

Linux常用文本命令:grep、sed、awk 、cut、tr、wc、uniq、sort
grep
grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。
grep常用参数:

-B num : 除了显示符合样式的那一行之外,并显示该行之前的num行内容。before -A num :除了显示符合样式的那一行之外,并显示该行之前的num行内容。after -C num:除了显示符合样式的那一行之外,并显示该行之前后num行内容。 -c :计算符合样式的列数 -d 动作: 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。 -e :实现多个选项间的逻辑or关系. -n :在显示符合样式的那一行之前,标出该行的列数编号,即显示行号; -E :使用扩展的正则表达式 \egrep。 -i :忽略字符大小写的差别。 -o :只显示匹配的字符串部分。 -v :显示不包含匹配文本的所有行。 -V :显示版本信息 -s :不显示错误信息。
练习:
1.选取出"ip a"命令的ipv4地址 # ip a|grep "\<inet\>"|grep -E -o "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}"
sed
前言:
1.sed是非交互式的编辑器。它不会修改文件,除非使用shell重定向来保存结果。默认情况下,所有的输出行都被打印到屏幕上。
首先sed把当前正在处理的行保存在一个临时缓存区中(也称为模式空间),然后处理临时缓冲区中的行,完成后把该行发送到屏幕上。
sed每处理完一行就将其从临时缓冲区删除,然后将下一行读入,进行处理和显示。处理完输入文件的最后一行后,sed便结束运行。
sed把每一行都存在临时缓冲区中,在缓冲区中对这个副本进行编辑,将处理后的行输出到屏幕上,但不会修改原文件,除非使用-i参数。
3.sed可以对文件进行过滤,也可以进行修改。
[option]常用选项: -n:不输出模式空间内容到屏幕,即不自动打印。 -e:多点编辑。 -f /path/script_file:从指定的文件中读取编辑脚本。 -r:支持使用扩展正则表达式。 -i.bak:备份原文件,备份后在原文件处进行内容修改。(-i.bak是因为sed命令使用-i参数时不会询问,怕改错,有一定的危险性,因此-i.bak是在修改前先备份原文件,然后再修改该文件,一定程度上减少了出错风险。) 'script'即'地址命令':sed自身的语言脚本。 'script'='地址定界 + 编辑命令',若不加地址定界,则默认处理文本中的所有行。 '地址定界: ①不给地址,则对全文进行处理。 ②单地址: # :指定的行; $ :最后一行。 /pattern/ :搜索文本中包含"pattern"的所有行。 ③地址范围(哪行到哪行)[#代表行号,/pat/代表比包含有pat的首行]: #,# #,+# /pat1/,/pat2/ #,/pat1/ ③~:步进 1~2:奇数行 2~2:偶数行 编辑命令': d:删除模式空间匹配的行,并立即进行下一轮循环。 p:打印当前模式空间内容,追加到默认输出之后。 a[\]text:在指定文本/行的后面追加text内容。(在该行的下一行追加文本),支持使用"\n"实现多行追加。[\]只是方便辨别,实际命令中并不使用它,只需"a内容"或a\内容。 i[\]text:在指定文本/行前插入text内容。(在该行的上一行插入文本)。[]只是方便辨别,实际命令中并不使用它,只需"i内容"即可,或便于区分可i\text。 c[\]text:替换单行或多行为text内容,c内容,或c\内容。 w /path/somefile:保存模式匹配的行到指定文件中。 r /path/somefile:读取指定文件的内容,至模式空间中匹配到的行的后面。 =:为模式空间中的行打印行号。 !:为模式空间中匹配行取反处理。
'sed工具'
's///':查找替换,支持使用其他分隔符,s@@@,s%%%
替换标记:
g:行内全部替换
p:显示替换成功的行
w /path/to/somefile:将替换成功的行保存至文件中。
练习:原文本内容:
[root@localhost gaokai]# cat test.sh function look() { echo "this is a test4335" awdadAWDAaaw97979879722aaa awdadAWDAaaw97979879722aaa -------------------------------------------- 1.打印1,2行模式空间的内容,并追加到默认输出后。 # sed '1,2p' test.sh function look() { function look() { echo "this is a test4335" echo "this is a test4335" awdadAWDAaaw97979879722aaa awdadAWDAaaw97979879722aaa -------------------------------------------- 2.打印1,2行模式空间处理后的内容,不打印原模式空间内容,并输出 # sed -n '1,2p' test.sh function look() { echo "this is a test4335" --------------------------------------------- 3.不打印模式空间内容,然后将匹配到的行输出到屏幕上。 # sed -n '/func/,/awd/p' test.sh function look() { echo "this is a test4335" } awdadAWDAaaw97979879722aaa ---------------------------------------------- 4.在第3行行尾添加文本"()_______m",并显示 # sed '3a()_______m' test.sh function look() { echo "this is a test4335" ()_______m } awdadAWDAaaw97979879722aaa awdadAWDAaaw97979879722aaa
----------------------------------------------
5.在第1行前追加文本"_______m",并保存后在原处进行编辑。
# sed -i.bak '1i_______m' test.sh
# cat test.sh
_______m
function look() {
echo "this is a test4335"
awdadAWDAaaw97979879722aaa
awdadAWDAaaw97979879722aaa
-----------------------------------------------
6.删除第2行
# sed '2d' test.sh
echo "this is a test4335"
awdadAWDAaaw97979879722aaa
awdadAWDAaaw97979879722aaa
7.更换第1,3行内容为"this is tihuan",并输出
# sed '1,3cthis is tihuan' test.sh
this is tihuan
awdadAWDAaaw97979879722aaa
------------------------------------------------
8.在第1至3行后追加"zhui.txt"文本内容,并显示
#cat zhui.txt
----------
----------
#sed '1,3r zhui.txt' test.sh
function look() {
----------
----------
echo "this is a test4335"
----------
----------
awdadAWDAaaw97979879722aaa
----------
----------
awdadAWDAaaw97979879722aaa
-----------------------------------------------
9.替换行内内容,将单词"is"替换为大写"IS"
#sed 's/\<is\>/IS/' test.sh
function look() {
echo "this IS a test4335"
awdadAWDAaaw97979879722aaa
awdadAWDAaaw97979879722aaa
-----------------------------------------------
10.将/etc/default/grub文件中以"号结尾的行的冒号,替换为xyz"。
# sed -r 's/("$)/xyz\1/' /etc/default/grub
awk
文本报告生成器,逐行处理。
工作流程
#awk 'BEGIN{action} /pattern/{action} END{action}' filename
- 读输入文件之前执行的代码段(由BEGIN关键字标识)。
- 主循环执行输入文件的代码段。(执行完BEGIN后,开始读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。)
- 读输入文件之后的代码段(由END关键字标识)。
如图
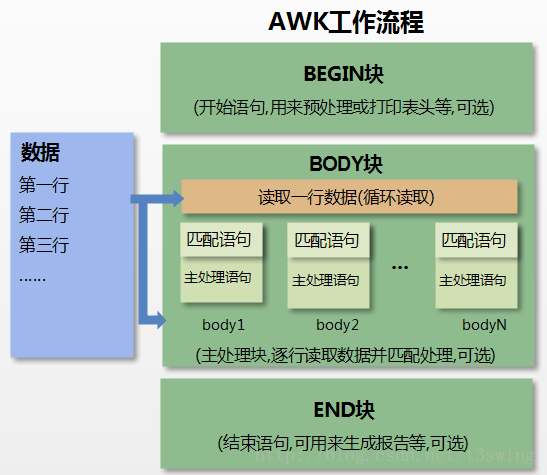
awk常见使用方式:
#awk -F"分隔符" '/pattern/{action}' filename
练习
1.以":"Wie分隔符,提取/etc/passwd文件的第一列 #awk -F":" '{print $1}' /etc/passwd 2.只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割。 #awk -F":" '{print $1"\t"$7}' /etc/passwd |sed -n '1,2p' 3.显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以"+"分割。 #awk -F":" '{print $1"+"$7}' /etc/passwd|sed -n '1,2p' 4.显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行之前添加行其中列名为name,shell,在最后一行添加"blue,/bin/nosh"。 #cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}' 5.搜索/etc/passwd以root单词开头的行,并显示该行的用户名和bash(以空格为分隔符)。 # awk -F":" '/^root\>/{print $1" "$7}' /etc/passwd
wc命令
[option] -c或--bytes或--chars 只显示Bytes数,字节数。 -l或--lines 只显示行数。 -w或--words 只显示单词数。 --help 在线帮助。 --version 显示版本信息。
sort命令
[option]: -n: 将数值按照从小到大顺序排序。。 -r :以相反的顺序来排序。
-t :指定分隔符,分割列;如-t " ",指定空格为分隔符。配合-k参数
-k : 指定列
-o <输出文件>:将排序后的结果存入指定的文件。
uniq
用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用,即去重,如...sort|uniq
[opion] -c或--count :在每列旁边显示该行重复出现的次数。 -d或--repeated: 仅显示重复出现的行。 -u或--unique 仅显示不重复出现行列。 [输入文件] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据; [输出文件] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
cut
第一,字节(bytes),用选项-b 第二,字符(characters),用选项-c 第三,域(fields),用选项-f 注意:英文和阿拉伯数字是单字节字符,中文是双字节字符,甚至是3字节字符(根据编码而定)。 注意:按字节或字符分割时将不能指定-d,因为-d是划分字段的。
[option] -b:按字节筛选; -n:与"-b"选项连用,表示禁止将字节分割开来操作(一般情况下不用,防止-b将多字节的字符强行分割导致乱码); -c:按字符筛选; -d:指定字段分隔符,不写-d时的默认字段分隔符为"TAB";因此只能和"-f"选项一起使用。 -f:与-d一起使用,以指定的分隔符为单位,选择显示的列号。 --complement:显示出去-f指定的列的其他列(即显示-f的补集)。 --output-delimiter:指定输出分割符;默认为输入分隔符。 注意:cut分隔符必须是单个字符。
tr
[option] -c: 反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换。要求字符集为ASCII。 -s :删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。 -d :删除字符串1中所有输入字符。
SET字符集
指定字符串1或字符串2的内容时,只能使用单字符或字符串范围或列表。 CHAR1-CHAR2 :字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。 [a-z] a-z内的字符组成的字符串。 [A-Z] A-Z内的字符组成的字符串。 [0-9] 数字串。 [:alnum:] :所有字母字符与数字 [:alpha:] :所有字母字符 [:lower:] :所有小写字母 [:upper:] :所有大写字母 [:digit:] :所有数字 [:xdigit:] :所有 16 进位制的数字 [:blank:] :所有水平空格 [:cntrl:] :所有控制字符 [:graph:] :所有可打印的字符(不包含空格符) [:print:] :所有可打印的字符(包含空格符) [:punct:] :所有标点字符 [:space:] :所有水平与垂直空格符
练习
1.将test.sh中的is替换为IS,并追加到a.txt文件中。 # cat test.sh|tr "is" "IS" >a.txt 2.将test中的小写字母转换为大写字母,并追加到a.txt文件中。 # cat test.sh|tr [a-z] [A-Z] >a.txt 注意:不能追加到原文件中,否则原文件会被清空。
1.查看access.log文件有多少个IP访问: ①#awk '{print $1}' access.log|sort|uniq|wc -l 2.查看某一个页面被访问的次数 ①#grep "index.php" access.log|wc -l 3.查看每一个IP访问了多少个页面,并按访问次数从小到大排序 ①#awk '{++S[$1]} END {for (a in S) print a,S[a]}' accsess.log |sort -n -t " " -k 2 ②#awk '{print $1}' access.log|sort|uniq -c|sort -n 4.查看某个IP访问了哪些页面,并进行统计,页面访问次数从小到大排序。
①#awk '{print $1,$7}' access.log|grep 192.168.24.1|sort|uniq -c |sort -n
5.去掉搜索引擎统计的页面,并统计去掉后的访问次数
①#awk '{print $12,$1}' access.log|grep ^\"Mozilla|awk '{print $2}'|sort |uniq|wc -l
6.查看2021年10月27日时这一个小时有多少IP访问。
①#awk '{print $4,$1}' access.log|grep '27/Oct/2021:05'|wc -l
②#awk '{print $4,$1}' access.log|grep '27/Oct/2021:05'|awk '{print $2}'|sort |uniq |wc -l
7.查看访问次数前十的IP地址
①#awk '{print $1}'|sort |uniq -c|sort -nr|head -n10


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统