
Python学习4
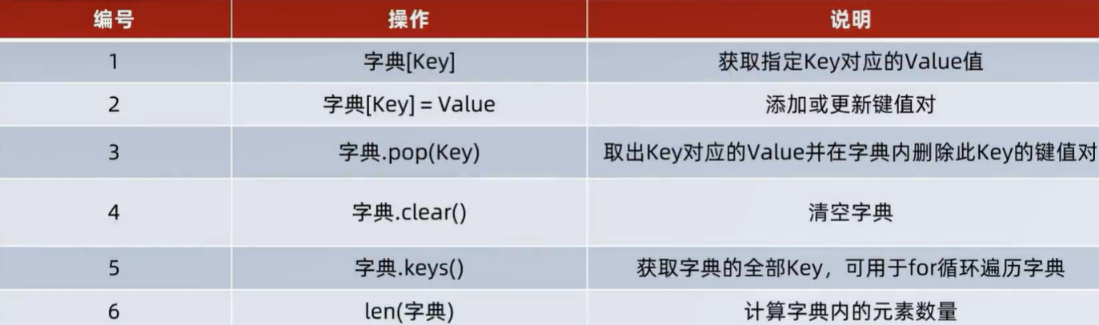
集合:
集合的特点: 不支持重复元素(自带去重功能)、内容无序
基本语法:
定义集合字面量: {元素,元素,······,元素}
定义集合变量 : 变量名称 = {元素,元素,······,元素}
定义空集合: 变量名称 = set( )
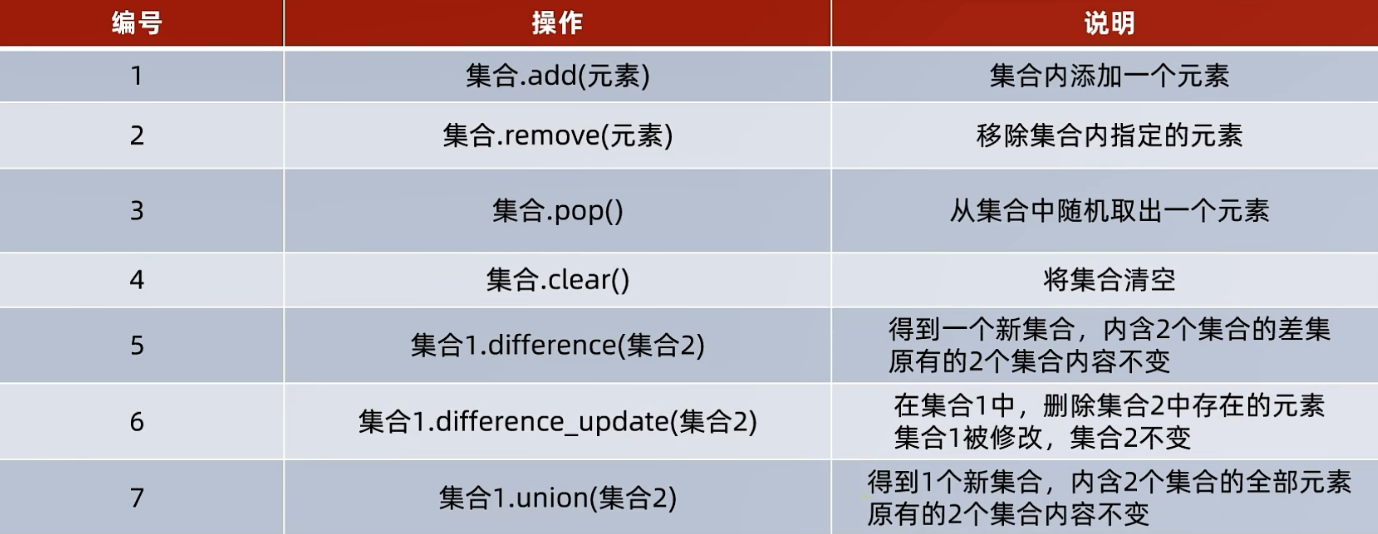
添加新元素
语法:集合.add(元素) 将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
my_set = {"你好!","hello!","再见!","886~"}
# 添加新元素
my_set.add("bye!")
print(f"my_set添加新元素后结果是:{my_set}")
移除元素
语法:集合.remove(元素) 将指定元素从集合内移除
结果:集合本身被修改,移除了元素
my_set = {"你好!","hello!","再见!","886~"}
# 移除元素
my_set.remove("你好!")
print(f"my_set移除你好!后,结果是:{my_set}")
取出元素
语法:集合.pop( ) 从集合中随机取出一个元素
结果: 会得到一个元素的结果,同时集合本身被修改,元素被移除
my_set = {"你好!","hello!","再见!","886~"}
# 取出元素
element = my_set.pop()
print(f"集合被取出的元素是{element},取出元素后集合为:{my_set}")
清空集合
语法: 集合.clear() 清空集合
结果:集合本身被清空
my_set = {"你好!","hello!","再见!","886~"}
# 清空
my_set.clear()
print(f"集合被清空为:{my_set}")
取出两个集合的差集
语法: 集合1.difference(集合2) 取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
set1 = {"你好!","hello!","再见!","886~"}
set2 = {"你好!","再见!","bye!"}
set3 = set1.difference(set2)
print(set3) # 结果是:{'886~', 'hello!'}
消除两个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内删除和集合2相同的元素。
结果:集合1被修改,集合2不变
set1 = {"你好!","hello!","再见!","886~"}
set2 = {"你好!","再见!","bye!"}
set1.difference_update(set2)
print(set1) # 结果是:{'hello!', '886~'}
集合合并
语法: 集合1.union(集合2)
功能: 将集合1和集合2组合成新集合
结果: 得到新集合,集合1和集合2不变
set1 = {"你好!","hello!","再见!","886~"}
set2 = {"你好!","再见!","bye!"}
set3 = set1.union(set2)
print(set3) # 结果是:{'你好!', 'hello!', '886~', '再见!', 'bye!'}
统计集合元素数量 len ( )
set1 = {"你好!","hello!","再见!","886~","再见!"}
num = len(set1)
print(f"集合内的元素数量有:{num}") # 不算入重复元素 结果是:集合内的元素数量有:4
集合的遍历
集合不支持下标索引,不能用while循环 ,可以用for循环
set1 = {"你好!","hello!","再见!","886~","再见!"}
for element in set1:
print(f"集合的元素有:{element} ",end="")
字典:
字典的定义,同样使用{ },不过存储的元素是一个个的 :键值对
语法:
定义字典字面量: {key:value , key:value , ...... , key:value}
定义字典变量: my_dict = {key:value , key:value , ...... , key:value}
定义空字典: my_dict = { } my_dict = dict ( )
字典同集合一样,不可以使用下标索引,但是字典可以通过key值来取得对应的Value
# 语法,字典[key]可以取到对应的value stu_score = {"小明": 99, "小红": 88, "小李": 77} print(stu_score["小明"]) # 结果:99 print(stu_score["小红"]) # 结果:88 print(stu_score["小李"]) # 结果:77
字典的key和value可以是任意数据类型(key不可为字典)
那么就说明,字典是可以嵌套的,需求如下,记录学生各科的考试信息:
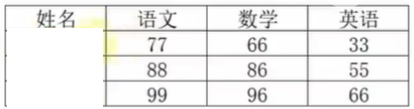

# 定义嵌套字典: stu_score = { "小明":{ "语文": 77, "数学": 66, "英语": 33 }, "小红":{ "语文": 88, "数学": 86, "英语": 55 }, "小李":{ "语文": 99, "数学": 96, "英语": 66 } } # 从嵌套字典中查看小明的语文成绩: score = stu_score["小明"]["语文"] print(f"小明的语文分数是:{score}")
新增元素
语法:字典 [key] = value,结果:字典被修改,新增了元素
# 定义字典: stu_score = { "小明": 33, "小红": 55, "小李": 66 } # 新增:小王的考试成绩 stu_score['小王'] = 99 print(stu_score) # 结果:{'小明': 33, '小红': 55, '小李': 66, '小王': 99}
更新元素
语法:字典 [key] = value, 结果:字典被修改,元素被更新
注意: 字典的key不可以重复,所以对已存在的key执行上述操作,就是更新value值
stu_score = { "小明": 33, "小红": 55, "小李": 66 } # 更新:小明王的考试成绩 stu_score['小明'] = 99 print(stu_score) # 结果:{'小明': 33, '小红': 55, '小李': 66}
删除元素
语法:字典. pop(key) ,结果:获得指定key的value, 同时字典被修改,指定key的数据被删除
stu_score = { "小明": 33, "小红": 55, "小李": 66 } value = stu_score.pop("小红") print(value) # 结果:55 print(stu_score) # 结果:{'小明': 33, '小李': 66}
清空字典
语法: 字典.clear ( ), 结果:字典被修改,元素被清空
stu_score = { "小明": 33, "小红": 55, "小李": 66 } stu_score.clear() print(f"字典内容被清空了,内容是:{stu_score}")
获取全部的key
语法:字典.keys( ), 结果:得到字典中的全部key
stu_score = { "小明": 33, "小红": 55, "小李": 66 } keys = stu_score.keys() print(f"字典的全部keys是:{keys}")
遍历字典
语法:方式一: 字典. keys(), 结果:得到字典中的全部key
方式二:直接对字典进行for循环,每一次循环都是直接得到key
stu_score = { "小明": 33, "小红": 55, "小李": 66 } # 方式一: keys = stu_score.keys() for key in keys: print(f"字典的key是:{key}") print(f"字典的value是:{stu_score[key]}") # 方式二: for key in stu_score: print(f"字典的key是:{key}") print(f"字典的value是:{stu_score[key]}")
字典zip用法
将两个对应的列表使用zip函数变为一个字典
keys = ['name', 'age', 'food'] values = ['Monty', 42, 'spam'] my_dict = dict(zip(keys, values)) print(my_dict) # 结果:{'name': 'Monty', 'age': 42, 'food': 'spam'}
字典的排序
- 按照key排序
sys = {"<":"less than", "==":"equal"}
# 单独打印出排序后的key值
new_sys = sorted(sys)
print(new_sys) # 结果:['<', '==']
new_sys = sorted(sys.keys())
print(new_sys) # 结果:['<', '==']
# 根据key的升序排序,把key, value都打印出来
new_sys1 = sorted(sys.items(), key=lambda d: d[0],reverse=False)
print(new_sys1) # 结果:[('<', 'less than'), ('==', 'equal')]
new_sys1 = sorted(sys.items(), reverse=False)
print(new_sys1) # 结果:[('<', 'less than'), ('==', 'equal')]
- 按照value排序
sys = {"<":"less than", "==":"equal"}
# 单独打印出排序后的key值
new_sys = sorted(sys.values())
print(new_sys) # 结果:['equal', 'less than']
# 根据key的升序排序,把key, value都打印出来
new_sys1 = sorted(sys.items(), key=lambda d: d[1],reverse=False)
print(new_sys1) # 结果:[('==', 'equal'), ('<', 'less than')]
统计字典内的元素数量,len( )
stu_score = { "小明": 33, "小红": 55, "小李": 66 } num = len(stu_score) print(f"字典中的元素数量有:{num}个")
字典的特点:
可以容纳多个数据; 可以容纳不同类型的数据; 每一份数据是key value键值对 ; 可以通过key获取到value, key不可重复(重复会覆盖原来的那个)
不支持下标索引(所以支持for循环遍历,不支持while循环遍历); 可以修改(增加、删除或更新元素等)
数据容器
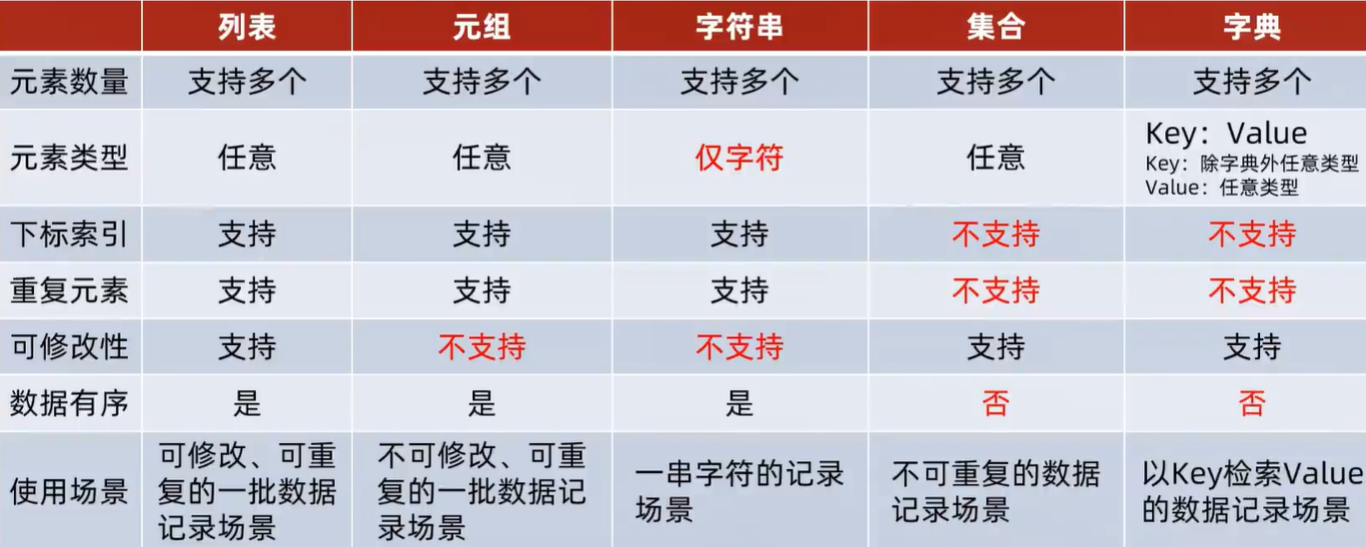
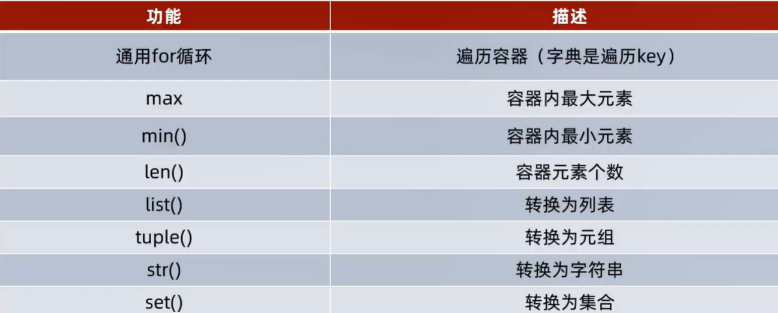
数据容器的通用操作——遍历
数据容器尽管有各自的特点,但是他们也有通用的一些操作。
首先,在遍历上: 5类数据容器否支持for循环遍历;列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
除了下标索引这个共性外,还可以通用类型转换
list (容器) 将给定容器转换为列表
str(容器) 将给定容器转换为字符串
tuple(容器) 将给定容器转换为元组
set(容器) 将给定容器转换为集合
排序
sorted(序列,[reverse=True]) 排序,reverse=True 表示降序,得到一个排好序的列表

函数进阶
多返回值
如果一个函数要有多个返回值,我们可以按照返回值的顺序,写对应顺序的多个变量接收即可
变量之间用逗号隔开,支持不同类型的数据return
def test_return(): return 1,True,"nihao" x,y,z = test_return() print(f"第一个返回值{x}的类型是{type(x)}") print(f"第二个返回值{y}的类型是{type(y)}") print(f"第三个返回值{z}的类型是{type(z)}")
关键字参数
函数调用时通过“ 键=值 ” 形式传递参数 可以让函数更加清晰,容易使用,同时也清除了参数的顺序需求
def user_info(name,age,gender): print(f"您的名字是:{name},年龄是:{age},性别是:{gender}") # 关键字传参 user_info(name="小明", age=20, gender="男") # 可以不按照顺序传参 user_info(age=20, gender="男", name="小明") # 位置参数 —— 默认使用形式 user_info('小明',20,'男') # 可以和位置参数混用,位置参数必须在前面,且匹配参数顺序 user_info("小明", age=20, gender="男")
缺省参数
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用时函数可不传该默认参数的值
注意: 所有位置参数必须出现在默认参数前面,包括函数定义和调用
作用:当调用函数时没有传递参数,就会使用默认是缺省参数对应的值
def user_info(name,age,gender = "男"): print(f"您的名字是:{name},年龄是:{age},性别是:{gender}") # 缺省参数 user_info(name="小明", age=20) # 结果是:您的名字是:小明,年龄是:20,性别是:男
不定长参数
不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景
作用:当调用函数时不确定参数个数时,可以使用不定长参数
不定长参数的类型:①位置传递 ②关键字传递
位置传递:
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型。 形式参数一般命名为args
# 不定长 - 位置不定长,*号 # 不定长定义的形式参数会作为元组存在,接受不定长数量的参数传入 def user_info(*args): print(f"args参数的类型是:{type(args)},内容是:{args}") user_info(1,2,3,'小明','男孩') # 结果是:args参数的类型是:<class 'tuple'>,内容是:(1, 2, 3, '小明', '男孩')
关键字传递
参数是“ 键=值 ” 形式的情况下,所有的“ 键=值 ” 都会被kwards接受,同时会根据“ 键=值 ” 组成字典 形式参数一般命名为kwargs
# 不定长 - 关键字不定长,**号 def user_info(**kwargs): print(f"kwargs参数的类型是:{type(kwargs)},内容是:{kwargs}") user_info(name='小王', age=11, gender='男孩') # 结果是:kwargs参数的类型是:<class 'dict'>,内容是:{'name': '小王', 'age': 11, 'gender': '男孩'}
匿名函数
# 定义一个函数,接收另一个函数作为传入参数 def test_func(compute): result = compute(1,2) # 确定compute是函数 print(f"compute参数的类型是:{type(compute)}") print(f"计算结果:{result}") # 定义一个函数,准备作为参数传入另一个函数 def compute(x,y): return x + y # 调用,并传入函数 test_func(compute)
函数compute,作为参数,传入了test_func函数中使用
- test_func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定
- compute函数接收2个数字对其进行计算,compute函数作为参数,传递给了test_func函数使用
- 最终,在test_func函数内部,由传入的compute函数,完成了对数字的计算
所以,这是一种,计算逻辑的传递,而非数据的传递。不仅仅是相加,相减、相除等任何逻辑都可以自行定义并作为函数传入
lambda匿名函数
函数的定义中:
- def关键字,可以定义带有名称的函数 有名称的函数,可以基于名称重复使用
- lambda关键字,可以定义匿名函数(无名称) 无名称的匿名函数,可以临时使用一次
语法: lambda 传入参数: 函数体(一行代码)
- lambda是关键字, 表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x,y表示接收2个形式参数
- 函数体,就是函数的执行逻辑,注意:只能写一行,无法写多行代码
注意: 匿名函数用于临时构建一个函数,只用一次的场景
匿名函数的定义中,函数体只能写一行代码,如果函数体要写多行代码,不可用lambda匿名函数,应使用def定义带名函数
# # 通过def定义带名函数: def test_func(compute): result = compute(1,2) print(result) def compute(x,y): return x + y test_func(compute) # 结果: 3 # 通过lambda关键字,传入一个一次性使用的lambda匿名函数 def test_func(compute): result = compute(1,2) print(result) test_func(lambda x, y: x + y) # 结果: 3
使用def和使用lambda,定义的函数功能完全一致,只是使用lambda关键字定义的函数是匿名的,无法使用第二次。
文件
编码
编码就是一种规则集合,记录了内容和二进制的相互转换的逻辑。最常使用的编码是UTF-8编码
计算机中有许多可以用的编码:UTF-8、 GBK、 Big5
UTF-8是目前全球通用的编码格式,除非有特殊要求,否则,一律以UTF-8格式进行文件编码
什么是文件 :
内存中存放的数据在计算机关机后就会消失,要长久保存数据,就要使用硬盘、光盘、U盘等设备。为了便于数据的管理和检索,引入了“文件”的概念
一篇文章、一段视频、一个可执行程序,都可以被保存为一个文件,并赋予一个文件名。操作系统以文件为单位管理磁盘中的数据。
一般来说,文件可分为文本文件、视频文件、音频文件、图像文件、可执行文件等多种类型。
文件的操作主要包括:打开、关闭、读、写等操作
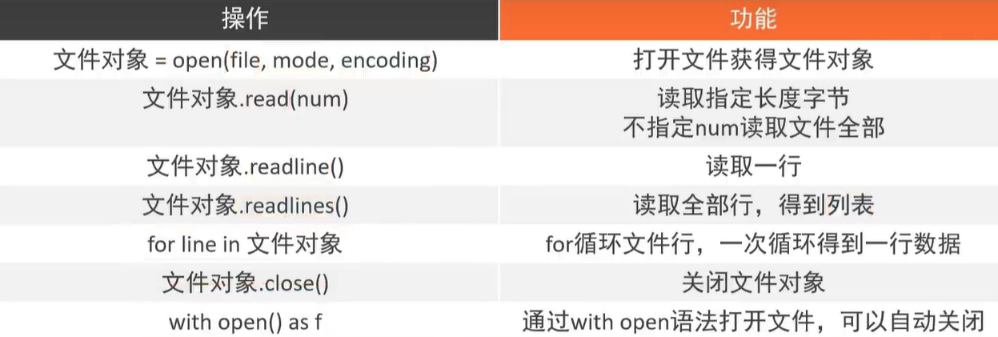
open( )打开函数
在Python中,使用open函数,可以打开一个已经存在的文件,或者是创建一个新文件,语法如下:
open(nema, mode, encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
r :以只读方式打开文件,文件的指针将会放在文件的开头,这是默认模式
w:打开一个文件只用于写入。如果该文件已存在则打开文件,并从头开始编辑,原有内容会被删除。如果该文件不存在,则创建新文件。
a:打开一个文件用于追加。如果该文件已存在,新的内容会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
encoding:编码格式(推荐使用UTF-8)
示例:
f = open('python.txt','r',encoding="UTF-8") # 注意:前两个是位置传参,但是encoding并不是第三位实际上,所以要用关键字传参
注意: 此时的 'f' 是 'open' 函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象. 属性或对象. 方法 对其进行访问。
read( )
语法:文件对象. read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
注意:读取文件,都会从上一个读取的地方继续读下去
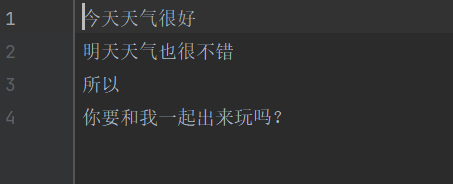
# 打开文件 f = open("测试.txt", "r", encoding= "UTF-8") print(type(f)) # 结果是<class '_io.TextIOWrapper'> # 读取文件 - read() print(f"读取10个字节的结果:{f.read(7)}") # 结果是:读取10个字节的结果:今天天气很好 print(f"read方法读取全部内容的结果是:{f.read()}") """ line 6 结果: read方法读取全部内容的结果是:明天天气也很不错 所以 你要和我一起出来玩吗? """
测试文件:
readlines( )方法
readlines可以按照行的方式把整个文件中的内容一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
f = open("测试.txt", "r", encoding= "UTF-8") lines = f.readlines() # 读取文件的全部行,封装到列表中 print(f"lines对象的类型:{type(lines)}") # 结果是:<class '_io.TextIOWrapper'> print(f"lines对象的内容是:{lines}") # 结果是:lines对象的内容是:['今天天气很好\n', '明天天气也很不错\n', '所以\n', '你要和我一起出来玩吗?']
readline( )方法
一次读取一行内容
f = open("测试.txt", encoding="UTF-8") content = f.readline() print(f"第一行:{content}") # 结果:第一行:今天天气很好 content = f.readline() print(f"第二行:{content}") # 结果:第二行:明天天气也很不错
for循环读取文件行
for line in open("测试.txt", encoding="UTF-8"): # 每一个line临时变量,就记录了文件的一行数据 print(line)
close ( )
关闭文件对象
f = open("测试.txt", "r") f.close() # 最后通过close,关闭文件对象,也就是关闭对文件的占用 # 如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用
with open()
通过with open( )的语句块对文件进行操作,可以在操作完成后自动关闭close文件,避免忘掉close方法
with open("测试.txt", "r", encoding="UTF-8") as f: for line in f: print(f"每一行数据是:{line}")
写文件
写入文件使用open函数的 "w" 模式进行写入
写入的方法有: write( ):写入内容; flush( ):刷新内容写到硬盘中
注意: w模式,文件不存在时,会创建新文件; w模式,文件存在时,会清空原有内容; close( )方法,会带有flush( )方法的功能
直接调用write,内容并未真正写入文件,而是会积攒在程序的内容中,称之为缓冲区;当调用flush 的时候,内容会真正写入文件; 这样做是避免频繁的操作硬盘, 导致效率下降
f = open("测试.txt", "w", encoding="UTF-8") # write写入 f.write("Hello World!!") # flush刷新 f.flush() # 将内存中积攒的内容,导入到硬盘的文件中
追加
追加写入的方法:'a' 模式,write( ),写入内容; flush( ), 刷新内容到硬盘中
注意: a模式,文件不存在,会创建新文件; a模式, 文件存在,会在原有内容后面继续写入; 也可以使用 “\n” 来写出换行符
f = open("测试.txt", "a", encoding="UTF-8") # write写入,flush刷新 f.write("\n今天很好!") # close 关闭, close自带flush刷新功能 f.close()
Python异常
当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”, 也就是我们常说的BUG
异常处理
我们要做的,不是力求程序完美运行,而是在力所能及的范围内,对可能出现的bug进行提前准备、提前处理。这种行为称之为:异常处理(捕获异常)
捕获异常的作用在于:提前假设某处会出现异常,提前做好准备,当真的出现异常时,可以有后续手段

基本语法:
try :
可能发生错误的代码
except :
如果出现异常执行的代码
示例:
# 尝试以 'r'模式打开文件,如果文件不存在,则以'w' 方式打开 try: f = open("测试.txt",'r') except: f = open("测试.txt",'w')
捕获指定异常:
注意:①如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常
②一般try下方只放一行尝试执行的代码
try: print(name) except NameError as e: print('name变量名称未定义错误')
捕获多个异常
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except后,并使用元组的方式进行书写
try: print(1/0) except(NameError,ZeroDivisionError): print('ZeroDivision错误...')
捕获所有异常
Exception中包含所有的异常
①except: ②except Exception
异常else
else表示的是如果没有异常要执行的代码
try: print("Hello!") except Exception as e: print("出现异常了!") else: print("我是else,是没有异常的时候执行的代码")
异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件
try: f = open("测试.txt", 'r', encoding="UTF-8") except Exception as e: f = open("测试.txt", 'w', encoding="UTF-8") else: print("好高兴,没有异常") finally: print(f"我是finally,有没有异常我都要执行") f.close()
异常的传递
异常不一定要在异常处查找,可以通过异常的传递发现
def func1(): print("func1 开始执行") num = 1 / 0 #异常,除以0异常 # 定义一个无异常的方法,调用上面的方法 def func2(): print("func2 开始执行") func1() print("func2 结束执行") # 定义一个方法,调用上面的方法 def main(): try: func2() except Exception as e: print(f"出现异常了!异常的信息是:{e}") main()
模块
Python模块(Module)是一个Python文件,以 .py 结尾,模块能定义函数、类和变量,模块里也能包含可执行的代码
模块的作用:Python中有很多各种不同的模块,每一个模块都可以帮助快速的实现一些功能,比如实现和时间相关的功能就可以使用time模块
模块的导入方式
[ from 模块名 ] import [ 模块 | 类 | 变量 | 函数 | * ] [ as 别名 ]
常用的组合形式:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
import 模块名
基本语法:
import 模块名; import 模块名1, 模块名2
模块名 . 功能名()
# 导入时间time模块 import time print("开始") # 让程序睡眠1秒(阻塞) time.sleep(1) print("结束")
from 模块名 import 功能名
语法:
from 模块名 import 功能名
功能名()
# 导入时间time模块的sleep功能 from time import sleep print("开始") # 让程序睡眠1秒(阻塞) sleep(1) print("结束")
from 模块名 import *
语法:
from 模块名 import *
功能名()
# 导入时间模块中的所有方法 from time import * print("开始") # 让程序睡眠1秒(阻塞) sleep(1) print("结束")
as 定义别名
模块名定义别名: import 模块名 as 别名; 功能名定义别名:from 模块名 import 功能 as 别名
# 模块名别名 import time as t t.sleep(3) # 功能名别名 from time import sleep as sl sl(2)
自定义模块
Python中已经帮我们实现了很多的模块,不过有时候我们需要一些个性化的模块,这里就可以通过自定义模块实现
注意:每个Python文件都可以作为一个模块,模块的名字就是文件的名字,也就是说自定义模块名必须要符合标识符命名规则
# 导入不同模块的同名功能 from my_module1 import test from my_module2 import test """ 如果有两个模块中有同名的功能,那么只会使用后一个导入的模块的功能,会将前面的覆盖掉 """ test (1, 2)
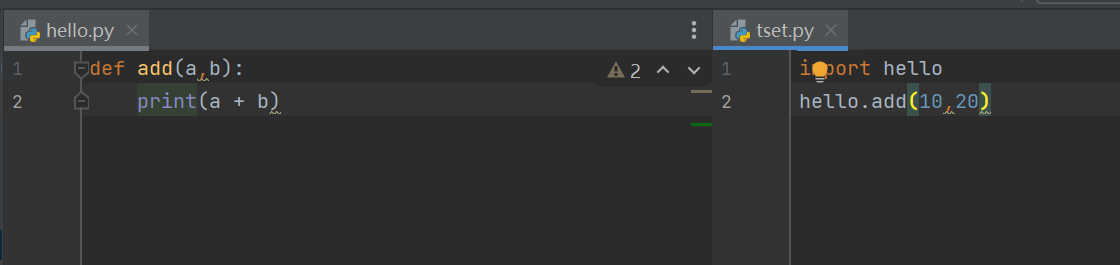
__main__变量
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,会在py文件中添加一些测试信息,例如:hello.py文件中添加测试代码 add(1,2)
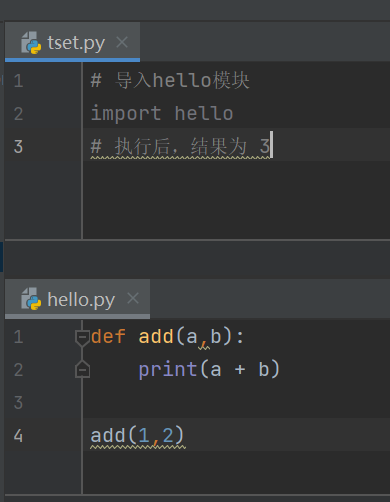
尽管test.py文件只是导入了hello.py文件,但是运行之后,hello.py文件中的所有内容都被执行了一遍。
解决方法:
def add(a,b): print(a + b) # 只在当前文件中调用该函数,其他导入的文件内不符合该条件则不会执行函数的调用 # 简而言之,只有在当前文件中运行时,才会是的下面if条件成立: if __name__ == '__main__': add(1,2)
__all__变量
如果一个模块文件中有 '_all_' 变量,当使用 'from xxx import * ' 导入时,只能导入这个列表中的元素
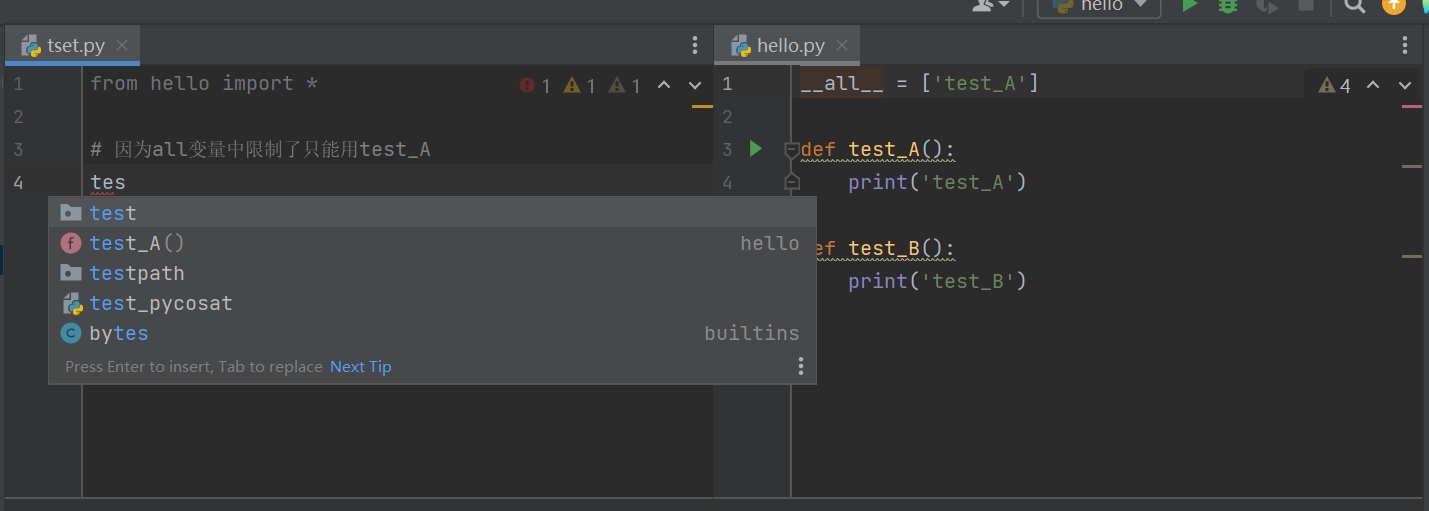
python包
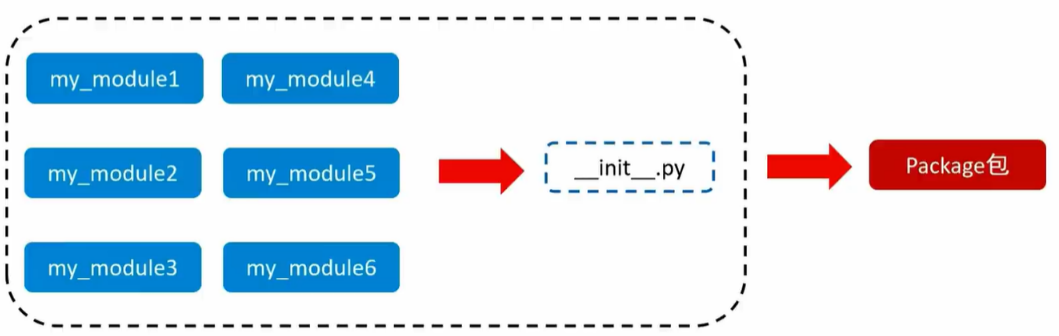
从物理上看,包就是一个文件夹,在该文件夹下包含了一个__init__.py文件,该文件可用于包含多个模块文件
从逻辑上看,包的本质依然是模块
新建一个包:

导入包:方式一:
# 导入自定义的包中的模块,并使用: import my_package.my_module1 import my_package.my_module2 my_package.my_module1.info_print1() my_package.my_module2.info_print2()
方式二:
# 导入自定义的包中的模块,并使用: from my_package import my_module1 from my_package import my_module2 my_module1.info_print1() my_module2.info_print2()
方式三:
# 导入自定义的包中的模块,并使用: from my_package.my_module1 import info_print1 from my_package.my_module2 import info_print2 info_print1() info_print2()
__all__变量限制模块
注意必须在' __init__.py'文件中添加 '__all__ = [ ]',控制允许导入的模块列表
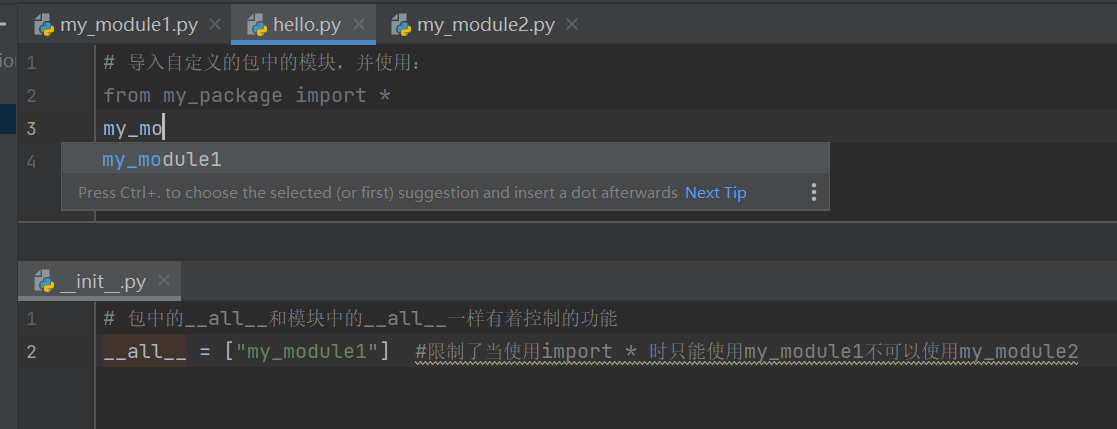
__init__.py文件
创建包会默认自动创建的文件,通过这个文件来表示一个文件夹是Python的包,而非普通的文件夹
第三方包
在Python程序的生态中,有许多的第三方包,可以极大地帮助我们提升开发效率,如:
科学计算中常用的:numpy包
数据分析中常用的:pandas包
大数据计算汇总常用的:pyspark、apache-flink包
图形可视化常用的:matplotlib、pyecharts
人工智能常用的:tensorflow
第三方包的安装十分简单,我们只需要使用Python内置的pip程序即可。在命令提示符程序中输入: pip install 包名称 即可快速安装第三方包
pip的网络优化
由于pip是连接的国外的网站进行包的下载,有时候速度过慢,可以通过如下命令,让其连接国内的网站进行包的安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
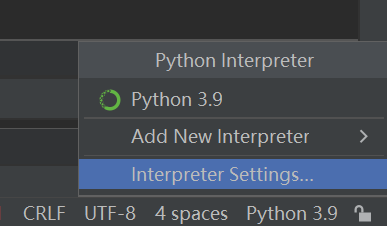
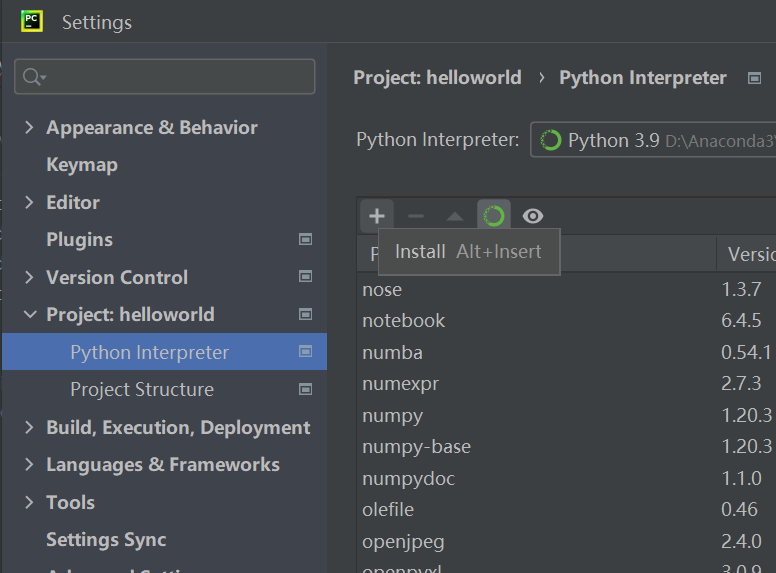
使用pycharm安装第三方包:
点击Interpreter Settings...
点击+号


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话