3、统计学习方法--K近邻法(KNN)
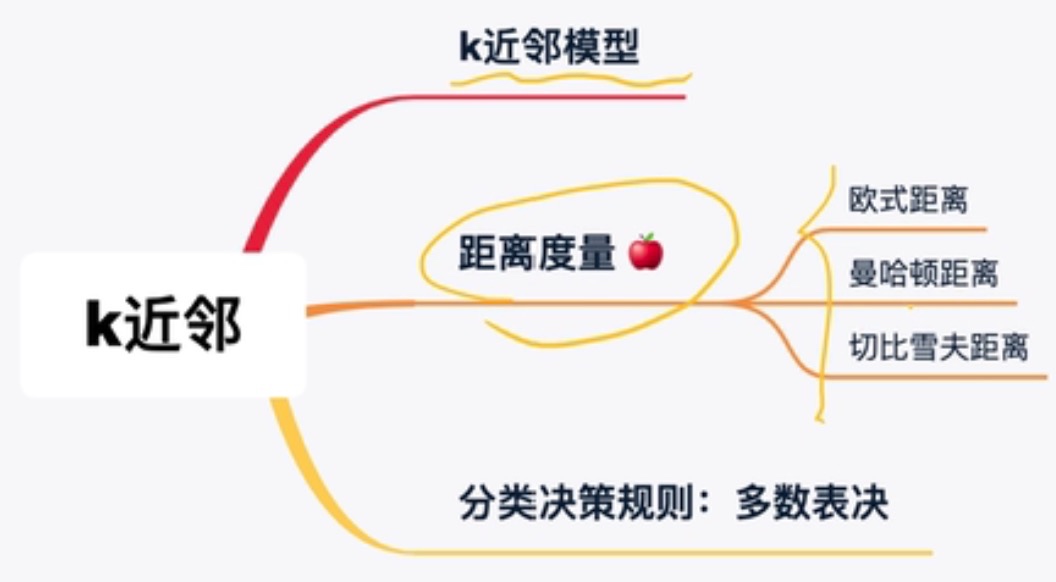
K近邻算法
一种基本分类与回归方法
k近邻算法
k近邻算法简单、直观:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把改输入实例分为这个类。
k近邻模型
- 三个基本要素:距离度量、K值的选择、分类决策规则
模型
当训练集、距离度量、K值及分类决策规则确定后,对于任何一个新的输入实例,它所属的类唯一确定。
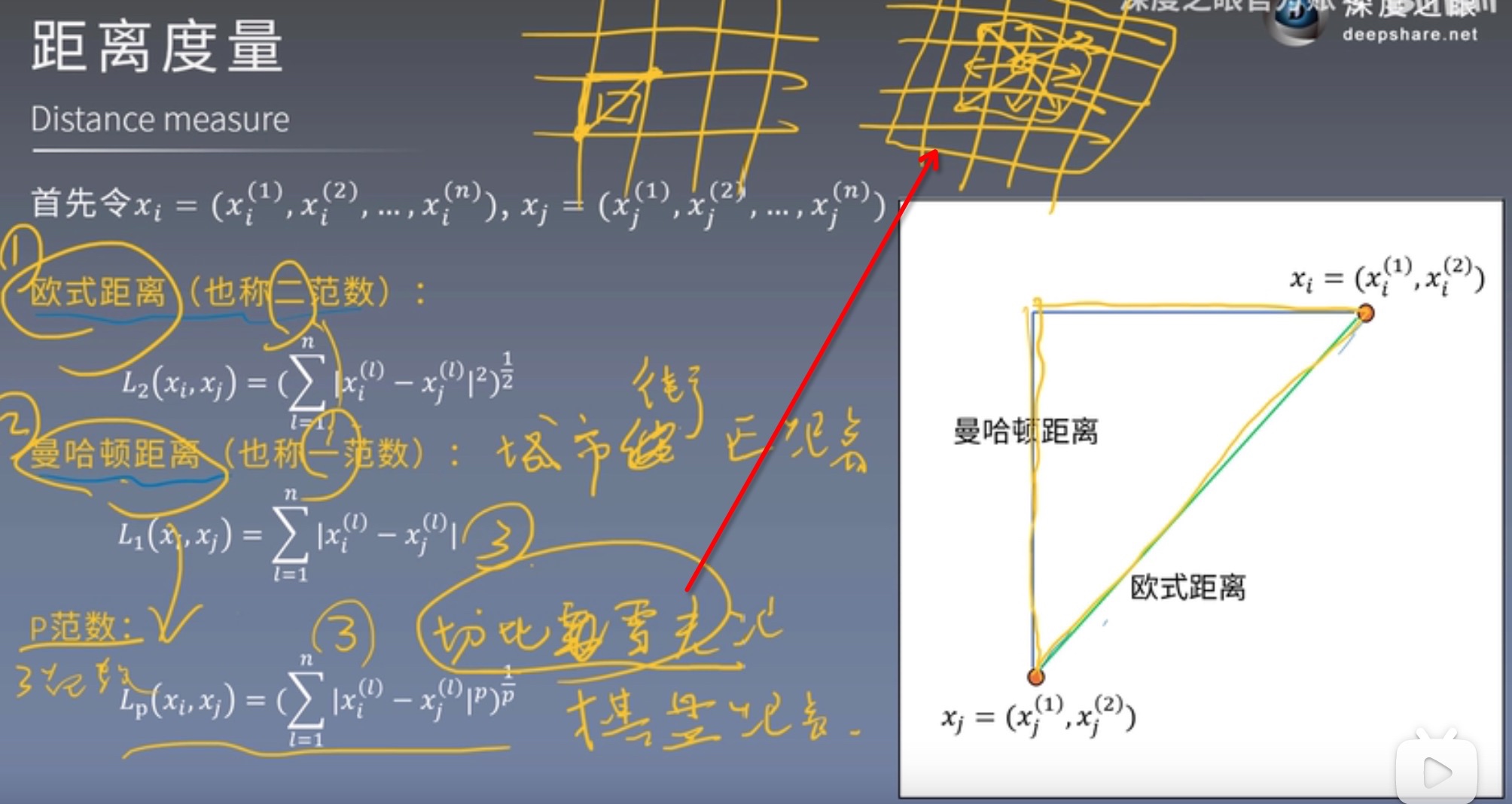
距离度量
- 一般欧氏距离用的比较多
不同的距离度量所确定的最近邻点是不同的


K值的选择
K值的选择对K近邻的结果影响重大

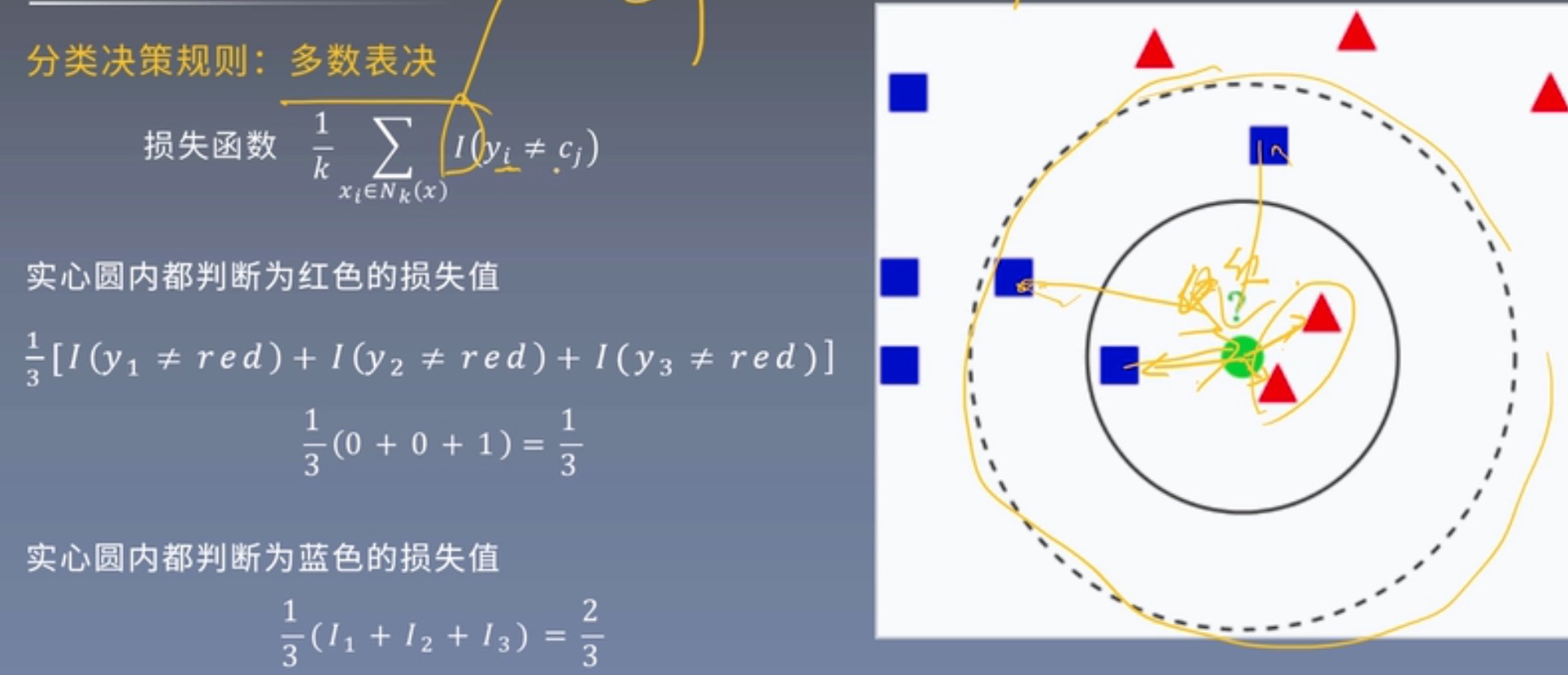
分类决策规则
k近邻法的实现:kd树
- 实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索,这点在特征空间的维数大以及训练数据容量大时尤其重要。
- 最简单的方法是线性扫描:训练集很大时非常耗时,这种方法是不可行的。
构造KD树
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的数形数据结构。
kd树是二叉树,表示对k维空间的一个划分,构造kd树相当于不断的用垂直坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd每一个节点对应于一个k维超矩形区域。

实例

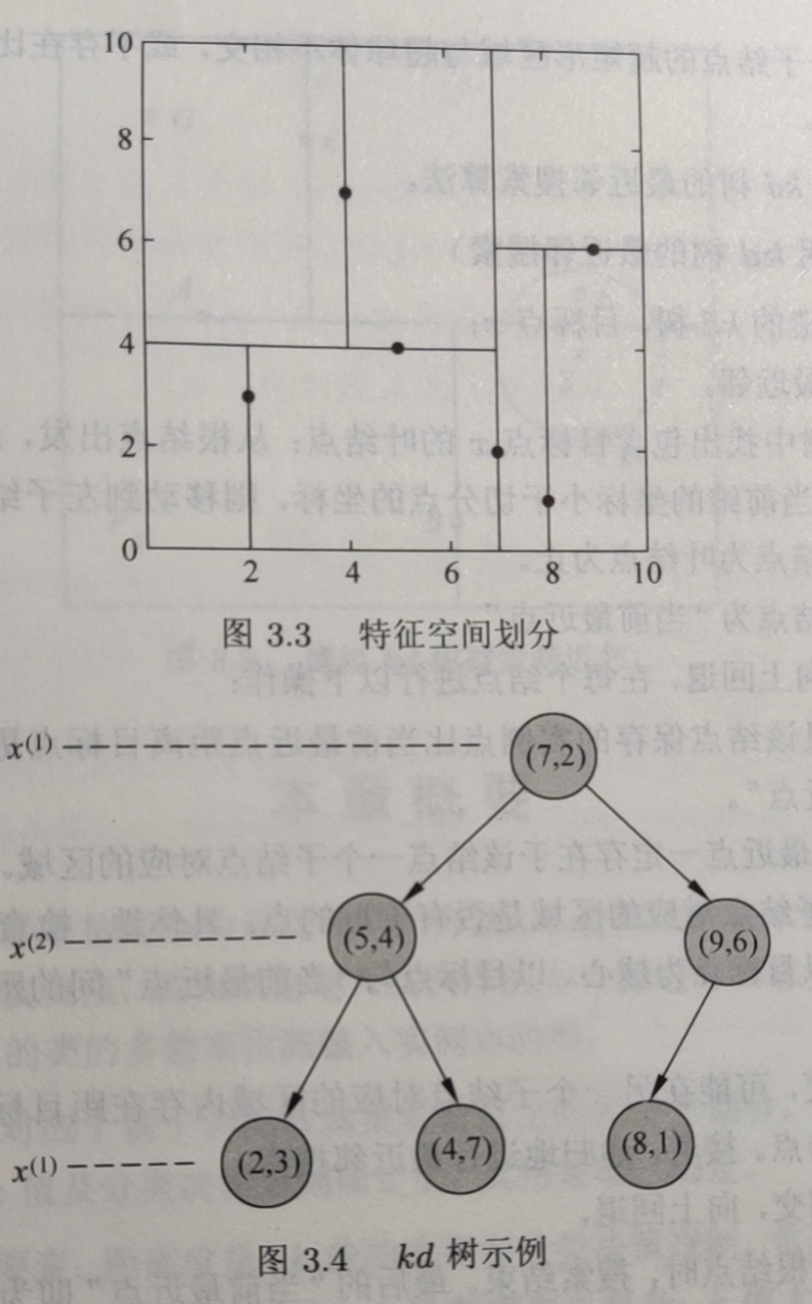
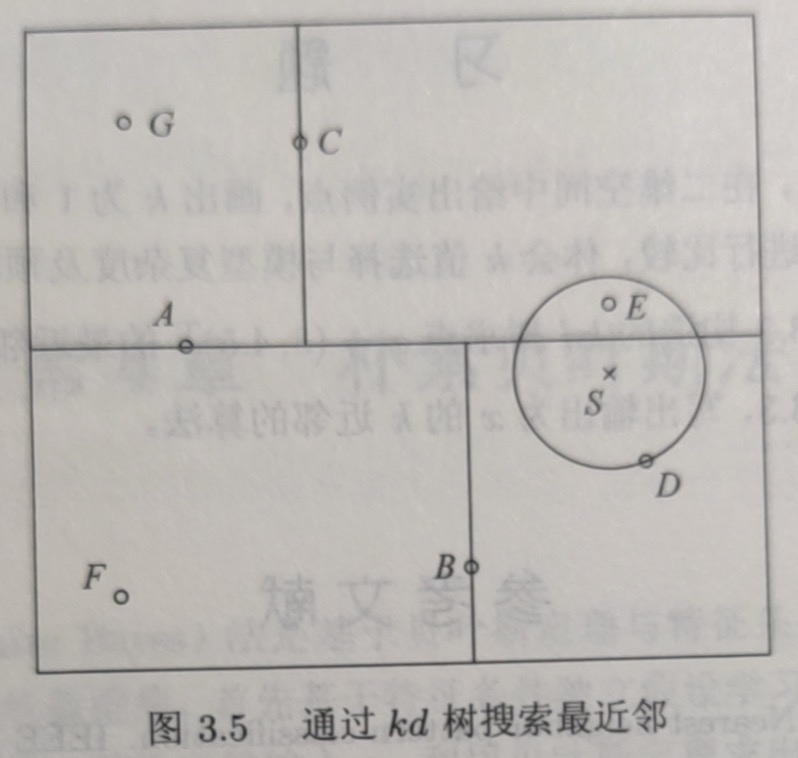
搜索KD树
给定一个目标点,搜索其最近邻。首先找到包含目标点的叶结点,然后从该叶结点出发,依次回退到父结点,不断查找与目标点最邻近的结点,当确定不可能存在更近的结点时终止,这样搜索被限制在空间的局部区域上,效率大为提高。

- 实例