MYSQL查询性能优化
查询的基础知识
MySQL查询过程如下图所示:
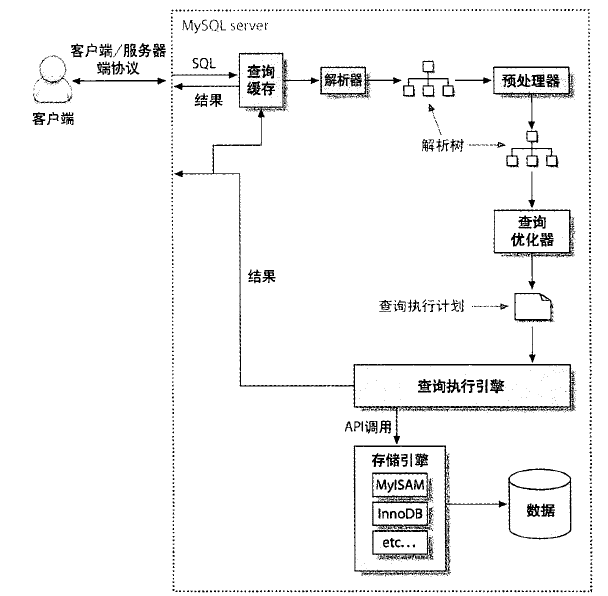
MySQL是通过查询语句的哈希查找来命中缓存的,需要注意的是如果查询语句大小写不一致或者有多余的空格,是不会命中缓存的。
一个查询通常有很多执行方式,查询优化器通过计算开销(随机读取次数)来选择最优的查询。
MySQL把所以的查询都当做联接来处理,联接是按照循环嵌套的策略来执行的,如下图所示:
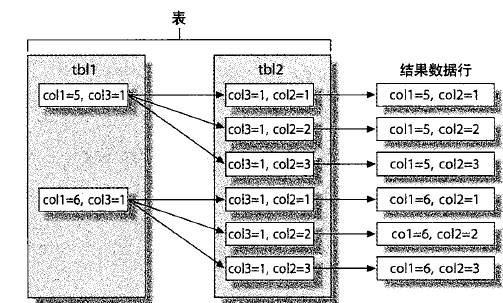
查询的优化和限制
我们需要知道查询优化器会做哪些优化,这样在写查询的时候就可以不需要考虑手动来做这些优化,把这些事情交给查询优化器去做是更好的选择,查询优化器的优化类型如下:
1. 联接优化
(1)对联接中的表重新排序


(2)将外联接转换为内联接
2. 排序优化
(1)使用索引排序
(2)内存快速排序
(3)文件排序
3. 优化COUNT()
(1)没有Where子句的COUNT(*):记录表的行数
(2)COUNT(column) 统计column非NULL的行数,column不可能为NULL时,COUNT(column)优化为COUNT(*)
4. 优化IN()
(1)对IN()里面的数据排序,进行二分查找,对IN()子查询不会使用这种优化,如:

5. 代数等价优化
(1)简化并规范化代数表达式
(a<b AND b=c) AND a=5 => b>5 AND b=c AND a=5
6. 早期终结
早期终结是指一旦满足查询的条件,MySQL就会立即停止处理该查询。
(1)LIMIT
(2)不可能的查询条件

(3)取得唯一值或值不存在

7. 其它优化
(1)索引优化MIN()和MAX()
(2)覆盖索引
(3)相等传递

查询优化器优化时存在一定的限制,在这些查询优化器不能很好地优化的地方,需要我们手动进行优化:
(1)关联子查询。如IN()可能优化得很差,如下面是个不好的优化


(2)联合(UNION)。有时不能把UNION外的条件应用到内部
(3)索引合并。排序和合并的开销可能很大
(4)相等传递。大IN表导致较慢的优化
(5)并行执行。不能在多CPU并行执行一个查询
(6)对同一个表SELECT和UPDATE

写出高效的查询
查询效率低的原因:
(1)应用程序获取了超过需要的数据
(2)MySQL服务器分析了超过需要的行
重构查询的方式:
(1)复杂查询和多个查询的权衡。用尽可能少的查询做尽可能多的事情有时候是不对的。
(2)缩短查询,防止查询长时间占用表


(3)分解联接
写查询时考虑以下的优化方法:
1. 优化联接
(1)ON或USING使用的列上有索引
(2)GROUP BY或ORDER BY只引用一个表的列
2. 优化COUNT()
(1)总是使用COUNT(*)
(2)对索引的小部分进行统计


(3)保存统计结果
3. 优化LIMIT和OFFSET
在覆盖索引上进行偏移
4. 优化子查询
尽可能使用联接代替IN、EXISTS、NOT EXISTS
5. 优化联合
(1)始终使用UNION ALL
(2)条件下推到UNION
6. 优化GROUP BY和DISTINCT
(1)索引优化
(2)ORDER BY NULL跳过自动排序
以下是常用的查询优化提示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号