


有了二叉查找树、平衡树为啥还需要红黑树?
红黑树算是很难的一种数据结构吧,一般很少考察插入、删除等具体操作步骤,如果遇到要你手写红黑树的面试官,就直接告辞吧。
所以,更多是会考察你对红黑树的理解程度,考察的最多的估计就是为什么有了二查找查找树/平衡树还需要红黑树这个问题了。
1、二叉查找树的缺点
二叉查找树的特点就是左子树的节点值比父亲节点小,而右子树的节点值比父亲节点大。如图所示:
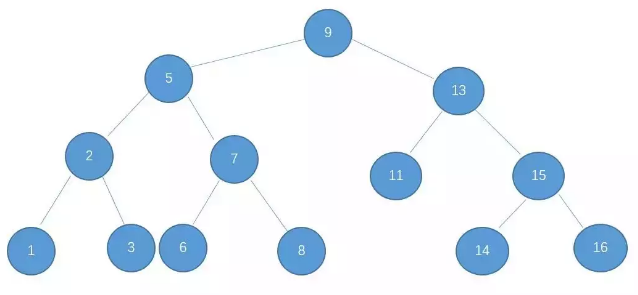
基于二叉查找树的这种特点,我们在查找某个节点的时候,可以采取类似于二分查找的思想,快速找到某个节点。
n 个节点的二叉查找树,正常的情况下,查找的时间复杂度为 O(logn)。
之所以说是正常情况下,是因为二叉查找树有可能出现一种极端的情况,例如:
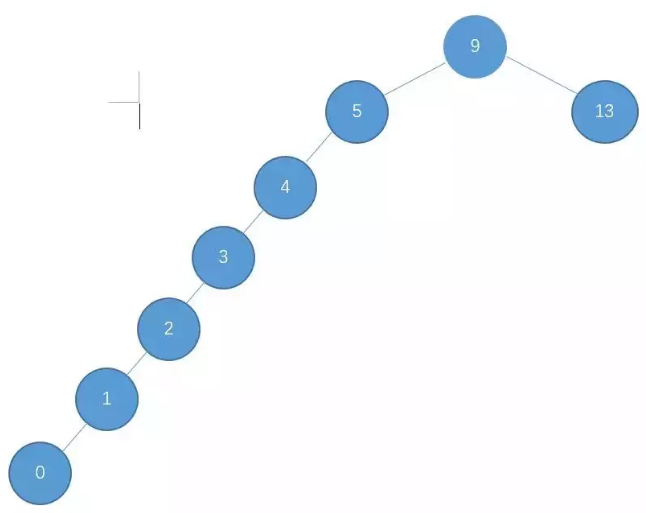
这种情况也是满足二叉查找树的条件,然而,此时的二叉查找树已经近似退化为一条链表,这样的二叉查找树的查找时间复杂度顿时变成了 O(n),可想而知,我们必须不能让这种情况发生,为了解决这个问题,于是我们引申出了平衡二叉树。
2、平衡二叉树
平衡二叉树就是为了解决二叉查找树退化成一颗链表而诞生了,平衡树具有如下特点:
1、具有二叉查找树的全部特性。
2、每个节点的左子树和右子树的高度差至多等于1。
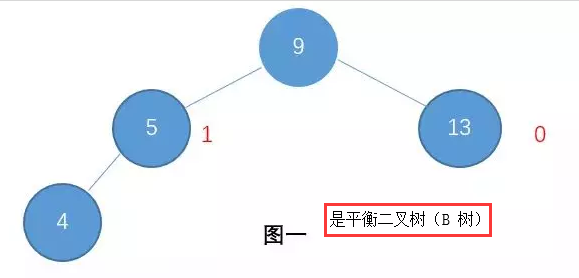
例如:图一就是一颗平衡树了,而图二则不是(节点右边标的是这个节点的高度)
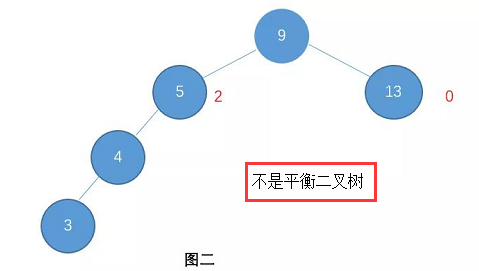
对于图二,因为节点9的左孩子高度为2,而右孩子高度为0。他们之间的差值超过1了。
平衡树基于这种特点就可以保证不会出现大量节点偏向于一边的情况了。关于平衡树如何构建、插入、删除、左旋、右旋等操作这里不在说明,具体可以看这篇文章:以后在有面试官问你AVL树,你就把这篇文章扔给他。
于是,通过平衡树,我们解决了二叉查找树的缺点。对于有 n 个节点的平衡树,最坏的查找时间复杂度也为 O(logn)。
3、为什么有了平衡树还需要红黑树?
虽然平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在 O(logn),不过却不是最佳的,因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树,红黑树具有如下特点:
1、具有二叉查找树的特点。
2、根节点是黑色的;
3、每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存数据。
4、任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的。
5、每个节点,从该节点到达其可达的叶子节点是所有路径,都包含相同数目的黑色节点。
例如下面的图片(注意,图片中黑色的、空的叶子节点没有画出)(图片来自极客时间)
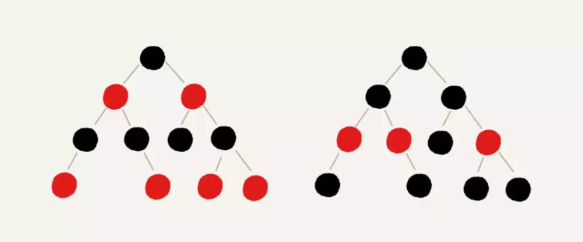
正是由于红黑树的这种特点,使得它能够在最坏情况下,也能在 O(logn) 的时间复杂度查找到某个节点。
至于为什么就能够保证时间复杂度为 O(logn),我这里就不细讲了,后面的文章可能会讲。
不过,与平衡树不同的是,红黑树在插入、删除等操作,不会像平衡树那样,频繁着破坏红黑树的规则,所以不需要频繁着调整,这也是我们为什么大多数情况下使用红黑树的原因。
不过,如果你要说,单单在查找方面的效率的话,平衡树比红黑树快。
所以,我们也可以说,红黑树是一种不大严格的平衡树。也可以说是一个折中发方案。
而关于红黑树的应用,一个非常经典的就是JDK1.8的HashMap中,当链表长度超过8时,就会由链表变成红黑树
小结:
平衡树是为了解决二叉查找树退化为链表的情况,而红黑树是为了解决平衡树在插入、删除等操作需要频繁调整的情况。
Over...
参考:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界