
进化多目标特征选择

基本知识
特征选择是一个多目标任务,分类精度最大化和特征选择数量最小化是特征选择的两个主要目标。
特征选择原因:当今世界大数据的激增,高维数据在许多实际应用中经常遇到。例如,在癌症分类中,癌症数据通常是高维的,并且包含大量不相关的、有噪声的或冗余的特征。
Feature selection (FS)通过选择一小部分相关特征来解决上述问题,可以提高分类性能,降低数据维数,减少空间存储,提高计算效率,便于数据可视化和理解。FS在数据挖掘、模式识别和机器学习中起着至关重要的作用。与特征构建和特征提取等其他降维技术相比,FS可以保留数据的原始语义,是一种具有可解释性的有效方法,便于人类对结果的理解。
选用进化算法的原因:进化计算(evolutionary computation, EC)具有全局搜索能力,不需要先验知识,基于种群的搜索可以获得一组解决方案来权衡多个相互冲突的目标,其衍生算法被称为进化多目标优化算法。
多目标优化
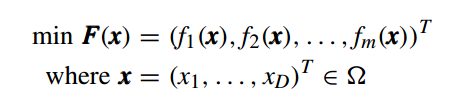
m为目标数,D为候选解x的维数。
在多目标优化中,多个目标通常是相互冲突的,在不同的目标之间总是存在权衡,因此不存在单一的最佳解决方案。
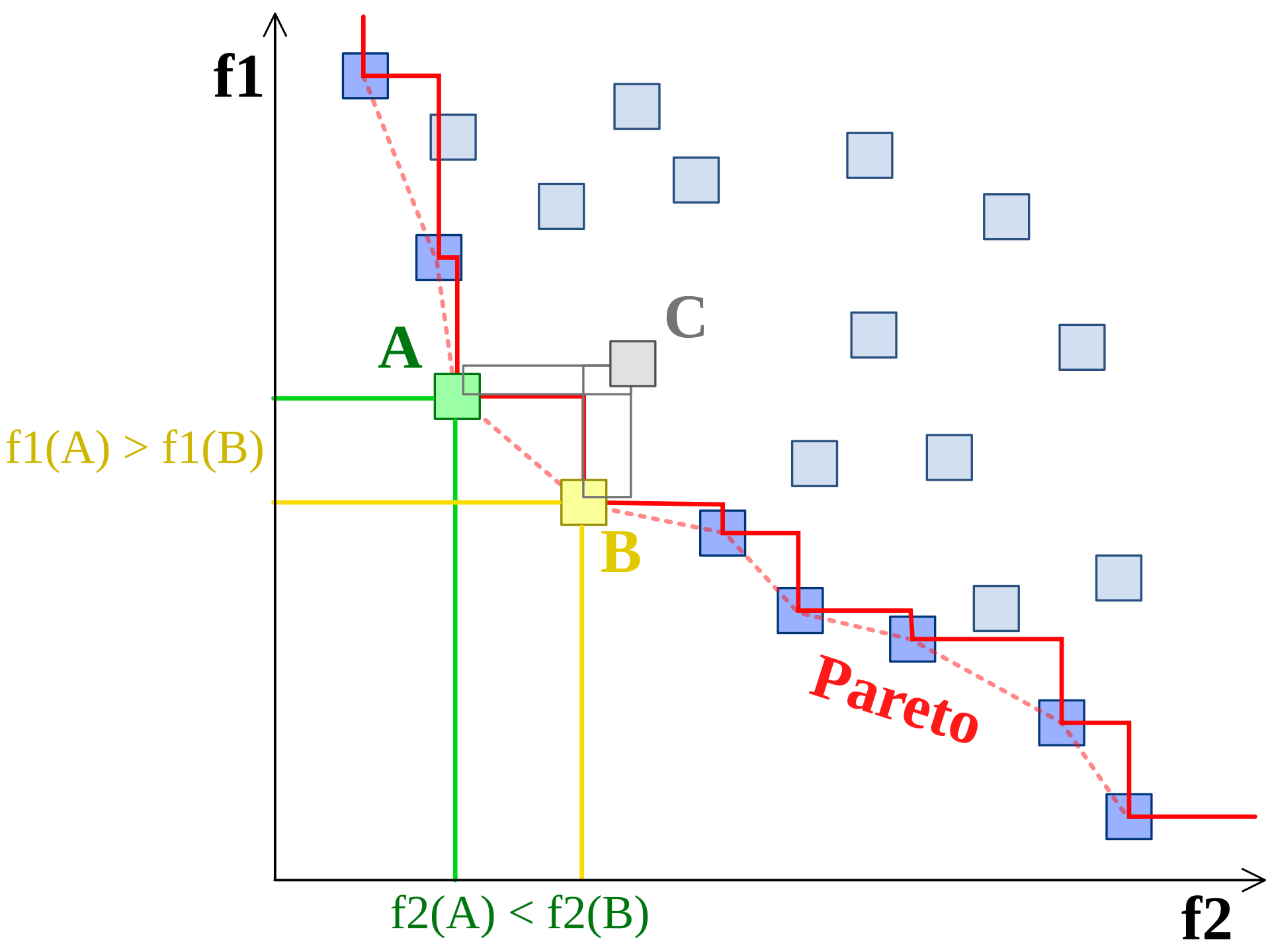
常用的目标包括最大化分类精度(可以用分类精度、分类误差、F1测度或互信息来表示)和最小化特征子集的大小(可以用所选特征的数量或冗余来表示),以及其他一些目标,如计算成本、模型大小等。
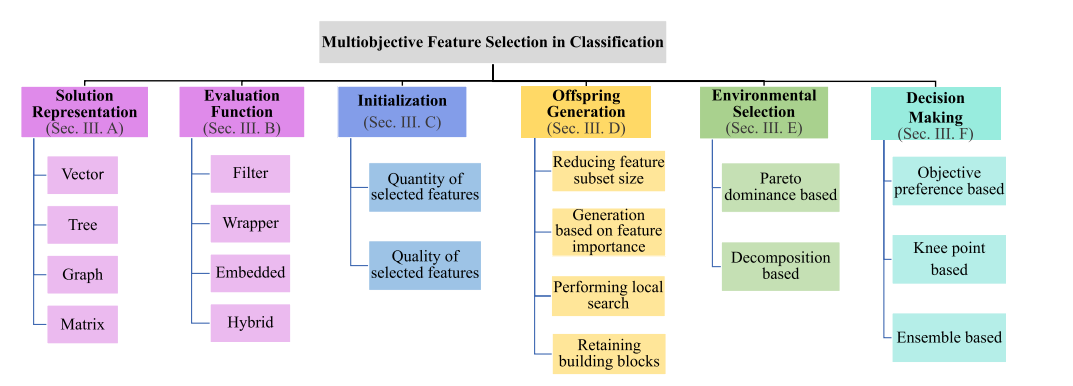
Solution Representation
矢量
基于矢量的表示在进化FS社区中最常用,可进一步分为两类:1)二进制编码和 2)连续编码

在二进制编码中,比特1和0分别表示选择或丢弃的特征。在连续编码中,阈值θ将连续表示值舍入到1和0,以确定是否选择相应的特征。
这种编码通常用于基于向量表示的EC(进化计算)方法,例如遗传算法(GAs)、粒子群优化(PSO)、差分进化(DE)等。
由于特征子集有很多0位(即特征没有被选择),对于经典的基于向量的表示来说是一种浪费。为此,提出了一种新的基于向量的表示方法,该方法只存储所选特征的索引,为特征子集表示节省内存,加快评估速度。(A new multi-objective wrapper method for feature selection–accuracy and stability analysis for BCI)
为了解决高维MOFS问题,借鉴了进化大规模优化中的协作协同进化思想,通过聚类算子将原来的大规模解表示分解为一组更小的解表示,以分而治之的方式解决高维MOFS问题。(MLFS-CCDE: Multi-objective large-scale feature selection by cooperative coevolutionary differential evolution)
树
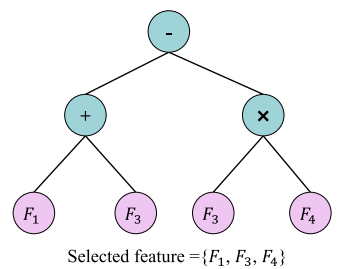
基于树的遗传规划(GP)是使用树表示的代表性方法。GP通过探索特征空间来检测重要特征和隐式自动挖掘复杂特征交互的能力使其成为一种有价值的FS方法。
图
在蚁群优化(ant colony optimization, ACO)的表示通常采用图的形式。
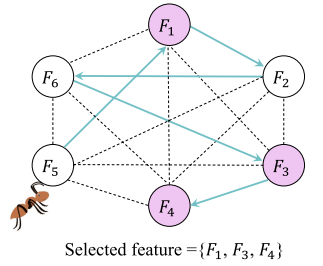
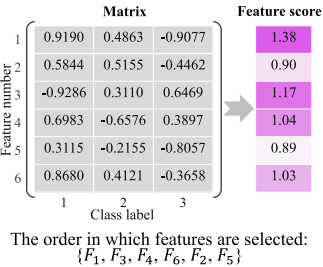
矩阵
在基于稀疏学习的FS方法中,使用变换矩阵来拟合稀疏学习模型,该模型可以表示为一个解。
Evaluation Functions
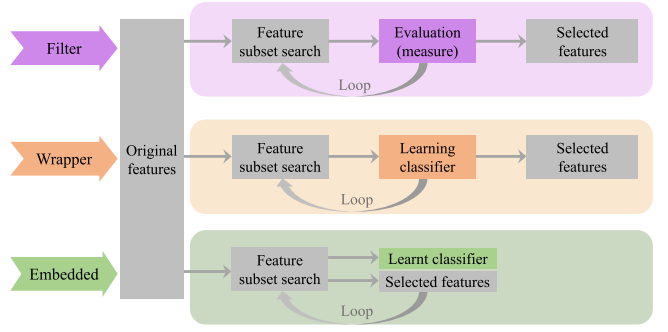
过滤方法Filter
根据数据的内在特征来评价特征子集的优劣,如信息论度量、相关性度量、相似性度量、一致性度量、统计度量、模糊集理论度量等。
包装方法Wrapper
它们通常以较高的计算时间和较弱的对其他分类算法的泛化为代价,为特定的分类算法提供较高的分类精度。最大化分类性能和最小化所选特征的数量是FS的两个主要目标。
嵌入方法Embedded
它们将FS和模型训练合并到一个过程中,通常比过滤器方法提供更好的分类性能,比包装器方法更有效。但是,嵌入式方法的泛化能力一般不如过滤方法,分类性能一般不如包装方法。
混合方法Hybrid
不同类型的MOFS方法(filter, wrapper, embedded)有不同的优缺点。为了充分发挥各种MOFS方法的优点,人们开发了一些混合MOFS方法。混合方法虽然依赖于不同MOFS方法的组合,但通常比较复杂,但分类性能优于单一方法。
典型的例子是高效的过滤方法与分类精度高的包装方法相结合。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人