
4.推荐系统之内容召回1——基于行为的
推荐系统之内容召回2——基于行为的
以短视频推荐为例
| 类 | user和video的关系 | 信息 | |
| C1 | 没见过的video | 海量video | |
| C2 | 见过,但未点击的video | user不感兴趣,视频量很大 | Negative(VN) |
| C3 | 见过并点击观看 | user感兴趣,少量的一部分 | Postive(VP) |
| C4 | 点击观看并且,点赞评论关注收藏 | 强烈兴趣,珍贵资源,量很少 | Love(VL) |
| C2 | (VN1) | (VN2) | (VN3) | ...(VNi) |
| C3 | (VP1) | (VP2) | (VP3) | ...(VPj) |
| C4 | (VL1) | (VL2) | (VL3) |
根据上表分析出的各类视频量对的关系不难得到:
similiar(P-L)很小 similiar(N-L)很大,juci,构建损失函数:
从用户样本中随机抽取1个Love样本,s个不Negative样本,s个Positive演变嫩。样本相似度去向量内积<VN·VP>
S(P,L) = 1/(1+e-<VP·VL>)
S(N,L) = 1/(1+e-<VN·VL>)
LOSS = -∑[1/(1+e-<VP·VL>)]+ ∑[1/(1+e-<VN·VL>)]
一个人的行为可以产生多条行为样本:
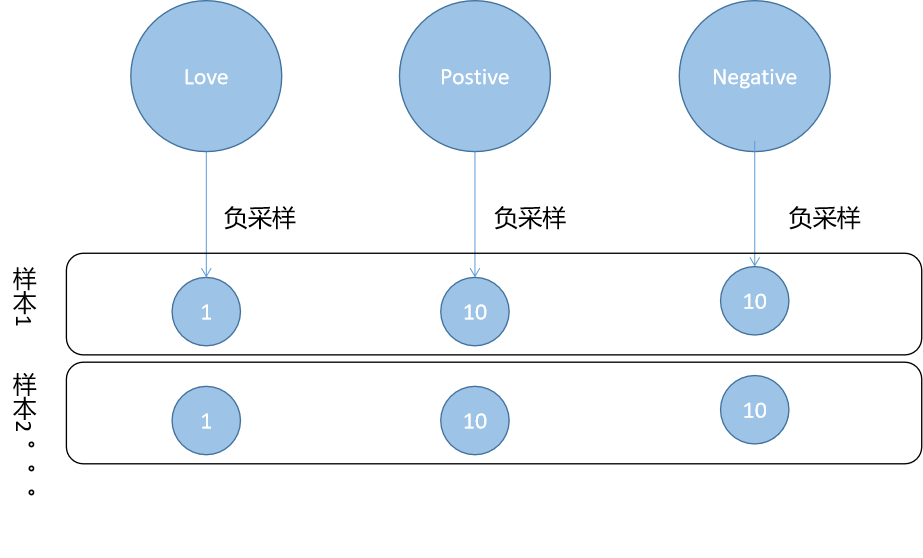
由此,我们能得到
L =
User1:Loss1+Loss2+Loss3...
+
User2:Loss4+Loss5+Loss6...
+
User3:Loss7+Loss8+Loss9...
+
...
优化
- 用户行为的数据存爱噪声
- 对于点击狂魔,降低点击次数
- 超热门item,降低采样次数(正样本),提升采样次数(负样本)
- 损失函数从形式上可以优化的更统一
- LOSS = - ∑[1/(1+e-<VP·VL>)] + ∑[1/(1+e-<VN·VL>)] ---->简化前
- LOSS = ∑[1/(1+e<VP·VL>)] + ∑[1/(1+e-<VN·VL>)] ---->简化后
- 这样做是为了后面学习Airbnb论文
- 向量空间优化
- L、N、P三个向量取自三个不同的向量空间,各自embedding
![]()
-
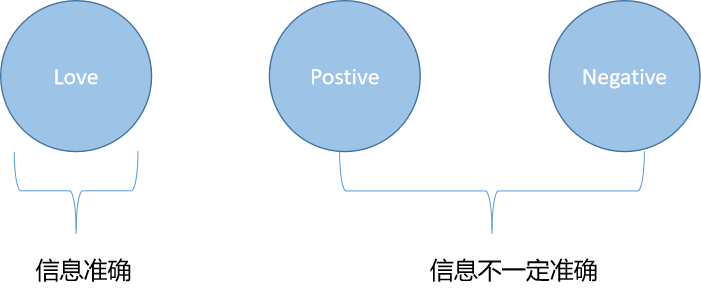
因为用户的行为中,Love类样本信息反映最为准确,所以对应出来的向量最有价值。正负样本的采样只在训练时使用。
posted on 2021-05-14 12:02 life‘s_a_struggle 阅读(138) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号