


鸟哥的linux私房菜——第七章学习(Linux 磁盘与文件系统管理)
1.1)、文件系统特征
我们称呼一个可被挂载的数据为一个文件系统而不是一个分区!
文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到 inode 中,至于实际数据则放置到 data block 区块中。 另外,还有一个超级区块 (superblock) 会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。
每个 inode 与 block 都有编号,至于这三个数据的意义可以简略说明如下:
- superblock:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的 block 号码;
- block:实际记录文件的内容,若文件太大时,会占用多个 block 。
索引式文件系统(indexed allocation)
我们将 inode 与 block 区块用图解来说明一下,如下图所示,文件系统先格式化出 inode 与 block 的区块,假设某一个文件的属性与权限数据是放置到 inode 4 号(下图较小方格内),而这个 inode 记录了文件数据的实际放置点为 2, 7, 13, 15 这四个 block 号码,此时我们的操作系统就能够据此来排列磁盘的读取顺序,可以一口气将四个 block 内容读出来! 那么数据的读取就如同下图中的箭头所指定的模样了。
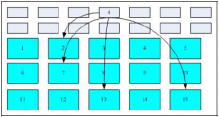
inode/block 数据存取示意图
U盘的FAT格式文件系统的文件读取方式如下,),FAT 这种格式的文件系统并没有 inode 存在,所以 FAT 没有办法将这个文件的所有 block 在一开始就读取出来。每个 block 号码都记录在前一个 block 当中, 他的读取方式有点像下面这样:
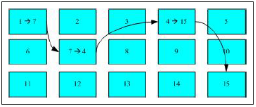
FAT文件系统数据存取示意图
两者之间就如同串联和并联的关系。
上图中我们假设文件的数据依序写入1->7->4->15号这四个 block 号码中, 但这个文件系统没有办法一口气就知道四个 block 的号码,他得要一个一个的将 block 读出后,才会知道下一个 block 在何处。 如果同一个文件数据写入的 block 分散的太过厉害时,则我们的磁头将无法在磁盘转一圈就读到所有的数据, 因此磁盘就会多转好几圈才能完整的读取到这个文件的内容!所以我们就需要“磁盘重组”了,磁盘重组的原因就是文件写入的 block 太过于离散了,此时文件读取的性能将会变的很差所致。这个时候可以通过磁盘重组将同一个文件所属的 blocks 汇整在一起,这样数据的读取会比较容易啊!
1.2)、Linux的EXT2文件系统(inode)
在复习一下:inode 的内容在记录文件的权限与相关属性,至于 block 区块则是在记录文件的实际内容。
而且文件系统一开始就将 inode 与 block 规划好了,除非重新格式化(或者利用 resize2fs 等指令变更文件系统大小),否则 inode 与 block 固定后就不再变动。
但是如果仔细考虑一下,如果我的文件系统高达数百GB时, 那么将所有的 inode 与 block 通通放置在一起将是很不智的决定,因为 inode 与block 的数量太庞大,不容易管理。
为此之故,因此 Ext2 文件系统在格式化的时候基本上是区分为多个区块群组 (block group) 的,每个区块群组都有独立的inode/block/superblock 系统。感觉上就好像我们在当兵时,一个营里面有分成数个连,每个连有自己的联络系统, 但最终都向营部回报连上最正确的信息一般!这样分成一群群的比较好管理啦!整个来说,Ext2 格式化后有点像下面这样:
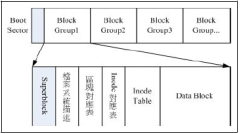
ext2文件系统示意图
- Data block(数据区块):
在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种,初始化太大则会造成空间浪费,太小会造成读写性能不良。合理使用block区块大小。
- inode table(inode表格):
inode 的内容在记录文件的属性以及该文件实际数据是放置在哪几号 block 内!系统读取文件时需要先找到 inode,并分析 inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容。
Inode的大小固定为128Bytes。记录一个 block 号码要花掉 4Byte。
为此我们的系统很聪明的将 inode 记录 block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。
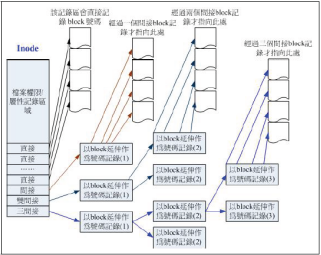
Inode示意图
- Superblock (超级区块)
这个文件系统的基本信息都写在这里
- Filesystem Description (文件系统描述说明)
- block bitmap (区块对照表)
- inode bitmap (inode 对照表)
- dumpe2fs: 查询 Ext 家族 superblock 信息的指令
1.3)、与目录树的关系
当我们在 Linux 下的 ext2 创建一个一般文件时, ext2 会分配一个 inode 与相对于该文件大小的block 数量给该文件。
当我们在 Linux 下的文件系统创建一个目录时,文件系统会分配一个 inode 与至少一块 block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码; 而 block 则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。
由于目录树是由根目录开始读起,因此系统通过挂载的信息可以找到挂载点的 inode 号码,此时就能够得到根目录的 inode 内容,并依据该 inode 读取根目录的 block 内的文件名数据,再一层一层的往下读到正确的文件名。举例来说,
- 【读取某文件时系统的步骤】
如果我想要读取 /etc/passwd 这个文件时,系统是如何读取的呢?
[root@study ~]# ll -di / /etc /etc/passwd 128 dr-xr-xr-x. 17 root root 4096 May 4 17:56 / 33595521 drwxr-xr-x. 131 root root 8192 Jun 17 00:20 /etc 36628004 -rw-r--r--. 1 root root 2092 Jun 17 00:20 /etc/passwd
步骤:
1. / 的 inode:
通过挂载点的信息找到 inode 号码为 128 的根目录 inode,且 inode 规范的权限让我们可以读取该 block 的内容(有 r 与 x) ;
2. / 的 block:
经过上个步骤取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码 (33595521);
3. etc/ 的 inode:
读取 33595521 号 inode 得知 dmtsai 具有 r 与 x 的权限,因此可以读取 etc/ 的 block 内容;
4. etc/ 的 block:
经过上个步骤取得 block 号码,并找到该内容有 passwd 文件的 inode 号码 (36628004);
5. passwd 的 inode:
读取 36628004 号 inode 得知 dmtsai 具有 r 的权限,因此可以读取 passwd 的 block 内容;
6. passwd 的 block:
最后将该 block 内容的数据读出来。
- 【新建某文件/目录时系统的步骤】
需要用到block bitmap和inode bitmap;
假设我们想要新增一个文件,此时文件系统的行为是:
1. 先确定使用者对于欲新增文件的目录是否具有 w 与 x 的权限,若有的话才能新增;
2. 根据 inode bitmap 找到没有使用的 inode 号码,并将新文件的权限/属性写入;
3. 根据 block bitmap 找到没有使用中的 block 号码,并将实际的数据写入 block 中,且更新 inode 的 block 指向数据;
4. 将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容。
一般滴,我们将 inode table 与 data block 称为数据存放区域,至于其他例如 superblock、 block bitmap 与 inode bitmap 等区段就被称为 metadata (中介数据) 啰,因为 superblock, inode bitmap 及 block bitmap 的数据是经常变动的,每次新增、移除、编辑时都可能会影
响到这三个部分的数据,因此才被称为中介数据的啦。
后来,由于数据的不一致(Inconsistent)状态引发了 日志式文件系统(Journaling filesystem)的兴起。
1. 预备:当系统要写入一个文件时,会先在日志记录区块中纪录某个文件准备要写入的信息;
2. 实际写入:开始写入文件的权限与数据;开始更新 metadata 的数据;
3. 结束:完成数据与 metadata 的更新后,在日志记录区块当中完成该文件的纪录。
在这样的程序当中,万一数据的纪录过程当中发生了问题,那么我们的系统只要去检查日志记录区块, 就可以知道哪个文件发生了问题,针对该问题来做一致性的检查即可,而不必针对整块 filesystem 去检查, 这样就可以达到快速修复 filesystem 的能力了!这就是日志式文件最基础的功能啰~
1.4)、Linux 文件系统的运行
我们知道所有的数据都得要载入到内存后 CPU 才能够对该数据进行处理,那么试想如果经常编辑一个大文件,在编辑过程中有需要频繁地要系统来写入磁盘中,由于磁盘写入的速度要比内存慢很多,因此常常会耗在等待磁盘的读写时间上,效率很低。
因此,Linux使用了一个异步处理方式(asynchronously):当系统载入一个文件到内存后,如果该文件没有被更改过,则在内存区段的文件数据会被设置为干净的(clean),但如果内存中的文件数据被更改过( 如使用nano、vim等编辑过)此时就会被设置为脏的(dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中,系统会不定时的将内存中设置为dirty的数据写回磁盘,以保持磁盘与内存数据的一致性。此外还可以利用sync指令来手动强制同步,将数据写入磁盘。
1.5)、挂载点(mount point)
每个filesystem都有独立的inode/block/superblock等信息,这个文件要能够链接到目录树才能够被我们使用。而将文件系统和目录树结合的动作我们称之为 “挂载”。
而且,挂载点一定是目录,该目录为进入该文件系统的入口。所以说并不是你有任何文件系统都能使用,必须要“挂载”到目录树的某个目录后,才能够使用该文件系统。
为了便于大家理解,在这里再次将目录树的架构图放在这里。
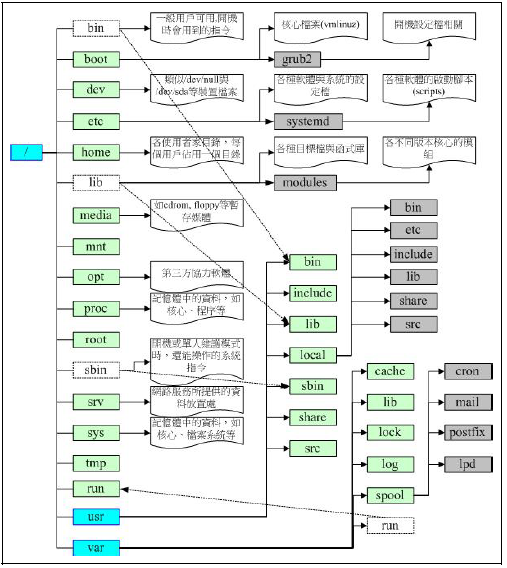
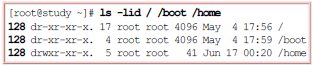
如果想要查看挂载点:需要输入:ls -lid 目录名 即可。如:
1.6)、文件系统由EXT4改为XFS
因此,从 CentOS 7.x 开始, 文件系统已经由默认的 Ext4 变成了xfs 这一个较适合大容量磁盘与巨型文件性能较佳的文件系统了。
xfs 文件系统在数据的分佈上,主要规划为三个部份,一个数据区 (data section)、一个文件系统活动登录区 (log section)以及一个实时运行区 (realtime section)。 这三个区域的数据内容如下:
- 数据区 (data section)
该区分为多个储存区群组 (allocation groups) 来分别放置文件系统所需要的数据,每个储存区群组都包含了 (1)整个文件系统的 superblock,(2)剩余空间的管理机制,(3)inode的分配与追踪。此外,inode与 block 都是系统需要用到时, 这才动态配置产生,所以格式化动作超级快。
- 文件系统活动登录区 (log section)
主要被用来纪录文件系统的变化,像是日志区。文件的变化会在这里记录下来,直到该变化 完整的写入到数据区后,该笔记录才会被终结。
- 实时运行区 (realtime section)
当有文件要被创建时,xfs 会在这个区段里面找一个到数个的 extent 区块,将文件放置在这个区块内,等到分配完毕后,再写入到data section 的 inode 与 block 去。
1.7)、XFS文件系统的描述数据观察
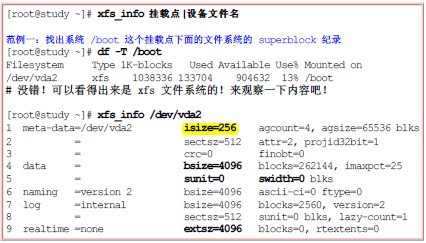
解释:
l 第一行isize指的是inode的容量,每个有256Bytes这么大,agcount指的是存储区群组(allocation group)的个数,有4个,agsize指的是每个存储区群组具有65536个block,结合第四行bsize=4096Bytes=4k,故整个系统文件的容量就是4*65536*4k的大小。
l 第二行的sectsz=512指的是逻辑扇区(sector)的容量大小;
l 第七行internal指的是该登录区的位置在文件系统内而不是外部设备的意思,且占用了4k*2560个block,共约10M的容量。
2.0)、磁盘与目录的容量
现在我们知道磁盘的整体数据是在 superblock 区块中,但是每个各别文件的容量则在 inode 当中记载的。文本界面下面该如何叫出这几个数据呢?有两个指令:
- df:列出文件系统的整体磁盘使用量;
- du:评估文件系统的磁盘使用量(常用在推估目录所占容量)
范例一:将容量结果以易读的容量格式显示出来
[root@study ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 10G 3.3G 6.8G 33% / devtmpfs 613M 0 613M 0% /dev tmpfs 623M 80K 623M 1% /dev/shm tmpfs 623M 25M 599M 4% /run tmpfs 623M 0 623M 0% /sys/fs/cgroup /dev/mapper/centos-home 5.0G 67M 5.0G 2% /home /dev/vda2 1014M 131M 884M 13% /boot
需要注意的是使用-a参数时,系统会出现/proc挂载点,但是里面的东西都是0,不要紧张哦,这是因为/proc里面的东西都是Linux系统所需要载入的系统数据,而且是挂载在“内存当中”的,所以当然没有没有占据任何的磁盘空间!
2.1)、实体链接与符号链接:ln
在linux下链接文件有两种:一种是类似Windows的捷径功能的文件,可以快速的链接到目标文件或目录;另一种是通过文件系统的inode链接来产生新的文件名(注意不是产生新文件),这种叫做实体链接(hard link)。
- hard link实体链接,硬式链接或实际链接
注意:文件名只与目录有关,但是文件内容则与inode有关。
当多个文件名对应到同一个 inode 号码时就是 hard link了,即hard link 只是在某个目录下新增一笔文件名链接到某 inode 号码的关连记录而已。
事实上 hard link 应该仅能在单一文件系统中进行的,故hard link也有一些限制:
-
- 不能跨 Filesystem;
- 不能 link 目录。
- Sysbolic link符号链接,即捷径
Symbolic link 就是在创建一个独立的文件,而这个文件会让数据的读取指向他 link 的那个文件的文件名!
举个例子:先创建一个符号链接文件链接到 /etc/crontab
[root@study ~]# ln -s /etc/crontab crontab2 [root@study ~]# ll -i /etc/crontab /root/crontab2 34474855 -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab 53745909 lrwxrwxrwx. 1 root root 12 Jun 23 22:31 /root/crontab2 -> /etc/crontab
解释:
由 1 号 inode 读取到链接文件的内容仅有文件名,根据文件名链接到正确的目录去取得目标文件的inode , 最终就能够读取到正确的数据了。你可以发现的是,如果目标文件(/etc/crontab)被删除了,那么整个环节就会无法继续进行下去, 所以就会发生无法通过链接文件读取的问题了!
这里还是得特别留意,这个 Symbolic Link 与 Windows 的捷径可以给他划上等号,由 Symbolic link 所创建的文件为一个独立的新的文件,所以会占用掉 inode 与 block 喔!
而对于hard link 来说,当某一个目录下的关联数据被杀掉后,也没有关系,可以通过其他目录下存在的关联数据来访问,所以该数据就不会不被见。即多重保障。
另:Symbolic link会占用掉inode和block,而hard link则不占用。
事例:
[root@study ~]# ln [-sf] 来源文件 目标文件
选项与参数:
-s :如果不加任何参数就进行链接,那就是hard link,至于 -s 就是symbolic link
-f :如果 目标文件 存在时,就主动的将目标文件直接移除后再创建!
范例一:将 /etc/passwd 复制到 /tmp 下面,并且观察 inode 与 block
[root@study ~]# cd /tmp [root@study tmp]# cp -a /etc/passwd . [root@study tmp]# du -sb ; df -i . 6602 . <==先注意一下这里的容量是多少! Filesystem Inodes IUsed IFree IUse% Mounted on /dev/mapper/centos-root 10485760 109748 10376012 2% / # 利用 du 与 df 来检查一下目前的参数~那个 du -sb 是计算整个 /tmp 下面有多少 Bytes 的容量啦! 范例二:将 /tmp/passwd 制作 hard link 成为 passwd-hd 文件,并观察文件与容量 [root@study tmp]# ln passwd passwd-hd [root@study tmp]# du -sb ; df -i . 6602 . Filesystem Inodes IUsed IFree IUse% Mounted on /dev/mapper/centos-root 10485760 109748 10376012 2% /
# 仔细看,即使多了一个文件在 /tmp 下面,整个 inode 与 block 的容量并没有改变!
[root@study tmp]# ls -il passwd* 2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd 2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd-hd # 原来是指向同一个 inode 啊!这是个重点啊!另外,那个第二栏的链接数也会增加!
范例三:将 /tmp/passwd 创建一个符号链接
[root@study tmp]# ln -s passwd passwd-so [root@study tmp]# ls -li passwd* 2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd 2668897 -rw-r--r--. 2 root root 2092 Jun 17 00:20 passwd-hd 2668898 lrwxrwxrwx. 1 root root 6 Jun 23 22:40 passwd-so -> passwd # passwd-so 指向的 inode number 不同了!这是一个新的文件~这个文件的内容是指向 # passwd 的。passwd-so 的大小是 6Bytes ,因为 “passwd” 这个单字共有六个字符之故 [root@study tmp]# du -sb ; df -i . 6608 . Filesystem Inodes IUsed IFree IUse% Mounted on /dev/mapper/centos-root 10485760 109749 10376011 2% / # 呼呼!整个容量与 inode 使用数都改变啰~确实如此啊!
范例四:删除原始文件 passwd ,其他两个文件是否能够打开?
[root@study tmp]# rm passwd [root@study tmp]# cat passwd-hd .....(正常显示完毕!) [root@study tmp]# cat passwd-so cat: passwd-so: No such file or directory [root@study tmp]# ll passwd* -rw-r--r--. 1 root root 2092 Jun 17 00:20 passwd-hd lrwxrwxrwx. 1 root root 6 Jun 23 22:40 passwd-so -> passwd # 怕了吧!符号链接果然无法打开!另外,如果符号链接的目标文件不存在, # 其实文件名的部分就会有特殊的颜色显示
2.2)、磁盘
如果我们想要在系统里面新增一颗磁盘时,应该做如下:
1. 对磁盘进行分区,以创建可用的 partition ;
2. 对该 partition 进行格式化 (format),以创建系统可用的 filesystem;
3. 若想要仔细一点,则可对刚刚创建好的 filesystem 进行检验;
4. 在 Linux 系统上,需要创建挂载点 (亦即是目录),并将他挂载上来;
- 观察磁盘分区状态lsblk,blkid,parted
lsblk :list block device,即列出系统上的所有磁盘列表。
blkid :列出设备的UUID等参数;
parted :列出磁盘的分区表类型和分区信息:parted /dev/vda print
- 磁盘分区gdisk,fdisk
特别注意:MBR 分区表请使用 fdisk 分区, GPT 分区表请使用 gdisk 分区!
- 磁盘格式化mkfs
创建文件系统 (make filesystem)
-
- XFS 文件系统 mkfs.xfs
- EXT4 文件系统 mkfs.ext4
2.3)、文件系统挂载与卸载
挂载前需要确定:
1、单一文件系统不应该被重复挂载在不同的挂载点(目录)中;
2、单一目录不应该重复挂载多个文件系统;
3、要作为挂载点的目录,理论上应该都是空目录才是。如果你要用来挂载的目录里面并不是空的,那么挂载了文件系统之后,原目录下的东西就会暂时的消失。
重新挂载根目录与挂载不特定目录
范例:将 / 重新挂载,并加入参数为 rw 与 auto
[root@study ~]# mount -o remount,rw,auto /
重点是那个“ -o remount,xx ”的选项与参数,尤其是当你进入单人维护模式时,你的根目录常会被系统挂载为只读,这个时候这个指令就太重要了!
本章节回顾:
l 一个可以被挂载的数据通常称为“文件系统, filesystem”而不是分区 (partition) 喔
l 基本上 Linux 的传统文件系统为 Ext2 ,该文件系统内的信息主要有:
- superblock:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的 block 号码;
- block:实际记录文件的内容,若文件太大时,会占用多个 block 。
l Ext2 文件系统的数据存取为索引式文件系统(indexed allocation)
l 需要磁盘重组的原因就是文件写入的 block 太过于离散了,此时文件读取的性能将会变的很差所致。 这个时候可以通过磁盘重组将同一个文件所属的 blocks 汇整在一起。
l Ext2文件系统主要有:boot sector, superblock, inode bitmap, block bitmap, inode table, data block 等六大部分。
l data block 是用来放置文件内容数据地方,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种而已;
l inode 记录文件的属性/权限等数据,其他重要项目为: 每个 inode 大小均为固定,有 128/256Bytes 两种基本容量。每个文件都仅会占用一个 inode 而已; 因此文件系统能够创建的文件数量与 inode 的数量有关;
l 文件的 block 在记录文件的实际数据,目录的 block 则在记录该目录下面文件名与其 inode 号码的对照表;
l 日志式文件系统 (journal) 会多出一块记录区,随时记载文件系统的主要活动,可加快系统复原时间;
l Linux 文件系统为增加性能,会让内存作为大量的磁盘高速缓存;
l 实体链接只是多了一个文件名对该 inode 号码的链接而已;
l 符号链接就类似Windows的捷径功能。
l 磁盘的使用必需要经过:分区、格式化与挂载,分别惯用的指令为:gdisk, mkfs, mount三个指令;
l 分区时,应使用 parted 检查分区表格式,再判断使用 fdisk/gdisk 来分区,或直接使用 parted 分区;
l 为了考虑性能,XFS 文件系统格式化时,可以考虑加上 agcount/su/sw/extsize 等参数较佳;
l 如果磁盘已无未分区的容量,可以考虑使用大型文件取代磁盘设备的处理方式,通过 dd 与格式化功能。
l 开机自动挂载可参考/etc/fstab之设置,设置完毕务必使用 mount -a 测试语法正确否。
Over...

