

4、统计学习方法--朴素贝叶斯
朴素贝叶斯
- 是基于贝叶斯定理与特征条件独立假设的分类方法。
- 这个假设是这个方法可以实际操作的前提
1、经典案例


- P(B|A) A发生的的情况下B发生的概率:A就是抽中红豆 那么B一定就是绿豆 所以P(B|A)=1
- P(A) 抽中红豆的概率 1/3
- P(B) 路人抽中绿豆的概率 1 ----因为已经知道路人抽中绿豆 所以是1
条件概率

变换推导
- P(AB)=P(A|B)P(B)=P(B|A)P(A)
==>P(A|B)=P(AB)/P(B)
==>由于 P(AB)=P(B|A)P(A)
- 所以 P(A|B)=P(B|A)P(A)/P(B)
直观理解

统计学习方法|朴素贝叶斯原理剖析及实现(基本原理讲的比较好)
- 网页地址
https://www.pkudodo.com/2018/11/21/1-3/ - 本地html地址
file:///Users/glin/000life/%E5%AD%A6%E4%B9%A0/%E6%8A%80%E6%9C%AF%E8%B5%84%E6%96%99/%E7%AE%97%E6%B3%95%E7%9B%B8%E5%85%B3%E7%9A%84html/%E7%BB%9F%E8%AE%A1%E5%AD%A6%E4%B9%A0%E6%96%B9%E6%B3%95-%E6%9C%B4%E7%B4%A0%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%8E%9F%E7%90%86%E5%89%96%E6%9E%90%E5%8F%8A%E5%AE%9E%E7%8E%B0.html
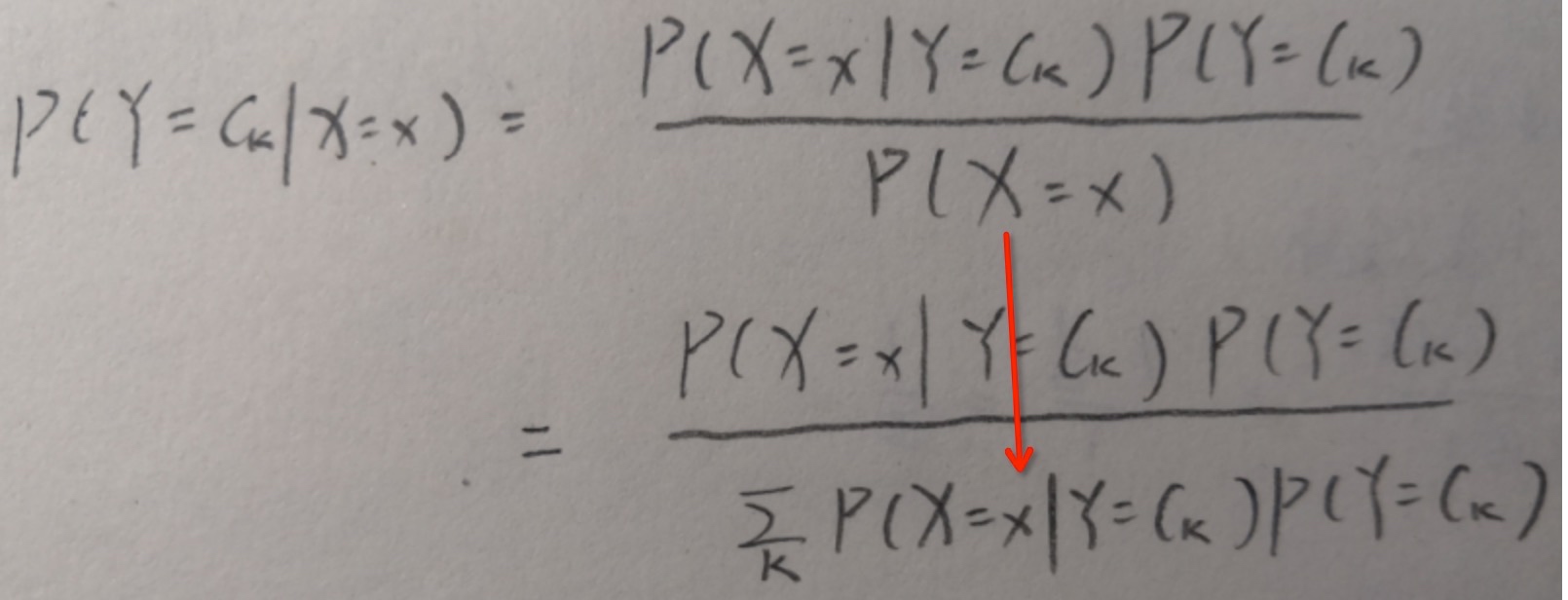
图中箭头为什么得到下边的结果?
P(X=x) 代表 X在整个样本空间发生的概率,改成下边的格式以后表示将整个样本空间分成ck份,每份上的概率累加与原来的概率是一样的
####另一种解释方式

- 注意:其中红框部分是X和Y的联合概率 Y=Ck是每个类别的概率 对所有类别求和的话结果就是1
以上是对一个样本来说的 如果扩展到每个样本 则有
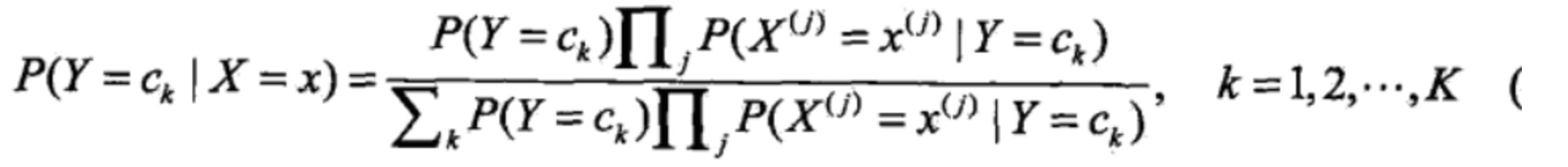
假设:
如果a,b相互独立:
P(a,b)=P(a).P(b)
P(a,b|c)=P(a|c).P(b|c)
和上图的式子进行比对,其实就是把P(X=x|Y=Ck)这一项变成了连乘,至于为什么能连乘,下图有详细说明:
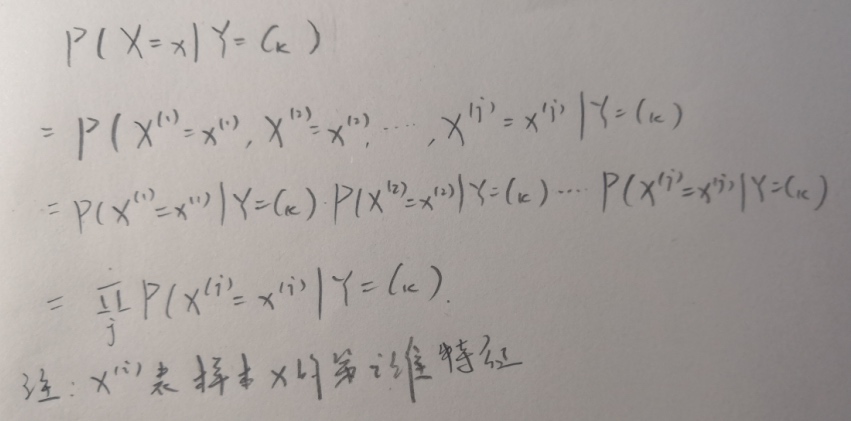
为什么可以把里面的直接拆开来连乘?概率老师不是说过只有相互独立才能直接拆吗?是的,朴素贝叶斯分类器对条件概率分布做出了条件独立性的假设。为啥?因为这样能算,就这么简单,如果条件都不独立,后面咋整?读者:那你这不严谨啊。emmm….事实上是这样,向量的特征之间大概率是不独立地,如果我们独立了,会无法避免地抛弃一些前后连贯的信息(比方说我说“三人成_”,后面大概率就是个”虎“,这个虎明显依赖于前面的三个字)。在建立模型时如果这些都考虑进去,会让模型变得很复杂,后来前人说那我们试试不管它们,强行独立。诶发现效果还不错诶,那就这么用吧。这就是计算机科学家和数学家的分歧所在。
上图中P(X=x|Y=Ck)转换成能求的式子了以后,那么就是比较Y为不同Ck的情况下哪个概率最大,那就表示属于哪个类的可能性最大。所以前头式子前头加上一个argmax,表示求让后式值最大的Ck。
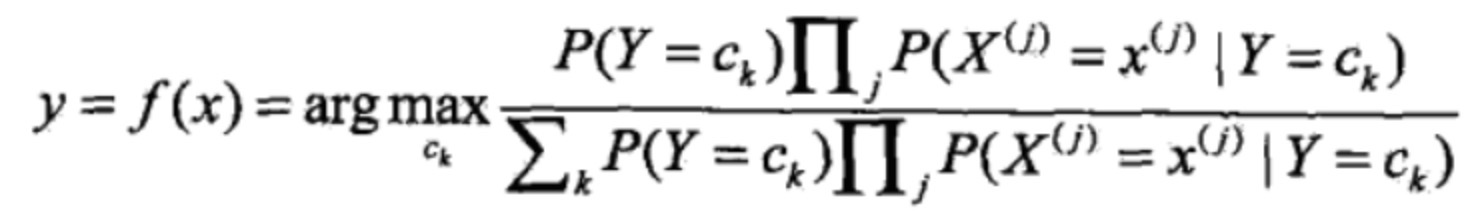
然后由于下图中圈出来这一项是在Y为不同Ck情况下的连乘,所以不管k为多少,所有Ck连乘结果肯定是一致的,在比较谁的值最大时,式子里面的常数无法对结果的大小造成影响,可以去掉。
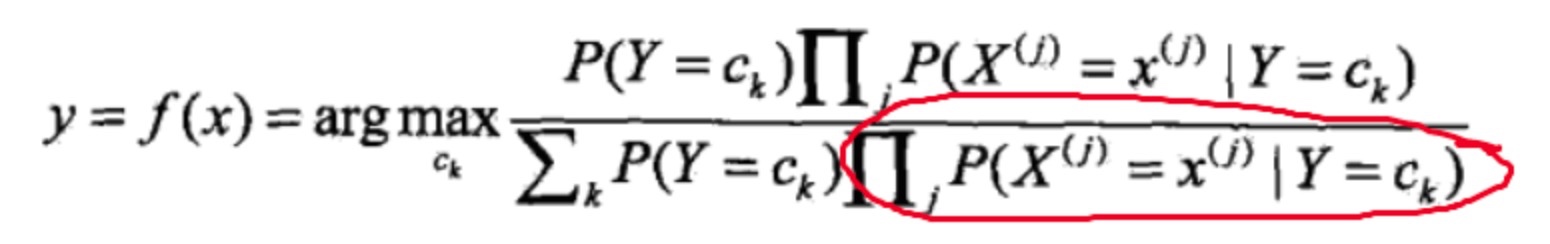
就变成了下面这样:
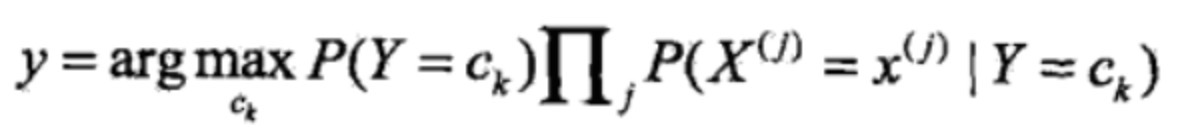
这一步开始没明白
其实分母 也就是红色的部分 第一项 P=(Y=Ck) 在整个像本空间累加的时候结果就是1
后边的乘的式子 在整个样本空间中 Y=Ck 一定发生所以是1 前边x在整个特征为j的样本空间的所有x的概率和也是1 所以可以直接省去分母 得到后边的公式。
统计学习方法-朴素贝叶斯原理剖析及实现
朴素贝叶斯完整推导过程

实际应用中是使用极大释然估计进行处理的

极大释然估计改进---贝叶斯估计

例题
-
计算步骤:

-
例题解析:


