
AI人工智能学习-Day1
注意:开启课程前,先了解学习AI为了什么?需要掌握哪些基础。
如果学习枯燥,可以参考华为开发者学堂视频课程。
一、课程介绍
1、人工智能发展历程
1945年艾伦图灵在论文《计算机器域智能》中提出了著名的图灵测试,给人工智能的发展产生了深远的影响。
1951年,马文-明斯基(Marvin Minsky)和迪恩艾德蒙(Dean Edmunds)建立了“随机神经网络模拟加固计算器”SNARC。
1955年8月31日,“人工智能”(artificial intelligence)一词在一份关于召开国际人工智能会议的提案中被提出,正式宣告人工智能作为一门学科的诞生。
在1965年麻省理工学院约瑟夫维森班(Joseph Weizenbaum)间建立了世界上第一个自然语言程序ELIZA。
70年代开始,科学家的成果无法满足社会的期待,有限的计算机能力和快速增长的计算需求之间形成了尖锐的矛盾。
人工智能进入第一个冬天。
1981年,日本国际贸易和工业部提供8.5亿美元用于第五代计算机项目研究。
1986年10月,大卫鲁梅尔哈特(David Runmelhart)、杰佛里辛顿(Geoffrey Hinton)和罗纳德威廉姆斯(Ronald Williams)发表了一片具有里程碑意义的经典论文《通过误差反向传播学习表示》。
80年代后期,产业界发现对专家系统的开发与维护成本高昂,商业价值有限,在失望情绪的影响下,对人工智能投入大幅消减,人工智能的发展再度进入冬天。
2、人工智能前景
国家层面大力发展;
发展驱动力
GPU芯片加速计算力:推动矩阵、向量计算;
人才培养与教育
人工智能基础(幼儿园——大学)
AI巨头公司布局
百度AI城市——上海;
华为云AI——水务环保燃气;
人工智能在各行各业的应用
安防:天眼计划,分析人类生活轨迹,应用视觉技术,打造智慧城市;
金融:利用语音识别、语音理解等技术打造智能客服,识别电话诈骗;
医疗:智能影像可以快速进行癌症早期筛查,帮助患者更早发现病灶;
交通:无人驾驶通过传感器、计算机视觉等技术解放人的双手和感知,例如,特斯拉Models3解放人的双手和感知;
零售:利用计算机视觉、语音/语音的识别,计算机视觉提供更好的消费体验,分析个人偏好,定向实现真实需求;
工业制造:机器人代理工人在危险场所完成工作,在流水线上高效完成重复工作,导致一批重复劳动力失业;
3、人工智能定义
通过机器来模拟人类认识能力的一种科技能力。
核心能力是根据给定的输入做出判断或预测。
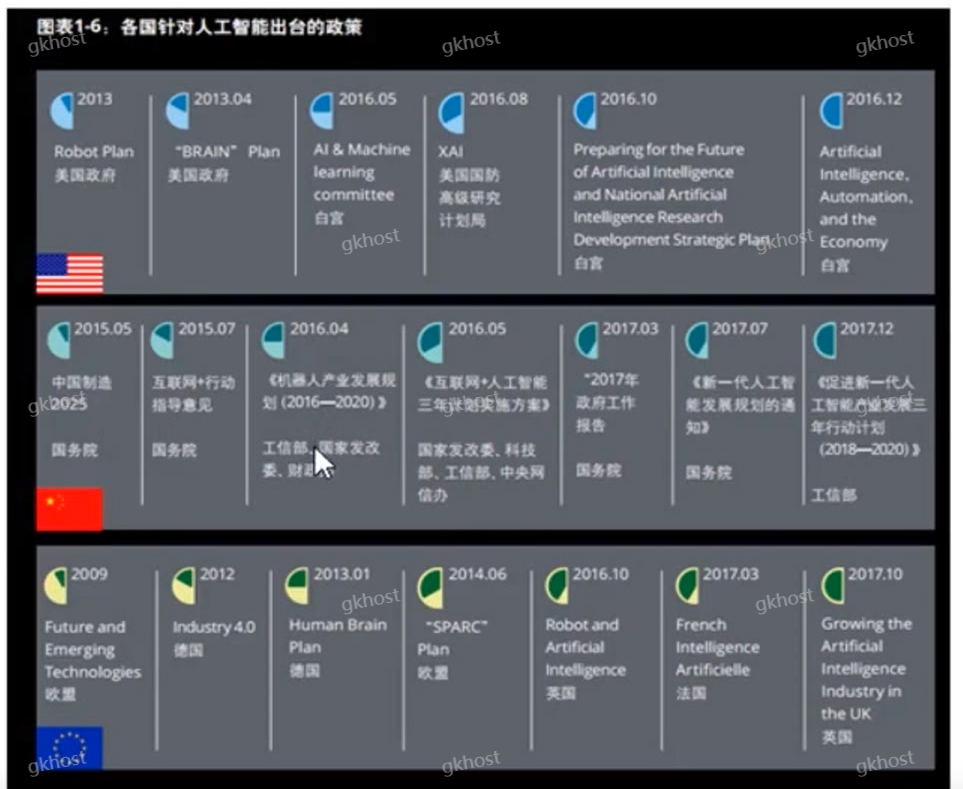
思考:通过什么途径才能让机器具备这样的能力?识别训练数据的模型,分析规律的能力,称为机器学习。
模型的定义:每个数据特征输入机器中,训练得出计算算法;
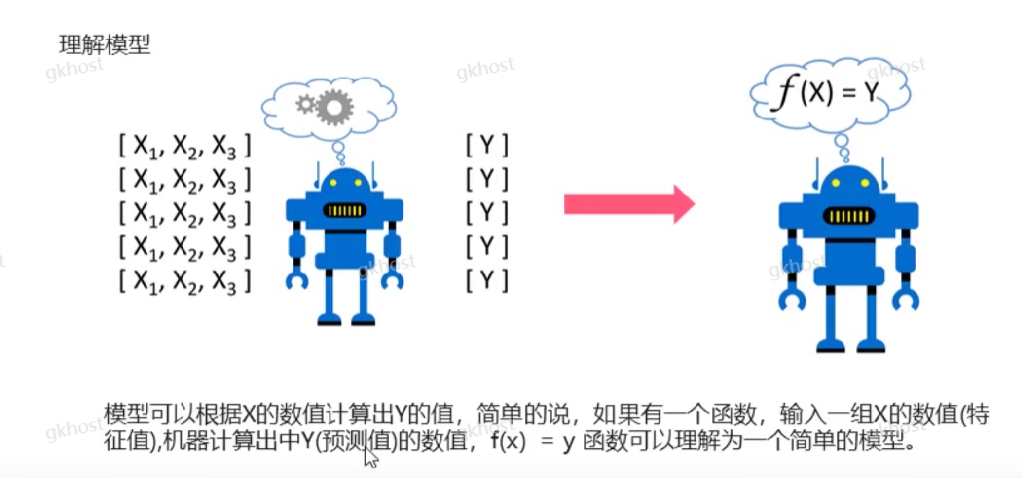
假设如果特征值有n个,实现多维的算法模型,计算大规模的数据;
群体:召集一批人员举重;
收集方式:手腕上的传感器收集数据;
历史数据:收集数据X1~Xn;
函数或模型:f([x])=y
4、监督学习
回归
从给定的训练数据集(历史数据)中学习出一个函数(特征提取,总结成一个函数),当新数据到来时,可以根据这个函数预测结果(验证当前函数或模型);
准备数据:包含输入和输出,也可以说是特征和目标。
线性回归举例一:
假设有一项健康运动的研究调查,通过手段传感器收集一些健康者的数据;
数据结构:
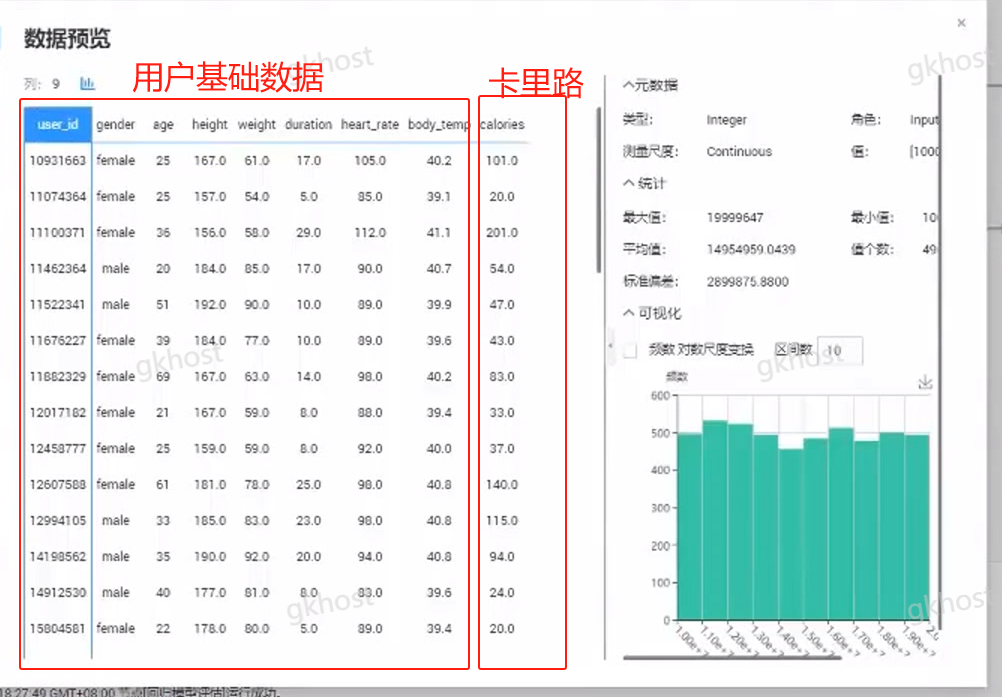
训练集(准备1000人的训练数据):提前准备的原始数据,存放到训练模型的数据库中;
训练数据:包含性别、身高、体重、年龄、心率、运动时长、体温、消耗的卡里路数据;
训练后得到的消耗结果:通过手腕传感器收集卡里路;
预测结果:输入特征值(训练集),得到我们需要的预测函数及训练模型;
例如:预测函数
f([27,1,60,165,134,37,25]) = 231
函数:f([X1,X2,X3,X4,X5,X6,X7]) = Y
目标数据:预测卡里路,通过预生成的函数(训练模型)加载训练集数据,不断完善函数输出近似预测值的卡里路值(训练结果);
演示:数据处理及示意图(华为云平台:机器学习服务MLS)
参考:https://connect.huaweicloud.com/courses/learn/Learning/sp:cloudEdu_?courseNo=course-v1:HuaweiX+CBUCNXE036+Self-paced&courseType=1
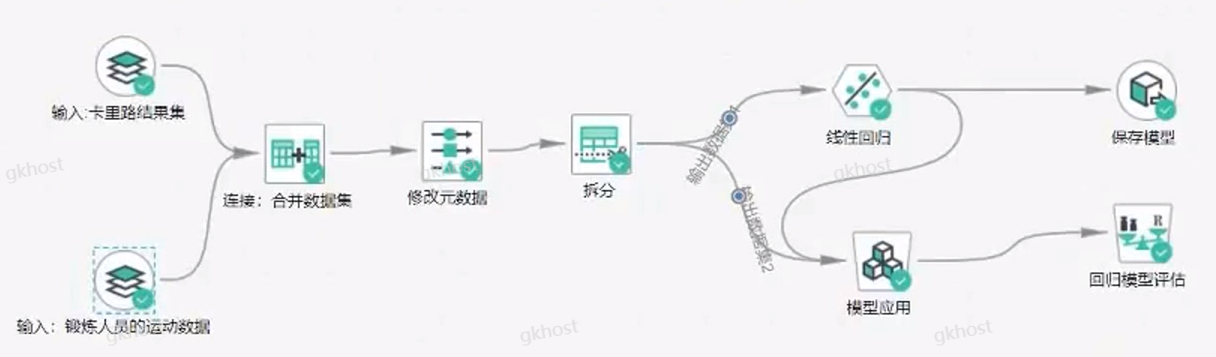
训练的工作流程:
数据集——两个输入部分
-
-
-
- 锻炼人员的运动数据,存放在机器学习平台的数据库中,即excel的*.csv文件中;
- 卡里路数据,运动传感器收集的数据,即训练后的卡里路消耗的目标数据,即预测数据;
- 下图即机器学习真正所需数据,将数据集喂给机器找到其中的规律,实现训练函数的目的;
-
![]()
-
-
元数据——是否参加训练的变量名
-
-
-
- 定义元数据:定义特征值即INPUT角色,None角色是非特征;
-
-
数据拆分——70%数据集用作训练,30%数据集用作验证
输出部分——回归的监督学习
算法选择——线性回归算法
学习结果:通过70%数据集通过线性回归算法得到实际的训练结果,与30%数据集进行验证,评估当前保存的模型即函数,是否满足我们的需求;
回归模型的评估标准
以下三个参数作用:指评分真实值与预测值之间的误差,在多次建模的过程中,每一次建模结果都会产生一组误差值,评判一个回归模型好坏的方法就是看这三个误差值是否变小或者变大,误差值越小表示回归模型越好。
注意:
真实值:通过传感器收集运动员的卡路里数据;
预测值:通过输入锻炼人员的基础数据,经过回归模型即函数计算得到的卡路里数据;
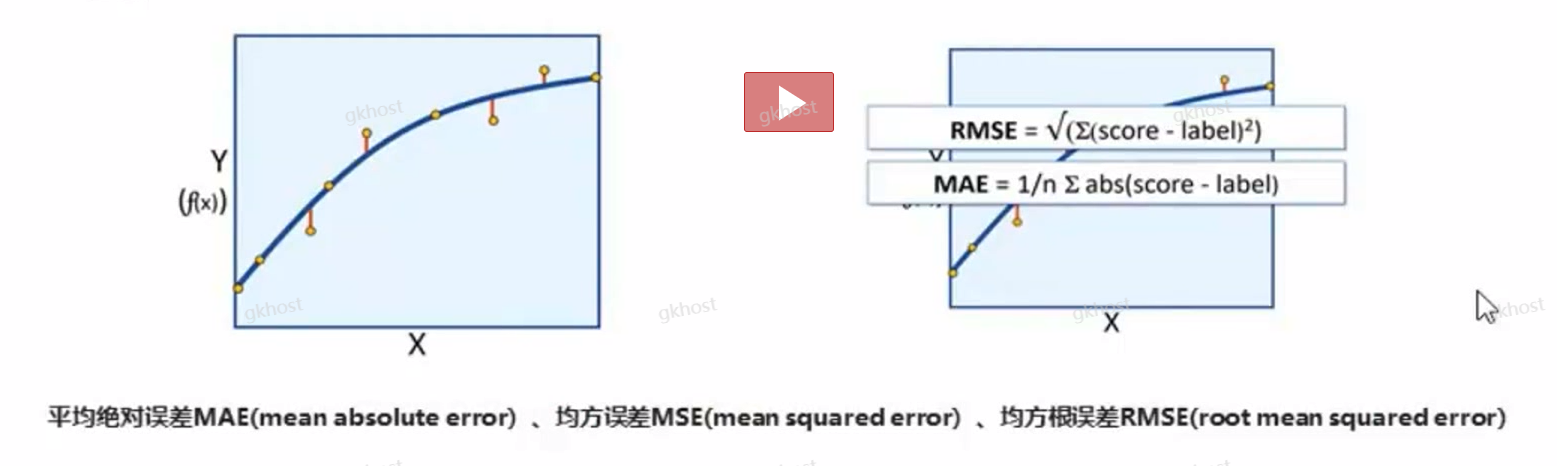
一组误差值:误差值越小,模型越好;并产生回归模型的评估值MAE、MSE、RMSE的一组误差值;
下图,左边第一图,原点越接近抛物线,变化值越小,RMSE误差越小,表示模型效果越好;
-
-
-
- MAE平均绝对误差:
((模型计算得到卡路里值-传感器收集的卡路里值)1+……+(模型计算得到卡路里值-传感器收集的卡路里值)n )/n
- MSE均方误差
- RMSE均方根误差:
((模型计算得到卡路里值-传感器收集的卡路里值)12+……+(模型计算得到卡路里值-传感器收集的卡路里值)n2 )/n,再求根
- MAE平均绝对误差:
-
-
-
-
-
-
均方根误差,它是观测值与真值偏差的平方和观测次数n比值的平方根,在实际测量中,观测次数n总是有限的,真值只能用最可信赖(最佳)值来代替.方根误差对一组测量中的特大或特小误差反映非常敏感,所以,均方根误差能够很好地反映出测量的精密度。均方根误差,当对某一量进行甚多次的测量时,取这一测量列真误差的均方根差(真误差平方的算术平均值再开方),称为标准偏差,以σ表示。σ反映了测量数据偏离真实值的程度,σ越小,表示测量精度越高,因此可用σ作为评定这一测量过程精度的标准。
![]()
-
-
-


分类
分类举例一:
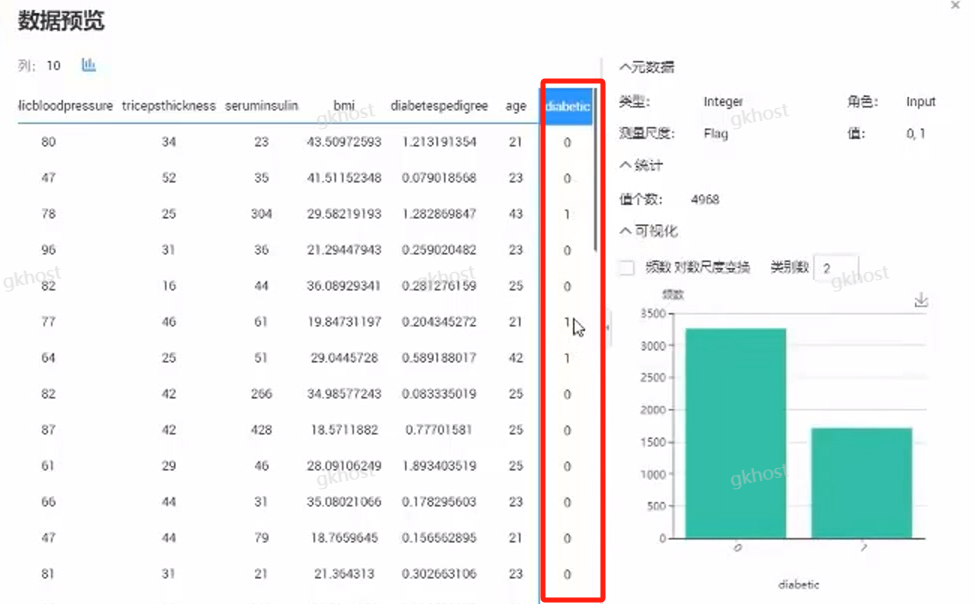
假设有一家诊所,收集到患者的一些信息,例如血糖指数、心脏血压、年龄、身体质量指数等信息,并且已标注糖尿病患者和非糖尿病患者(1和0),利用数据训练一个模型来做预测。
分类目的:通过患者身体指标,将患者分为两类,类值1和0标识这两类人群;
分类类值:自定义类值的对应关系;
糖尿病患者:1
非糖尿病患者:0

模型(函数):f([X1,X2,X3,X4]) = Y[1|0]
函数值接近0或接近1;
数据集:包含血糖指数、心脏血压、年龄、身体质量指数等信息,通过模型计算出是否糖尿病指数0或者1;
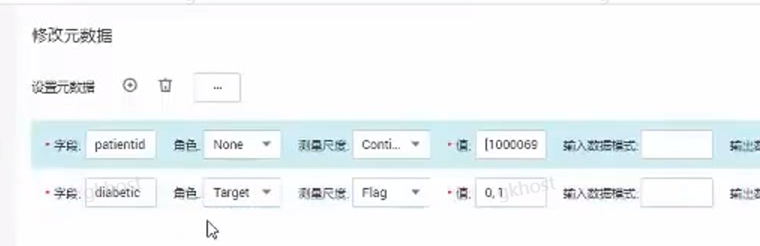
修改元数据:
参数患者id无效数据,置为none;
参数糖尿病diabetic的值置为0或1;

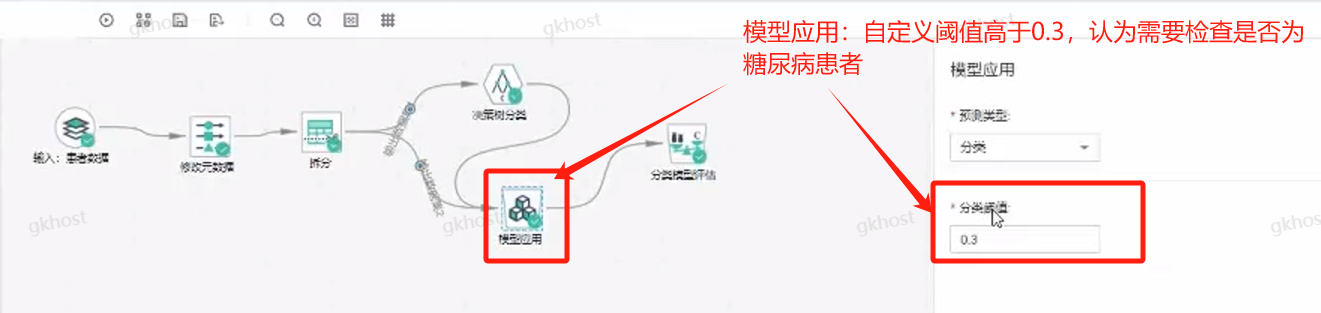
数据拆分——拆分模块定义70%数据集用作训练(“子数据集的百分比”70),模型应用模块定义30%数据集用作验证;

输出部分——当前学习大概一分钟左右,输出模型;
算法选择——决策树算法,通过判断条件经过逐层的判断,得出最终的概率值;

学习结果:根据“模型应用”中的分类阈值大于0.3的概率值,定义为糖尿病患者(1);
特殊值:概率值输出0.3333,由于大于阈值(调整分类阈值较低),需要经过再次确认,避免误诊;

回归模型的评估标准
模型预测的值是在0到1之间,阈值的选择决定预测值;


精确率、准确率:Accuracy = (TP + TN)/(TP + TN +FN + FP)
注意:值占百分比越大,越好;
精确率、查准率:Precision = TP/(TP+FP)
注意:预测的概率值大于0.3(确诊和误诊的情况),确诊为糖尿病患者的占比;
召回率、查全率:Recall = TP/(TP + FN)
注意:预测的概率值小于0.3被误诊和大于0.3被确诊的患者,确诊为糖尿病患者的占比;
期望查询率:1即100%,所有糖尿病患者都被确诊;
真正类率:(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率),TPR = TP/(TP+FN);
负正类率:(false postive rate TPR))特异度,花粉实例中所有负例占所有负例的比例,FPR=FP/(FP+TN);
纵轴TPR:Sensitivity(正例覆盖率),TPR越大,预测正类中实际正类越多;
横轴FPR:FPR越大,预测正例中实际负例越多;
ROC曲线:接受者操作特征(receiver operating characteristic),ROC曲线上每个店反应着对同一信号刺激的感受性;


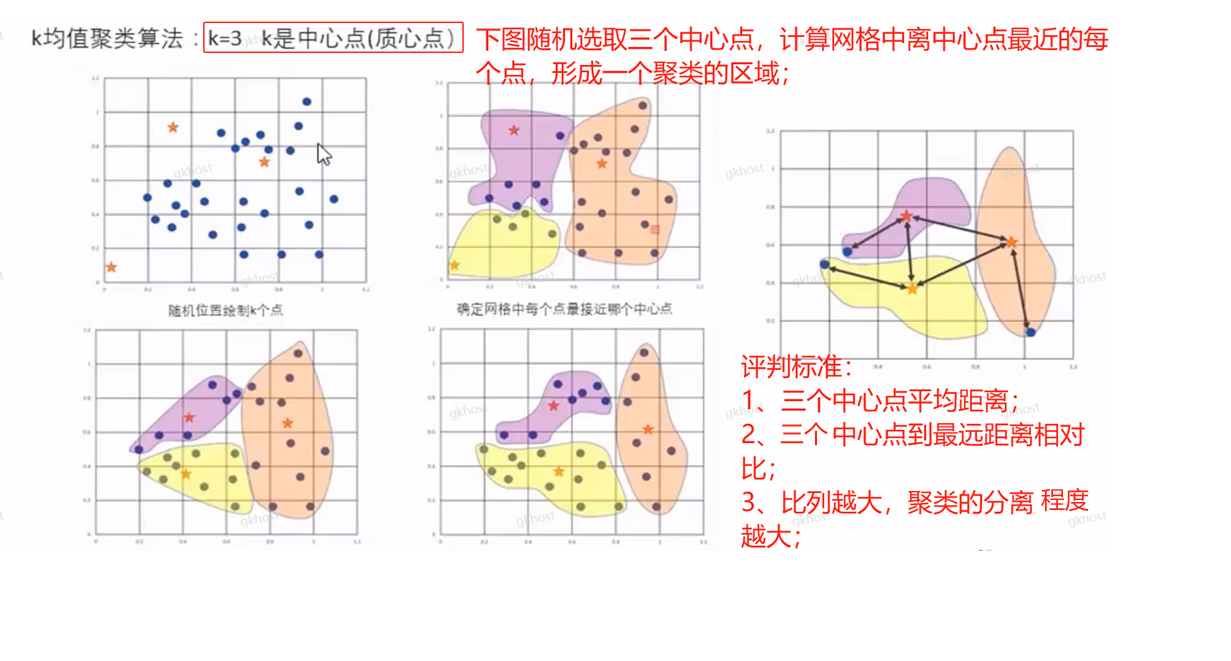
5、非监督学习(重点)
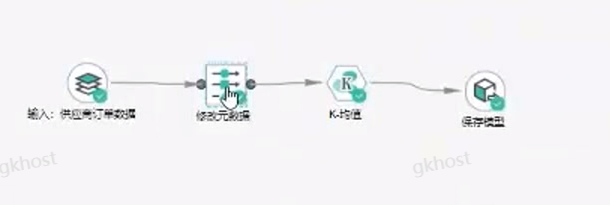
聚类:
聚类建模案例一:现有批发商品交易活动数据,依据每个客户的年进货量大小,找出潜在的大客户,然后定制化销售策略;
无目标值,无法做线性回归;
无客户类别,无法做分类;

输入:供应商订单数据
修改元数据:定义参数id的角色为None;
算法:K均值算法,通过输入的数据集,找出聚类类别;

保存模型:PMML模型模式
6、科研工作者
Geoffrey Hinton是多伦多大学教授,谷歌大脑多伦多升级网络负责人;
Yann LeCun是纽约大学教授,Facebook研究室负责人,他改进了卷积神经网络CNN算法;
Yoshua Bengio是蒙特利尔大学教授,微软公司战略顾问,他推动了循环神经网络RNN算法的发展;
7、什么是机器学习?
概述
机器学习是一种统计学方法,计算利用已有数据,得出某种模型,再利用此模型预测结果。
随经验增加,结果更好;
模型涉及要素——新数据、模型、历史数据、结果;
案例:孩子认识世界的过程,来理解机器学习;
见到猫,告诉他这种动物叫猫,下次孩子见到猫时,从大脑中输出猫的符号;
总结:机器学习流程
核心流程:
数据收集:理解数据的含义,数据质量(例如:健身数据年龄平均)评估;
数据处理:数据清洗(去噪、去重)、数据格式转换、特性提取;
模型训练:了解常用的机器学习算法(理解为函数),选择合适的算法去训练,如何选择算法(监督学习:回归、分类;非监督学习:聚类);
评估模型:通过预测数据集去预测目标,分析评估模型指标数据,评估结果可视化;
回归模型:预测值通过均方根误差比较小;
分类模型:由于查准度AUC区域大,准确率高;
聚类模型:计算中心点之间的平均距离值与计算中心点到区域范围最远点距离的比;
应用模型:导出或发布模型进行应用,最后对模型的效果进程反馈跟踪;
30%数据集集对比分析,判断模型是否满足要求,70%数据集与30%数据集对比,如果精确率和精准率比较高,可用于实际生产环境中;
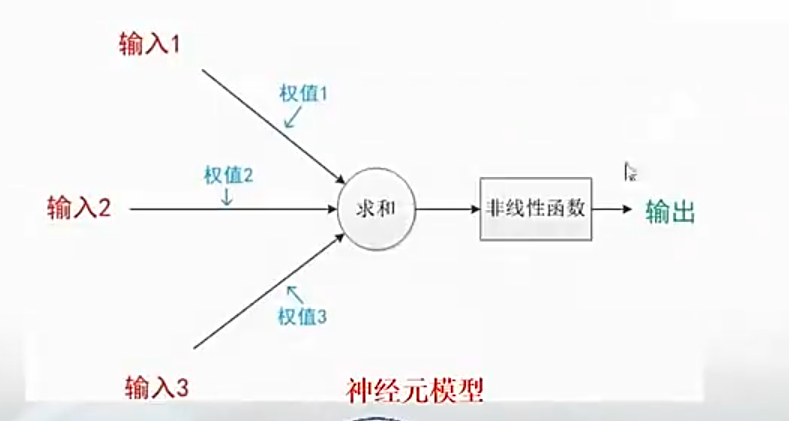
8、神经元模型
1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构,发表了抽象的神经元模型MP。
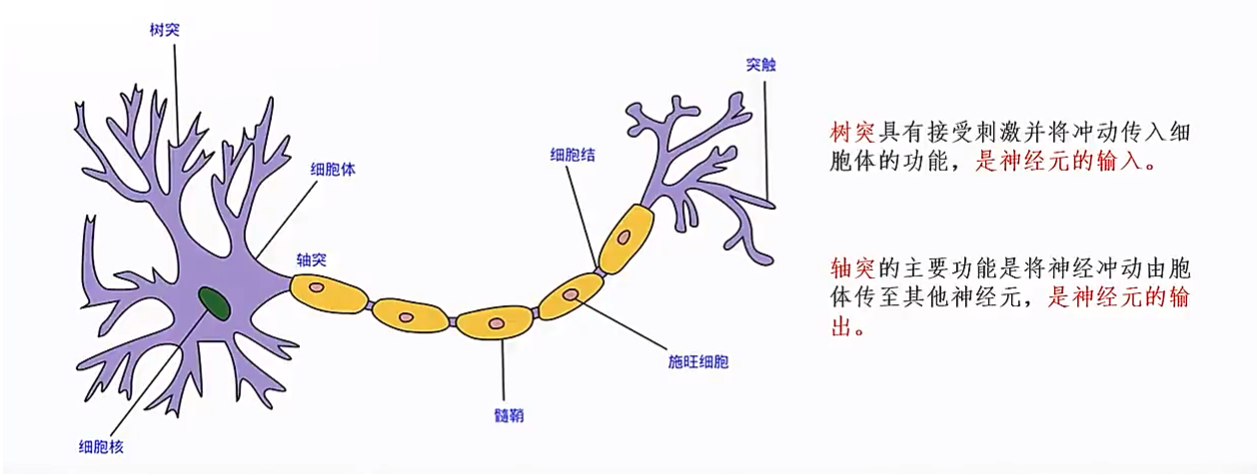
数据输入:模拟神经元的树突;
数据输出:模拟神经元的轴突;
乘加运算:模拟细胞核;
注意:这类运算模拟神经元的基础;
9、神经网络的发展
感知机:1958年两层神经网络首尾相接,组成单层神经网络,称作感知机;成为首个可以学习的神经网络;缺陷,无法对异或进行计算;
10、主流应用
AI辅助软件:辅助办公、辅助教育;
AI消费:AI PC、AI手机、XR设备和脑机接口技术等;
AI医疗:影像分析、药物研究等;
AI生活:智能家居、语音助手、自动驾驶等场景;
AI科研:药物研发、材料科学等领域;
AI制造:通过机器学习和自动化技术,优化生产过程、质量控制和物流管理,提升制造效率;
AI金融:利用智能算法进行风险评估和投资组合优化,实时监测金融交易,识别潜在欺诈行为,提供24小时在线客服;
AI教育:提供个性化教学方案,辅助教师进行课堂教学,提供在线教育平台,打破地域限制;
AI交通:实现自动驾驶汽车的自主导航和避障,优化交通信号控制和路线规划,减少拥堵和事故;
AI智慧安防:利用身份认证系统和智能摄像监控,提高安全性和监控效率;
AI能源与环保:通过AI优化能源生产和分配,提高能源利用效率,进行环境监测和保护;
AI游戏与娱乐:在电子游戏中实现智能对战,提升游戏体验;
11、数字孪生技术就在我们身边
i.数字孪生脑:
人脑的突触参数高达 100 万亿,数字孪生脑是通过计算机或芯片来实现的虚拟大脑,它能够帮助研究人员理解信息如何在大脑中传播和处理的过程。
2015 年起,冯建峰担任复旦大学类脑智能科学与技术研究院院长,目前,他还担任上海数学中心首席教授兼任复旦大学大数据学院院长。复旦大学冯建峰教授团队构建了一个全人脑尺度大脑模拟平台数字孪生脑(DTB,Digital Twin Brain),首次在世界上实现了对 860 亿神经元和百万亿突触的具有生物已知结构的模拟。
ARM 处理器硬件微型体系架构原创者、英国曼彻斯特大学斯蒂芬·B·弗伯(Stephen B. Furber)教授对该研究评价称:“我已经深入了解了 DTB 团队的工作,他们有着很大的目标,通过基于生物数据的全脑计算模型的模拟和整合来探索类脑智能。”
在英国伦敦大学学院卡尔·J·弗里斯顿(Karl J. Friston)教授看来,DTB 是“全球计算神经科学和生物信息学领域最全面、技术原则最严谨和最重要的工作之一”。
二、如何掌握AI的应用能力及角色定位
1、如何掌握AI的应用能力
先上车ABC,AI、Bigdata、Cloud;
掌握一门编程语言;
理解机器学习的原理;
熟悉一款云平台和AI应用的集成方式(接口API或SDK,通过接口进程机器到硬件或者软件中);
至少会一种接口调试工具(Postman),调试接口的连通性和可行性;
2、角色定位
AI应用工程师:主要将AI与行业应用结合,开发各种应用或者中间件;
AI售前工程师:主要是结合各行业,提出各种AI应用的场景,向客户提供解决方案;
AI集成工程师(项目经理):主要是与AI产品供应商合作(整合),提供整体集成解决方案,包括实施和运维;
AI产品经理:主要是将AI功能落地到产品上,提升产品的交互体验,增强产品的竞争力;
AI研发工程师(技能要求高):主要负责核心AI技术的研发工作(算法、模型),涉及源代码、调参、调优;
参考:
https://connect.huaweicloud.com/courses/learn/Learning/sp:cloudEdu_?courseNo=course-v1:HuaweiX+CBUCNXE036+Self-paced&courseType=1&ticket=ST-82074695-DACvSpinVZ0CVdvobM0kGBgr-sso

 浙公网安备 33010602011771号
浙公网安备 33010602011771号