利用pandas的read_csv函数读取data类型的文件
1. pycharm新建一个项目,如Python_paper_experiment
2.下载一个.data数据集,如UCI数据集之iris.data(150个样本,每个样本都有四个属和一个类别:"sepal length", "sepal width", "petal length", "petal width", "class")。
iris.data数据集下载地址:UCI Machine Learning Repository: Iris Data Set, 这种.data文件可以在Vscode和pycharm中打开大概观察一下
之后将iris.data文件放入第一步创建的项目中,项目结构如下:
3.一段小代码实现iris.data的读取与打印输出
sep:separator的缩写,表示分隔符,建议用逗号
names:每一个属性的名字(列名), iris.data的最后一列是class,表示每一个样本的类别

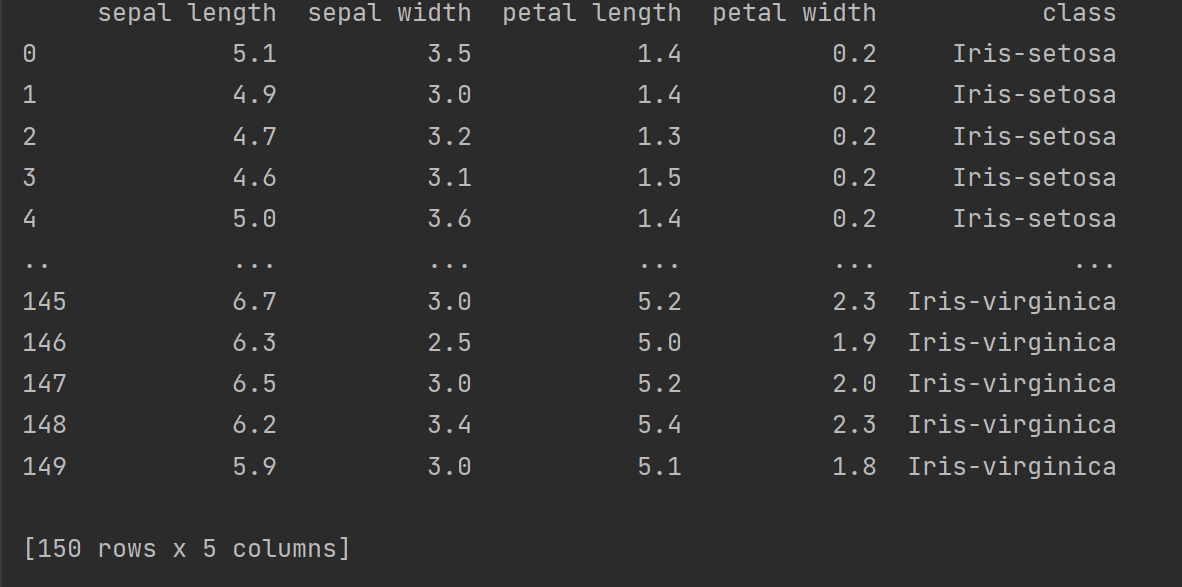
输出data:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号