
SVM支持向量机--曾经的王者
SVM支持向量机--曾经的王者(硬间隔、软间隔、核函数、拉格朗日凸优化)

思路(SVM)
对于简单的情况,二位线性可分平面的分类,训练标注数据为[x, y]。为了提高模型的鲁棒性,和抗噪声能力。理论上存在一条宽度为D = 2d的隔离带。
两类数据分别再这条隔离带的两边。隔离带的确定,仅仅有支持向量所决定。
这样做的好处:
- 抗噪声能力:测试集的分类情况由支持向量确定的超平面决定,就算由噪声或者异常数据,也不会对支持向量的选取造成太大影响。
- 鲁棒性: 缓冲隔离带,更软。
假定找到的支持向量的数据集为SNŒ{[Xi,Yi},隔离带的中间分割线方程为 WX+W0,根据距离公式不难得到:
D = 2d = 1/|| w || (分子由于w的成倍缩放不会对直线的空间位置造成影响,所以必可以放缩为1)可以看作讲看空间的放大和缩小,比例尺
因此,我们需要得到一个确定w的“损失函数”。
- 因为希望分类效果好,我们希望D越大越好,即 min{|| w || }
- 为了保证分类正确,需满足:
![]()
![]()
![]()

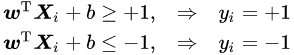
为使得形式统一: yi(wx+w0) >= 0
因此便得到了一个拉格朗日求极值的凸优化问题。由于数学证明过程十分复杂,数学水平有限,先把更多的精力放在学习模型思想上。

通过直接的数学推到最终得到: w = ∑αyixi(i 属于支持向量集SN)wo = 1 - w*xi
理解上式:
- α支持向量的权重,例如一个支持向量离其他支持向量远,α就大。如果两个支持向量技术重合,那么α=0.5.
- 带入任意测试数据得到wx = ∑αyixix,本质上是计算测试数据个支持向量的相似度,类似于k近邻
软隔离带(SVC)
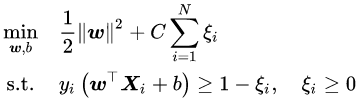
软间隔的隔离带由边界点和错误点一起决定,所以训练不光要找出边界的点,也找出了错误点。
软边距SVM是一个L2正则化分类器,式中表示铰链损失函数。使用松弛变量: 处理铰链损失函数的分段取值后。
处理铰链损失函数的分段取值后。
某种程度上,软间隔使得SVM获得了一定的稀疏性,但这种稀疏性,也仅仅对少量稀疏有着不错的效果,对大量稀疏特征处理人不是很好。
关于超参数C如何学习, 网格搜索。
理解上式:
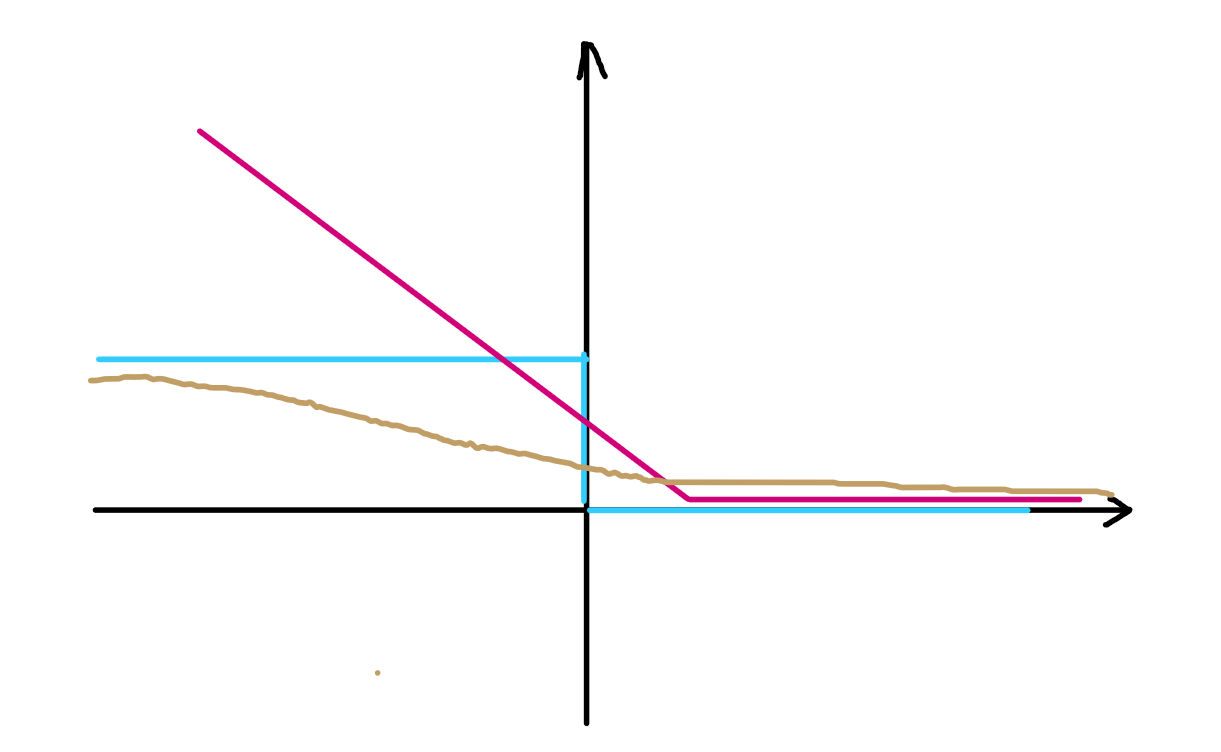
- 对比LR的L2正则式子可以将式子看作:min{|| w || } + C∑(1-yi(wx+w0)) “hingle距离”
- 正则项 损失函数
- 紫色的函数再svm下,最好,再分类正确的情况下没有间隔(不用学习),再分类错误的时候产生软间隔(学习),同事再分类正确打的时候也有一定的鲁棒性。
- 蓝色函数在分类和错误的时候都没有学习。
- 黄色函数,一直在学习
1 from sklearn import svm 2 import numpy as np 3 from sklearn.model_selection import GridSearchCV 4 5 6 def read_data(path): 7 with open(path) as f: 8 lines = f.readlines() 9 lines = [eval(line.strip()) for line in lines] 10 X, y = zip(*lines) 11 X = np.array(X) 12 y = np.array(y) 13 return X, y 14 15 16 X_train, y_train = read_data("train_data") 17 X_test, y_test = read_data("test_data") 18 19 20 # C对样本错误的容忍,带松弛变量的SVM 21 22 model = svm.SVC() 23 # #非常慢 24 model.fit(X_train,y_train) 25 print(model.support_vectors_) # 打印支持向量的点 26 print(model.support_) 27 print(len(model.support_)) # 打印支持向量的索引 28 score = model.score(X_test, y_test) 29 print(f"score: {score}") 30 31 32 # # 网格搜索 33 # search_space = {'C': np.logspace(-3, 3, 7)} 34 # print(search_space['C']) 35 # model = svm.SVC() 36 # gridsearch = GridSearchCV(model, param_grid=search_space) 37 # gridsearch.fit(X_train, y_train) # 训练集划分成子训练集和有效集进行网格化搜索 38 # cv_performance = gridsearch.best_score_ 39 # test_performance = gridsearch.score(X_test, y_test) 40 # print("C:", gridsearch.best_params_['C'])
核方法
核方法主要解决的是升维之后内积计算的问题。
| 无核函数 | 有核函数 | |
| WX | ∑αyi<xi·x> | ∑αyi<Φ(xi)·Φ(x)>=∑αyi<x·z>2 |
| 训练数据X | x | Φ(x)不关心 |
| 支持向量Xi | xi | Φ(xi)不关心 |
SVM发展的20年来,总结下来,使用最多的三个核函数:
-
‘linear’:线性核函数
-
‘poly’:多项式核函数
-
‘rbf’:径像核函数/高斯核
1 from sklearn import svm 2 from sklearn import datasets 3 from sklearn.model_selection import train_test_split as ts 4 ''' 5 ‘linear’:线性核函数 6 ‘poly’:多项式核函数 7 ‘rbf’:径像核函数/高斯核 8 ‘sigmod’:sigmod核函数 9 ‘precomputed’:核矩阵 10 ''' 11 #import our data 12 iris = datasets.load_iris() 13 X = iris.data 14 y = iris.target 15 16 #split the data to 7:3 17 X_train,X_test,y_train,y_test = ts(X,y,test_size=0.3) 18 print y_test 19 # select different type of kernel function and compare the score 20 21 # kernel = 'rbf' 22 clf_rbf = svm.SVC(kernel='rbf') 23 clf_rbf.fit(X_train,y_train) 24 score_rbf = clf_rbf.score(X_test,y_test) 25 print("The score of rbf is : %f"%score_rbf) 26 27 # kernel = 'linear' 28 clf_linear = svm.SVC(kernel='linear') 29 clf_linear.fit(X_train,y_train) 30 score_linear = clf_linear.score(X_test,y_test) 31 print("The score of linear is : %f"%score_linear) 32 33 # kernel = 'poly' 34 clf_poly = svm.SVC(kernel='poly') 35 clf_poly.fit(X_train,y_train) 36 score_poly = clf_poly.score(X_test,y_test) 37 print("The score of poly is : %f"%score_poly)
posted on 2021-06-02 16:53 life‘s_a_struggle 阅读(146) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号