


Redis之哨兵机制(sentinel)——配置详解及原理介绍
说到Redis不得不提哨兵模式,那么究竟哨兵是什么意思?为什么要使用哨兵呢?
接下来一一为您讲解:
1.为什么要用到哨兵
哨兵(Sentinel)主要是为了解决在主从(master-slave)复制架构中出现宕机的情况,主要分为两种:
1.1 从Redis宕机(slave)
在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据。
在Redis2.8版本后,主从断线后恢复的情况下实现增量复制。
1.2 主Redis宕机(master)
需要以下2步才能完成:
i.第一步,在从数据库中执行 SLAVEOF NO ONE 命令,断开主从关系并且提升为主库继续服务;
ii.第二步,将主库重新启动后,执行 SLAVEOF 命令,将其设置为其他库的从库,这时数据就能更新回来。
由于这个手动完成恢复的过程其实是比较麻烦的并且容易出错,所以Redis提供的哨兵(sentinel)的功能来解决.
2.什么是哨兵
Redis-Sentinel是用于管理Redis集群,该系统执行以下三个任务:
2.1 监控(Monitoring):
Sentinel会不断地检查你的主服务器和从服务器是否运作正常;
2.2 提醒(Notification):
当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知;
2.3 自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时,Sentinel 会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
3.Sentinel集群搭建
3.1 Sentinel集群拓扑图
而哨兵也分为单哨兵和多哨兵两种模式:
- 单哨兵模式
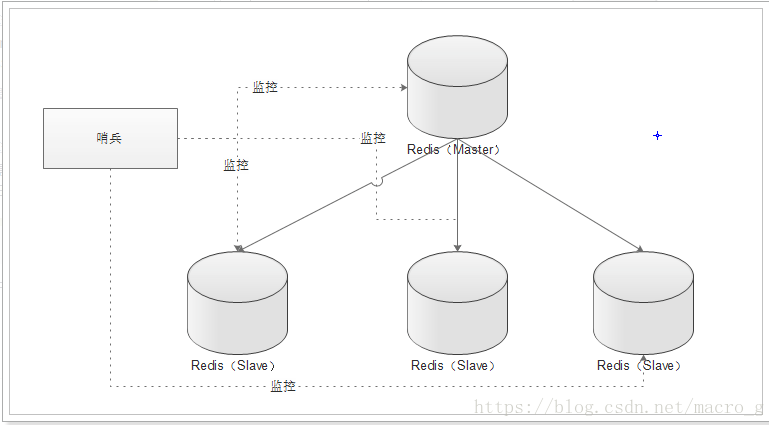
- 多哨兵模式
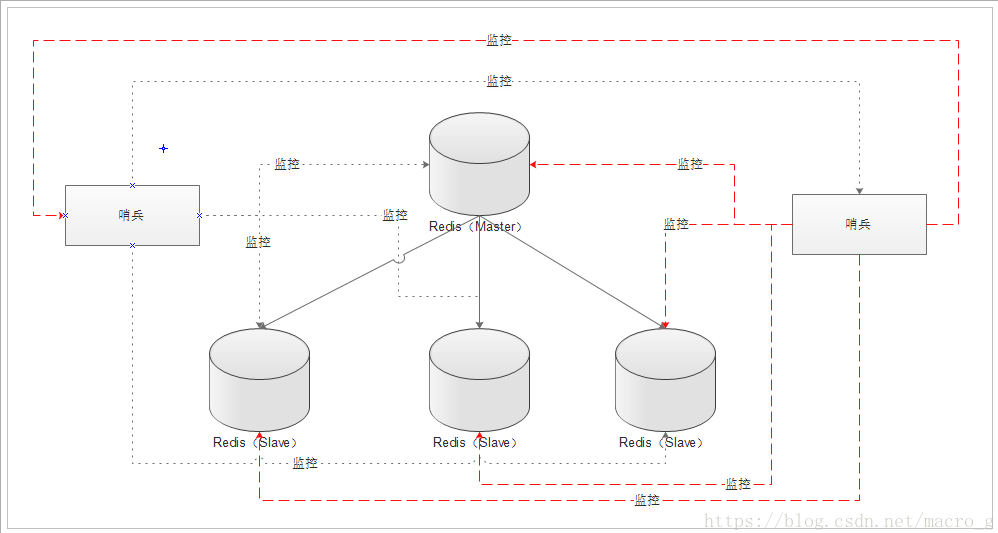
通过两个图示很容易发现:多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控。
3.2 在保证Redis主从架构集群可用的前提下,复制三份配置文件
# 进入redis所在目录
cd /usr/local/src/redis-3.2.1
# 创建6379、6380、6381目录,分别将安装目录下的sentinel.conf拷贝到这三个目录下
mkdir -p /usr/local/redis/6379 && cp sentinel.conf /usr/local/redis/6379/26379.conf
mkdir -p /usr/local/redis/6380 && cp sentinel.conf /usr/local/redis/6380/26380.conf
mkdir -p /usr/local/redis/6381 && cp sentinel.conf /usr/local/redis/6381/26381.conf
3.3 分别配置三个哨兵
# 修改sentinel配置文件
vim /usr/local/redis/6379/26379.conf
修改内容:
# 添加守护进程模式
daemonize yes
# 添加指明日志文件名
logfile "/usr/local/redis/6379/sentinel26379.log"
# 修改工作目录
dir "/usr/local/redis/6379"
# 修改启动端口
port 26379
# 添加关闭保护模式
protected-mode no
# 修改sentinel monitor
sentinel monitor macrog-master 192.168.24.131 6379 2
# 将配置文件中mymaster全部替换macrog-master
# 在末行模式下 输入 :%s/mymaster/macrog-master/g
依次修改26380,26381配置
说明:
macrog-master:监控主数据的名称,自定义即可,可以使用大小写字母和“.-_”符号
192.168.24.131:监控的主数据库的IP
6379:监控的主数据库的端口
2:最低通过票数
3.4 启动哨兵进程
redis-sentinel /usr/local/redis/6379/26379.conf //或者 redis-server /usr/local/redis/6379/26379.conf --sentinel
redis-sentinel /usr/local/redis/6380/26380.conf //或者 redis-server /usr/local/redis/6380/26380.conf --sentinel
redis-sentinel /usr/local/redis/6381/26381.conf //或者 redis-server /usr/local/redis/6381/26381.conf --sentinel
3.5. 测试
测试前分别打开三个哨兵的日志(上面配置有logfile的名字):
1、 从库宕机(6380)
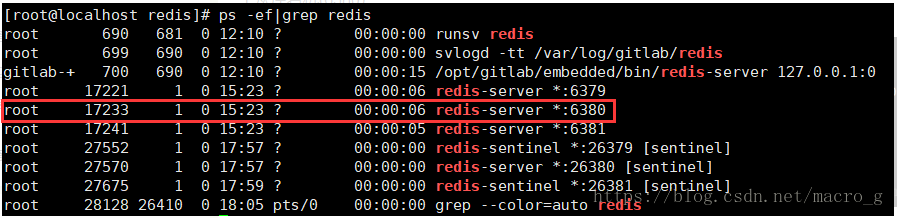
手动使从库6380宕机,即杀掉该进程:
kill -9 17233
30s后,26379/26380/26381日志均打印:
27552:X 10 Sep 18:12:12.757 # +sdown slave 192.168.24.131:6380 192.168.24.131 6380 @ macrog-master 192.168.24.131 6379
这表示:检测到从库宕机(+sdown: Subjective down主观宕机,第4节介绍),并告知master库6379。
现在我们重新启动6380实例。
redis-server 6380/6380.conf
26379/26380/26381日志均打印:
27570:X 10 Sep 18:15:40.384 * +reboot slave 192.168.24.131:6380 192.168.24.131 6380 @ macrog-master 192.168.24.131 6379
27570:X 10 Sep 18:15:40.451 # -sdown slave 192.168.24.131:6380 192.168.24.131 6380 @ macrog-master 192.168.24.131 6379
可以看出:slave重新加入到了主从复制中。-sdown:说明是恢复服务。
2、 主库宕机(6379)
同样的我们手动将master库宕机:
kill -9 17221
30s后, 26381日志打印:
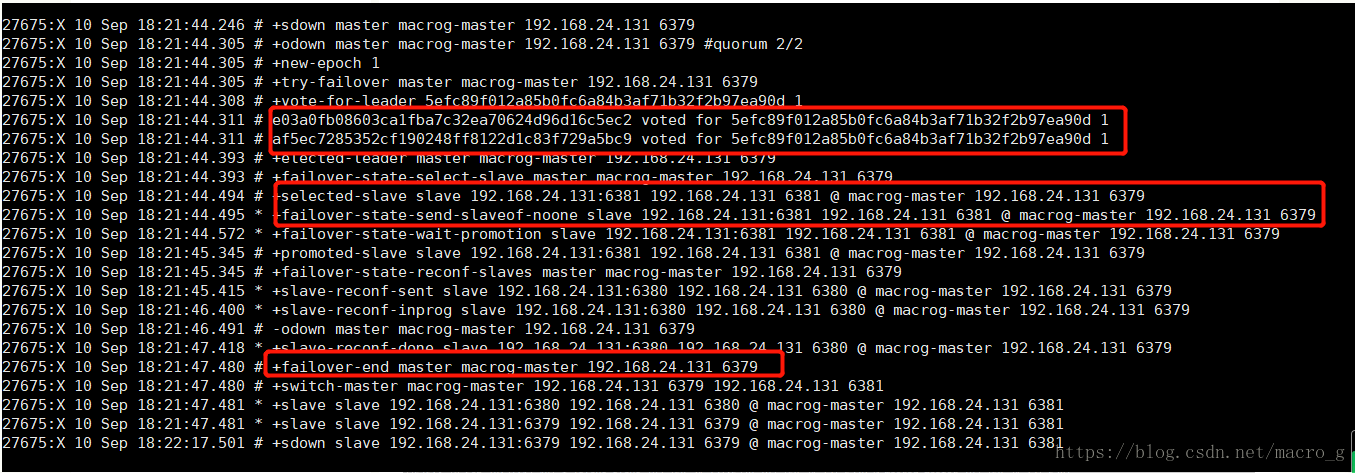
最上面两条log表示master宕机(+sdown,+odown分别表示主观宕机和客观宕机,第4节介绍)
第二个红方框表示:哨兵将哨兵中某一个选举成为leader,选择6381为新的master;
最后三行表示:设置6379和6380为6381的slave;
也可以通过info replication查看主从关系 发现master已经切换为6381。
接下来,我们恢复6379(原master),查看状态:
redis-server 6379/6379.conf
日志均打印:
27675:X 10 Sep 18:28:10.392 # -sdown slave 192.168.24.131:6379 192.168.24.131 6379 @ macrog-master 192.168.24.131 6381
表示:已经将6379设置为6381的slave。
4.Sentinel原理介绍
在上面遇到的两个名词,主观down和客观down:
SDOWN:subjectively down,直接翻译的为”主观”失效,即:当前sentinel实例认为某个redis服务为”不可用”状态;
ODOWN:objectively down,直接翻译为”客观”失效,即:多个sentinel实例都认为master处于”SDOWN”状态,那么此时master将处于ODOWN,ODOWN可以简单理解为master已经被集群确定为”不可用”,将会开启failover。
SDOWN与ODOWN转换过程:
1、每个sentinel实例在启动后,都会和已知的slaves/master以及其他sentinels建立TCP连接,并周期性发送PING(默认为1秒),在交互中,如果redis-server无法在”down-after-milliseconds”时间内响应或者响应错误信息,都会被认为此redis-server处于SDOWN状态。
2、SDOWN的server为master,那么此时sentinel实例将会向其他sentinel间歇性(一秒)发送”is-master-down-by-addr ”指令并获取响应信息,如果足够多的sentinel实例检测到master处于SDOWN,那么此时当前sentinel实例标记master为ODOWN…其他sentinel实例做同样的交互操作。配置项”sentinel monitor ”,如果检测到master处于SDOWN状态的slave个数达到,那么此时此sentinel实例将会认为master处于ODOWN。
3、每个sentinel实例将会间歇性(10秒)向master和slaves发送”INFO”指令,如果master失效且没有新master选出时,每1秒发送一次”INFO”;”INFO”的主要目的就是获取并确认当前集群环境中slaves和master的存活情况。
4、经过上述过程后,所有的sentinel对master失效达成一致后,开始failover。
Sentinel与slaves“自动发现”机制:
在sentinel的配置文件中,都指定了port,此port就是sentinel实例侦听其他sentinel实例建立链接的端口。
在集群稳定后,最终会每个sentinel实例之间都会建立一个tcp链接,此链接中发送”PING”以及类似于”is-master-down-by-addr”指令集,可用来检测其他sentinel实例的有效性以及”ODOWN”和”failover”过程中信息的交互。
在sentinel之间建立连接之前,sentinel将会尽力和配置文件中指定的master建立连接。sentinel与master的连接中的通信主要是基于pub/sub来发布和接收信息,发布的信息内容包括当前sentinel实例的侦听端口。
Over....

