Python基础入门(2)- python中的数据类型
python数据类型
- 什么是数据类型?
将数据分类,能有效的被电脑识别
- 为什么会有多种数据类型?
为了适应更多的使用场景,将数据划分为多种类型,每一种类型都有着各自的特点和使用场景,帮助计算机高效的处理以展示数据
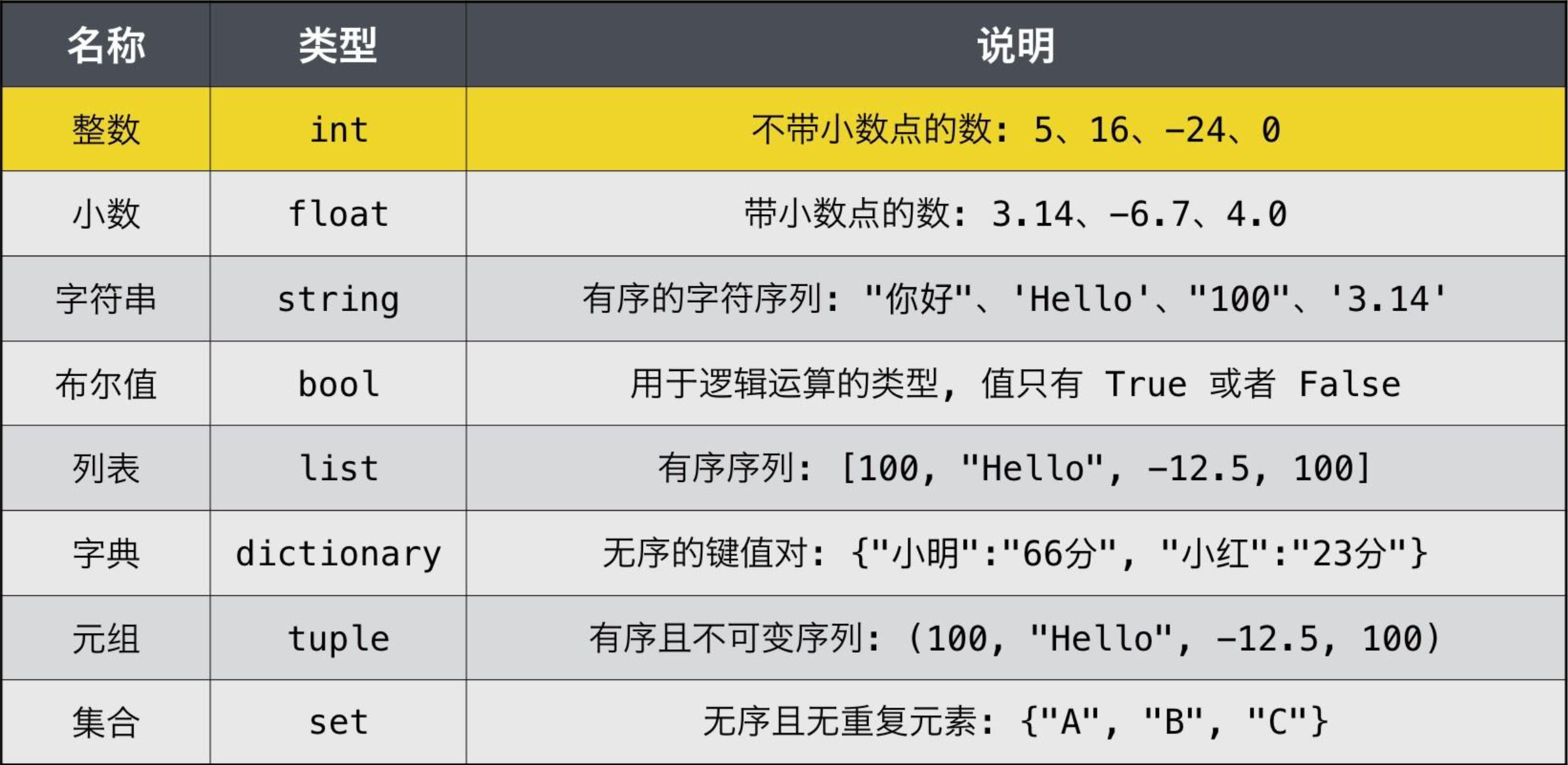
- python数据类型如图👇,其中整数和小数统称为数字类型
- 如何知道一个变量是什么数据类型?可以通过python内置函数type,使用方法为 type(已经被赋值的变量名或变量)
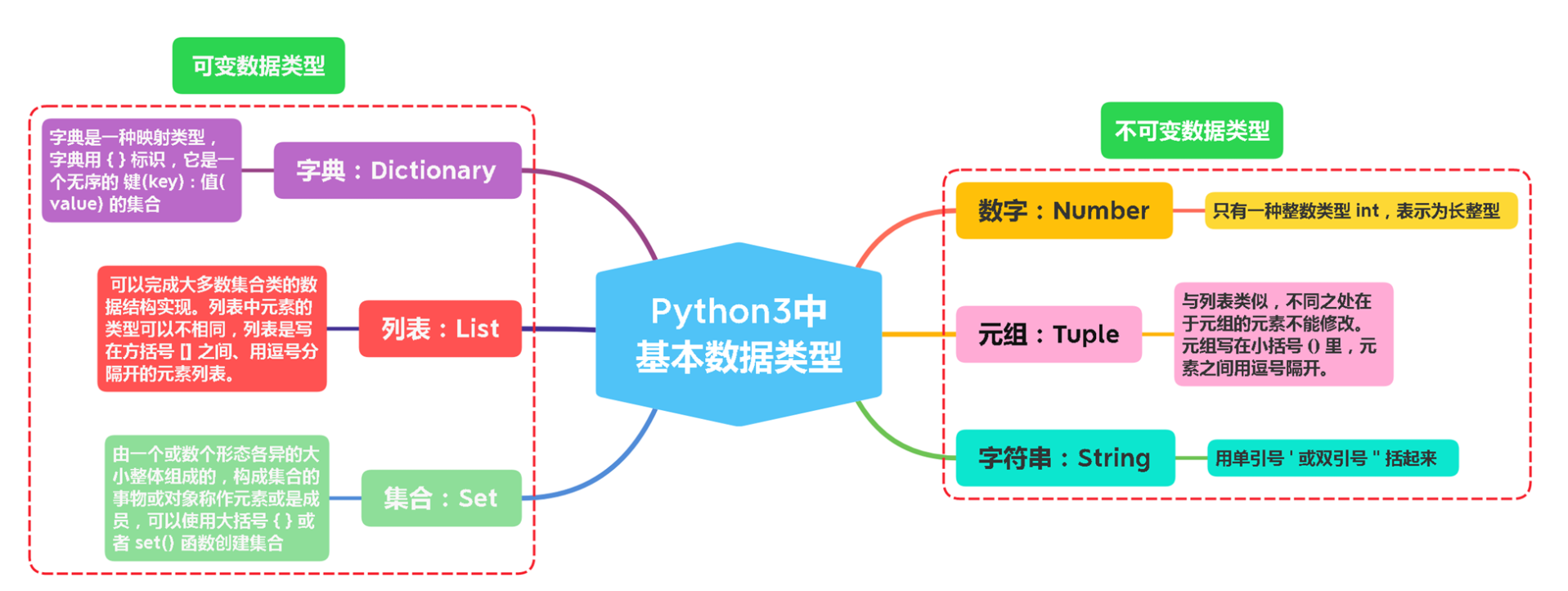
- 同样可以按照可变和不可变进行划分,如图👇:
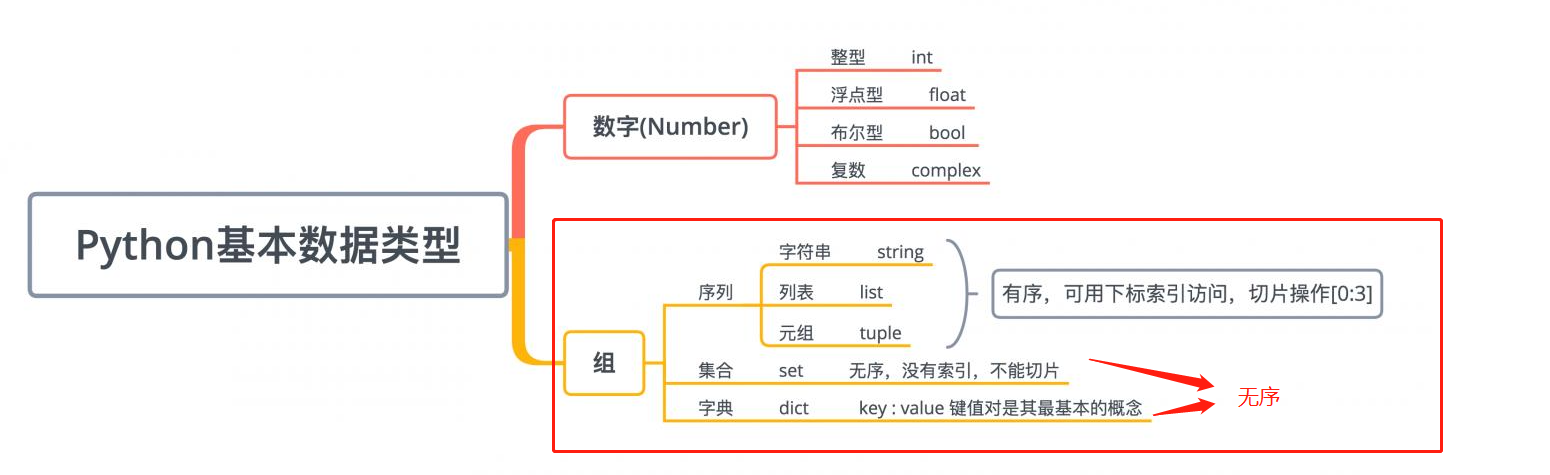
- 按照有序,无需分类—>针对存在多个字符的数据类型进行分类
数字类型
Python 支持三种不同的数字类型:
整型(int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。布尔(bool)是整型的子类型。
浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
声明数字类型
#整型(int) num1=10 num2=int(10) #浮点型(float) num3=3.14 num4=float(3.14) #复数(complex) num5=3+4j num6=comple(3+4)
数字运算
Python 解释器可以作为一个简单的计算器,您可以在解释器里输入一个表达式,它将输出表达式的值。
表达式的语法很直白: +, -, * 和 /, 和其它语言(如Pascal或C)里一样。例如:
>>> 2 + 2 4 >>> 50 - 5*6 20 >>> (50 - 5*6) / 4 5.0 >>> 8 / 5 # 总是返回一个浮点数 1.6注意:在不同的机器上浮点运算的结果可能会不一样。
在整数除法中,除法 / 总是返回一个浮点数,如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // :
>>> 17 / 3 # 整数除法返回浮点型 5.666666666666667 >>> >>> 17 // 3 # 整数除法返回向下取整后的结果 5 >>> 17 % 3 # %操作符返回除法的余数 2 >>> 5 * 3 + 2 17注意:// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系,有一个是浮点型,结果必是浮点型。
>>> 7//2 3 >>> 7.0//2 3.0 >>> 7//2.0 3.0 >>>Python 可以使用 ** 操作来进行幂运算:
>>> 5 ** 2 # 5 的平方 25 >>> 2 ** 7 # 2的7次方 128变量在使用前必须先"定义"(即赋予变量一个值),否则会出现错误:
>>> n # 尝试访问一个未定义的变量 Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'n' is not defined不同类型的数混合运算时会将整数转换为浮点数:
>>> 3 * 3.75 / 1.5 7.5 >>> 7.0 / 2 3.5在交互模式中,最后被输出的表达式结果被赋值给变量 _ 。例如:
>>> tax = 12.5 / 100 >>> price = 100.50 >>> price * tax 12.5625 >>> price + _ 113.0625 >>> round(_, 2) 113.06此处, _ 变量应被用户视为只读变量。
数学函数
函数 返回值 ( 描述 ) abs(x) 返回数字的绝对值,如abs(-10) 返回 10 ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5 cmp(x, y)
如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。 exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0 floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4 log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0 max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。 min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。 modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 pow(x, y) x**y 运算后的值。 round(x [,n]) 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。
其实准确的说是保留值将保留到离上一位更近的一端。
sqrt(x) 返回数字x的平方根。
随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
Python包含以下常用随机数函数:
函数 描述 choice(seq) 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 random() 随机生成下一个实数,它在[0,1)范围内。 seed([x]) 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 shuffle(lst) 将序列的所有元素随机排序 uniform(x, y) 随机生成下一个实数,它在[x,y]范围内。
三角函数
Python包括以下三角函数:
函数 描述 acos(x) 返回x的反余弦弧度值。 asin(x) 返回x的反正弦弧度值。 atan(x) 返回x的反正切弧度值。 atan2(y, x) 返回给定的 X 及 Y 坐标值的反正切值。 cos(x) 返回x的弧度的余弦值。 hypot(x, y) 返回欧几里德范数 sqrt(x*x + y*y)。 sin(x) 返回的x弧度的正弦值。 tan(x) 返回x弧度的正切值。 degrees(x) 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 radians(x) 将角度转换为弧度
数学常量
常量 描述 pi 数学常量 pi(圆周率,一般以π来表示) e 数学常量 e,e即自然常数(自然常数)。

字符串类型
- 用 ‘’或 ""包裹的信息 就是字符串
- 字符串中可以包含任意字符:如字母,数字,符号,且没有先后顺序
- 在python中,使用str 来代表字符串类型,并且通过该函数可以定义字符串
- 字符串不可改变!通过内置函数id,我们会发现,给变量重新换一个值后,变量名是没有变,但是在这个变量在内存中的地址已经变了 id(重新赋值后的变量)
- 通过内置函数len可以返回字符串的长度 len(字符串/变量名)
声明字符串
#声明字符串 name1=str('Hello') name2='world' name3="你好" name4='''中国''' #支持回车换行输入(显示)文本 name5="""台湾是中国的""" #支持回车换行输入(显示)文本
访问(截取)字符串中的值
#!/usr/bin/python var1 = 'Hello World!' var2 = "Python Gelaotou" print ("var1[0]: ", var1[0]) print ("var2[1:5]: ", var2[1:5])以上实例执行结果:
var1[0]: H var2[1:5]: ytho
字符串连接
多个字符串或者字符串类型的变量可以通过+号进行拼接
# coding:utf-8 name='张三' local='中国' man=name+local print(man) print('李四'+'北京')
print(name,local)以上实例执行结果:
张三中国 李四北京
转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。如下表:
转义字符 描述 \(在行尾时) 续行符 \\ 反斜杠符号 \' 单引号 \" 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 换行 \v 纵向制表符 \t 横向制表符 \r 回车 \f 换页 \oyy 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 \xyy 十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 \other 其它的字符以普通格式输出
字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
操作符 描述 实例 + 字符串连接 * 重复输出字符串 [] 通过索引获取字符串中字符 [ : ] 截取字符串中的一部分 in 成员运算符 - 如果字符串中包含给定的字符返回 True not in 成员运算符 - 如果字符串中不包含给定的字符返回 True r/R 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。
布尔类型与空类型
布尔类型
- 定义:真假的判断
#布尔类型定义 name_true=bool(True) name_false=bool(False) #或者 name_true=True name_false=False
- 固定值:True—>真;False—>假
- 布尔类型和数字、字符串的关系:
- int 0 —>False;非0 —>True
- float 0.0 —>False;非0.0 —>True
- str ""(空字符串) —>False;非空字符串—>True
空类型
定义:不属于任何数据类型
#空类型定义 name_false=bool(False)
- 固定值:None
- 空类型属于False的范畴
- 如果不确定类型的时候,可以用空类型
列表类型
- 列表就是队列
- 它是各种数据类型的集合,也是一种数据结构
- 列表是一种有序,且内容可重复的集合类型
- 列表中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推
- 内置函数max(取最大值)和min(取最小值),在列表中使用的时候,列表中的元素不能是多种类型,如果类型不统一,则会报错
- 空类型的列表虽然都是None,但是列表是有长度的,非空,所以空类型列表的布尔值为True
声明列表
#声明列表 names = list(['name1', 'name2']) names = ['name1', 'name2'] #常见列表类型 str_array = ['dewei', 'xiaomi', ' '] #字符串类型的列表,空格的字符串不是空字符串。 int_array = [1, 2, 3, 212] #整型列表 float_array = [1.2, 2.3, 2.25, 0.0, 0.2220] #浮点类型的列表 bool_array = [True, False, False, True] #布尔类型的列表 none_array = [None, None, None] #空类型的列表 list_array = [[1, 2, 3], [1.2, 3.1]] #列表中嵌套列表 mix_array = ['dewei', 1, 3.21, None, True] #混合列表
访问列表中的值
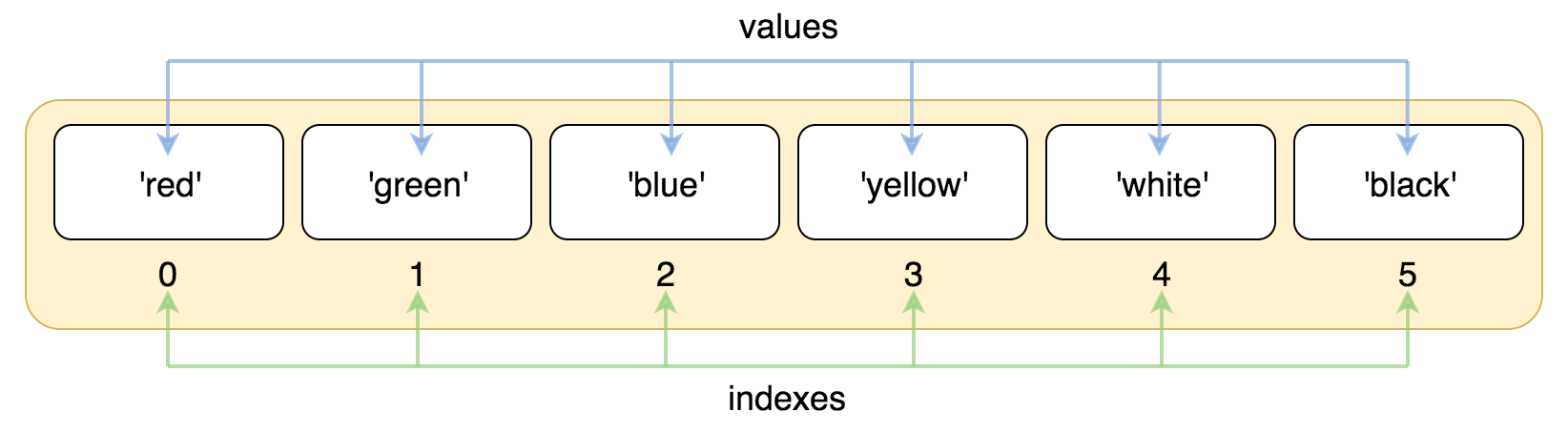
与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。
通过索引列表可以进行截取、组合等操作。
# coding:utf-8 list = ['red', 'green', 'blue', 'yellow', 'white', 'black'] print( list[0] ) print( list[1] ) print( list[2] )以上实例输出结果:
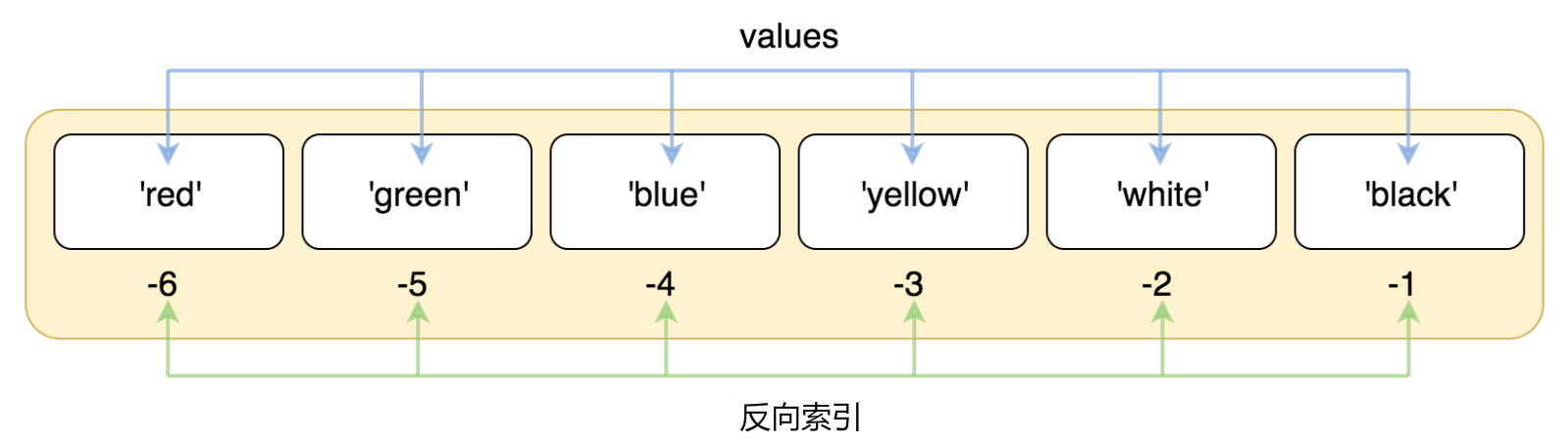
red green blue索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。
# coding:utf-8 list = ['red', 'green', 'blue', 'yellow', 'white', 'black'] print( list[-1] ) print( list[-2] ) print( list[-3] )以上实例输出结果:
black white yellow使用下标索引来访问列表中的值,同样你也可以使用方括号 [] 的形式截取字符,如下所示:
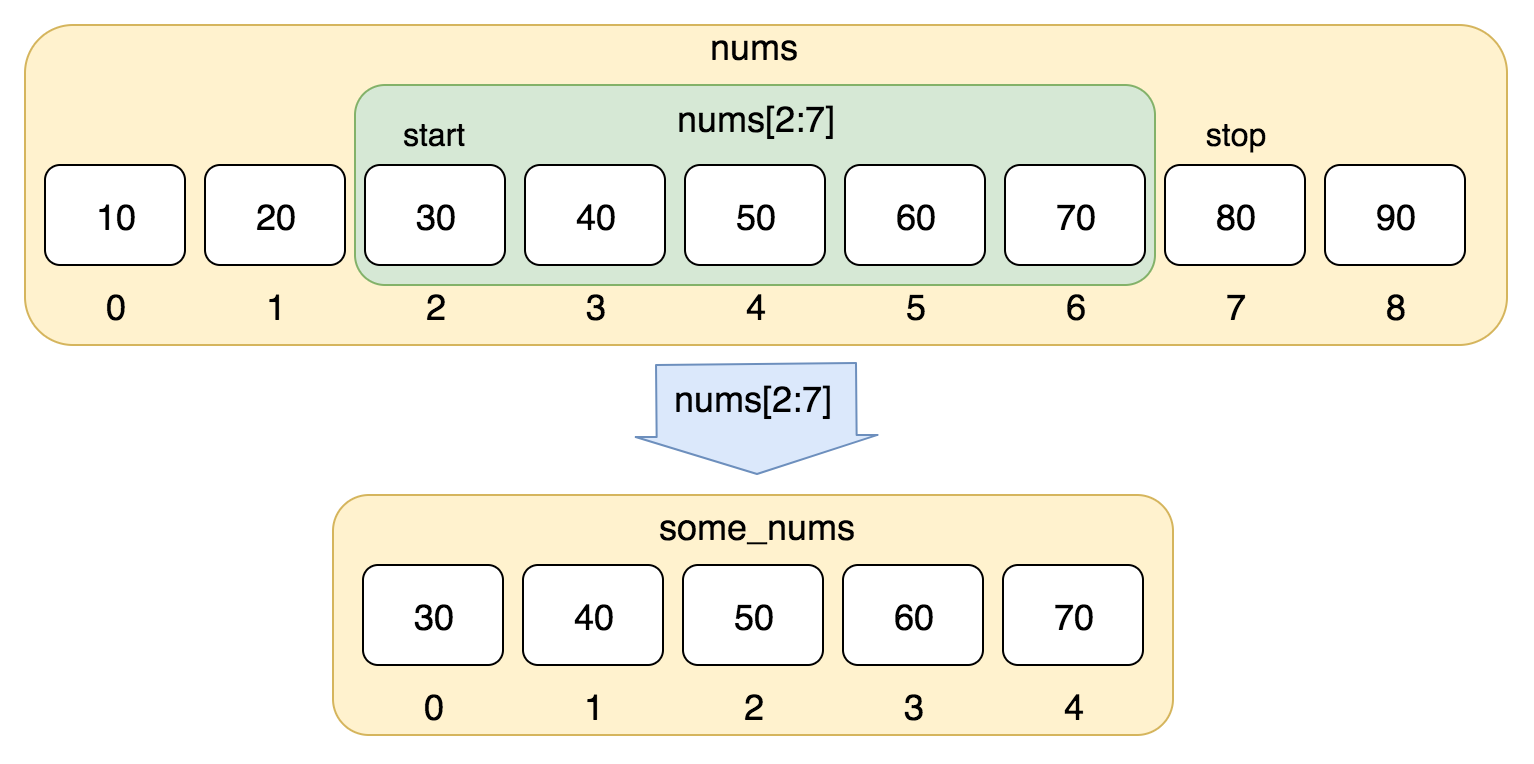
# coding:utf-8 nums = [10, 20, 30, 40, 50, 60, 70, 80, 90] print(nums[0:4])以上实例输出结果:
[10, 20, 30, 40]使用负数索引值截取:
# coding:utf-8 list = ['Google', 'Gelaotou', "Zhihu", "Taobao", "Wiki"] # 读取第二位 print ("list[1]: ", list[1]) # 从第二位开始(包含)截取到倒数第二位(不包含) print ("list[1:-2]: ", list[1:-2])以上实例输出结果:
list[1]: Gelaotou list[1:-2]: ['Gelaotou', 'Zhihu']
更新列表
可以对列表的数据项进行修改或更新,也可以使用 append() 方法来添加列表项,如下所示:
# coding:utf-8 list = ['Google', 'Gelaotou', 1997, 2000] print ("第三个元素为 : ", list[2]) list[2] = 2001 print ("更新后的第三个元素为 : ", list[2]) list1 = ['Google', 'Gelaotou', 'Taobao'] list1.append('Baidu') print ("更新后的列表 : ", list1)以上实例输出结果:
第三个元素为 : 1997 更新后的第三个元素为 : 2001 更新后的列表 : ['Google', 'Gelaotou', 'Taobao', 'Baidu']
删除列表元素
可以使用 del 语句来删除列表的的元素,如下实例:
# coding:utf-8 list = ['Google', 'Gelaotou', 1997, 2000] print ("原始列表 : ", list) del list[2] print ("删除第三个元素 : ", list)以上实例输出结果:
原始列表 : ['Google', 'Gelaotou', 1997, 2000] 删除第三个元素 : ['Google', 'Gelaotou', 2000]
列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
Python 表达式 结果 描述 len([1, 2, 3]) 3 长度 [1, 2, 3] + [4, 5, 6] [1, 2, 3, 4, 5, 6] 组合 ['Hi!'] * 4 ['Hi!', 'Hi!', 'Hi!', 'Hi!'] 重复 3 in [1, 2, 3] True 元素是否存在于列表中 for x in [1, 2, 3]: print(x, end=" ") 1 2 3 迭代
列表截取与拼接
Python的列表截取与字符串操作类型,如下所示:
L=['Google', 'Gelaotou', 'Taobao']操作:
Python 表达式 结果 描述 L[2] 'Taobao' 读取第三个元素 L[-2] 'Gelaotou' 从右侧开始读取倒数第二个元素: count from the right L[1:] ['Gelaotou', 'Taobao'] 输出从第二个元素开始后的所有元素 >>>L=['Google', 'Gelaotou', 'Taobao'] >>> L[2] 'Taobao' >>> L[-2] 'Gelaotou' >>> L[1:] ['Gelaotou', 'Taobao'] >>>列表还支持拼接操作:
>>>squares = [1, 4, 9, 16, 25] >>> squares += [36, 49, 64, 81, 100] >>> squares [1, 4, 9, 16, 25, 36, 49, 64, 81, 100] >>>嵌套列表
使用嵌套列表即在列表里创建其它列表,例如:
>>>a = ['a', 'b', 'c'] >>> n = [1, 2, 3] >>> x = [a, n] >>> x [['a', 'b', 'c'], [1, 2, 3]] >>> x[0] ['a', 'b', 'c'] >>> x[0][1] 'b'
元组类型
初识元组
- 什么是元组:元组与列表一样,都是一种可以存储多种数据类型的队列;并且元组与列表一样是一个无限制长度的数据结构
- 元组也是一个有序的,且元素可以重复的集合
- 在Python中,tuple代表着元组这种类型,也可以定义一个元组
- 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
- 内置函数max(取最大值)和min(取最小值),在元组中使用的时候,元组中的元素不能是多种类型,如果类型不统一,则会报错
元组和列表的区别
- Python的元组与列表类似,不同之处在于元组的元素不能修改,列表元素可以修改
- 元组使用小括号 ( ),列表使用方括号 [ ]
- 元组比列表占用资源更小
声明元组
#声明元组
tup0= tuple(('xiaomi', 'sky')) tup1 = ('Google', 'Gelaotou', 1997, 2000) tup2 = (1, 2, 3, 4, 5 ) tup3 = "a", "b", "c", "d" # 不需要括号也可以 type(tup3) #<class 'tuple'>创建空元组
tup1 = ()元组中只包含一个元素时,需要在元素后面添加逗号 , ,否则括号会被当作运算符使用:
>>> tup1 = (50) >>> type(tup1) # 不加逗号,类型为整型 <class 'int'> >>> tup1 = (50,) >>> type(tup1) # 加上逗号,类型为元组 <class 'tuple'>
访问元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
# coding:utf-8 tup1 = (12, 34.56) tup2 = ('abc', 'xyz') # 以下修改元组元素操作是非法的。 # tup1[0] = 100 # 创建一个新的元组 tup3 = tup1 + tup2 print (tup3)以上实例输出结果:
(12, 34.56, 'abc', 'xyz')
删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
# coding:utf-8 tup = ('Google', 'Gelaotou', 1997, 2000) print (tup) del tup print ("删除后的元组 tup : ") print (tup)以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
删除后的元组 tup : Traceback (most recent call last): File "test.py", line 8, in <module> print (tup) NameError: name 'tup' is not defined
元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
Python 表达式 结果 描述 len((1, 2, 3)) 3 计算元素个数 (1, 2, 3) + (4, 5, 6) (1, 2, 3, 4, 5, 6) 连接 ('Hi!',) * 4 ('Hi!', 'Hi!', 'Hi!', 'Hi!') 复制 3 in (1, 2, 3) True 元素是否存在 for x in (1, 2, 3): print (x,) 1 2 3 迭代
元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
tup = ('Google', 'Gelaotou', 'Taobao', 'Wiki', 'Weibo','Weixin')
Python 表达式 结果 描述 tup[1] 'Gelaotou' 读取第二个元素 tup[-2] 'Weibo' 反向读取,读取倒数第二个元素 tup[1:] ('Gelaotou', 'Taobao', 'Wiki', 'Weibo', 'Weixin') 截取元素,从第二个开始后的所有元素。 tup[1:4] ('Gelaotou', 'Taobao', 'Wiki') 截取元素,从第二个开始到第四个元素(索引为 3)。
元组内置函数
Python元组包含了以下内置函数
序号 方法及描述 实例 1 len(tuple)
计算元组元素个数。>>> tuple1 = ('Google', 'Gelaotou', 'Taobao') >>> len(tuple1) 3 >>>2 max(tuple)
返回元组中元素最大值。>>> tuple2 = ('5', '4', '8') >>> max(tuple2) '8' >>>3 min(tuple)
返回元组中元素最小值。>>> tuple2 = ('5', '4', '8') >>> min(tuple2) '4' >>>4 tuple(iterable)
将可迭代系列转换为元组。
>>> tuple1=tuple(list1)
>>> tuple1
('Google', 'Taobao', 'Gelaotou', 'Baidu')
关于元组是不可变的
所谓元组的不可变指的是元组所指向的内存中的内容不可变。
>>> tup = ('a', 'b', 'c', 'd', 'e', 'f') >>> tup[0] = 'g' # 不支持修改元素 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> id(tup) # 查看内存地址 4440687904 >>> tup = (1,2,3) >>> id(tup) 4441088800 # 内存地址不一样了从以上实例可以看出,重新赋值的元组 tup,绑定到新的对象了,不是修改了原来的对象。
字典类型
字典
字典是由多个键key及其对应的值value所组成的一种数据类型
在Python中,dict用来代表字典,并且可以创建一个字典
在Python中,通过{}将一个个key与value存入字典中
字典中每一个key一定是唯一的
- 内置函数
in可以判断key是否存在
max/min可以判断key的最大/小值
len()可以使用
- 空字典的bool为False
字典支持的数据类型
key支持字符串、数字和元祖,但是不支持列表
value支持python所有的数据类型
声明字典
emptyDict = {} #或者 emptyDict=dict() print("Length:", len(emptyDict)) print(type(emptyDict)) print(bool(emptyDict))以上实例输出结果:
Length: 0 <class 'dict'> False
访问字典里的值
# coding:utf-8 dict = {'Name': 'Student', 'Age': 7, 'Class': 'First'} print ("dict['Name']: ", dict['Name']) print ("dict['Age']: ", dict['Age'])
修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
# coding:utf-8 dict = {'Name': 'Student', 'Age': 7, 'Class': 'First'} dict['Age'] = 8 # 更新 Age dict['School'] = "家里蹲" # 添加信息 print ("dict['Age']: ", dict['Age']) print ("dict['School']: ", dict['School'])
删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
# coding:utf-8 dict = {'Name': 'Student', 'Age': 7, 'Class': 'First'} del dict['Name'] # 删除键 'Name',相当于删除了Name和Student这个键值对 dict.clear() # 清空字典 del dict # 删除字典 print ("dict['Age']: ", dict['Age']) print ("dict['School']: ", dict['School'])
字典键的特性
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住。相当于跟新了键的value值
- 键的数据类型不能使用列表;数字,字符串或元组都可以
- 值的类型支持python所有的数据类型
集合类型
- 集合(set)是一个无序的不重复元素序列。
- 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合声明
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} >>> print(basket) # 这里演示的是去重功能 {'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内 True >>> 'crabgrass' in basket False >>> # 下面展示两个集合间的运算. ... >>> a = set('abracadabra') >>> b = set('alacazam') >>> a {'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素 {'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素 {'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素 {'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素 {'r', 'd', 'b', 'm', 'z', 'l'}
集合添加元素
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作 s.add( x )
thisset = set(("a", "b", "c")) thisset.add("d") print(thisset) #{'a', 'b', 'c', 'd'}还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式 s.update( x )
thisset = set(("a", "c", "c")) thisset.update({1,3}) print(thisset) #{1, 3, 'a', 'c'} thisset.update([1,4],[5,6]) print(thisset) #{1, 3, 4, 5, 6, 'a', 'c'}
集合移除元素
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误;语法格式 s.remove( x )
thisset = set(("a", "b", "c")) thisset.remove("c") print(thisset) #{'a', 'b'} thisset.remove("d") # 不存在会发生错误 """ Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Facebook' """此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误;语法格式 s.discard( x )
thisset = set(("a", "b", "c")) thisset.discard("d") # 不存在不会发生错误 print(thisset) #{'a', 'b', 'c'}我们也可以设置随机删除集合中的一个元素,语法格式 s.pop()
thisset = set(("b", "a", "c", "d")) x = thisset.pop() print(x) #a多次执行测试结果都不一样。set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
计算集合元素个数
语法格式 len(s)
thisset = set(("a", "b", "c")) len(thisset) #3
清空集合
语法格式 s.clear()
thisset = set(("a", "b", "c")) thisset.clear() print(thisset) #结果为set()如果我想要把这个集合删掉,只需要删除集合变量即可 del 集合变量
a = set(("a", "b", "c")) del a print(a) """ Traceback (most recent call last): File print(a) NameError: name 'a' is not defined """
判断元素是否在集合中存在
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False;语法格式 x in s
thisset = set(("a", "b", "c")) "a" in thisset #True "d" in thisset #False
数据类型常用内置函数
具体详细见:https://www.runoob.com/python3/python3-built-in-functions.html
- type:返回变量/对象类型
- id:返回变量/对象内存地址
- max:返回数据中最大的成员;(中文符号 > 字母 > 数字 > 英文符号)
- min:返回数据中最小的成员;(中文符号 > 字母 > 数字 > 英文符号)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构