
集成学习——rft & adaboost
集成学习
集成学习主要有两种思想:
- 集成弱学习器,提升分类能力
- 集成强学习器,提升泛化能力
Random Forest 随机森林 强分类器的方差(泛化能力)提升
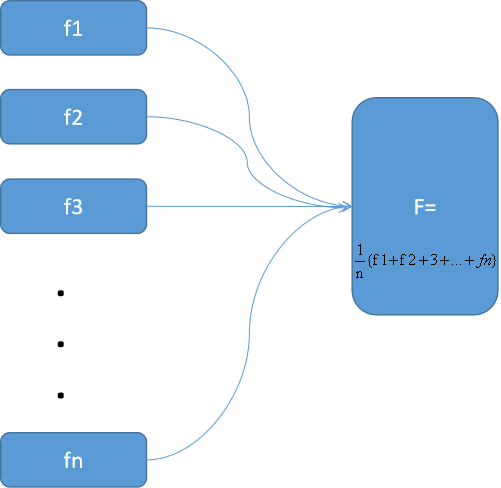
思想:若干个独立训练的分类器,并行训练,每个分类器对应于一个f1输出,得到(f1,f2,。。。,fn),求和取平均得到新的F。
选用什么分类器: DT、KNN等分类能力强的模型
理解:怎样确保独立?
- 训练数据的独立,每个分类器训练时使用的训练集之间相互独立:
- 例如,真实数据集合有100w条数据,随机抽取20w条数据作为训练集。
- 独立性要求抽取的比例不能太高,训练效果又要求训练样本不能太少。需要tradeoff
- 每组训练集的特征相互独立:
- 比如数据是n维度特征的,每组数据都随机抽取int(√n)位特征组成新的训练集。
| f1 | 0.9 |
| f2 | 0.88 |
| f3 | 0.92 |
假设分类前每个分类器的方差为D = δ2 ,两个分类器集成后
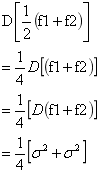
一般来说,继承之后训练器的方差在0.5δ2 ~ δ2 之间。
Adaboost 弱分类器的(偏差)分类能力提升
思想:若干个分类器串行训练,每一轮训练更新每个训练数据的权重和每个Gm模型的权重。知道M个分类器都训练完成,得到的分类器GM为所求分类器。
选用什么分类器: LR等弱分类器
算法:(学短板)
随机初始化第一轮训练集中每个数据的圈子中为1/n(共n组数据)
第m轮,
- 计算该轮分类的error(错误率)error = ∑wi*I(yi!=Gm(xi))
- 该轮分类器的权重αm为:αm = 0.5*log[(1-e)/e]
- 更新下一轮训练样本中数据的权重wm+1,i+1 = wm,i * exp(-αmm*yi*Gm(xi))
第m+1 轮,重复,第m轮步骤
直到训练完M个分类器。
posted on 2021-06-04 09:58 life‘s_a_struggle 阅读(117) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号