
Java集合总结
基础知识
数据物理结构
顺序存储结构
数组是什么:一段连续的内存存储空间。
优点:随机访问快,访问每个元素所用时间相等。
缺点:大小固定,数组容量大时插入,删除效率低。
链式存储结构
链表是什么:不连续的内存空间
优点:大小动态拓展,插入删除效率高(内存空间随机,只需将链表元素上下文中的内存地址修改。)
缺点:不能随机访问(通过下标获取值效率低,Node(item = 元素值,next =下一个元素地址,last=最后元素地址))。
索引
索引是什么:通过数组的方式,创建并记录所有集合元素内存地址的索引表。为了方便查询,整体无序,但索引块之间有序。需要额外的空间存储索引表。
优点:对顺序查询的一种改进,查询效率高。
缺点:需要额外的存储空间。
散列
散列是什么:选取某个函数,数据元素根据计算存储位置,可能存在多个数据元素存储在一个位置,引起地址冲突。
优点:基于元素值查询,效率高,存储效率高。
缺点:存取随机,不能按照顺序查找。
数据逻辑结构
集合
数据元素同属于一个集合,单个数据元素之间没有任何关系。
线性
数据元素之间时一对一的关系。
树形
数据元素之间存在一对多的关系
图形
数据元素之间存在多对多的关系
线程安全
乐观锁
CAS+自旋
悲观锁
Reentrantlock ,synchronized
| 基础知识线程安全(锁) | synchronized | Reentrantlock |
|---|---|---|
| ① 底层实现 | JVM层面的锁 | jdk提供的API层面的锁 |
| ② 是否可手动释放 | 否,自动释放锁的占用 | 手动释放锁,不释放造成死锁 |
| ③ 是否可中断 | 不可中断类型的锁,除非加锁的代码中出现异常或正常执行完成 | 则可以中断,可通过trylock(long timeout,TimeUnit unit)设置超时方法或者将lockInterruptibly()放到代码块中,调用interrupt方法进行中断。 |
| ④ 是否公平锁 | 为非公平锁 | 可以选公平锁也可以选非公平锁 |
| ⑤ 锁是否可绑定条件Condition | 不能绑定,Object类的wait()/notify()/notifyAll()方法要么随机唤醒一个线程要么唤醒全部线程。 | 通过绑定Condition结合await()/singal()方法实现线程的精确唤醒 |
| ⑥ 锁的对象 | 锁的是对象,锁是保存在对象头里面的,根据对象头数据来标识是否有线程获得锁/争抢锁; | k锁的是线程,根据进入的线程和int类型的state标识锁的获得/争抢。 |
collection
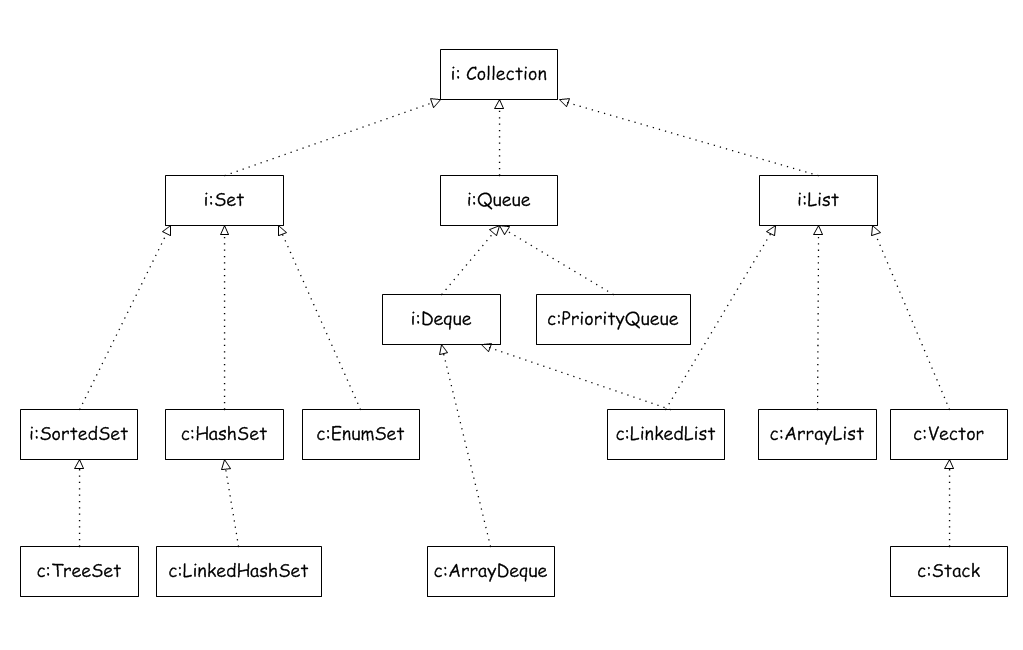
List
ArrayList
数据结构:动态数组,自动扩容。添加元素时容量不足会自动新建一个数组,长度为原数组的长度*扩容因子。新元素会存入新数组,并将新数组赋值给集合,将原数组删除。
new ArrayList() 两个常量:节省集合创建时占用的资源。
EMPTY_ELEMENTDATA :有参构造器指定初始长度,扩容按照1.5倍
DEFAULTCAPACITY_EMPTY_ELEMENTDATA :无参构造器创建默认长度(10),扩容按照1.5倍
迭代器:fail-fast 因为ArrayList 是线程不安全的,当遇到并发修改集合中的一个值时,ArrayList集合游标会存在错误。所以产 生迭代器机制,提前将异常抛出。iterator () 获取迭代器时,保存modcount(操作次数)快照,游标初始值为0。 hasNext判断条件:cursor != size 如果有其他线程修改了集合长度(新增或者删除),会导致siez 变化modCount和 快照会有差异。
拷贝:拷贝前后变量
基本数据类型:独立,因在占上分配,拷贝一份完全独立。
引用数据类型:不独立,占中只是拷贝一份地址,拷贝前后指向同一堆中内容。
String :独立 ,不区分JDK版本,String 对象会在常量池中存储。并且创建之后保持不变。
正常拷贝:实现Cloneable接口,clone方法默认,则为浅拷贝。
深拷贝:需要递归所有的引用类型,递归到基本类型和String,数组为止,都拷贝一次。
序列化:重新序列化方法,因为存放元素的数组elementData 中存在null。序列化时只需按照size读写。
Array.asList 方法:接收的是可变参数,基本类型不支持泛型。
Vector
简单说就是在Array List上加了一个Synchronized ,保证线程安全。
LinkedList
数据结构:链表结构,维护一个内部类Node,item当前值,next下一个地址指针,prev上一个地址指针
双端队列:实现了Deque接口,支持从首尾获取元素。
CopyOnWriteArrayList
数据结构:数组结构实现。
写时加锁复制:ReentranLock锁机制保证线程安全,只有修该数组之前会将数组拷贝一份,操纵新数组,并赋值给array,丢弃就旧数 组。读操作没有锁机制,读的是旧数组。读写分离,写不会阻塞读取。
弱一致性:写操作会生成新的数组,读的数据可能已经修改过了。迭代器也是弱一致性,读的是旧数据。
Set
HashSet
底层使用HashMap存储数据,用map的key存储元素。元素不重复,key不能重复,无序的,允许第一个null也只有一个。
非线程安全,没有get()方法,虚拟对象PRESENT,存map时,value固定为此值。
LinkedHashSet
没有成员变量及api,全部使用LinkedHashMap替代。
TreeSet
底层使用NavigableMap存储元素,实际上大部分情况就是TreeMap。
CopyOnWriteArraySet
底层使用CopyOnWriteArrayList ,调addIfAbsent方法保证元素的不可重复 。
ConcurrentSkipListSet
底层使用ConcurrentSkipListMap
Queue
阻塞队列BlockingQueue
数组阻塞队列 ArrayBlockingQueue 先进先出,读写互相排斥
数据结构:静态数组,容量固定必须指定长度,没有扩容机制,没有元素的下标位置null占位。
锁:ReentrantLock 存取是同一把锁,操作的是同一个数组对象。
阻塞:1.notEmpty
出队:队列count为0,无元素可取时,阻塞在该对象上。
2.notFull
入队:队列count为数组的length,放不进元素时,阻塞在该对象上。
入队:从队首开始添加元素,记录putIndex(到队尾时置为0) 。唤醒notEmpty。
出队:从队首开始取元素,记录takeIndex。唤醒notFull。
链表阻塞队列LinkedBlockingQueue
删除元素时两个锁一起加,先进先出
数据结构:链表Node,可以指定容量,默认为Integer.MAX_VALUE,内部类Node存储元素。
锁分离:存取互不排斥,操作的是不同的Node对象。
takeLock:取Node节点保证前驱后继不会乱。
putLock:存Node节点保证前驱后继不会乱
阻塞:同ArrayBlockingQueue
入队:队尾入队,记录last节点。
出队:队首出队,记录head节点。
删除元素时两个锁一起加,先进先出
同步队列SynchronousQueue
这是一种线程与线程间一对一传递消息的模型,特别之处在于它内部没有容器。
公平模式下的模型:队尾匹配队头出队。
非公平模式下的模型:队尾匹配队尾出队。
LinkedTransferQueue
LinkedTransferQueue 使用了一个叫做 dual data structure 的数据结构,或者叫做 dual queue ,翻译为双重数据结构或者双重队列。
放元素时先跟队列头节点对比,如果头节点是非数据节点,就让它们匹配,如果头节点是数据节点,就生产一个数据节点放在队列尾端(入队)。
取元素时也是先跟队列头节点对比,如果头节点是数据节点,就让它们匹配,如果头节点是非数据节点,就生产一个非数据节点放在队列尾端(入队)。
优先级的阻塞队列PriorityBlockingQueue
链表阻塞双端队列LinkedBlockingDeque
延迟队列DelayQueue
Map
HashMap
数据结构:数组+链表
jdk8开始链表高度到8、数组长度超过64,链表转变为红黑树。
构造红黑树要比构造链表复杂,在链表的节点不多的时候,从整体的性能看来,数组+链表+红黑树的结构可能不一定比 数组+链表的 结构性能高。
频繁的扩容,会造成底部红黑树不断的进行拆分和重组,这是非常耗时的。因此,也就是链表长度比较长的时候转变成 红黑树才会显著提高效率。
元素以内部类Node节点存在
元素存储:
计算key的hash值,二次hash然后对数组长度取模,对应到数组下标。
如果没有产生hash冲突(下标位置没有元素),则直接创建Node存入数组
如果产生hash冲突,先进行equal比较。相同则取代该元素,不同,则判断链表高度插入链表,链表高度达到8,并且数 组长度到64则转变为,红黑树,长度低于6则将红黑树转回链表。
key为null,存在下标0的位置
扩容:
元素个数达到阈值threshold ,扩容2倍,新建数组。
旧数组的数据移到新数组,遍历旧数组,重新计算每个元素的存储位置(原下标或者原下标+旧数组长度)。
逐个转移数据 ,jdk7头插法,迁移链表,会导致元素顺序变成倒序,并发时可能导致环形链表,产生死锁。
jdk8尾插法,解决了死循环的问题。
重新设置阈值threshold
初始容量:
可以入参指定,官方要求输入2的N次方的值,如果不是则取最近的一个2的N次方值
负载因子loadFactor:扩容时的阈值,默认0.75。
hashCode定位下标,equal定位节点元素。
迭代器:fail-fast
Hashtable
数据结构同HashMap(同jdk7,没有红黑树),操作也一致。synchronized保证线程安全
ConcurrentHashMap
JDK7:
数据结构:ReentrantLock+Segment+HashEntry,一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表 结构
元素查询 :第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部
锁:Segment分段锁
Segment继承了ReentrantLock,锁定操作的Segment,其他的Segment不受影响,并发度为segment个数,可以通过 构造函数指定,数组扩容不会影响其他的segment。
get方法无需加锁。
JDK8:
数据结构:synchronized+CAS+Node+红黑树,Node的val和next都用volatile修饰,保证可见性。查找,替换,赋值操作都 使用CAS
锁:锁链表的head节点,不影响其他元素的读写,锁粒度更细,效率更高。扩容时,阻塞所有的写操作。
并发扩容 :一个线程发起扩容的时候,就会通过cas设置sizeCtl属性(volatile修饰),告知其他线程扩容状态变更。创建一个两 倍容量的新数组nextTable,单线程完成。
扩容时候会判断这个值(sizeCtl属性),如果超过阈值就要扩容。首先根据运算得到需要遍历的次数i,然后利用 tabAt方法获得i位置的元素f初始化一个forwardNode实例fwd,如果f == null,则在table中的i位置放入fwd否则 采用头插法的方式把当前旧table数组的指定任务范围的数据给迁移到新的数组中,然后给旧table原位置赋值fwd
迁移数据至少每次获取16个迁移任务,transferIndex扩容索引,迁移数据前先cas操作该变量,相当于任务头指 针(游标的作用)
直到遍历过所有的节点以后就完成了复制工作,把table指向nextTable,并更新sizeCtl为新数组大小的0.75倍 , 扩容完成。 在此期间如果其他线程的有读写操作都会判断head节点是否为forwardNode节点,如果是就帮助扩容
ForwardingNode节点:
标记作用,表示其他线程正在扩容,并且此节点已经扩容完毕
关联了nextTable,扩容期间可以通过find方法,访问已经迁移到了nextTable中的数据。
如果遍历到的节点是forward节点,就向后继续遍历,再加上给节点上锁的机制,就完成了多线程的控制。多线程 遍历节点,
处理了一个节点,就把对应点的值set为forward,另一个线程看到forward,就向后遍历。这样交叉就完成了复制 工作。
读操作无锁:Node的val和next使用volatile修饰,读写线程对该变量互相可见。数组用volatile修饰,保证扩容时被读线程感 知。
TreeMap
红黑树实现
LinkedHashMap
继承自HashMap
顺序 accessOrder为false,插入顺序保存。
accessOrder为true,访问顺序保存,访问会导致顺序变动最近访问的元素在最后面,可以利用这个特性实现LRU(缓存淘 汰)。
双向链表:元素直接有指针双向链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号