
C++并发编程实战 笔记
并发方式常分成多进程并发与多线程并发
多进程并发 将应用程序分为多个独立的进程同时运行,独立的进程可以通过进程就按通信渠道传递讯息(信号,套接字,文件,管道等等)。
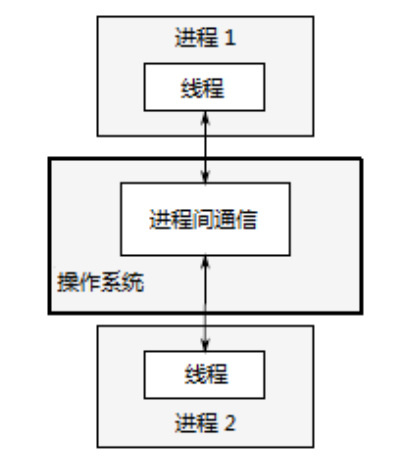
优点:操作系统对进程间提供保护和高级别的通信机制,更容易编写安全的并发代码。可通过远程链接的方式在不同的机器上运行独立的进程。
缺点:因为操作系统对进程的保护导致进程间的通信效率低,运行多个进程需要固定开销:需要时间启动进程,操作系统需要资源管理进程。
多线程并发 在单进程中运行多个线程。线程很像轻量级的进程,可以相互独立运行,且在不同的指令序列中运行。但同一进程内线程共享地址空间,且可以访问大多数数据。
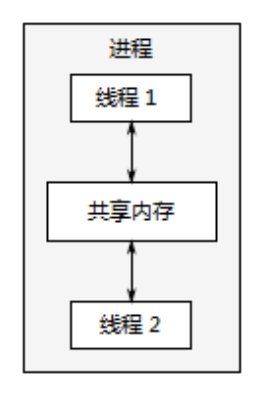
优点:由于线程间共享内存不存在数据保护,减小了操作系统记录的工作量,使多线程开销远低于多进程。
缺点:多线程开发需要对线程通信的数据一致问题做大量工作
本书只关注多线程并发。
有两种利用并发来提高性能的方式:第一,将一个单个任务分成几部分并行运行,从而降低总运行时间,这就是任务并行(task parallelism)。虽然,这听起来很直观,但是一个相当复杂的过程,因为各个部分之间可能 存在着依赖。区别可能是在过程方面——一个线程执行算法的一部分,而另一个线程执行算法的另一个部分 ——或是在处理数据——每个线程在不同的数据块上执行相同的操作(第二种方式)。后一种方法被称为数据并行(data parallelism)。
什么时候不使用并发
不使用并发的唯一原因使收益比不上成本。
1.使用并发的程序通常难以理解,将提高维护代码的额外成本;
2.性能增益小于预期,启动线程时存在固有开销,因为操作系统需要分配内核资源和堆栈空间,才能将新线程加入调度器。若实际执行时间比启动线程时间要小得多,这将导致整体性能下降。
3.假设客户端应用在对每一个链接启动独立线程时,需要处理大量链接从而生成过多线程而耗尽系统资源。这种情况将出现错误,但可使用线程池的方式对性能进行优化。
线程管理
每个程序至少有一个执行main()函数的线程,其他线程与主线程同时运行。如main()函数执行完会退出一样, 线程执行完函数也会退出。
使用C++启动线程,就是构造std::thread对象
void do_some_work();
std::thread my_thread(do_some_work);
std::thread 可以通过有函数操作符类型的实例进行构造:
class background_task
{
public:
void operator()() const
{
do_something();
do_something_else();
}
};
background_task f;
std::thread my_thread(f); //可见thread内部启动线程是通过操作符
提供的函数对象将被复制到新线程中,函数对象的执行和调用都在线程的内存空间中进行。
线程启动后是要等待线程结束,还是让其自主运行。当std::thread对象销毁之前还没有做出决定,程序就会终止(std::thread 的析构函数会调用 std::terminate())。因此,即使有异常存在们也要确保线程能够正确的汇入(joined)或分离(detached)
如果不等待线程汇入 ,就必须保证线程结束之前,访问数据的有效性。这不是一个新问题——单线程代码 中,对象销毁之后再去访问,会产生未定义行为——不过,线程的生命周期增加了这个问题发生的几率。
struct func
{
int& i;
func(int& i_) : i(i_) {}
void operator() ()
{
for (unsigned j=0 ; j<1000000 ; ++j){
{
do_something(i); // 1 潜在访问隐患:空引用
}
}
};
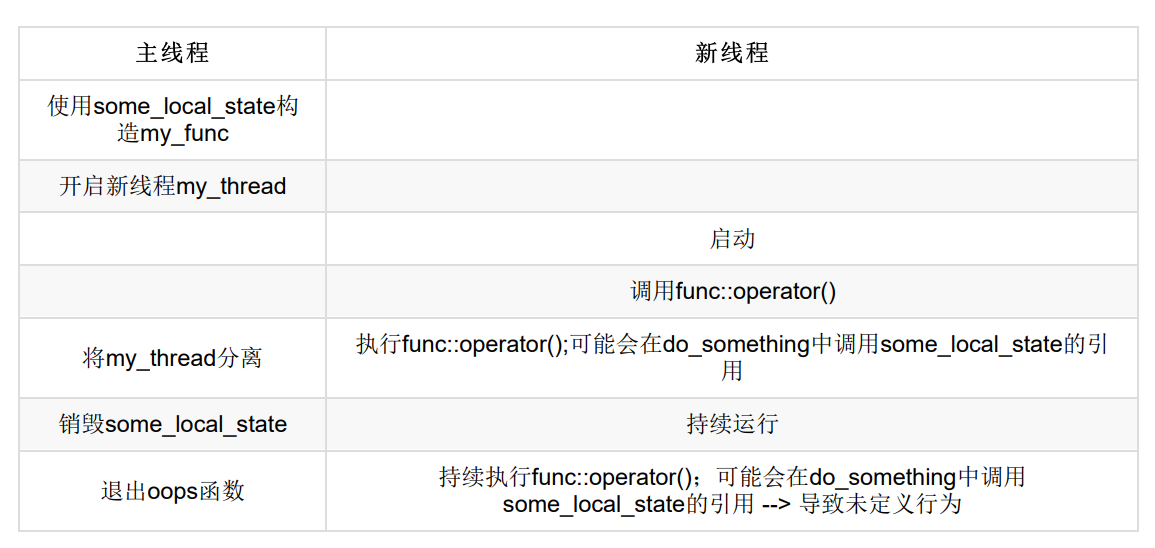
void oops()
{
int some_local_state = 0;
func my_func(some_local_state); //局部变量
std::thread my_thread(my_func);
my_thread.detach(); //不等待线程结束
}
当 oops() 函数执行完毕时,线程中函数可能仍在运行,而my_func作为局部变量已被销毁,所以线程将可能访问已经销毁的变量。
这种情况的常规处理方法:将数据复制到线程中。如果使用一个可调用的对象作为线程函数,这个对象就会 复制到线程中,而后原始对象会立即销毁。但对于对象中包含的指针和引用还需谨慎。使用访问局部变量的函数去创建线程是一个糟糕的主意。 也可以通过使用 join() 来确保线程在主函数完成前结束。
如需等待线程,需要使用join()。 调用join() 将在等待完毕后清理内存相关,join()只能被调用一次,调用后对其使用joinable()时,将返回false;
异常情况注意事项
如果想要分离线程,可以在线程启动后,直接使用detach()进行分离。如果等待线程,则需要细心挑选使用join()的位置。当在线程运行后产生的 异常,会在join()调用之前抛出,这样就会跳过join()。
避免应用被抛出的异常所终止。通常,在无异常的情况下使用join()时,需要在异常处理过程中调用join(),从而避免生命周期的问题。
struct func; //见上文
void f()
{
int some_local_state = 0;
func my_func(some_local_state);
std::thread t(my_func); //启动线程
try
{
do_some_thing_in_this_thread();
}
catch(...)
{
t.join(); //(1)
throw;
}
t.join(); //(2)
}
使用RAII(Resource Acquisition Is Initialization),提供一个类来实现上述效果,在析构函数中使用join() 。
//使用RAII等待线程完成
class thread_guard
{
std::thread& t;
public:
explict thread_guard(std::thread& t_):
t(t_)
{}
~thread_guard()
{
if(t.joinable())
{
t.join();
}
}
thread_guard(thread_guard const&)=delete; // 3
thread_guard& operator=(thread_guard const&)=delete;
};
struct func;
void f()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread t(my_func);
thread_guard g(t);
do_something_in_current_thread();
}
当f() 执行结束时,局部对象会被逆序销毁,thread_guard对象g是第一个被销毁的,线程将被加入到原始线程。即使do_something_in_current_thread抛出一个异常,这个销毁依旧会发生。
后台运行线程
使用 detach() 将使线程在后台运行,这意味着与主线程不能直接交互。如果线程分离就不可能有 std::thread 对象能引用它,分离后线程将不能汇入。C++运行库保证,当线程退出时,相关资源能被正确回收。
分离线程通常被称为守护线程(daemon threads)。线程的生命周期可能会从应用的起始到结束,分离线程只能决定线程什么时候结束,发后即忘(fire and forget)的任务使用的就是分离线程。
调用 std::thread 成员函数detach()来分离一个进程。之后,相应的std::thread对象就与实际执行的线程无关了,并且这个线程也无法汇入。
std::thread t(do_background_work);
t.detach();
assert(!t.joinable());
为了从std::thread对象中分离线程,不能对没有执行线程的std::thread对象使用detach(),并且要用同样的方法进行检查---当std::thread对象使用joinable()返回为true时,可使用detach()。
使用分离线程简单例子:让一个文字应用处理软件同时编辑多个文档。为每个文字处理窗口分配一个线程,执行相同代码。
//使用分离线程处理文档
void edit_document(std::string const& filename)
{
open_document_and_display_gui(filename);
while(!done_editing())
{
//获取输入
user_command cmd=get_user_input();
//打开新文档
if(cmd.type==open_new_document)
{
std::string const new_name=get_filename_from_user();
//分配新线程处理任务并分离
std::thread t(edit_document,new_name); // 1
t.detach(); // 2
}
else
{
process_user_input(cmd);
}
}
}
不仅可以向std::thread构造函数传递函数名,还可以传递函数所需的实参。也可以使用带有数据的成员函数替代需要传参的普通函数。
传递参数
需要注意的时,参数会被拷贝至新线程的内存空间中(同临时变量),即使函数中的参数是引用形式,拷贝操作也会被执行。
void f(int i,std::string const& s);
std::thread t(f,3,"hello");
注意!函数f需要一个std::string参数作为第二个对象,但这里使用的是字符串的字面值,也就是char const* 类型,线程上下文完成字面值向std::string类型的转换。
此处需要保证隐式转换发生在std::thread构造函数拷贝操作之前
void f(int i,std::string const& f);
void not_oops(int some_param)
{
char buffer[1024];
_get_buffer();
//1
//std::thread t(f,3,buffer);
//2
std::thread t(f,3,std::string(buffer)); //使用std::string
}
在情况1下,函数oops可能会在buffer完成对std::string 的隐式转化之前结束,导致未定义行为,所以需要保证在转递到std::thread构造函数之前,就完成所有转化,情况2;
当试图使用线程更新应用传递的数据结构时:
void update_data_for_widget(widget_id w,widget_data& data); // 1
void oops_again(widget_id w)
{
widget_data data;
std::thread t(update_data_for_widget,w,data); // 2
display_status();
t.join();
process_widget_data(data);
}
虽然update_data_for_widget期待传入一个引用类型,但std::thread构造函数并不知晓,无视了函数参数类型而进行盲目拷贝。对于可移动的类型,内部代码会以右值的方式转递参数,但因为函数期望以非常量引用为参数(而非右值)所以会在编译时出错。解决方法如下:
std::thread t(update_data_for_widget,w,std::ref(data));
这样update_data_for_widget就会收到data的引用,而非data的拷贝副本,这样代码就能顺利的通过编译。
以上传参语法与std::bind相似,也同样可以传递一个成员函数指针和一个合适的对象指针作为第一参数。
class X
{
public:
void do_lengthy_work();
};
X my_x;
std::thread t(&X::do_lengthy_work,&my_x); // 1
新线程将调用 my_x.do_lengthy_work(),其中my_x的地址作为对象指针提供函数,也可以在后续继续添加成员函数参数
class X
{
public:
void do_lengthy_work(int);
};
X my_x;int num(0);
std::thread t(&X::do_lengthy_work,&my_x,num);
转移所有权
C++标准库中有很多资源占有(resource-owning)类型。std::ifstream、std::uniqure_ptr、std::thread都是可移动但不可复制的,这就是为什么将移动操作引入 std::thread 的原因。以下例子实现了在线程间的转移所有权:
void some_function();
void some_other_function();
std::thread t1(some_function); //1
std::thread t2=std::move(t1); //2
t1 = std::thread(some_other_function); //3
std::thread t3; //4
t3 = std::move(t2); //5
t1 = std::move(t3); //6 该操作将使程序崩溃
①创建新线程_1并与t1相关联,②通过显式std::move创建t2,将t1所有权转移给t2,此时t1与新线程_1已没有任何关系。
③通过临时对象std::thread创建新线程_2,并通过临时对象隐式调用移动操作将所有权移交t1
④使用默认构造方式创建t3,并不与任何线程进行关联。⑤因为t2是一个命名对象,需要显式调用std::move。移动操作完成后t1与执行some_other_function的对象相关联,t2与任何线程都无关联,t3与执行some_function的线程相关联。
最后一个操作将some_function线程所有权给t1,但t1已经有一个关联的线程了所以系统调用std::terminate() 终止程序运行。不能通过赋予新值给std::thread来“丢弃”一个线程!
std::thread实例支持以参数进行传递与函数返回
//线程所有权可以在函数外进行转移
std::thread f()
{
void some_function();
return std::thread(some_function);
}
std::thread g()
{
void some_other_function(int);
std::thread t(some_other_function,42);
return t;
}
//线程所有权可以在函数内转移,std::thread可以作为参数进行传递
void f(std::thread t);
void g()
{
void some_function();
f(std::thread(some_function));
std::thread t(some_function);
f(std::move(t));
}
确定线程数量
std::thread::hardware_concurrency() 会返回并发线程的数量。例如,多核系统中返回值可以是CPU核芯的数量。返回值也仅仅是一个标识,当无法获取时,函数返回0。
以下为并行版std::accumulate,代码将整体工作拆分为小任务,交给每个线程去做,并设置最小任务数,避免产生太多线程,程序会在操作数量为0时抛出异常。比如,std::thread无法启动线程,就会抛出异常。
从std::thread::hardware_concurrency() 与任务实际所需进行决定。
见解决方案Case parallel_accumulate
线程标识
线程标识为std::thread::id 类型,可以通过两种方式进行检索,第一种可通过调用 std::thread 对象成员函数 get_id() 来获取。如果 std::thread对象没有与任何执行线程相关联,get_id() 将返回 std::thread::type 默认构造值,这个值表示“无线程”。第二种,当前线程中调 用 std::this_thread::get_id() (这个函数定义在 <thread> 头文件中)也可以获得线程标识。
如果两个对象的 std::thread::id 相等, 那就是同一个线程,或者都“无线程”。如果不等,那么就代表了两个不同线程,或者一个有线程,另一没有线程。
std::thread::id 对象可以用于排序比较。标准库也提供了 std::hash<std::thread::id>容器,std::thread::id也可以作为无序容器的键值。
std::thread::id 实例常用作检测线程是否需要进行一些操作。比如当用线程来分割一项工作(如代码2.9), 主线程可能要做一些与其他线程不同的工作,启动其他线程前,可以通过 std::this_thread::get_id() 得到自己的线程ID是否与初始线程ID相同。
std::thread::id master_thread;
void some_core_part_of_algorithm()
{
if(std::this_thread::get_id()==master_thread)
{
do_master_thread_work();
}
do_common_work();
}
共享数据
条件竞争
C++标准术语定义为:并发的去修改一个独立对象,数据竞争是未定义行为的起因。
以下是几种避免恶性条件竞争:
1.对数据结构采用保护机制,确保只有修改线程才能看到不变量的中间状态。从其他访问线程的角度来看,修改不是已经完成了,就是还没开始。
2.采用无锁编程,对数据结构和不变量进行修改,修改完的结构能完成一系列不可分割的变化。
3.使用软件事务内存(software transactional memory(STM)),使用事务的方式去处理数据结构的更新。
其中最基本的方式是使用互斥量。
使用互斥量
通过实例化std::mutex创建互斥量实例,成员函数lock()可对互斥量上锁,unlock()为解锁。不过不推荐直接调用成员函数,而是采用RAII模板来进行管理。
C++库内提供了RAII模板类 std::lock_guard,在构造时提供已锁的互斥量,并在析构时进行解锁。
//使用互斥量保护列表
std::list<int> some_list;
std::mutex some_mutex;
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex); // 3
some_list.push_back(new_value);
}
bool list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex); // 4
return std::find(some_list.begin(),some_list.end(),value_to_find) != some_list.end();
}
上例中add_to_list 和 list_contains 函数对数据访问是互斥的。
这是面向对象设计的准则:将其放在一个类中,就可让他们联系在一起,也可对类的功能进行封装,并进行数据保护。这种情况下,函数add_to_list和list_contains可以作为这个类的成员函数。互斥量和需要保护的数据,在类中都定义为private成员,这会让代码更清晰,并且方便了解什么时候对互斥量上锁。
对于 C++17后的编译器也可使用 std::scoped_lock guard(some_mutex)
切勿将未受保护的指针或引用传递到互斥锁作用域之外!
条件竞争不仅可能发生在对同一数据的并发修改,也可能发生在会发生在接口间的条件竞争
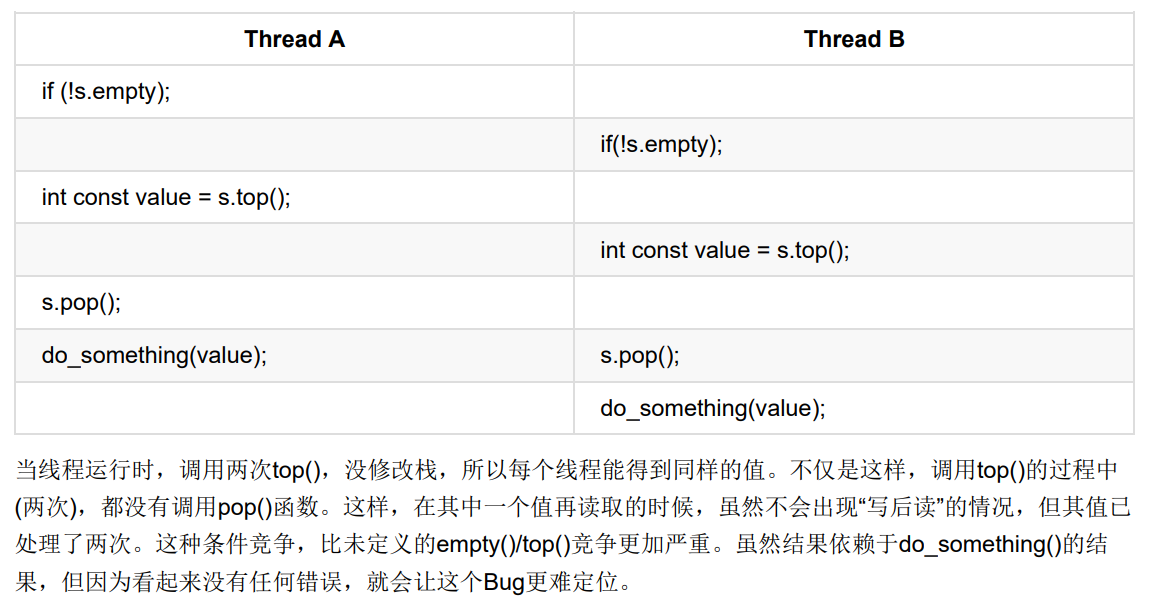
stack<int> s;
if(!s.empty()) //1
{
int const value = s.top(); //2
s.pop(); //3
do_something(value);
}
在调用empty()①和调用top()②之间可能有来自另一个线程的pop()调用并删除了最后一个元素。即使使用互斥量对栈内部数据进行保护,但依旧不能阻止条件竞争的发生。
死锁问题
当多个互斥量相互等待时就会出现,将没有线程能继续工作。为避免死锁的最基础做法,让两个互斥量以相同的顺序上锁:总在互斥量B之前锁住互斥量A
但当有多个互斥量保护同一个类的独立实例时,一个操作对同一个类的两个不同实例进行数据的交换操作,仍有可能造成死锁。
可用C++标准库中std::lock ---一次性锁住多个互斥量,并没有副作用(死锁风险)。
class some_big_object;
void swap(some_big_object& lhs,some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs,X& rhs)
{
if(&lhs == &rhs)
return ;
std::lock(lhs.m,rhs,m);
std::lock_guard<std::mutex> lock_a(lhs.m,std::adopt_lock);
std::lock_guard<std::mutex> lock_a(rhs.m,std::adopt_lock);
swap(lhs.some_detail,rhs.some_detail);
}
};
先使用std::lock()锁住两个互斥量,并创建两个std::lock_guard实例,提供std::adopt_lock 参数标识将锁托管给std::lock_guard实例。
也可使用 C++ 17下支持的RAII模板类型,与std::lock_guard<>的功能相同,该类型可以接受不定数量的互斥量类型作为模板参数,以及相应的互斥量作为构造函数,构造时上锁,析构时解锁。
void swap(X& lhs,X& rhs)
{
if(&lhs == &rhs)
return;
std::scoped_lock guard(lhs.m,rhs.m);
swap(lhs.some_detail,rhs.some_detail);
}
这里使用了 C++17的隐式参数模板类型推导机制,与下行等价。
std::scoped_lock<std::mutex,std::mutex> guard(lhs.m,rhs.m);
死锁通常是对锁的使用不当造成。无锁的情况下两个线程 std::thread 对象相互调用join() 就能造成死锁。以下为几种避免死锁的方法:
避免嵌套锁
当线程获得一个锁的时候,别再去获取另一个,当需要获取多个锁时,用std::scoped_lock() 和 std::lock() 去做。
避免在持有锁时调用外部代码
外部代码无法直观确定,在持有锁时,若外部代码要获取一个锁就会违反上一条意见,但有时这是不可避免地。
使用固定顺序去获取锁
但硬性要求获取两个或两个以上的锁时,不能使用 std::lock 单独操作来获取他们时,尽可能的在每个线程上使用固定的顺序去获取它们。
使用层次锁结构
std::unique_lock 是更灵活的一种RAII模板类,可以支持立刻锁定,延迟锁定,尝试锁定,定时尝试锁定以及移动语义转移互斥量所有权等等。
std::unique_lock 在不同域中转递:
std::unique_lock<std::mutex> get_lock()
{
extern std::mutex some_mutex;
std::unique_lock<std::mutex> lk(some_mutex);
prepare_data();
return lk;
}
void process_data()
{
std::unique_lock<std::mutex> lk(get_lock()); // 2
do_something();
}
保护共享数据的方式
保护共享数据的初始化
在单线程代码中常见的延迟初始化
std::shared_ptr<some_resource> resource_ptr;
void foo()
{
if(!resource_ptr)
{
resource_ptr.reset(new some_resource); // 1
}
resource_ptr->do_something();
}
多线程代码中,只有1处需要保护,这样就能保证共享数据的初始化是安全的。
但以如下这种直接使用互斥量将使得线程资源产生不必要的序列化,为了确定数据源已经初始化,每个线程必须等待互斥量。
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;
void foo()
{
std::unique_lock<std::mutex> lk(resource_mutex); // 所有线程在此序列化
if(!resource_ptr)
{
resource_ptr.reset(new some_resource); // 只有初始化过程需要保护
}
lk.unlock();
resource_ptr->do_something();
}
其中双重检查锁定模式是具有数据竞争的。 C++和双重检查锁定模式(DCLP)的风险
对此C++标准库提供了std::once_flag 和 std::call_once 来处理这种情况,比起锁住互斥量并显式的检查指针,使用 std::call_once 初始化将消耗更少的资源。
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag; //1
void init_resource()
{
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag,init_resource); // 可以完整的进行一次初始化
resource_ptr->do_something();
}
std::call_once 也可以用于类成员延迟初始化类型成员(线程安全)。(传成员函数指针 + 成员实例指针)
class X
{
private:
connection_info connection_details;
connection_handle connection;
std::once_flag connection_init_flag;
void open_connection()
{
connection=connection_manager.open(connection_details);
}
public:
X(connection_info const& connection_details_):
connection_details(connection_details_)
{}
void send_data(data_packet const& data) // 1
{
std::call_once(connection_init_flag,&X::open_connection,this); // 2
connection.send_data(data);
}
data_packet receive_data() // 3
{
std::call_once(connection_init_flag,&X::open_connection,this); // 2
return connection.receive_data();
}
};
在不支持C++11的编译器上,局部的static类型的初始化具有条件竞争——抢着去定义这个变量。但在C++11标准中,初始化和定义完全在一个线程中发生,并且没有其他线程可在初始化完成前对其进行处理,竞争将终止于初始化阶段。
class my_class;
my_class& get_my_class_instance()
{
static my_class instance;
return instance;
}
C++17提供了std::shared_mutex和std::shared_timed_mutex,C++14提供了std::shared_timed_mutex 这些互斥量被称为读者-作者锁。std::shared_mutex有更高的性能优势,std::shared_timed_mutex 有更多的操作方法。对于无需修改数据类型结构的线程,可以使用std::shared_lock<std::shared_mutex>获取访问权。
使用std::shared_mutex对数据结构进行保护
class dns_entry;
class dns_cache
{
std::map<std::string,dns_entry> entries;
mutable std::shared_mutex entry_mutex;
public:
//读
dns_entry find_entry(std::string const& domain) const
{
std::shared_lock<std::shared_mutex> lk(entry_mutex);
std::map<std::string,dns_entry>::const_iterator const it=
entries.find(domain);
return (it==entries.end())?dns_entry():it->second;
}
//写
void update_or_add_entry(std::string const& domain,dnx_entry const& dns_details)
{
std::lock_guard<std::shared_mutex> lk(entry_mutex);
entries[domain]=dns_details;
}
}
当share_lock锁定时,同使用share_lock操作的线程不会阻塞,使用unique_lock\lock_guard锁定时,任何关于该锁操作的非本线程线程都会阻塞。
嵌套锁
线程对已经获取的 std::mutex(已经上锁)再次上锁是错误的,尝试这样做将导致未定义行为。在某些情况下,一个线程会尝试释放一个互斥量前多次获取。因此,C++标准库提供了std::recursive_mutex类。除了可以在同一线程的单个实例多次上锁,其他功能和std::mutex相同。
线程同步操作
C++标准库提供了条件变量(condition variables) 和 future 来进行线程间的同步。
在等待线程在检查间隙,可使用std::this_thread::sleep_for()进行周期性间歇
bool flag;
std::mutex m;
void wair_for_flag()
{
std::unique_lock<std::mutex> lk(m);
while(!flag)
{
lk.unlock(); // 1 解锁互斥量
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 2 休眠100ms
lk.lock(); // 3 再锁互斥量
}
}
循环中,休眠前②函数对互斥量进行解锁①,并且在休眠结束后再对互斥量上锁,所以另外的线程就有机会获取锁并设置标识。
更为优先的选择是使用C++标准库的工具去等待事件的发生。通过另一线程触发等待事件的 机制是最基本的唤醒方式(例如:流水线上存在额外的任务时),这种机制就称为“条件变量”。
C++标准库对条件变量有两套实现:std::condition_variable 和 std::condition_variable_any。两者都需要与互斥量一起才能工作,前者只能与std::mutex一起工作,后者可以和合适的互斥量进行工作,所以加上了 _any 的前缀。同样是前者更为高效后者更为灵活。
使用std::condition_variable处理数据等待
std::mutex mut;
std::queue<data_chunk> data_queue; //1
std::condition_variable data_cond;
void data_preparation_thread()
{
while(more_data_to_prepare())
{
data_chunk const data = prepare_data();
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data); //2
data_cond.notify_one(); //3
}
}
void data_processing_thread()
{
while(true)
{
std::unique_lock<std::mutex> lk(mut); // 4
data_cond.wait(lk,[]{return !data_queue.empty();});//5
data_chunk data=data_queue.front();
data_queue.pop();
lk.unlock(); // 6
process(data);
if(is_last_chunk(data))
break;
}
}
首先,队列中中有两个线程,两个线程之间会对数据进行传递①。数据准备好时,使用 std::lock_guard 锁定 队列,将准备好的数据压入队列②之后,线程会对队列中的数据上锁,并调用 std::condition_variable 的 notify_one()成员函数,对等待的线程(如果有等待线程)进行通知③。
另外的一个线程正在处理数据,线程首先对互斥量上锁(这里使用std::unique_lock要比std::lock_guard④更加 合适)。之后会调用 std::condition_variable 的成员函数wait(),传递一个锁和一个Lambda表达式(作为等待的 条件⑤),的Lambda函数 []{return !data_queue.empty();} 会去检查data_queue是 否为空,当data_queue不为空,就说明数据已经准备好了。
wait()会去检查这些条件(通过Lambda函数),当条件满足(Lambda函数返回true)时返回。如果条件不满足 (Lambda函数返回false),wait()将解锁互斥量,并且将线程(处理数据的线程)置于阻塞或等待状态。
wait将先上锁然后进行条件判断,获得 true 时候将继续,获得 false 时将解锁并阻塞,直到获得成员函数notify_one()通知,重新上锁并进行条件检测。
构建线程安全队列
见multi-thread-template thread_safe_queue
使用future事件
future就像将任务托管给另一个线程,而主线程可以做其他事情,直到需要获得托管的任务结果时。若任务已经完成则可以直接获取结果,否则阻塞知道获取结果。
C++标准库中有两种future,声明在<future>头文件中,unique future(std::future<>)和shared futures(std::shared_future<>),与std::unique_ptr和std::shared_ptr非常类似。std::future 只能与指定事件关联,而std::shared_future能关联多个事件。
当不着急让任务结果时,可以使用 std::async 启动一个异步任务。与std::thread对象等待的方式不同, std::async 会返回一个 std::future对象,这个对象持有最终计算出来的结果。当需要这个值时,只需要调用这个对象的get()成员函数,就会阻塞线程直到future为就绪为止,并返回计算结果。
#include <future>
#include <iostream>
int find_the_answer_to_ltuae();
void do_other_stuff();
int main()
{
std::future<int> the_answer=std::async(find_the_answer_to_ltuae);
do_other_stuff();
std::cout<<"The answer is "<<the_answer.get()<<std::endl;
}
std::async 传参方式与 std::thread 类似,可以传入成员函数指针与具体对象及其参数,当参数为右值时使用移动的方式转移原始数据。
#include <string>
#include <future>
struct X
{
void foo(int,std::string const&);
std::string bar(std::string const&);
};
X x;
auto f1=std::async(&X::foo,&x,42,"hello"); // 调用p->foo(42,"hello"),p是指向x的指针
auto f2=std::async(&X::bar,x,"goodbye"); // 调用tmpx.bar("goodbye"), tmpx是x的拷贝副本
大多数情况下可以在函数调用之前向std::async传递一个额外参数,这个参数的类型是std::launch ,std::launch::defered表明函数调用延迟到wait()或者get()函数调用时才执行,std::launch::async表明函数必须在其所在的独立线程上执行。
auto f6=std::async(std::launch::async,Y(),1.2); // 在新线程上执行
auto f7=std::async(std::launch::deferred,baz,std::ref(x)); // 在wait()或
get()调用时执行
auto f8=std::async(std::launch::deferred | std::launch::async,baz,std::ref(x)); // 实现选择执行方式
auto f9=std::async(baz,std::ref(x));
f7.wait(); // 调用延迟函数
future与任务关联
std::packaged_task<> 将future与函数活可调用对象进行绑定。当调用std::packaged_task对象时,就会调用相关函数和可调用对象,当future状态为就绪时就会储存返回值。
std::packaged_task<>的模板参数是一个函数签名,构造std::packaged_task<>实例时,就必须传入函数或可调用对象。函数签名参数可隐式转换。可以用int类型参数和返回float类型的函数,来构建 std::packaged_task<double<double>> 实例。
从包装可调用对象的意义来讲,std::packaged_task 与 std::function 类似,只不过std::packaged_task 将其包装的可调用的执行结果传递给了一个std::future对象。
使用std::promises
std::promise<T>提供设定值的方式,与std::future<T>对象相关联。std::promise/std::future对提供一种机制:future可以阻塞等待线程,提供数据的线程可以使用promise对相关值进行设置,并将future的状态置为“就绪”。
可以通过给定的 std::promise 的get_future()成员函数来获取与之相关的std::future 对象, 与std::packaged_task的用法类似。当promise设置完毕(使用set_value()成员函数)时,对应的future状态就变 为“就绪”,并且可用于检索已存储的值。
future将储存抛出的错误
当调用抛出一个异常时,这个异常就会存储到future中,之后future的状态置为“就绪”,之后调用get()会抛出已存储的异常。
对于std::promise,当存入的是异常而非数值时,就需要调用set_exception 而非set_value()。这通常使用在一个 catch 块中
extern std::promise<double> some_promise;
try{
some_promise.set_value(calculate_value());
}
catch(...)
{
some_promise.set_exception(std::current_exception());
}
可用std::copy_exception()作为替代方 案,std::copy_exception() 会直接存储新的异常而不抛出:
some_promise.set_exception(std::copy_exception(std::logic_error("foo ")));
这比使用try/catch块更加清晰,当异常类型已知,就应该优先使用。不是因为代码实现简单,而是给编译器提 供了极大的优化空间。
使用超时
使用超时的最简单方式,就是对特定线程添加延迟处理。当线程无所事事时,就不会占用其他线程的处理时间。
std::this_thread::sleep_for() 和 std::this_thread::sleep_until()
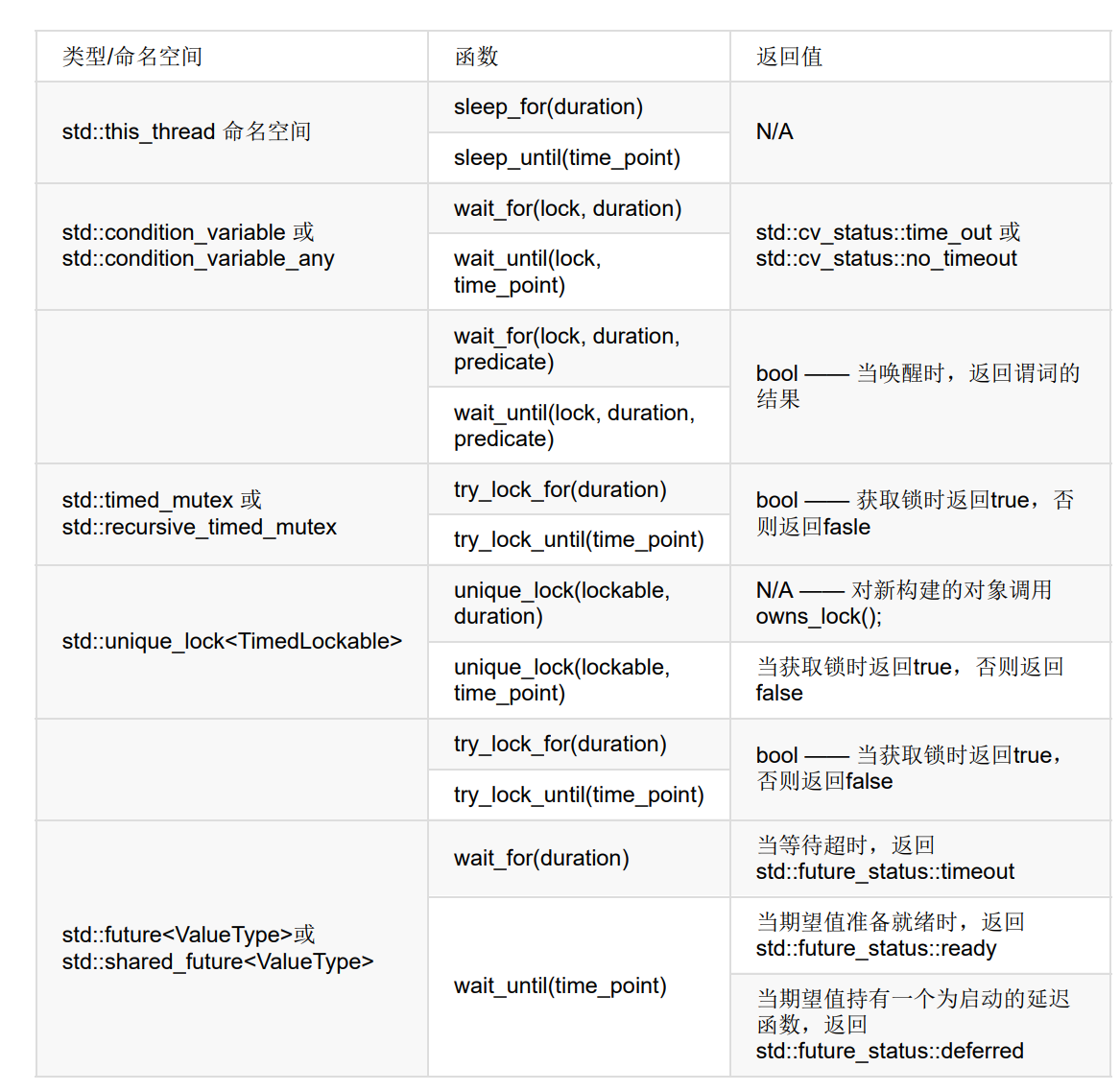
使用future的函数式编程
串行版本快速排序:
template<typename T>
std::list<T> sequential_quick_sort(std::list<T> input)
{
if(input.empty())
{
return input;
}
std::list<T> result;
result.splice(result.begin(),input,input.begin()); // 1
T const& pivot=*result.begin(); // 2
auto divide_point=std::partition(input.begin(),input.end(),
[&](T const& t){return t<pivot;}); // 3
std::list<T> lower_part;
lower_part.splice(lower_part.end(),input,input.begin(),
divide_point); // 4
auto new_lower(
sequential_quick_sort(std::move(lower_part))); // 5
auto new_higher(
sequential_quick_sort(std::move(input))); // 6
result.splice(result.end(),new_higher); // 7
result.splice(result.begin(),new_lower); // 8
return result;
}
使用future的并行版快速排序
template<typename T>
std::list<T> parallel_quick_sort(std::list<T> input)
{
if(input.empty())
{
return input;
}
std::list<T> result;
result.splice(result.begin(),input,input.begin());
T const& pivot=*result.begin();
auto divide_point=std::partition(input.begin(),input.end(),
[&](T const& t){return t<pivot;});
std::list<T> lower_part;
lower_part.splice(lower_part.end(),input,input.begin(),
divide_point);
std::future<std::list<T> > new_lower( // 1
std::async(¶llel_quick_sort<T>,std::move(lower_part)));
auto new_higher(
parallel_quick_sort(std::move(input))); // 2
result.splice(result.end(),new_higher); // 3
result.splice(result.begin(),new_lower.get()); // 4
return result;
}
比起使用 std::async() ,可以写一个spawn_task()函数对 std::packaged_task 和 std::thread 做一下包装。
其本身并没有太多优势(事实上会造成大规模的超额任务),但可为转型成一个更复杂的实现进行 铺垫,实现会向队列添加任务,而后使用线程池的方式来运行。 std::async更适合于已知所有任务的情况, 并且要能完全控制线程池中构建或执行过任务的线程。
spawn_task的简单实现
template<typename F,typename A>
std::future<std::result_of<F(A&&)>::type>
spawn_task(F&& f,A&& a)
{
typedef std::result_of<F(A&&)>::type result_type;
std::packaged_task<result_type(A&&)>
task(std::move(f)));
std::future<result_type> res(task.get_future());
std::thread t(std::move(task),std::move(a));
t.detach();
return res;
}
函数化编程可算作是并发编程的范型,并且也是通讯顺序进程(CSP,Communicating Sequential Processer)的范型,这里的线程没有共享数据,但有通讯通道允许信息在不同线程间进行传递。
基于参与者设计模式实现简单ATM逻辑
使用状态机建模
struct card_inserted
{
std::string account;
};
class atm
{
messaging::receiver incoming;
messaging::sender bank;
messaging::sender interface_hardware;
void (atm::*state)();
std::string account;
std::string pin;
void waiting_for_card() // 1
{
interface_hardware.send(display_enter_card()); // 2
incoming.wait(). // 3
handle<card_inserted>(
[&](card_inserted const& msg) // 4
{
account=msg.account;
pin="";
interface_hardware.send(display_enter_pin());
state=&atm::getting_pin;
}
);
}
void getting_pin();
public:
void run() // 5
{
state=&atm::waiting_for_card; // 6
try
{
for(;;)
{
(this->*state)(); // 7
}
}
catch(messaging::close_queue const&)
{
}
}
};
这里无需考虑同步和并发 问题,只需要考虑什么时候接收和发送信息即可。为ATM逻辑所设的状态机运行在 独立的线程上,比如:与银行通讯的接口,以及运行在独立线程上的终端接口。
这些参与者会互相发送信息,去执行手头上的任务,并且不会共享状态,除非是通过信息直接传入的。
使用锁存器 latch 实现事件同步
构造 std::latch 时,将计数器的值作为构造函数的唯一参数。当等待的事件发生,就会调用锁存器 count_down 成员函数。 当计数器为0时,锁存器状态将变为就绪。可以调用wait成员函数对锁存器进行阻塞,知道等待锁存器处于就绪。可调用is_ready成员函数判断是否就绪,想要计数器减少1并阻塞直至0,可调用count_down_and_wait;
void foo(){
unsigned const thread_count=...;
latch done(thread_count); // 1
my_data data[thread_count];
std::vector<std::future<void> > threads;
for(unsigned i=0;i<thread_count;++i)
threads.push_back(std::async(std::launch::async,[&,i]{ // 2
data[i]=make_data(i);
done.count_down(); // 3
do_more_stuff(); // 4
}));
done.wait(); // 5
process_data(data,thread_count); // 6
} // 7
使用栅栏 barrier 实现阻挡
std::barrier 更为简单,开销更低,std::flex_barrier 更灵活,开销较大。
使用 std::barrier 实现线程同步
result_chunk process(data_chunk);
std::vector<data_chunk>
divide_into_chunks(data_block data, unsigned num_threads);
void process_data(data_source &source, data_sink &sink) {
unsigned const concurrency = std::thread::hardware_concurrency();
unsigned const num_threads = (concurrency > 0) ? concurrency : 2;
std::experimental::barrier sync(num_threads);
std::vector<joining_thread> threads(num_threads);
std::vector<data_chunk> chunks;
result_block result;
for (unsigned i = 0; i < num_threads; ++i) {
threads[i] = joining_thread([&, i] {
while (!source.done()) { // 6
if (!i) { // 1
data_block current_block =
source.get_next_data_block();
chunks = divide_into_chunks(
current_block, num_threads);
}
sync.arrive_and_wait(); // 2
result.set_chunk(i, num_threads, process(chunks[i])); // 3
sync.arrive_and_wait(); // 4
if (!i) { // 5
sink.write_data(std::move(result));
}
}
});
}
} // 7
std::flex_barrier更为灵活,具有一个额外的构造函数,需要传入一个完整的函数和线程数量,当所有线程都到达栅栏处那么这个函数就由其中一个线程运行。并提供了一种修改下一个周期到达栅栏处线程个数的方式。
使用 std::flex_barrier 实现线程同步
void process_data(data_source &source, data_sink &sink) {
unsigned const concurrency = std::thread::hardware_concurrency();
unsigned const num_threads = (concurrency > 0) ? concurrency : 2;
std::vector<data_chunk> chunks;
auto split_source = [&] { // 1
if (!source.done()) {
data_block current_block = source.get_next_data_block();
chunks = divide_into_chunks(current_block, num_threads);
}
};
split_source(); // 2
result_block result;
std::experimental::flex_barrier sync(num_threads, [&] { // 3
sink.write_data(std::move(result));
split_source(); // 4
return -1; // 5
});
std::vector<joining_thread> threads(num_threads);
for (unsigned i = 0; i < num_threads; ++i) {
threads[i] = joining_thread([&, i] {
while (!source.done()) { // 6
result.set_chunk(i, num_threads, process(chunks[i]));
sync.arrive_and_wait(); // 7
}
});
}
}
返回值-1表示线程数目保持不变,返回值为0或 其他数值则指定的是下一个周期中参与迭代的线程数量。
原子操作☢️
原子操作时不可分割的操作,是操作的最小单位。如果读取对象的加载操作是原子的,那么这个对象的所有修改操作也是原子的。
原子类型不可被拷贝构造和拷贝赋值。拷贝构造和拷贝赋值都会将第一个对象的值 进行读取,然后再写入另外一个。对于两个独立的对象,这里就有两个独立的操作了,合并这两个操作必定 是不原子的。因此,操作就不被允许。
标准原子类型定义在头文件<atomic> 中。原子操作几乎含有is_lock_free 成员函数,可以让用户查询该原子操作是直接使用原子指令 (x.is_lock_free()返回true)还是内部使用了锁结构(返回false)
原子操作可以替代互斥量实现同步操作。如果由原子操作需求,最好使用不基于互斥量的实现。
C++17中所有原子类型都含有一个static constexpr成员变量,如果相应硬件上原子类型X是无锁类型,那么X::is_always_lock_free将返回true
只有 std::atomic_flag 类型不提供 is_lock_free()。该类型是一个简单的布尔标志,并且在这种类型上的操作都是无锁的。
标准原子类型的备选名和与其相关的 std::atomic<> 特化类
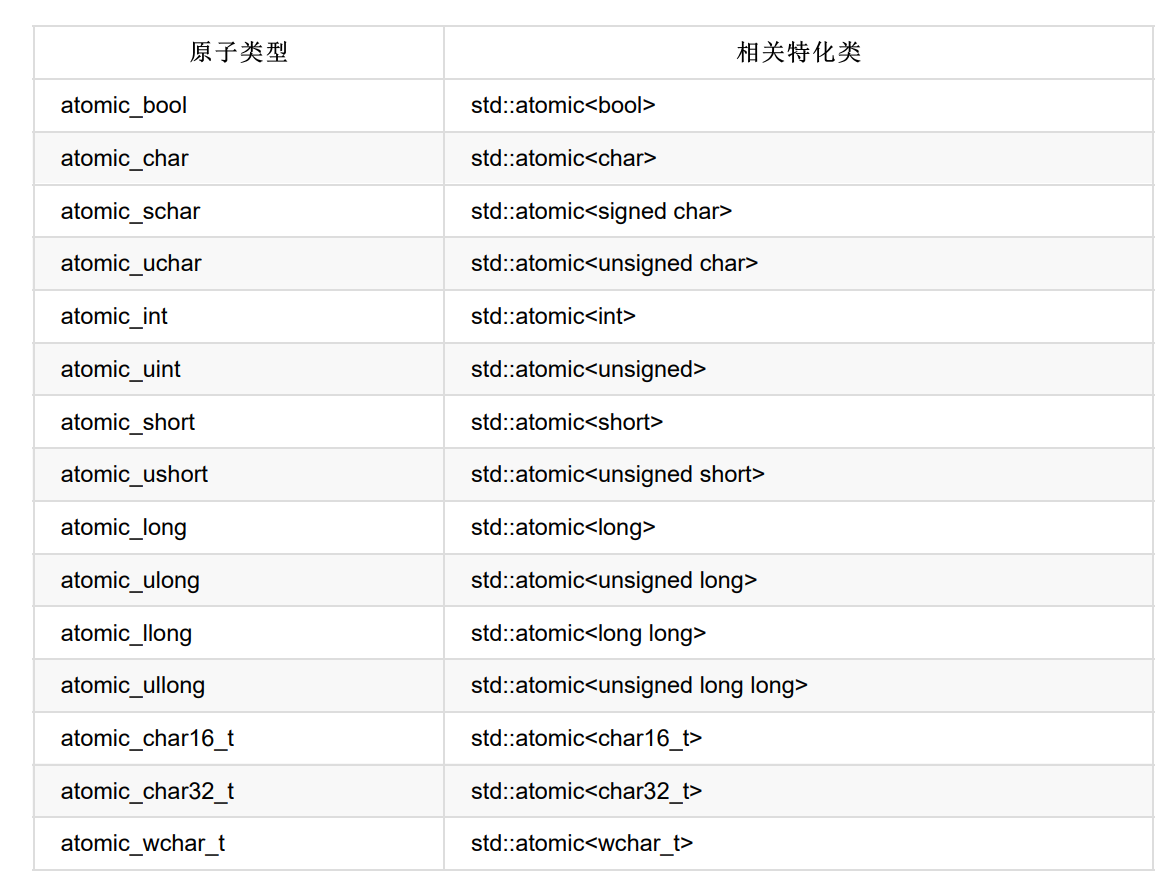
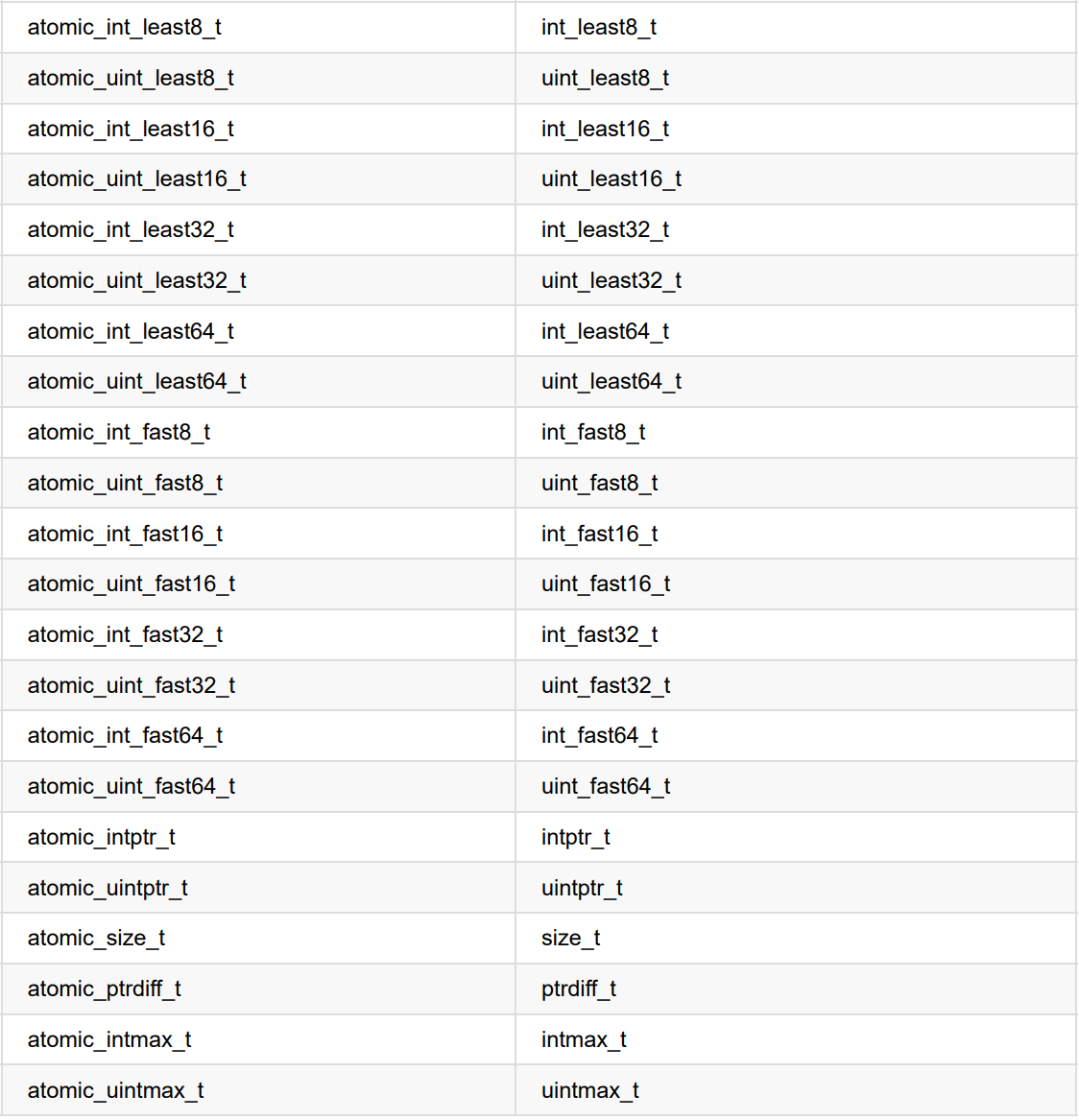
标准原子类型定义(typedefs)和对应的内置类型定义(typedefs)
对于标准类型进行typedef T,相关的原子类型就在原来的 类型名前加上atomic_的前缀:atomic_T。除了singed类型的缩写是s,unsigned的缩写是u,和long long的缩 写是llong之外,这种方式也同样适用于内置类型。对于std::atomic模板,使用相应的T类型去特化模板的 方式,要好于使用别名的方式。
通常,标准原子类型不能进行拷贝和赋值,它们没有拷贝构造函数和拷贝赋值操作符。但是,可以隐式转化 成对应的内置类型,所以这些类型依旧支持赋值,可以使 用 load() 和store() 、 exchange() 、 compare_exchange_weak() 和 compare_exchange_strong() 。
std::atomic<> 类模板不仅仅是一套可特化的类型,作为原发模板也可以使用自定义类型创建对应的原子变 量。因为是通用类模板,操作限制为 load() , store() (赋值和转换为用户类 型),exchange(), compare_exchange_weak() 和compare_exchange_strong()。
原子操作分为三类:
Store操作,可选如下内存序 : memory_order_relaxed , memory_order_release , memory_order_seq_cst 。
Load操作,可选如下内存序: memory_order_relaxed , memory_order_consume ,memory_order_acquire, memory_order_seq_cst 。
Read-modify-write(读-改-写)操作,可选如下内存序: memory_order_relaxed ,memory_order_consume, memory_order_acquire ,memory_order_release, memory_order_acq_rel , memory_order_seq_cst 。
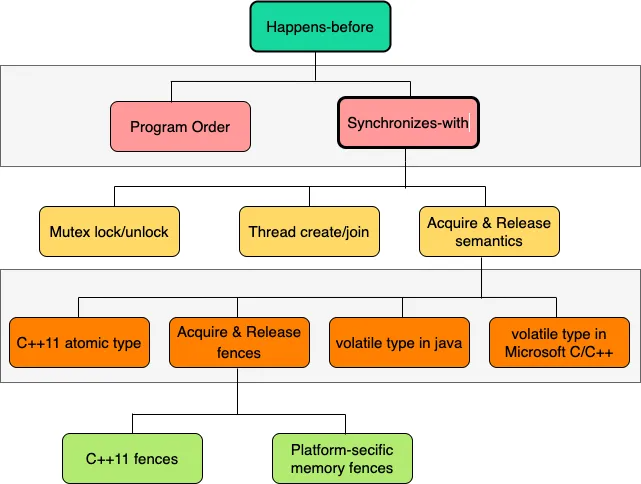
Sequential consistency 是顺序一致性模型对应约束符号为memory_order_seq_cst,是控制粒度最为严格的内存模型,也是std::atomic的默认模型
- 每个线程的执行顺序与代码顺序严格一致
- 线程间执行顺序可能交替进行,但对于单个线程来看仍然是顺序执行
- 顺序一致性的所有操作都按照代码指定的顺序进行,符合开发人员的思维逻辑,但这种严格的排序也限制了现代CPU利用硬件进行并行处理的能力,会严重拖累系统的性能。
Relax 模型对应 memory_order_relaxed ,这种类型只能保证当前的数据访问时原子操作(不会被其他线程的操作打断),但对内存访问顺序没有任何约束,对不同数据的读写可能会被重新排序。该类型常用于统计计数。
Acquire-Release 模型对应 memory_order_consume 、 memory_order_acquire 、memory_order_release 和 memory_order_acq_rel。
- Acquire:如果一个操作X带有acquire语义,那么在操作X后的所有读写指令都不会被重排序到操作X之前
- Release:如果一个操作X带有release语义,那么在操作X前的所有读写指令操作都不会被重排序到操作X之后
假设有一个原子变量A,对A的写操作(Release)和读操作(Acquire)之间进行同步,并建立排序约束关系,即对于写操作(release)X,在写操作X之前的所有读写指令都不能放到写操作X之后;对于读操作(acquire)Y,在读操作Y之后的所有读写指令都不能放到读操作Y之前。
memory_order_release
假设有一个原子变量A,对其进行写操作X的时候施加了memory_order_release约束符,则在当前线程T1中,该操作X之前的任何读写操作指令都不能放在操作X之后。当另外一个线程T2对原子变量A进行读操作的时候,施加了memory_order_acquire约束符,则当前线程T1中写操作之前的任何读写操作都对线程T2可见;当另外一个线程T2对原子变量A进行读操作的时候,如果施加了memory_order_consume约束符,则当前线程T1中所有原子变量A所依赖的读写操作都对T2线程可见(没有依赖关系的内存操作就不能保证顺序)。
需要注意的是,对于施加了memory_order_release约束符的写操作,其写之前所有读写指令操作都不会被重排序写操作之后的前提是:其他线程对这个原子变量执行了读操作,且施加了memory_order_acquire或者 memory_order_consume约束符。
一个对原子变量的load操作时,使用memory_order_acquire约束符:在当前线程中,该load之后读和写操作都不能被重排到当前指令前。如果其他线程使用memory_order_release约束符,则对此原子变量进行store操作,在当前线程中是可见的。
假设有一个原子变量A,如果A的读操作X施加了memory_order_acquire标记,则在当前线程T1中,在操作X之后的所有读写指令都不能重排到操作X之前;当其它线程如果对A进行施加了memory_order_release约束符的写操作Y,则这个写操作Y之前所有的读写指令对当前线程T1是可见的(这里的可见请结合 happens-before 原则理解,即那些内存读写操作会确保完成,不会被重新排序)。
也就是说从线程T2的角度来看,在原子变量A写操作之前发生的所有内存写入在线程T1中都会产生作用。也就是说,一旦原子读取完成,线程T1就可以保证看到线程 A 写入内存的所有内容。
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer() {
std::string* p = new std::string("Hello"); // L10
data = 42; // L11
ptr.store(p, std::memory_order_release); // L12
}
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire))); // L17
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
在上述例子中,原子变量ptr的写操作(L12)施加了memory_order_release标记,根据前面所讲,这意味着在线程producer中,L10和L11不会重排到L12之后;在consumer线程中,对原子变量ptr的读操作L17施加了memory_order_acquire标记,也就是说L8和L19不会重排到L17之前,这也就意味着当L17读到的ptr不为null的时候,producer线程中的L10和L11操作对consumer线程是可见的,因此consumer线程中的assert是成立的。
memory_order_consume
一个load操作使用了memory_order_consume约束符:在当前线程中,load操作之后的依赖于此原子变量的读和写操作都不能被重排到当前指令前。如果有其他线程使用memory_order_release内存模型对此原子变量进行store操作,在当前线程中是可见的。
在理解memory_order_consume约束符的意义之前,我们先了解下依赖关系,举例如下:
std::atomic<std::string*> ptr;
int data;
std::string* p =newstd::string("Hello");
data =42;
ptr.store(p,std::memory_order_release);
在该示例中,原子变量ptr依赖于p,但是不依赖data,而p和data互不依赖
现在结合依赖关系,理解下memory_order_consume标记的意义:有一个原子变量A,在线程T1中对原子变量的写操作施加了memory_order_release标记符,同时线程T2对原子变量A的读操作被标记为memory_order_consume,则从线程T1的角度来看,在原子变量写之前发生的所有读写操作,只有与该变量有依赖关系的内存读写才会保证不会重排到这个写操作之后。
也就是说,当线程T2使用了带memory_order_consume标记的读操作时,线程T1中只有与这个原子变量有依赖关系的读写操作才不会被重排到写操作之后。而如果读操作施加了memory_order_acquire标记,则线程T1中所有写操作之前的读写操作都不会重排到写之后(此处需要注意的是,一个是有依赖关系的不重排,一个是全部不重排)。
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer() {
std::string* p = new std::string("Hello"); // L10
data = 42; // L11
ptr.store(p, std::memory_order_release); // L12
}
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume))); // L17
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
与memory_order_acquire一节中示例相比较,producer()没有变化,consumer()函数中将load操作的标记符从memory_order_acquire变成了memory_order_consume。而这个变动会引起如下变化:producer()中,ptr与p有依赖 关系,则p不会重排到store()操作L12之后,而data因为与ptr没有依赖关系,则可能重排到L12之后,所以可能导致L19的assert()失败。
当确定只需对某个变量限制访问顺序的时候,应尽量使用 memory_order_consume,减少代码重排的限制,以提升程序性能。
memory_order_acq_rel
相当于同时使用 memory_order_release 和 memory_order_acquire 约束符。理解为该原子操作前操作可于该原子操作前重排序,该原子操作后操作可于该原子操作后重排序
std::atomic_flag 最基础的原子类型
这个类型的对象可以在两个状态间切换:设置和清除。std::atomic_flag 类型的对象必须被ATOMIC_FLAG_INIT初始化。初始化标志位是“清除”状态。这里没得选 择,这个标志总是初始化为“清除”:
当标志对象已初始化,只能做三件事情:销毁,清除或设置(查询之前的值)。
有限的特性使得 std::atomic_flag 非常适合于作自旋锁。初始化标志是“清除”,并且互斥量处于解锁状态。为 了锁上互斥量,循环运行test_and_set()直到旧值为false,就意味着这个线程已经被设置为true了。解锁互斥 量是一件很简单的事情,将标志清除即可。
std::atomic<T*>
通过特化 std::atomic 进行定义,操作是针对于相关类型的指针。虽然既不能拷贝构造,也不能拷贝赋值,但是可以通过合适的类型指针进行构造和赋 值。 std::atomic 也有load(), store(), exchange(), compare_exchange_weak()和 compare_exchange_strong()成员函数,获取与返回的类型都是T*。
std::atomic 为指针运算提供新的操作。基本操作有fetch_add()和fetch_sub(),它们在存储地址上做原子 加法和减法,为+=, -=, ++和--提供简易的封装。
class Foo{};
Foo some_array[5];
std::atomic<Foo*> p(some_array);
Foo* x=p.fetch_add(2); // p加2,并返回原始值
assert(x==some_array);
assert(p.load()==&some_array[2]);
x=(p-=1); // p减1,并返回原始值
assert(x==&some_array[1]);
assert(p.load()==&some_array[1]);
标准原子整型的相关操作
如同普通的操作集合一样(load(), store(), exchange(), compare_exchange_weak(), 和 compare_exchange_strong()), std::atomic 和 std::atomic 也是有一套完整的操作可 以供使用:fetch_add(), fetch_sub(), fetch_and(), fetch_or(), fetch_xor(),还有复合赋值方式((+=, -=, &=, |= 和^=),以及++和--(++x, x++, --x和x--).
C++标准库也对原子类型中的 std::shared_ptr<> 智能指针类型提供非成员函数,这些操作重载了标准原子类型的操作,并且可获 取 std::shared_ptr<>* 作为第一个参数.
std::shared_ptr<my_data> p;
void process_global_data()
{
std::shared_ptr<my_data> local=std::atomic_load(&p);
(local);
}
void update_global_data()
{
std::shared_ptr<my_data> local(new my_data);
std::atomic_store(&p,local);
}
第六章 基于锁的并发容器实现见源码文件
第七章 无锁并发实现见源码文件
关于无锁编程需要重点注意:
无锁结构资源释放,ABA问题和无锁情况下的内存顺序优化
并发设计
最基础的方式是通过将数据进行预划分,由多个线程分担自己的部分最后在主线程中合并。
可见先前解决方案Case parallel_accumulate
template<typename T>
std::list<T> parallel_quick_sort(std::list<T> input)
{
if(input.empty())
{
return input;
}
std::list<T> result;
result.splice(result.begin(),input,input.begin());
T const& pivot=*result.begin();
auto divide_point=std::partition(input.begin(),input.end(),
[&](T const& t){return t<pivot;});
std::list<T> lower_part;
lower_part.splice(lower_part.end(),input,input.begin(),
divide_point);
std::future<std::list<T> > new_lower(
// 1
std::async(¶llel_quick_sort<T>,std::move(lower_part)));
auto new_higher(
parallel_quick_sort(std::move(input)));
// 2
result.splice(result.end(),new_higher);
// 3
result.splice(result.begin(),new_lower.get());
// 4
return result;
}
算法改进:
为避免发起过多资源,使用std::thread::hardware_concurrency()获取本地支持的硬件并发数量,只有在当前发起线程数量少于该数时发起新线程。
为使线程避免长时间阻塞等待结果,我们需要使线程能够持续的获取更多的工作。
当线程使用 std::partition 划分 lower_part 与 higher_part 后,将lower_part数据与一个std::promise进行打包为chunk并持有该std::promise内的std::future以用于后续同步,打包后放入共享的线程安全容器THC(thread_safe_container)中。
此时若当前线程数量小于硬件并发数量,发起新线程以相同的方式对THC内数据包chunk以上文相同的方式进行处理,结果将保存在该chunk的std::promise中以用于同步。
将lower_part打包后,原线程内还有higher_part,此时选择使用递归的方式以相同方法处理higher_part。
在higher_part处理完毕后,进行std::future::wait_for(std::chrono::second(0))获取lower_part的是否处理完毕,若完毕,合并并返回,否则将从THC中获取任一chunk作为当前任务,以实现线程资源的充分利用。
并发代码设计
任务划分可分为根据任务类型与根据任务数据两种。
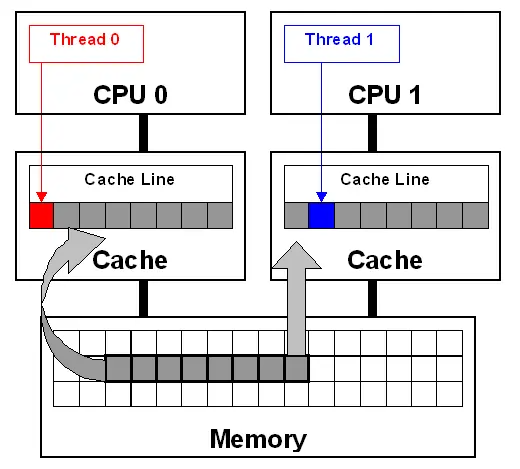
数据争用与乒乓缓存
两个线程在线程在不同处理器上对同一数据进行读取时,通常会先拷贝到每个线程的缓存中,并让多个处理器同时进行处理,当有数据对数据进行修改时并且需要更新到其他核芯的缓存中去时,就需要耗费一定的时间,这可能会使其他处理器停下来以等待硬件内存更新缓存中的数据。
std::atomic<unsigned long> counter(0);
void processing_loop()
{
while(counter.fetch_add(1,std::memory_order_relaxed)<100000000)
{
do_something();
}
}
counter变量是全局的,所有线程都能调用processing_loop()。因此每次对counter进行增量处理时,处理器都必须确保缓存中的counter是最新值,然后进行修改
fetch_add是一个“读-写-改”操作,因此需要对最新的值进行查找,若另一个线程在另一个处理器上执行同样的代码,counter的数据就需要在两个处理器之间进行传递,两个处理器的缓存中间就存有counter的最新值。若此时有很多处理器同时对这段代码进行处理,处理器会互相等待。这种情况就是高竞争(high contention),若处理器很少相互的等待则称为低竞争(low contention)。
而在循环中counter的数据在每个缓存中传递多次,这就是乒乓缓存(cache ping-pong)
使用mutex互斥量与上文使用atomic相同,高竞争且处理器相互等待下都可能出现乒乓缓存。
伪共享 (false_sharing)
处理器缓存通常使用缓存行(cache_line)而不是用单数据储存,内存块大小由处理器决定,因为硬件缓存可确定缓存行的大小,较小的数据项就在同一内存行的相邻位置上。当线程访问的一组数据在同一数据行内时,这种方式的性能将大大优于对于多个缓存行的读取。但当同一缓存行储存的是无关数据时,且需要被不同的线程访问时,就会出现性能问题。
假设一个int类型的数组,并有一组线程可以访问数组中的元素且访问非常频繁,通常int的大小要小于一个cache_line,因为MESI协议下,线程间虽然只是修改cache_line中其中不同的元素,但都会竞争同一个cache_line的所有权,这也会导致高竞争下的乒乓缓存。这时该cache_line的状态就被认为是伪共享(false_sharing),为避免该问题,可以通过将数据构造在不同的cache_line中,在C++17的标准头文件<new>中定义了<std::hardware_destructive_interference_size>它指定了当前编译目标可能共享的连续字节的最大数目。如果确保数据间隔大于等于这个字节数就能避免错误的共享。
让数据紧凑
伪共享发生的原因在于:某个线程要访问的数据过于接近另一线程的数据。但若选择使用非紧凑数据,这将给单线程造成数据访问的延迟。为避免伪共享应当努力让不同线程访问不同内存行。而单线程内则尽可能访问已加载的内存行,提高缓存命中率。
为多线程设计数据结构
在为多线程性能设计数据结构时,需要考虑竞争,伪共享和邻近数据,这三个对于性能都有重大影响的因素。
对于多线程中的数据结构应当尝试以下三点:
- 尝试调整数据在线程间的分布,让同一线程中的数据紧密联系在一起。
- 尝试减少线程上所需的数据量。
- 尝试让不同的线程访问不同的储存位置,以避免伪共享。
为测试伪共享问题,可以通过填充大量的数据块强迫数据分布在不同cache_line,然后通过并发访问,若此时能够提高性能则认为此处发生伪共享问题。
struct protected_data
{
std::mutex m;
char padding[65536]; //也可以使用std::hardware_destructive_interference_size使该块占用内存大于一个内存行
my_data data_to_protect;
};//用于测试互斥量竞争中的伪共享
struct my_data
{
data_item1 d1;
data_item2 d2;
char padding[65536];
};
my_data some_array[256];//用于测试数组数据中的伪共享问题
并行算法中的异常安全
通常相较于串行算法,并行算法会更加注意异常问题。操作在串行算法中抛出异常时,算法只需要对其本身进行处理,就可以避免资源泄露和损坏不变量,这里允许异常传递给调用者,由调用者对异常进行处理。在并行算法中有很多操作需要运行在独立的线程上,所以不能传播异常。如果函数在创建线程后异常退出,那么应用会终止。
使用 std::terminate 的地方,可不是什么好地方
如果确认了新线程的目标工作,并要返回一个计算的结果的同时,允许代码产生异常,可以将std::packaged_task 和 std::future 结合使用。(见使用std::packaged_task的并行std::accumulate);
try
{
for(unsigned long i=0;i<(num_threads-1);++i)
{
// ... as before
}
T last_result=accumulate_block()(block_start,last);
std::for_each(threads.begin(),threads.end(),
std::mem_fn(&std::thread::join));
}
catch(...)
{
for(unsigned long i=0;i<(num_thread-1);++i)
{
if(threads[i].joinable())
thread[i].join();
}
throw;
}
使用std::future来接住异常问题,然后在使用std::future::get()时将异常进一步抛出,在外层处理异常,并保证线程汇入以避免线程泄露(未join())。也可以使用RAII类对线程进行控制,保证该类析构时对所有可汇入线程进行汇入。
对于异常安全,还需要注意一件事,如果没有等待的情况下对future实例进行销毁,析构函数会等待对应线程执行完毕后才执行。这就能体现线程泄露的问题,因为线程还在执行,且持有数据引用。下面将展示使用 std::async() 完成异常安全的实现。
同理,也能使用std::async()实现异常安全
template<typename Iterator,typename T>
T parallel_accumulate(Iterator first,Iterator last,T init)
{
unsigned long const length=std::distance(first,last);
// 1
unsigned long const max_chunk_size=25;
if(length<=max_chunk_size)
{
return std::accumulate(first,last,init);
// 2
}
else
{
Iterator mid_point=first;
std::advance(mid_point,length/2);
// 3
std::future<T> first_half_result=
std::async(parallel_accumulate<Iterator,T>,
// 4
first,mid_point,init);
T second_half_result=parallel_accumulate(mid_point,last,T());
return first_half_result.get()+second_half_result;
// 6
}
}
该版通过std::async产生future,将异常捕获在future内,在对get()调用后,future中储存的异常会再次抛出。
可扩展性和Amdahl定律
扩展性对于并行编程同样重要,扩展性代表了应用完全利用系统中的处理器执行任务的能力。将应用写死为单线程运行就是完全不可扩展的,即使添加了100个处理器到系统中同样不会有性能的提升。
对于多线程程序的一种性能计算方式可以通过一下简化模型 :将程序划分为”串行“和”并行“部分。串行部分:只能由单线程执行一些工作的地方。并行部分:可以让所有可用的处理器一起工作的部分。在这种假设下将程序”串行“部分的用时比例用fs来表示,性能增益(P),处理器数量(N)进行估计:
$$
P = \frac{1}{fs+\frac{1-fs}{N}}
$$
这就是Amdahl定律,该定律明确了对代码最大化并发可以保证所有处理器都能用来做有用的工作,如果将"串行"部分减少,或者减少线程的的等待,就可以在多处理器系统中获得更多的性能收益。
扩展性:当有更多的处理器加入时,减少单个动作的执行时间,或在给定的时间内做更多的工作。有时这两个指标是等价的。
多线程隐藏延迟
线程并非任何时候都在做有用的工作,有时也会等待其他线程,或者等待I/O完成,亦或是等待其他事情。如果线程等待时,系统中还有必要的任务需要完成,就可以将等待”隐藏起来“;
不论等待的理由是什么,线程阻塞就意味着在等待CPU时间片。处理器将会在阻塞的时间内运行另一个线程而不是什么都不做。因此,当知道一些线程需要耗费相当一段时间进行等待时,可以利用CPU的空闲时间去运行一个或多个线程。
设计并发代码
并行std::for_each
std::for_each原理其实很简单:对某个范围内的元素,依次使用用户提供的函数。并行和串行最大的区别是函数的调用顺序。
为实现该函数并行版本,需要对每个线程所处理的元素进行划分。事先知道元素数量可以在处理前对数据进行划分,若只有并行任务运行,则可以使用std::thread::hardware_concurrency()决定线程数量。同样,若这些元素都能独立处理任务,则可以使用连续的数据块以以避免伪共享。为将异常传递给调用者,需要使用std::packaged_task和std::future来对线程中的异常进行转移。
并行std::find
(以上见代码文件)
高级线程管理
线程池
最简单的线程池实现:拥有固定数量的工作线程(通常工作线程数量和std::thread::hardware_concurrency()相同)。工作需要完成时,可以调用函数将任务挂在任务队列中。每个工作线程都会从任务队列上获取任务,然后执行这个任务,执行完成后再回来获取新的任务。线程池中线程就不需要等待其他线程完成对应任务了。如果需要等待,就需要对同步进行管理。
简单线程池代码实现:
class thread_pool
{
std::atomic_bool done;
thread_safe_queue<std::function<void()> > work_queue;
// 1
std::vector<std::thread> threads;
// 2
join_threads joiner;
// 3
void worker_thread()
{
while(!done)
// 4
{
std::function<void()> task;
if(work_queue.try_pop(task))
// 5
{
task();
// 6
}
else
{
std::this_thread::yield();
// 7
}
}
}
public:
thread_pool():
done(false),joiner(threads)
{
unsigned const thread_count=std::thread::hardware_concurrency();
// 8
try
{
for(unsigned i=0;i<thread_count;++i)
{
threads.push_back(
std::thread(&thread_pool::worker_thread,this));
// 9
}
}
catch(...)
{
done=true;
// 10
throw;
}
}
~thread_pool()
{
done=true;
// 11
}
template<typename FunctionType>
void submit(FunctionType f)
{
work_queue.push(std::function<void()>(f));
// 12
}
};
使用线程安全队列管理任务队列,用户通过使用std::function<void()>对任务进行封装,推入队列中,由工作队列worker_thread从队列上获取任务,以及同时执行这些任务,进行循环知道设置done标志,如果队列上没有任务,则调用std::this_thread::yield()使线程减少竞争时间片(休息),并给予其他线程向任务队列推送任务的机会。
但这样的线程池过于简单,无法解决有返回值或需要执行阻塞操作的任务,并且可能会出现如死锁的问题,在简单情况下使用std::async通常能提供更好的功能。
等待线程池中的任务
为将执行任务的线程结果返回到等待线程上处理,需要使用future对最终结果进行转移。但packaged_tast<>实例是不可拷贝的,仅可移动,所以不能再使用std::function<>来实现任务队列,因为std::function<>需要存储可复制构造的函数对象。
此时我们需要自定义一个带有函数操作符的类型擦除类,只需要处理没有入参的函数和无返回的函数即可,所以这只需要用到简单的虚函数调用。
function_wrapper类实现:
class function_wrapper
{
struct impl_base{
virtual void call() = 0;
virtual ~impl_base() {}
};
std::unique_ptr<impl_base> impl;
template<typename F>
struct impl_type:impl_base
{
F f;
impl_type(F&& f_):f(std::move(f_)) {}
void call {f();}
};
public:
template<typename F>
function_wrapper(F&& f):
impl(new impl_type<F>(std::move(f)))
{}
void operator()(){impl->call();}
function_wrapper() = default;
function_wrapper(function_wrapper&& other)
{
impl = std::move(other.impl);
return *this;
}
function_wrapper(const function_wrapper&)=delete;
function_wrapper(function_wrapper&)=delete;
function_wrapper& operator=(const function_wrapper&)=delete;
};
窃取任务
当工作线程对应的工作队列上没有可用任务时将进入等候状态,这将造成资源的浪费。所以我们应当尽可能让每个工作线程的工作饱和。
在每个工作线程的工作队列放置在全局线程池的全局变量列表中
class thread_pool
{
...
std::vector<std::unique_ptr<working_stealing_queue>> queues;
//每个线程的工作队列都将储存在线程池的全局工作队列中
...
//使用序号来索引队列
static thread_local work_stealing_queue* local_work_queue;
static thread_local unsigned my_index;
void worker_thread(unsigned my_index_)
{
my_index = my_index_;
//新生成的工作线程将线程池给予的索引初始化到local_thread变量中
local_work_queue=queues[my_index].get();
//根据索引获取工作队列
while(!done)
{
run_pending_task();
}
}
public:
thread_pool()
{
unsigned const thread_count = std::thread::hardware_concurrency();
for(unsigned i=0;i<thread_count;++i)
{
queues.push_back(std::unique_ptr<work_stealing_queue>(new work_stealing_queue));
//创建线程时赋予index索引
threads.push_back(std::thread(&thread_pool::work_thread,this,i));
}
}
void run_pending_task()
{
task_type task;
if(pop_task_from_local_queue(task)|| //从本地任务列表获取任务
pop_task_from_pool_queue(task)|| //从全局任务列表获取任务
pop_task_from_other_thread_queue(task)) //从其他线程的本地列表中窃取任务
{
task();
}
else
{
std::this_thread::yield();
}
}
//任务提交接口
template<typename FunctionType>
std::future<typename std::result_of<Functiontype()>::type>
submit(FunctionType f)
{
typedef typename std::result_of<FunctionType()>::type result_type;
std::packaged_task<result_type()> task(f);
std::future<result_type> res(task.get_future());
//判断是否为工作线程
if(local_work_queue)
{
local_work_queue->push(std::move(task));
}
else
{
pool_work_queue.push(std::move(task));
}
return res;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号