
word2vec by Goggle
word2vec
14年被谷歌搞出来的,社交领域运用十分广泛,并很快被除了文本中之外的其他邻域运用。
首先,了解什么是语言模型:
- 判断(计算)一句话合理的概率
- 用周边词预测一个位置出现词的概率(类似于完形填空)
一、模型构建:
step1 :
假设我们有一个sentence:w1, w2, w3, w4
根据贝叶斯估计,计算sentence合理的概率
p(w1, w2, w3, w4) = p(w1)·p(w2 | w1)·p(w3 | w1, w2)·p(w4 | w1, w2, w3)
随着句子复杂度增加,词数增多,运算难度会越来越大。需要优化》》》》》》》》
step2:
slide窗口 = n 每个词的概率仅仅由前面的几个词决定。未来降低复杂度,目前最多n取2.
n=1 ==>O(v2)
n=2 ==>O(v3)
n = 1时,简化p:
p(w1, w2, w3, w4) = p(w1)·p(w2 | w1)·p(w3 | w2)·p(w4 | w3)
牺牲了前面词对靠后一点词的影响,获得了运算上的简化。
如何求p(w2 |w1)
| 文章 | 1 | 2 | 3 | .... |
| sentence1 | w1 | w2 | w3 | w... |
| sentence2 | w1 | w4 | w2 | w... |
| sentence3 | w1 | w5 | w6 | w... |
| sentence4 | w1 | w2 | w7 | w... |
p(w2|w1) = 2/4 = 0.5
p(w4|w1) = 1/4 = 0.25
存在问题:P(w1|w7)= 0,显然任何一个概率为0都是我们不想看到的。
step3:
假设语料库中一共有v个词,假设每个词出现了v次。(相当于认为扩大了语料库)
于是p(w2|w1) = (w2 +c)/(4 +7c)
当c = 1时:
| 文章 | 1 | 2 | 3 | .... |
| sentence1 | w1 | w2 | w3 | ... |
| sentence2 | w1 | w4 | w2 | ... |
| sentence3 | w1 | w5 | w6 | ... |
| sentence4 | w1 | w2 | w7 | ... |
| 假设语料库 c =1 | ||||
| w1 | w1 | *7 | ... | |
| w1 | w2 | *7 | ... | |
| w1 | w3 | *7 | ... | |
| w1 | w4 | *7 | ... | |
| w1 | w5 | *7 | ... | |
| w1 | w6 | *7 | ... | |
| w1 | w7 | *7 | ||
step4:神经元降低复杂度
silde = n = 1
一种理论上可行的方法:
词向量w2,onehot编码作为输入(0,1,0,0,...)
经过DNN,最后通过softmax,输出每个词出现的概率。
silde = n = 2
词向量w2,onehot编码作为输入(0,1,0,0,...)
词向量w3,onehot编码作为输入(0,0,1,0,...)
经过DNN,最后通过softmax,输出每个词出现的概率。
| 概率 | 神经元 |
|
p(wi |w2,w3) p(wi |w2,w4) |
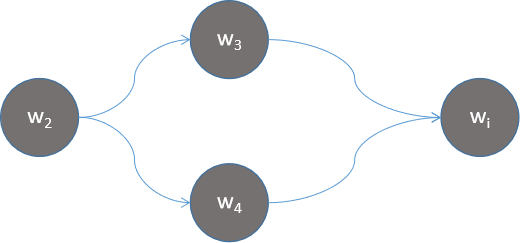
|
| O(v3) | O(2v2) |
| 每个都是独立参数 | 共用神经元 |
存在问题:onehot编码参数太多,参数特征稀疏,只能代表词位置,不具备物理意义(语义)。我们希望时构造一个语言模型,显然onehot编码时不能满足要求的。
step5:
用稠密方法替代向量,随机初始每个词向量为一个n维的向量(一般n取128)
这样做的好处时,可以用两个词向量的距离来表示语义上的相似度,这显然是onehot做不到的,因为onehot编码,所有词向量都是两两正交的。
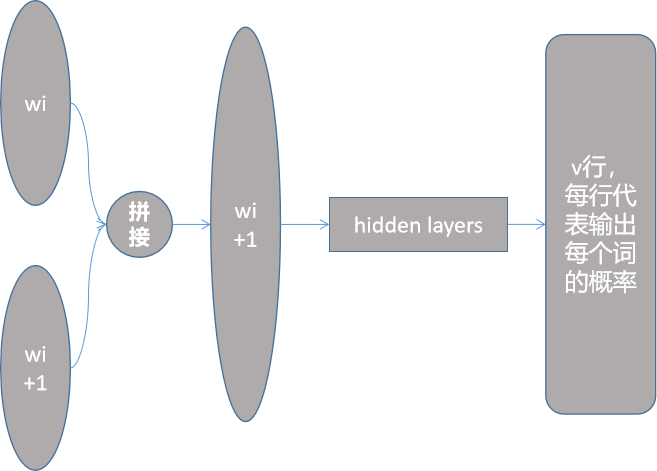
step6:降低输入参数
 例如:(1,2,3)+(2,1,1) = (3,3,4)
例如:(1,2,3)+(2,1,1) = (3,3,4)
输入向量按位相加,带来了信息的损失,丧失部分语义,带来参数量的降低。
这样做的好处,向量相加之后的向量不会随着输入词的增多而增长。n-gram的n无论是多少,输入都是128维向量。
缺点:我们来看输出,输出是v行128维的向量,通过soft'max得到它计算量任然比较大。
step7:

对训练集来说,使用二分查找来进行多个LR训练,可以把运算量级,从v降到logv。
结合中文词的特点:长尾分布。很少的词使用频率很高,大量的词不怎么被使用。
可继续用huffman树,通过词频建树查找优化
例如;
| 词 | a | b | c | d | e |
| 词频 | 10 | 8 | 5 | 3 | 4 |
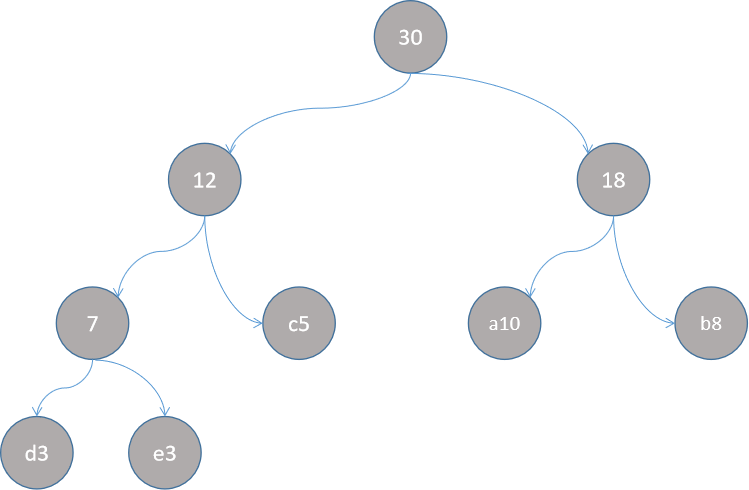
step8:
实际训练的时候设置超参数scild窗口数,例如窗口数为2时,一个句子,从前往后扫描,step=1词,每次扫描五个词。来训练。
二、总结
- 这个模型本质时语义模型,是为了预测某个位置上出现词的概率。但是实际几乎没人这么用。用的更多的时,随机初始化词向量,经过训练之后,得到的词向量文件。这个副产品反而时用的最多。
- 理解霍夫曼树为什么是动态的:
- huffman整体结构有每个词的词频决定
- 整体语料根据窗口数大小生成不同的训练样本
- 这些训练样本使用的huffman'树是同一颗
- 每个训练样本对应的目标词不一样,因此不同的训练样本在huffman树上走的路线不相同。
posted on 2021-05-13 16:20 life‘s_a_struggle 阅读(85) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号