
图解Redis(一):数据结构,缓存使用,缓存问题,单线程,和Memcached区别
之前也介绍过redis,但是今天看到了这位老哥写的文章,嗯.....不得不说,还是大佬厉害。写的很详细,有图有代码。在此对作者进行感谢,本文在原文基础上进行 了版本重新排版和润饰。
目录:
1、什么是redis
2、redis的五种基本数据类型
- String
- list
- hashmap
- set
- zset
3、redis结合spring boot的使用(作为缓存使用)
4、缓存问题
- 雪崩
- 穿透
- 击穿
5、Redis的速度
- 单线程的好处
6、Redis和Memcached的区别
- 存储方式上
- 数据支持类型上
- 使用底层模型不同
- Value的大小
1、什么是Redis
Redis 是 C 语言开发的一个开源的(遵从 BSD 协议)高性能键值对(key-value)的内存数据库,可以用作数据库、缓存、消息中间件等。
它是一种 NoSQL(not-only sql,泛指非关系型数据库)的数据库。
其优点是,Redis 作为一个内存数据库:
-
性能优秀,数据在内存中,读写速度非常快,支持并发 10W QPS。
-
单进程单线程,是线程安全的,采用 IO 多路复用机制。
-
丰富的数据类型,支持字符串(string)、散列(hash)、列表(list)、集合(set)、有序集合(sorted sets,又叫zset)等。
-
支持数据持久化,可以将内存中数据保存在磁盘中,重启时加载。
-
主从复制,哨兵,高可用。
-
可以用作分布式锁。
-
可以作为消息中间件使用,支持发布-订阅。
2、五种基本数据类型
在Redis 内部内存管理中是如何描述这五种基本类型:
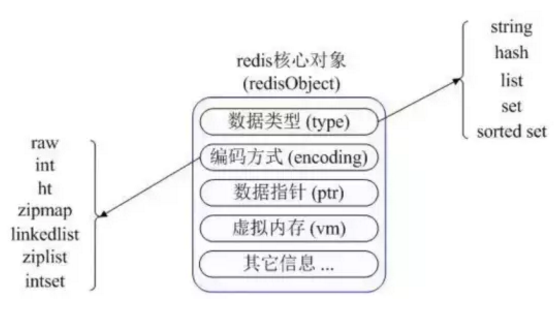
首先 Redis 内部使用一个 redisObject 对象来表示所有的 key 和 value。
redisObject 最主要的信息如上图所示:type 表示一个 value 对象具体是何种数据类型,encoding 是不同数据类型在 Redis 内部的存储方式。比如:type=string 表示 value 存储的是一个普通字符串,那么 encoding 可以是 raw 或者 int。
那么,具体这五种类型是如何表示的呢?请往下看:
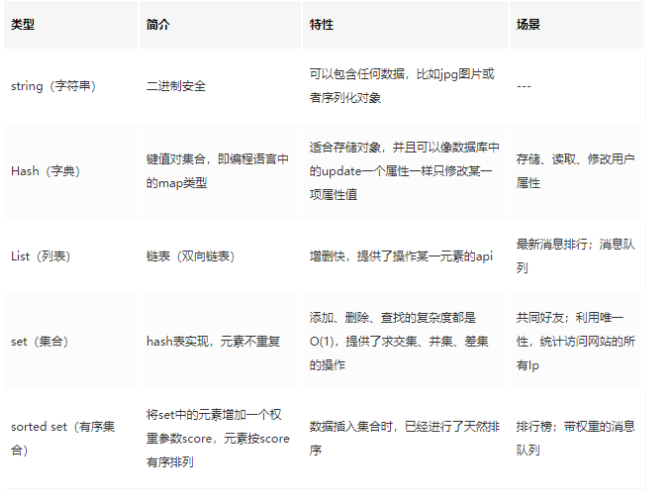
①:String
String是 Redis 最基本的类型,可以理解成与 Memcached一模一样的类型,一个 Key 对应一个 Value。Value 不仅是 String,也可以是数字。
String 类型是二进制安全的,意思是 Redis 的 String 类型可以包含任何数据,比如 jpg 图片或者序列化的对象。String 类型的值最大能存储 512M。
②:Hash
Hash是一个键值(key-value)的集合。Redis 的 Hash 是一个 String 的 Key 和 Value 的映射表,Hash 特别适合存储对象。常用命令:hget,hset,hgetall 等。
③:List
List列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边) 常用命令:lpush、rpush、lpop、rpop、lrange(获取列表片段)等。
数据结构:List 就是链表,可以用来当消息队列用。Redis 提供了 List 的 Push 和 Pop 操作,还提供了操作某一段的 API,可以直接查询或者删除某一段的元素。
实现方式:Redis List 的是实现是一个双向链表,既可以支持反向查找和遍历,更方便操作,不过带来了额外的内存开销。
应用场景:List 应用场景非常多,也是 Redis 最重要的数据结构之一,比如 Twitter 的关注列表,粉丝列表都可以用 List 结构来实现。
④:Set
Set是 String 类型的无序集合。集合是通过 hashtable 实现的。Set 中的元素是没有顺序的,而且是没有重复的。常用命令:sdd、spop、smembers、sunion 等。
应用场景:Redis Set 对外提供的功能和 List 一样是一个列表,特殊之处在于 Set 是自动去重的,而且 Set 提供了判断某个成员是否在一个 Set 集合中。通过交集可查看是否有共同好友。
⑤:Zset
Zset和 Set 一样是 String 类型元素的集合,且不允许重复的元素。常用命令:zadd、zrange、zrem、zcard 等。当你需要一个有序的并且不重复的集合列表,那么可以选择 Sorted Set 结构。
和 Set 相比,Sorted Set关联了一个 Double 类型权重的参数 Score,使得集合中的元素能够按照 Score 进行有序排列,Redis 正是通过分数score来为集合中的成员进行从小到大的排序。
实现方式:Redis Sorted Set 的内部使用 HashMap 和跳跃表(skipList)来保证数据的存储和有序:HashMap 里放的是成员到 Score 的映射,而跳跃表里存放的是所有的成员,排序依据是 HashMap 里存的 Score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
五种数据类型总结:
3、Redis结合spring boot的使用
结合 Spring Boot 使用,一般有两种方式:
- 一种是直接通过 RedisTemplate 来使用;
- 一种是使用 Spring Cache 集成 Redis(也就是注解的方式)。
接下来 我们做一个小case来看一下:
第一步:先引入对应的依赖:pom.xml 中添加:


<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>
注意:
1、spring-boot-starter-data-redis:在 Spring Boot 2.x 以后底层不再使用 Jedis,而是换成了 Lettuce。
2、commons-pool2:用作 Redis 连接池,如不引入启动会报错。
3、spring-session-data-redis:Spring Session 引入,用作共享 Session。
第二步:配置文件 application.yml 的配置:
server:
port: 8082
servlet:
session:
timeout: 30ms
spring:
cache:
type: redis
redis:
host: 127.0.0.1
port: 6379
password:
# redis默认情况下有16个分片,这里配置具体使用的分片,默认为0
database: 0
lettuce:
pool:
# 连接池最大连接数(使用负数表示没有限制),默认8
max-active: 100
第三步:创建实体类User.java
public class User implements Serializable{ private static final long serialVersionUID = 662692455422902539L; private Integer id; private String name; private Integer age; public User() { } public User(Integer id, String name, Integer age) { this.id = id; this.name = name; this.age = age; } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public String toString() { return "User{" + "id=" + id + ", name='" + name + '\'' + ", age=" + age + '}'; } }
第四步:分别通过两种方式来使用
(1)直接通过 RedisTemplate 来使用
默认情况下的模板只能支持 RedisTemplate<String, String>,也就是只能存入字符串,所以自定义模板很有必要。
添加配置类 RedisCacheConfig.java:
@Configuration @AutoConfigureAfter(RedisAutoConfiguration.class) public class RedisCacheConfig { @Bean public RedisTemplate<String, Serializable> redisCacheTemplate(LettuceConnectionFactory connectionFactory) { RedisTemplate<String, Serializable> template = new RedisTemplate<>(); template.setKeySerializer(new StringRedisSerializer()); template.setValueSerializer(new GenericJackson2JsonRedisSerializer()); template.setConnectionFactory(connectionFactory); return template; } }
添加测试类:
@RestController @RequestMapping("/user") public class UserController { public static Logger logger = LogManager.getLogger(UserController.class); @Autowired private StringRedisTemplate stringRedisTemplate; @Autowired private RedisTemplate<String, Serializable> redisCacheTemplate; @RequestMapping("/test") public void test() { redisCacheTemplate.opsForValue().set("userkey", new User(1, "张三", 25)); User user = (User) redisCacheTemplate.opsForValue().get("userkey"); logger.info("当前获取对象:{}", user.toString()); }
然后在浏览器访问,观察后台日志 http://localhost:8082/user/test

(2)使用 Spring Cache 集成 Redis(注解的方式)
Spring Cache 具备很好的灵活性,不仅能够使用 SPEL(spring expression language)来定义缓存的 Key 和各种 Condition,还提供了开箱即用的缓存临时存储方案,也支持和主流的专业缓存如 EhCache、Redis、Guava 的集成。
定义接口 UserService.java:
public interface UserService { User save(User user); void delete(int id); User get(Integer id); }
接口实现类 UserServiceImpl.java:
@Service public class UserServiceImpl implements UserService{ public static Logger logger = LogManager.getLogger(UserServiceImpl.class); private static Map<Integer, User> userMap = new HashMap<>(); static { userMap.put(1, new User(1, "肖战", 25)); userMap.put(2, new User(2, "王一博", 26)); userMap.put(3, new User(3, "杨紫", 24)); } @CachePut(value ="user", key = "#user.id") @Override public User save(User user) { userMap.put(user.getId(), user); logger.info("进入save方法,当前存储对象:{}", user.toString()); return user; } @CacheEvict(value="user", key = "#id") @Override public void delete(int id) { userMap.remove(id); logger.info("进入delete方法,删除成功"); } @Cacheable(value = "user", key = "#id") @Override public User get(Integer id) { logger.info("进入get方法,当前获取对象:{}", userMap.get(id)==null?null:userMap.get(id).toString()); return userMap.get(id); } }
为了方便演示数据库的操作,这里直接定义了一个 Map<Integer,User> userMap。
注意,这里的核心是三个注解:
-
@Cachable
-
@CachePut
-
@CacheEvict
测试类:UserController
@RestController @RequestMapping("/user") public class UserController { public static Logger logger = LogManager.getLogger(UserController.class); @Autowired private StringRedisTemplate stringRedisTemplate; @Autowired private RedisTemplate<String, Serializable> redisCacheTemplate; @Autowired private UserService userService; @RequestMapping("/test") public void test() { redisCacheTemplate.opsForValue().set("userkey", new User(1, "张三", 25)); User user = (User) redisCacheTemplate.opsForValue().get("userkey"); logger.info("当前获取对象:{}", user.toString()); } @RequestMapping("/add") public void add() { User user = userService.save(new User(4, "李现", 30)); logger.info("添加的用户信息:{}",user.toString()); } @RequestMapping("/delete") public void delete() { userService.delete(4); } @RequestMapping("/get/{id}") public void get(@PathVariable("id") String idStr) throws Exception{ if (StringUtils.isBlank(idStr)) { throw new Exception("id为空"); } Integer id = Integer.parseInt(idStr); User user = userService.get(id); logger.info("获取的用户信息:{}",user.toString()); } }
用缓存要注意,启动类要加上一个注解开启缓存:
@SpringBootApplication(exclude=DataSourceAutoConfiguration.class) @EnableCaching public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
①先调用添加接口:http://localhost:8082/user/add

②再调用查询接口,查询 id=4 的用户信息:

可以看出,这里已经从缓存中获取数据了,因为上一步 add 方法已经把 id=4 的用户数据放入了 Redis 缓存 3、调用删除方法,删除 id=4 的用户信息,同时清除缓存:

④再次调用查询接口,查询 id=4 的用户信息:

没有了缓存,所以进入了 get 方法,从 userMap 中获取。
缓存注解
①、@Cacheable
根据方法的请求参数对其结果进行缓存:
-
Key:缓存的 Key,可以为空,如果指定要按照 SPEL 表达式编写,如果不指定,则按照方法的所有参数进行组合。
-
Value:缓存的名称,必须指定至少一个(如 @Cacheable (value='user')或者 @Cacheable(value={'user1','user2'}))
-
Condition:缓存的条件,可以为空,使用 SPEL 编写,返回 true 或者 false,只有为 true 才进行缓存。
②、@CachePut
根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发真实方法的调用。参数描述见上。
③、@CacheEvict
根据条件对缓存进行清空:
-
Key:同上。
-
Value:同上。
-
Condition:同上。
-
allEntries:是否清空所有缓存内容,缺省为 false,如果指定为 true,则方法调用后将立即清空所有缓存。
-
beforeInvocation:是否在方法执行前就清空,缺省为 false,如果指定为 true,则在方法还没有执行的时候就清空缓存。缺省情况下,如果方法执行抛出异常,则不会清空缓存。
4、缓存问题
在将redis作为缓存使用的过程中,会出现哪些问题呢?
比如,既然作为缓存,那肯定会存在和数据库的数据一致性问题。如果项目对缓存的要求比较高,是强一致性的,那么就不要使用缓存。而对于要求较低的场景,我们可以使用合适的策略来降低不一致的概率,如:合适的缓存更新策略,更新数据库后及时更新缓存,缓存失败后增加重试机制等。
-
雪崩
那么,还有一种极端情况就是,当缓存中大部分或者所有的数据都是过期的了,那么在当某时间内有大量请求操作,那么此时这些请求就全部会落到数据库上,那么数据库如果扛不住的话,就发生了“雪崩”现象。
举个栗子:
目前电商首页以及热点数据都会去做缓存,一般缓存都是定时任务去刷新,或者查不到之后去更新缓存的,定时任务刷新就有一个问题。
如果首页所有 Key 的失效时间都是 12 小时,中午 12 点刷新的,我零点有个大促活动大量用户涌入,假设每秒 6000 个请求,本来缓存可以抗住每秒 5000 个请求,但是缓存中所有 Key 都失效了。此时 6000 个/秒的请求全部落在了数据库上,数据库必然扛不住,直接挂掉。如果重启DB,数据库立马又会被新流量给打死了。
这就是我理解的缓存雪崩——同一时间大面积失效,瞬间 Redis 跟没有一样,那这个数量级别的请求直接打到数据库几乎是灾难性的。
你想想如果挂的是一个用户服务的库,那其他依赖他的库所有接口几乎都会报错。如果没做熔断等策略基本上就是瞬间挂一片的节奏,你怎么重启用户都会把你打挂,等你重启好的时候,用户早睡觉去了,临睡之前,骂骂咧咧“什么垃圾产品”。
那么,这种情况如何解决呢?(如何解决雪崩问题)
在批量往Redis里存数据时,给每个Key都加一个随机失效时间,这样就不会产生大片数据同时失效的情况, 从根源上解决。
setRedis(key, value, time+Math.random()*10000);
如果Redis是集群部署,那么将热点数据均匀分散到不同的Redis库中,这样也可以避免全部失效。
再不济就是设置热点数据永不过期,有更新操作就更新缓存,如运维更新了首页商品,那你刷下缓存就OK,。
-
缓存穿透
缓存穿透指的是缓存和数据库中都没有,但是用户却在不断地发起请求。
举个栗子:我们数据库的 id 都是从 1 自增的,如果发起 id=-1 的数据或者 id 特别大不存在的数据,这样的不断攻击导致数据库压力很大,严重会击垮数据库。
解决办法:
在接口层增加校验,比如:用户鉴权,参数做校验,不合法的校验直接return,比如id做基础校验,id<=0直接拦截等。
此外,还有一个高端玩家的玩法,就是使用布隆过滤器(Bloom Filter),其原理就是利用高效的数据结构和算法快速判断你这个Key是否在DB中存在,如果不存在就返回,存在就去查DB刷新K-V再返回。
-
缓存击穿
缓存击穿和缓存雪崩类似,但是又不完全一样。雪崩是因为大面积的缓存失效,导致大量请求打崩了DB。而击穿是指一个key非常热点,在不停的扛着大量的请求,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发直接落到了DB上,就在这个Key的点上击穿了缓存。
即:雪崩可以理解为是大面积的击穿。
那么,击穿该如何解决呢?
有两条思路:
一是像解决雪崩类似,只不过雪崩是设置过期时间为随机的,而击穿是设置热点数据永不过期;
二是加上互斥锁。即先在redis缓存中查找,如果缓存中没有,则获得锁,再去DB中查找,查到后返回并更新Redis缓存,再释放锁。有人问,这里去DB中如果也查不到呢?那怎么办,大哥,去DB中查不到,那就不是击穿了,那是穿透了,哈哈哈。
加互斥锁代码如下:
public static String getData(String key) throws InterruptedException { //从Redis查询数据 String result = getDataByKV(key); //参数校验 if (StringUtils.isBlank(result)) { try { //获得锁 if (reenLock.tryLock()) { //去数据库查询 result = getDataByDB(key); //校验 if (StringUtils.isNotBlank(result)) { //插进缓存 setDataToKV(key, result); } } else { //睡一会再拿 Thread.sleep(100L); result = getData(key); } } finally { //释放锁 reenLock.unlock(); } } return result; }
5、Redis的速度
对于Redis速度,不用我说了,肯定很快啦,要不然大家也不会用它。
官方提供的数据显示:它可以达到 100,000+ 的 QPS(每秒内的查询次数),这个数据不比 Memcached 差!
我们知道Redis是单线程的,那么为什么还能这么快呢?
Redis 确实是单进程单线程的模型,因为 Redis 完全是基于内存的操作,CPU 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章的采用单线程的方案了(毕竟采用多线程会有很多麻烦)。
之所以单线程还快,有如下四点:
-
Redis 完全基于内存,绝大部分请求是纯粹的内存操作,非常迅速,数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度是 O(1)。
-
数据结构简单,对数据操作也简单。
-
采用单线程,避免了不必要的上下文切换和竞争条件,不存在多线程导致的 CPU 切换,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有死锁问题导致的性能消耗。
-
使用多路复用 IO 模型,非阻塞 IO。
6、Redis和Memcached的区别
平时为什么选择 Redis 的缓存方案而不用 Memcached ?
原因有如下四点:
-
存储方式上:Memcache 会把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。Redis 有部分数据存在硬盘上,这样能保证数据的持久性。
-
数据支持类型上:Memcache 对数据类型的支持简单,只支持简单的 key-value,,而 Redis 支持五种数据类型。
-
使用底层模型不同:它们之间底层实现方式以及与客户端之间通信的应用协议不一样。Redis 直接自己构建了 VM 机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
-
Value 的大小:Redis 可以达到 1GB,而 Memcache 只有 1MB。
参考及致谢:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号