Linux基础
一、通过设置调试标志,PTRACE_TRACEME
使用PTRACE_TRACEME作为第一个参数调用ptrace函数,表示该进程由父进程跟踪。任何信号(除了SIGKILL),不管是从外来的还是由exec系统调用产生的,都将使得子进程被暂停,由父进程决定子进程的行为。在request为PTRACE_TRACEME情况下,ptrace()只干一件事,它检查当前进程的ptrace标志是否已经被设置,没有的话就设置ptrace标志,除了request的任何参数(pid,addr,data)都将被忽略。
每个进程只能被PTRACE_TRACEME一次,因此只要程序的开头就先执行一次ptrace(PTRACE_TRACEME, 0, 0, 0),当gdb再想attach的时候就会发现已经执行了一次不能再执行了从而返回-1。
二、内核空间和用户空间的讨论
这里以32位的Linux系统为例,虚拟地址空间划分0-3GB的空间为用户空间,剩下的1GB空间为内核空间。
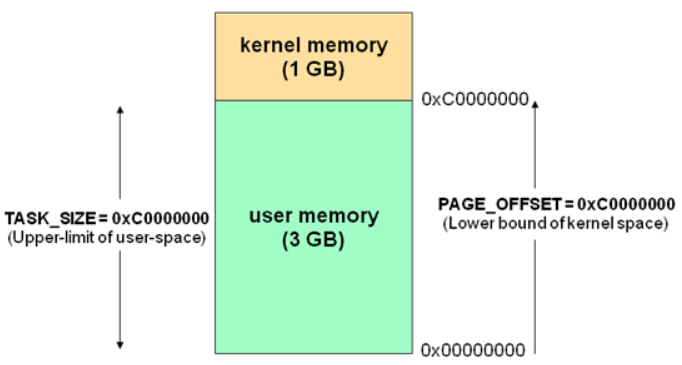
TASK_SIZE = PAGE_OFFSET = 0xc0000000。
线性地址空间:是指Linux系统中从0x00000000到0xFFFFFFFF整个4GB虚拟存储空间。
内核空间:0xC0000000到0xFFFFFFFF的1GB线性地址空间。内核线性地址空间由所有进程共享,但只有运行在内核态的进程才能访问,用户进程可以通过系统调用切换到内核态访问内核空间,进程运行在内核态时所产生的地址都属于内核空间。
用户空间:用户空间占用从0x00000000到0xBFFFFFFF共3GB的线性地址空间,每个进程都有一个独立的3GB用户空间,所以用户空间由每个进程独有,但是内核线程没有用户空间,因为它不产生用户空间地址。子进程共享(或继承)父进程的用户空间只是使用与父进程相同的用户线性地址到物理内存地址的映射关系,而不是共享父进程用户空间(即共享物理空间,但是逻辑上独立)。
物理地址 = 逻辑地址 – 0xC0000000(内核地址空间的地址转换关系)
内核逻辑地址空间访问为0xC0000000 ~ 0xFFFFFFFF,对应的物理内存范围就为0×0 ~ 0×40000000,即只能访问1G物理内存。若机器中安装了8G物理内存,内核依然只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核的虚拟地址空间已经全部映射到物理内存地址范围0×0 ~ 0×40000000。
为了内核能使用后面多出来的物理内存,内核地址空间被划分三部分:ZONE_DMA、ZONE_NORMAL和 ZONE_HIGHMEM。ZONE_HIGHMEM(高端内存),内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,其中通过内核PTE页面表建立映射关系。PS:高端内存HIGH_MEM地址空间范围为 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。
ZONE_DMA 内存开始的16MB ZONE_NORMAL 16MB~896MB ZONE_HIGHMEM 896MB ~ 1GB
补充:
- 用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
- 32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
- 64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。64位系统划分内核与用户空间的比例:1:1。
三、pid相关内容
我的理解里,在Linux内核中,其实也可以说是没有进程这个概念,只有线程的概念。
每一个线程在内核中都用一个task_struct(进程描述符,又称PCB)结构体表示。在同一命名空间内,PID可以用于标识一个线程,且是唯一的。但是内核中命名空间有多个,还存在父子关系的命名空间。所以,命名空间+PID才能唯一标识一个线程。子命名空间的PID对父命名空间是可见的,反之则不可见。
PID的相关信息不只PID一种,这句话可能有点奇怪。怎么说吧,在内核中,一个线程有PID、TGID、PGID,以及SID。但是后三者的值都是通过PID取得的。
- TGID:线程组ID,同一进程内的线程的TGID为主线程的PID。
- PGID:进程组ID,同一进程组内线程的PGID为进程组长的PID(一般是父进程)。
- SID:会话ID,用户登录后活动涉及的所有进程的SID相同,可以理解为同一用户发起的进程SID相同。
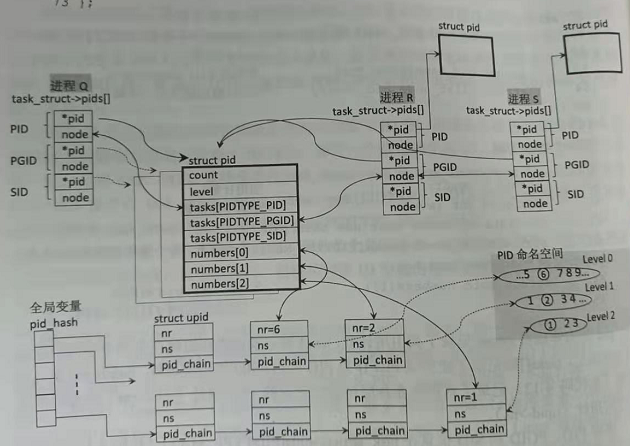
在内核3.13.x版本中,task_struct中有成员pids,存储了该线程所有的PID相关信息。该数组的类型pid_link,该结构体有一个指向pid结构体的指针和用于串联链表的node。另外,该数组的下标用枚举体表示。
struct task_struct { pid_t pid; pid_t tgid; ...... struct pid_link pids[PIDTYPE_MAX]; ...... };
pids数组下标取值如下:
enum pid_type { PIDTYPE_PID, PIDTYPE_PGID, PIDTYPE_SID, PIDTYPE_MAX };
pid_link结构体定义如下:
struct pid_link { struct hlist_node node; struct pid *pid; };
pid结构体中,count是引用计数,level是使用该PID的命名空间的数量。其中,我们需要重点关注tasks和numbers这两个成员。
tasks是一个hlist_head(注意不是hlist_node)类型的数组,每一项都记录着一个链表的表头节点。通过 task[PIDTYPE_PID] 可以得到使用该pid作为PID的 task_struct,通过task[PIDTYPE_PGID] 可以得到使用该pid作为PGID的 task_struct,通过 task[PIDTYPE_SID] 可以得到使用该pid作为SID的 task_struct。具体通过contain_of(task[PIDTYPE_PID], pid_link ,pids[PIDTYPE_PID])获得task_struct结构体的地址。因为task_struct中已经有tgid记录TGID了,所以该数组就不再重复记录。
struct upid { int nr; struct pid_namespace *ns; }; struct pid { refcount_t count; unsigned int level; /* lists of tasks that use this pid */ struct hlist_head tasks[PIDTYPE_MAX]; /* wait queue for pidfd notifications */ wait_queue_head_t wait_pidfd; struct rcu_head rcu; struct upid numbers[1]; };
查询pid有两种方式:1.遍历 task_struct链表(所有的task_struct都是用一个双向链表串起);2.通过 pid_hash哈希链表查询。
前者消耗的时间太多,后者的 pid_hash链表就是为了查询而设计的。通过pid_hash(nr(pid数值),ns(命名空间))来计算hash值,再利用该值找到对应的哈希桶,也是链表。该链表是由一个个upid结构体组成,通过container_of可以追溯至pid结构体,因为其中的number[]的某一项就指向该upid。number数组的数量取决于level,也就是命名空间的数量。
已知pid来查询进程方式:find_vpid函数提供了通过pid数值获得pid结构体的功能,再通过pid_task函数来获得 task_struct结构体。find_vpid 函数调用 find_pid_ns 函数实现获取pid结构体。
struct pid *find_pid_ns(int nr, struct pid_namespace *ns) { struct upid *pnr; hlist_for_each_entry_rcu(pnr, &pid_hash[pid_hashfn(nr, ns)], pid_chain) if (pnr->nr == nr && pnr->ns == ns) return container_of(pnr, struct pid, numbers[ns->level]); return NULL; }
struct task_struct *pid_task(struct pid *pid, enum pid_type type) { struct task_struct *result = NULL; if (pid) { struct hlist_node *first; first = rcu_dereference_check(hlist_first_rcu(&pid->tasks[type]), lockdep_tasklist_lock_is_held()); if (first) result = hlist_entry(first, struct task_struct, pid_links[(type)]); } return result; }
hlist_first_rcu(&pid->tasks[type]) = hlpid->tasks[type].first
hlist_entry = container_of
总结上面所有变量的关系如下图所示。
最后,我们需要知道,pid_hash在内核4.15.x以后被弃用,改用idr树查询pid。因为idr树与命名空间绑定,可以通过ID值获取到命名空间,再通过命名空间获得pid结构体。idr树是基于radix树实现的。idr机制就是整数ID管理机制,一种将整数ID号和特定指针关联在一起的机制。
pids数组在4.19.x以后藏到了task_struct->signal->pids中。
进程描述符在内核中都是用双向链表窜起来的,task_struct->tasks为list_head结构体,通过它来实现双向链表,通过container_of得到 task_struct实例。
struct list_head { struct list_head *next, *prev; };
四、进程创建
进程创建的本质就是拷贝父进程的内容来实现快速创建新的子进程,比如task_struct、mm_struct、页表、环境变量,以及内核栈。
进程创建修改的系统调用有fork、vfork,以及clone。
三者的区别:
- fork:完全复制父进程的空间和内容,父子进程共享内存空间。
- vfork:与fork大致相同,但是父进程创建子进程后阻塞,直到子进程完成其任务才恢复。
- clone:可以灵活选择父进程的内容继承。
子进程复制了父进程的页表,也继承了父进程打开的描述符。
父子进程中的任意一个对可写页发出写操作时,发出写操作的一方会将页帧复制一份,并改写其页表映射关系。
execve系统调用将目标可执行文件的映像替换掉进程原本的映像,并不是创建新进程。
内核栈在task_struct->stack中描述,内核栈只有一页的大小(4KB),内核栈后面跟着thread_info结构体。进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址。进程从用户态转到内核态的时候,进程的内核栈总是空的。当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息就无效了,相当于清空内核栈。内核代码执行时使用的是内核栈。
五、proc文件系统
/proc/<pid>/maps:保存了进程镜像的布局,包括可执行文件、共享库、栈、堆和VDSO等。
/proc/kcore:Linux内核的动态核心文件,以ELF文件的形式展现内核转储,gdb可以使用/proc/kcore来对内核调试和分析。
参考
https://www.cnblogs.com/zlcxbb/p/5841417.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号