
单机版Hadoop平台的安装与配置
- 在实验机(建议使用性能较好的个人笔记本)上安装Vmware软件,根据系统适当选择Vmware版本;
- 创建虚拟机,一般需要修改宿主机BIOS/uefi中芯片组虚拟化支持,建议先不指定系统安装介质;
- 设置Linux系统安装介质,通常选择光盘ISO文件,建议采用RedHat系列(如RHEL、CentOS等)或Ubuntu系列;
- 利用U盘(优先建议)或Vmware工具将下载好的Hadoop安装文件及JDK安装文件导入虚拟机中的Linux系统
- 安装并配置Java环境,建议安装Oracle JDK;
- 安装并配置Hadoop平台,建议安装Hadoop 2.x版本;
运行Hadoop自带的单词计数程序包验证Hadoop平台是否配置成功
- 下载安装VMware(本机下载的为VMware Workstation 15.5 Pro)。
- 下载相应版本的Linux操作系统(Redhat或者Ubuntu),以Redhat7为例。
- 安装好VMware后,创建新的虚拟机
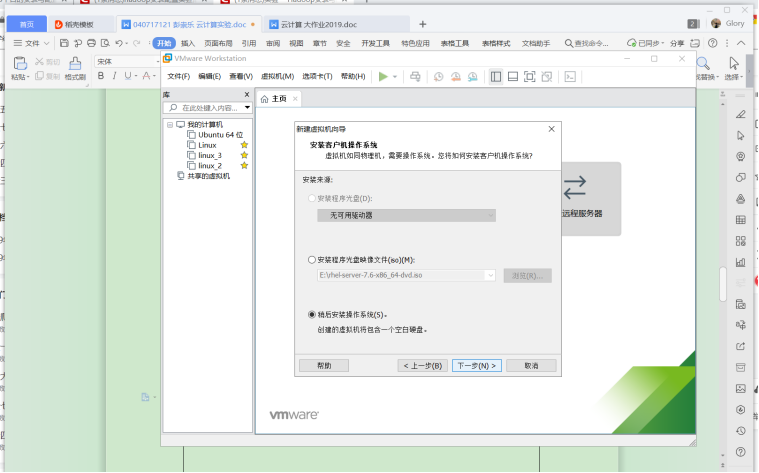
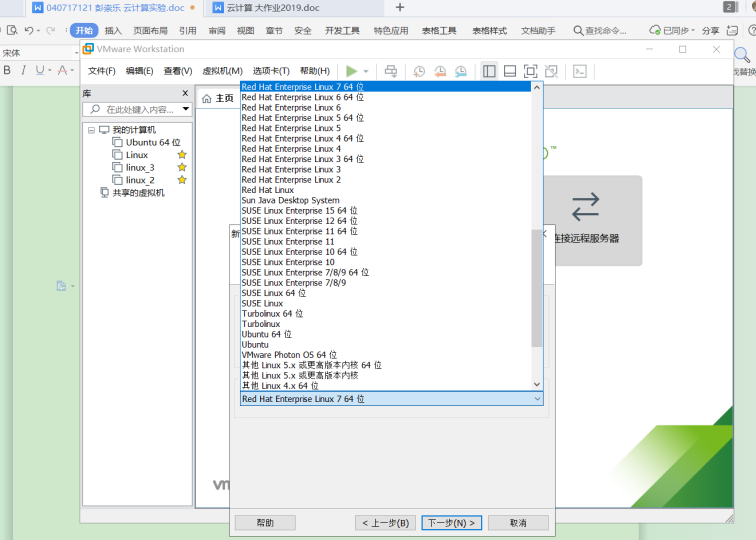
- 根据下载的Linux选择Redhat版本
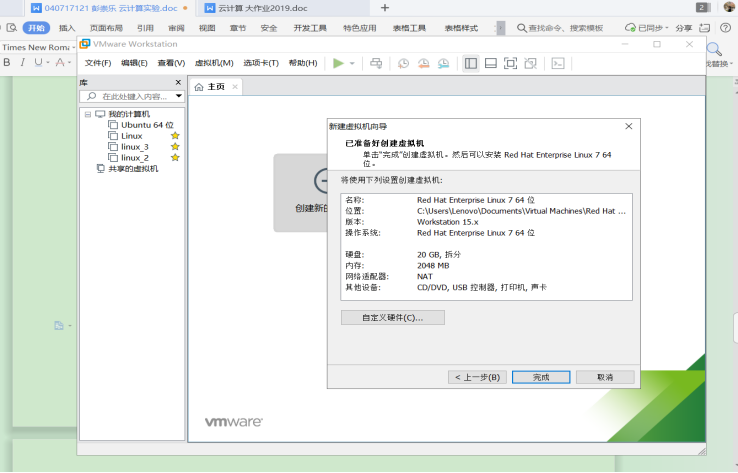
- 到这一步时,选择自定义硬件
![]()
- 进入自定义硬件后,选
择新CD/DVD,选中使用ISO映像文件,选中刚才下载的Linux操作系统的映像文件。
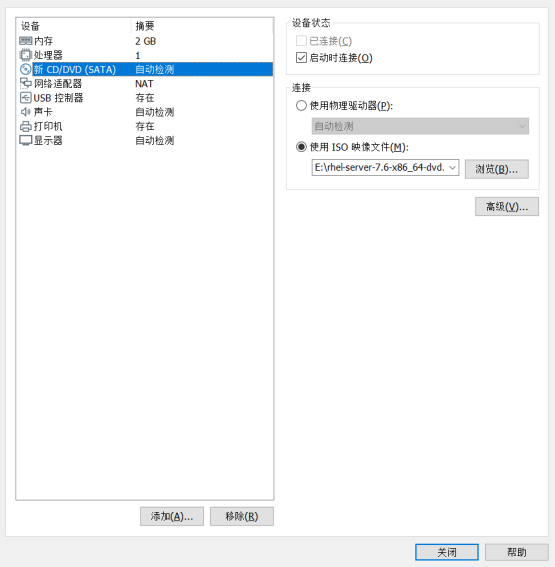
- 点击关闭,此时虚拟机已经配置成功,接下来需要打开虚拟机配置Linux操作系统。
- 进入虚拟机后,可以选择对应的语言,地区等,在安装最后设置用户及root,安装后重启即可。此时我们已经安装好了Linux操作系统,接下来要为Hadoop平台的安装做最后一步的准备工作,即配置jdk。有的操作系统可能会已经配置好了jdk,故我们需要先查看。
9.打开linux系统终端,输入su,进入root用户。输入rpm -qa |grep java 查看是否安装java jdk,若出现java版本,则证明已安装java jdk。
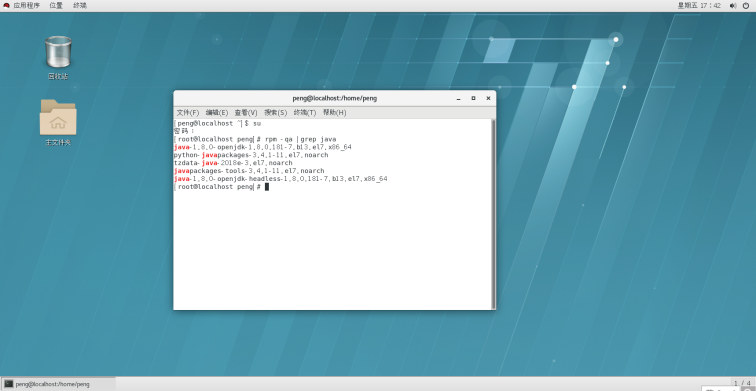
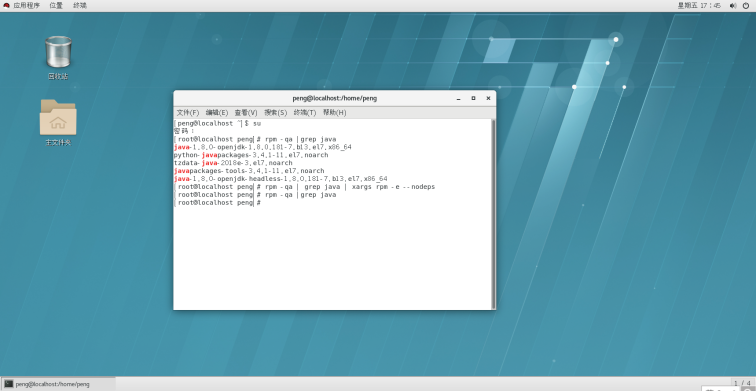
10.输入rpm -qa | grep java | xargs rpm -e --nodeps 批量卸载所有带有Java的文件 这句命令的关键字是java。
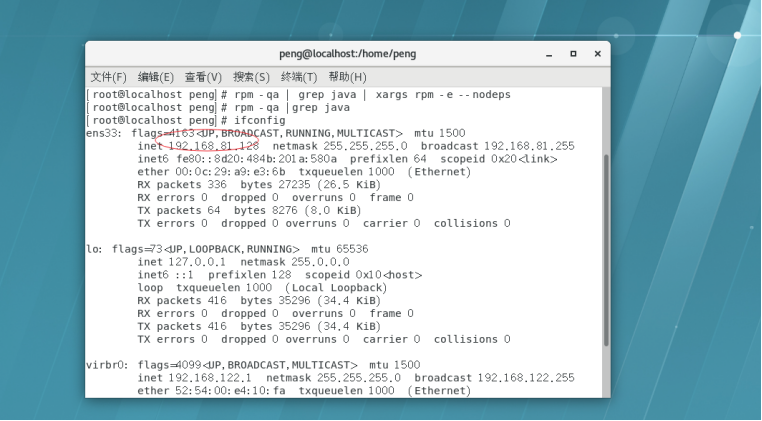
11.由于我是通过Xftp在电脑主机和虚拟机中传输文件,首先我们输入ifconfig 获取虚拟机的IP地址。可以看到这台虚拟机的IP地址为192.168.81.128
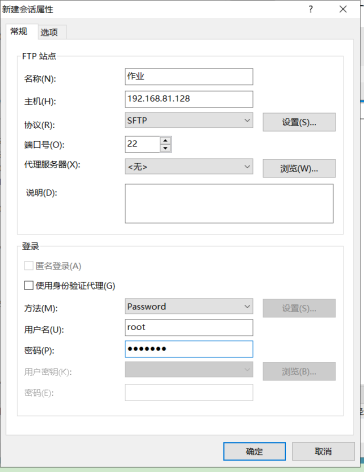
- 在usr目录下新建一个java文件夹用来存放jdk。
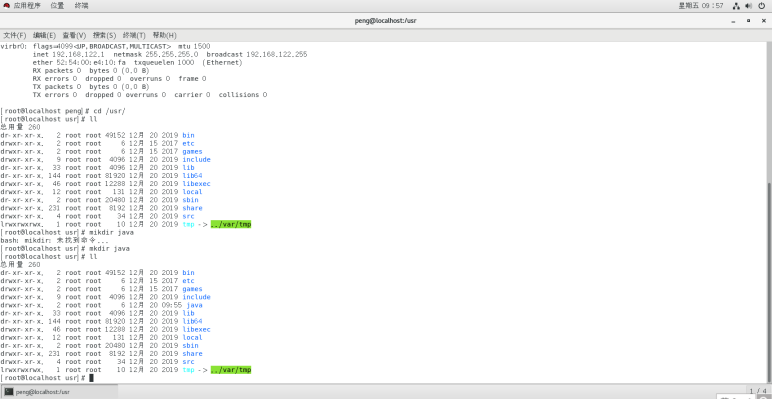
- 通过xftp,将jdk放到java目录下,特别注意,jdk版本一定不能过高,否则将会出现很多很多警告。

- 继续执行tar -zxvf jdk-8u191-linux-x64.tar.gz(压缩包文件名)进行解压,解压完成后继续执行vim /etc/profile 进行环境的配置。并在最后插入
export JAVA_HOME=/usr/java/jdk-13.0.1
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:JAVA_HOME/bin
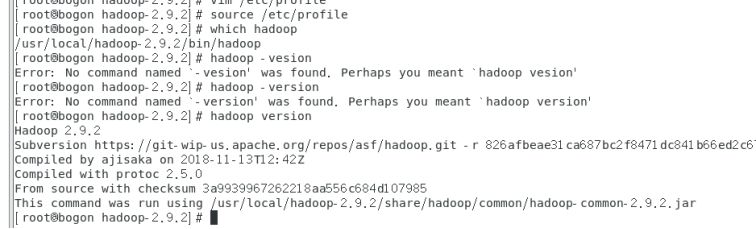
- 保存退出 source /etc/profile 重新加载环境变量,输入java-version。出现下列情况,说明java已经配置完成。

- 将已经下载后的Hadoop压缩包,放到home下。并输入 tar -zxvf /home/hadoop-2.9.2.tar.gz -C /usr/local/ 解压到local目录下。
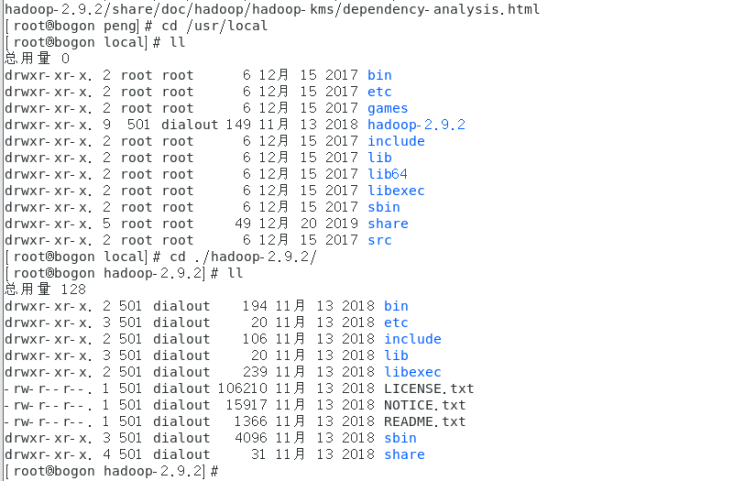
- 输入vi /etc/profile设置Hadoop环境变量,修改后的环境变量为
export JAVA_HOME=/usr/jdk/jdk-13.0.1
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 保存退出 source /etc/profile 重新加载环境变量
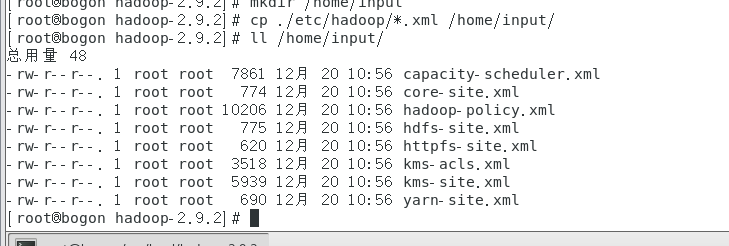
- 输入mkdir /home/input在home下建立input目录。
- 在hadoop目录下输入cp ./etc/hadoop/*.xml /home/input/将hadoop目录下的所有xml文件复制到input目录下。
- 输入ll /home/input/ 查看是否复制成功。
- 输入hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /home/input/ /home/output 将统计结果放入output文件夹中。
- 输入 ll /home/output 即可查看到output文件夹里的内容。再次输入more /home/output/part-r-00000即可查看到结果。此时,实验已经全部完成。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号