第四次作业
HDFS 采用的是master/slaves主从结构模型来管理数据,这种结构模型主要由四个部分组成:Client(客户端)、Namenode(名称节点)、Datanode(数据节点)和SecondaryNamenode(第二名称节点,辅助Namenode)。一个真正的HDFS集群包括一个Namenode和若干数目的Datanode。Namenode是一个中心服务器,负责管理文件系统的命名空间 (Namespace )及客户端对文件的访问。集群中的Datanode一般是一个节点运行一个Datanode进程,负责管理客户端的读写请求,在Namenode的统一调度下进行数据块的创建、删除和复制等操作。数据块实际上都是保存在Datanode本地文件系统中的。每个Datanode会定期的向Namenode发送数据信息,报告自己的状态(心跳机制)。没有按时发送心跳信息的Datanode会被Namenode标记为“宕机”,“宕机”的Datanode不会被分配I/O任务。
HDFS集群中只有唯一的一个Namenode,负责所有元数据的管理工作。这种方式保证了Datanode不会脱离Namenode的控制,同时,用户数据也永远不会经过Namenode,大大减轻了Namenode的工作负担,使之更方便管理工作。通常在部署集群中,我们要选择一台性能较好的机器来作为Namenode。当然,一台机器上也可以运行多个Datanode,甚至Namenode和Datanode也可以在一台机器上,但是在实际运用中,为了给Namenode尽可能多的内存,不会有将Namenode和Datanode放在同一节点的情况。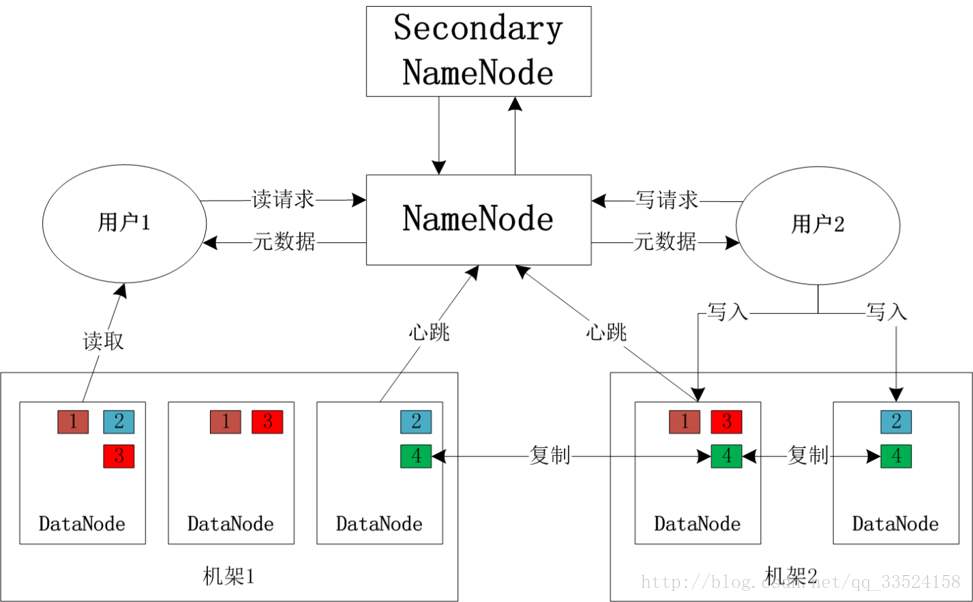
2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号