数:无
- 返回值:返回可视图对象。
- 实例:
#!/usr/bin/python3 dict= {'a': 1, 'b': 2, 'c': 3} print(dict.items()) #dict_items([('a', 1), ('b', 2), ('c', 3)])
clear()
- 描述:字典 clear() 函数用于删除字典内所有元素。
- 语法: dict.clear()
- 参数:无
- 返回值:该函数没有任何返回值。
- 实例:
#!/usr/bin/python3 dict= {'a': 1, 'b': 2, 'c': 3} print(len(dict)) #3 dict.clear() print(len(dict)) #0
pop()
- 描述:
- 字典 pop() 方法删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
- 如果要删除的 key 不存在,则需要添加默认值,否则会报错
- 语法: pop(key[,default])
- 参数
- key: 要删除的键值
- default: 如果没有 key,返回 default 值
- 返回值:返回被删除的值。
- 实例:
#!/usr/bin/python3 dict= {'a': 1, 'b': 2, 'c': 3,'d':4,'e':5} print(dict.pop('a')) #1 print(dict) #{'b': 2, 'c': 3, 'd': 4, 'e': 5} print(dict.pop('b','已删除')) #2 print(dict) #{'c': 3, 'd': 4, 'e': 5} print(dict.pop('f','没有找到对应的key')) #没有找到对应的key print(dict) #{'c': 3, 'd': 4, 'e': 5}还可以使用内置函数del删除
#!/usr/bin/python3 dict= {'a': 1, 'b': 2, 'c': 3,'d':4,'e':5} del dict['a'] print(dict) #{'b': 2, 'c': 3, 'd': 4, 'e': 5} del dict['f'] #没有key直接报错
copy()
- 描述:字典 copy() 函数返回一个字典的浅复制。
- 语法: dict.copy()
- 参数:无
- 返回值:返回一个字典的浅复制。
- 实例:
#!/usr/bin/python3 a= {1:'a',2:'b',3:'c',4:['d','e','f']} b=a.copy() a[4][1]='d' a[4].pop(2) a.setdefault(5,'g') print(a) #{1: 'a', 2: 'b', 3: 'c', 4: ['d', 'd'], 5: 'g'} print(b) #{1: 'a', 2: 'b', 3: 'c', 4: ['d', 'd']}
成员运算符
#!/usr/bin/python3 a= {1:'a',2:'b',3:'c'} print(1 in a) #True print(4 not in a) #True print(bool(a.get(2))) #True注意:使用get()判断,如果value是None,是会返回False的
#!/usr/bin/python3 a= {1:'a',2:'b',3:None} print(3 in a) #True print(bool(a.get(3))) #False
popitem()
- 描述
- Python 字典 popitem() 方法随机返回并删除字典中的最后一对键和值。
- 如果字典已经为空,却调用了此方法,就报出KeyError异常。
- 语法: dict.popitem()
- 参数:无
- 返回值:返回一个键值对(key,value)形式,按照 LIFO(Last In First Out 后进先出法) 顺序规则,即最末尾的键值对。
- 实例:
#!/usr/bin/python3 a= {1:'a',2:'b',3:'d'} a_1=a.popitem() print(a_1) #(3, 'd') print(a) #{1: 'a', 2: 'b'}
集合常用方法
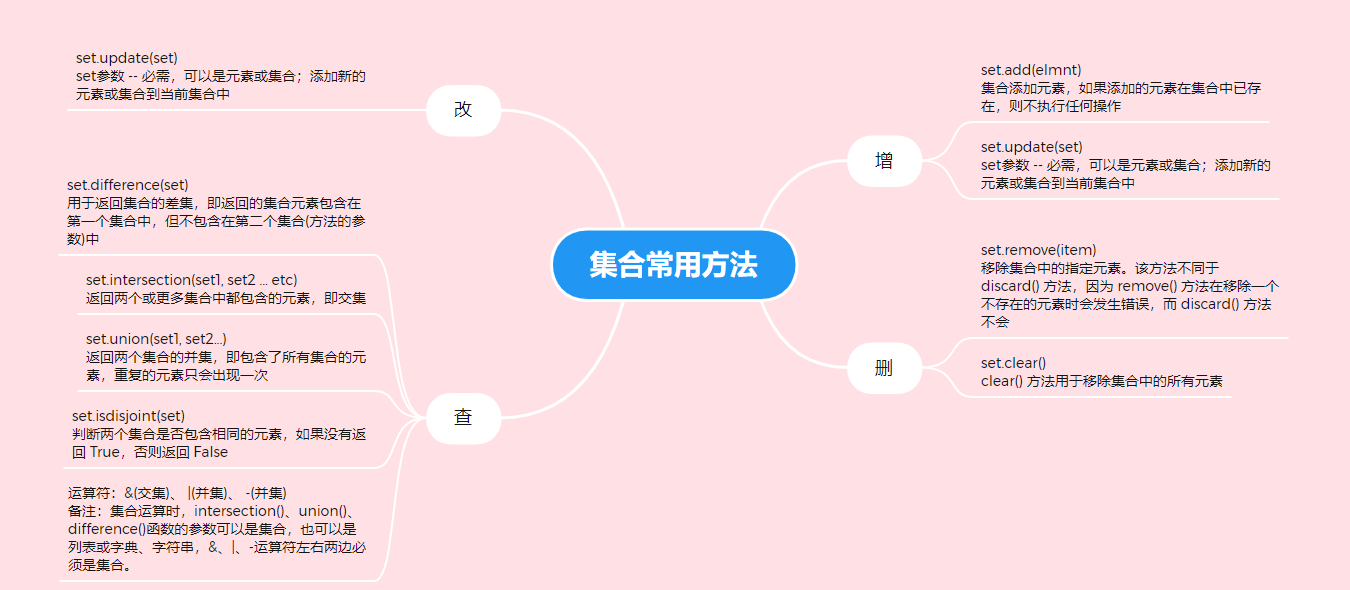
add()
- 描述:add() 方法用于给集合添加元素,如果添加的元素在集合中已存在,则不执行任何操作。
- 语法: set.add(elmnt)
- 参数:elmnt -- 必需,要添加的元素。
- 返回值:无
- 实例:
fruits = {"apple", "banana", "cherry"} fruits.add("orange") print(fruits) #{'apple', 'banana', 'orange', 'cherry'}# coding:utf-8 # set_1={1,'2',None,(1,'2'),{1,'2'},[1,'2'],{"key":"value"}} #报错,集合里面不能放列表、字典、不能再嵌套集合 set_1={1,'2',None,(1,'2'),(3,'4')} sample=(1,'2') sample_0=(3,4) sample_1={3,4} sample_2=[5,6] sample_3= {'key':'value'} set_1.add(sample) set_1.add(sample_0) # set_1.add(sample_1) # set_1.add(sample_2) # set_1.add(sample_3) print(set_1) #{1, '2', None, (1, '2'), (3, 4), (3, '4')}
update()
- 描述:update() 方法用于修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略。
- 语法: set.update(set)
- 参数:set -- 必需,可以是元素或集合
- 返回值:无
- 实例:
- 合并两个集合,重复元素只会出现一次:
# coding:utf-8 # set_1={1,'2',None,(1,'2'),{1,'2'},[1,'2'],{"key":"value"}} #报错,集合里面不能放列表、字典、不能再嵌套集合 set_1={1,'2',None,(1,'2')} sample=(1,2) sample_1={3,4} sample_2=[5,6] sample_3= {'key':'value'} set_1.update(sample) set_1.update(sample_1) set_1.update(sample_2) set_1.update(sample_3) print(set_1) #{1, 2, 3, 4, 5, 6, 'key', None, (1, '2'), '2'}# coding:utf-8 #str在添加时会被打散 set_1={1,'2',None} sample=('你好中国') set_1.update(sample) print(set_1) #{1, '国', '好', None, '你', '中', '2'}
remove()
- 描述:remove() 方法用于移除集合中的指定元素。该方法不同于
discard()方法,因为remove()方法在移除一个不存在的元素时会发生错误,而discard()方法不会。- 语法: set.remove(item)
- 参数:item -- 要移除的元素
- 返回值:无
- 实例:
# coding:utf-8 fruits = {"apple", "banana", "cherry"} fruits.remove("banana") print(fruits) #{'apple', 'cherry'}
clear()
- 描述:clear() 方法用于移除集合中的所有元素。
- 语法: set.clear()
- 参数:无
- 返回值:无
- 实例:
# coding:utf-8 fruits = {"apple", "banana", "cherry"} fruits.clear() print(fruits) #set()
difference()
- 描述:difference() 方法用于返回集合的差集,即返回的集合元素包含在第一个集合中,但不包含在第二个集合(方法的参数)中。
- 语法: set.difference(set)
- 参数:set -- 必需,用于计算差集的集合
- 返回值:返回一个新的集合。
- 实例:
# coding:utf-8 x = {"apple", "banana", "cherry"} y = {"google", "microsoft", "apple"} print(x.difference(y)) #{'cherry', 'banana'} print(y.difference(x)) #{'microsoft', 'google'}
intersection()
- 描述:intersection() 方法用于返回两个或更多集合中都包含的元素,即交集。
- 语法: set.intersection(set1, set2 ... etc)
- 参数
- set1 -- 必需,要查找相同元素的集合
- set2 -- 可选,其他要查找相同元素的集合,可以多个,多个使用逗号 , 隔开
- 返回值:返回一个新的集合。
- 实例:
- 返回一个新集合,该集合的元素既包含在集合 x 又包含在集合 y 中:
# coding:utf-8 x = {"a", "b", "c"} y = {"c", "d", "e"} z = {"f", "g", "c"} print(x.intersection(y, z)) #{'c'}
union()
- 描述:union() 方法返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。
- 语法:set.union(set1, set2...)
- 参数
- set1 -- 必需,合并的目标集合
- set2 -- 可选,其他要合并的集合,可以多个,多个使用逗号 , 隔开。
- 返回值:返回一个新集合。
- 实例:
- 合并两个集合,重复元素只会出现一次:
# coding:utf-8 x = {"a", "b", "c"} y = {"f", "d", "a"} z = {"c", "d", "e"} print(x.union(y, z)) #{'d', 'c', 'f', 'b', 'a', 'e'}
isdisjoint()
- 描述:isdisjoint() 方法用于判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
- 语法: set.isdisjoint(set)
- 参数:set -- 必需,要比较的集合
- 返回值:返回布尔值,如果不包含返回 True,否则返回 False。
- 实例:
- 判断集合 y 中是否有包含 集合 x 的元素:
# coding:utf-8 x = {"apple", "banana", "cherry"} y = {"google", "rice", "apple"} print(x.isdisjoint(y)) #False #也可以使用交集判断 z=bool(x.intersection(y)) print(bool(1-z)) #False
拓展:集合的&(交集)、 |(并集)、 -(并集) 运算符
- &符可以计算两个集合的交集,与集合的intersection()函数实现的功能一样
- |符可以计算两个集合的并集,与集合的union()函数实现的功能一样
- -运算符可以计算两个集合的差集,与集合的difference()函数实现的功能一样
# coding:utf-8 set_1 = {1, 2, 3, 4, 5, 6} set_2 = {4, 5, 6, 7, 8, 9} #分别使用intersection()函数和&运算符求两个集合的交集 result_1 = set_1.intersection(set_2) result_2 = set_1 & set_2 print(result_1) #{4, 5, 6} print(result_2) #{4, 5, 6} #分别使用union()函数和 | 运算符求两个集合的并集 result_3 = set_1.union(set_2) result_4 = set_1 | set_2 print(result_3) #{1, 2, 3, 4, 5, 6, 7, 8, 9} print(result_4) #{1, 2, 3, 4, 5, 6, 7, 8, 9} #分别使用difference()函数和 - 运算符求两个集合的差集 result_5 = set_1.difference(set_2) result_6 = set_1 - set_2 print(result_5) #{1, 2, 3} print(result_6) #{1, 2, 3}&、|、-与intersection()、union()、difference()函数的不同之处:
集合运算时,intersection()、union()、difference()函数的参数可以是集合,也可以是列表或字典、字符串,&、|、-运算符左右两边必须是集合。
# coding:utf-8 set_1 = {1, 2, 3, 4, 5, 6} list_1 = [4, 5, 6, 7, 8, 9] result_1 = set_1.intersection(list_1) print(result_1) #{4, 5, 6} result_2 = set_1 & list_1 print(result_2) #报错。类型错误
不同数据类型间转换
拓展dir()
- 描述:dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
- 语法: dir([object])
- 参数说明:object -- 对象、变量、类型。
- 返回值:返回模块的属性列表。
- 实例:
# coding:utf-8 a=123 b=['1','2','3'] c={1,2,3} d={'a':1,'b':2} e=(1,2,3) print(dir()) #'a', 'b', 'c', 'd', 'e' print(dir(b)) ''' ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] '''
字符串与数字的转换
- int不能转换带小数点的浮点数
- float可以把整数字符串转成浮点数
- str里的浮点数只能先转float再转int,不能直接转int
# coding:utf-8 str_1='3.14' num=123 numFloat=3.123 # str_int=int(str)#报错,需要先转成浮点型,再由浮点型转成字符串 str_float=float(str_1) num_str=str(num) numFloat_str=str(numFloat) # print(str_int)#报错 print(str_float,type(str_float)) #3.14 <class 'float'> print(num_str,type(num_str)) #123 <class 'str'> print(numFloat_str,type(num_str)) #3.123 <class 'str'>注意事项:str型转换成int型,要转换的字符串内容必须是整数,不然会报错
字符串与列表间的转换
split():字符串转列表
- 语法: str.split(str="", num=string.count(str))
- 参数
- str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
- num -- 分割次数。默认为 -1, 即分隔所有。
- 返回值:返回分割后的字符串列表。
- 实例:
# coding:utf-8 name='my name is Gelaotou' name_list=name.split() url='www.baidu.com' url_list=url.split('.',url.count('.')) print(name_list) #['my', 'name', 'is', 'Gelaotou'] print(url_list) #['www', 'baidu', 'com']join():列表转字符串
- 语法: sep.join(iterable)
- 参数:
- seq:生成字符串用来分割列表每个元素的符号
- iterable:非数字类型的列表或元组或集合
- 返回值:返回通过指定字符连接序列中元素后生成的新字符串。
- 实例:
# coding:utf-8 Symbol='.' url_list=['www', 'baidu', 'com'] print(Symbol.join(url_list),type(Symbol.join(url_list))) #www.baidu.com <class 'str'> print('|'.join(url_list),type(Symbol.join(url_list))) #www|baidu|com <class 'str'>注意事项:将列表转换成字符串,列表中的左右方括号[]、空格、引号以及逗号,都是字符串的内容
字符串与bytes的转换
什么是比特类型
- 二进制的数据流---bytes
- 一种特殊的字符串
- 字符串前+b标记
# coding:utf-8 name=b'Gelaotou' print(name,type(name)) #b'Gelaotou' <class 'bytes'>比特类型可以当做特殊的字符串
- 字符串的captitalize、replace、find都可以使用,只是其中的字符串都需要在前面加b
- 索引返回的是数值,切片与字符串相同
# coding:utf-8 name=b'gelAOTou' name_1=name.replace(b'e',b'E') print(name.capitalize()) #b'Gelaotou' print(name.find(b'A')) #3 print(name_1) #b'gElAOTou'encode():字符串转bytes
- 描述:encode() 方法以指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
- 语法: str.encode(encoding='UTF-8',errors='strict')
- 参数:
- encoding -- 要使用的编码,默认 UTF-8。
- errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
- 返回值:该方法返回编码后的字符串,它是一个 bytes 对象。
- 实例:
# coding:utf-8 name='张三' name_byte=name.encode("utf-8") print(name_byte,type(name_byte)) #b'\xe5\xbc\xa0\xe4\xb8\x89' <class 'bytes'>decode():bytes转字符串
- 描述:decode() 方法以指定的编码格式解码 bytes 对象。默认编码为 'utf-8'。
- 语法: bytes.decode(encoding="utf-8", errors="strict")
- 参数
- encoding -- 要使用的编码,如"UTF-8"。
- errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
- 返回值:该方法返回解码后的字符串。
- 实例:
# coding:utf-8 name='张三' name_byte=name.encode("utf-8") nameStr=name_byte.decode() print(name_byte,type(name_byte)) #b'\xe5\xbc\xa0\xe4\xb8\x89' <class 'bytes'> print(nameStr,type(nameStr)) #张三 <class 'str'>
元组、列表以及集合之间转换
# coding:utf-8 a='1234' b=(1,2,3,4) c=[1,2,3,4] d={1,2,3,4} print(tuple(a),list(a),set(a)) #('1', '2', '3', '4') ['1', '2', '3', '4'] {'3', '2', '1', '4'} print(list(b),str(b),set(b),type(str(b))) #[1, 2, 3, 4] (1, 2, 3, 4) {1, 2, 3, 4} <class 'str'> print(tuple(c),str(a),set(a)) #(1, 2, 3, 4) 1234 {'3', '4', '2', '1'} print(tuple(d),str(d),list(d),type(str(d))) #(1, 2, 3, 4) {1, 2, 3, 4} [1, 2, 3, 4] <class 'str'> print(tuple(a)==b) # print(list(str(b))) #list多层嵌套转换会使数据失真;列表类型在使用str()转换为字符串数据后,再使用list()转换为列表时,结果并不是原来的数据;['(', '1', ',', ' ', '2', ',', ' ', '3', ',', ' ', '4', ')']


 浙公网安备 33010602011771号
浙公网安备 33010602011771号