


左神算法第五节课:认识哈希函数和哈希表,设计RandomPool结构,布隆过滤器,一致性哈希,岛问题,并查集结构
认识哈希函数和哈希表
MD5Hash值的返回范围:0~9+a~f,是16位,故范围是0~16^16(2^64)-1,
【Hash函数】,又叫散列函数;
Hash的性质:
1) 输入域无穷大;
2) 输出域相对固定较小;
3) 输入一样,输出一样;
4) 输入不一样,输出可能一样,也可能不一样;
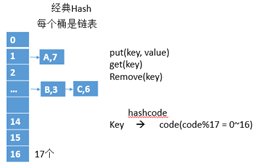
5) 均匀分布在输出域中,如经典表中对17取模,使得每个桶内的长度基本一样;散列函数,如同香水在房间;Hash函数和输入的顺序无关;
第4条即是Hash碰撞的原因:多个输入对应同一个输出;这是必然会产生的,因为输入域无穷,输出域确实有穷的。
【Hash表经典结构】
0~16是17个桶,当不够用的时候,就会扩容。
【JVM中的Hash表】

设计RandomPool结构
【题目】 设计一种结构,在该结构中有如下三个功能:
insert(key):将某个key加入到该结构,做到不重复加入。
delete(key):将原本在结构中的某个key移除。
getRandom():等概率随机返回结构中的任何一个key。
【要求】Insert、delete和getRandom方法的时间复杂度都是O(1);
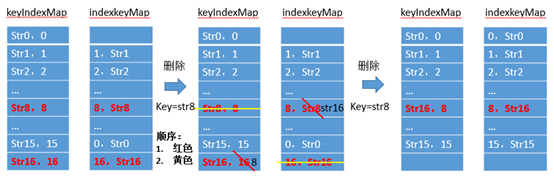
分析:由于复杂度要求,使得不能遍历;使用两张表,map1和map2,并使用一个计数变量size,将map1存入为(str, size),map2为(size, str);增加同基本,删除的话要注意删除时避免间断的出现,解决间断问题,
1 import java.util.HashMap; 2 3 public class Code_02_RandomPool { 4 public static class Pool<K> { 5 private HashMap<K, Integer> keyIndexMap; 6 private HashMap<Integer, K> indexKeyMap; 7 private int size; 8 9 public Pool() { 10 keyIndexMap = new HashMap<>(); 11 indexKeyMap = new HashMap<>(); 12 size = 0; 13 } 14 15 public void add(K k) { 16 keyIndexMap.put(k, size); 17 indexKeyMap.put(size, k); 18 size++; 19 } 20 public void insert(K k) { 21 if (!keyIndexMap.containsKey(k)) { 22 keyIndexMap.put(k, size); 23 indexKeyMap.put(size++, k); 24 } 25 } 26 public void delete(K key) { 27 //要保证删除之后,没有间断 28 if (keyIndexMap.containsKey(key)) { 29 int deleteIndex = keyIndexMap.get(key); 30 int lastIndex = --size; 31 K lastKey = indexKeyMap.get(lastIndex); 32 keyIndexMap.put(lastKey, deleteIndex); 33 indexKeyMap.put(deleteIndex, lastKey); 34 keyIndexMap.remove(key); 35 indexKeyMap.remove(lastKey); 36 } 37 } 38 39 public K getRandom() { 40 if (size == 0) { 41 return null; 42 } 43 int index = (int)(Math.random()*size); 44 return indexKeyMap.get(index); 45 } 46 47 } 48 private static void test() { 49 Pool<String> pool = new Pool<String>(); 50 pool.insert("zuo"); 51 pool.insert("cheng"); 52 pool.insert("yun"); 53 System.out.println(pool.size); 54 System.out.println(pool.getRandom()); 55 System.out.println(pool.getRandom()); 56 System.out.println(pool.getRandom()); 57 System.out.println(pool.getRandom()); 58 System.out.println(pool.getRandom()); 59 System.out.println(pool.getRandom()); 60 61 } 62 public static void main(String[] args) { 63 test(); 64 } 65 }
删去任一个元素时,需要拿最后一个元素来填充该位置。故需要取得最后一个元素的索引。
LastIndex = --size;
再存储最后一个元素的str值,
lastKey = indexKeyMap.get(lastindex);
认识布隆过滤器
布隆过滤器:
- 而布隆过滤器只需要哈希表1/8到1/4的大小就能解决同样的问题,它实际上是一个很长的二进制向量和一系列的随机映射函数。
- 如果一个优秀的函数能够做到不同的输入值所得到的返回值可以均匀的分布在输出域S中,将其返回值对m取余(%m),得到的返回值可以认为也会均匀的分布在0~m-1位置上。
1)isSameSet(A,B),A∈Set1,B∈Set2。查某个东西是否在一个集合中,存在一定的失误率(宁可错杀三千,不可放过一个)。并且使用很少的内存。由集群到单机。

如何做出0~m-1的bit空间,可以找一个int[],一个int是4字节,即32bit;一个整数表示32bit;

1 package class_05; 2 /* 3 * 怎么做出长度为0-m-1的bit类型数组,拿基础类型来拼; 4 */ 5 public class BitTest { 6 public static void main(String[] args) { 7 int[] arr = new int[1000];//1000*32=32000bit 8 int singleIntIsBit = 32; 9 int index = 30000; 10 int intIndex = index/singleIntIsBit; 11 int bitIndex = index%singleIntIsBit; 12 System.out.println(intIndex+" "+bitIndex); 13 //(1<<bitIndex)是将第intIndex桶内的第bitIndex位上的0变为1; 14 arr[intIndex] = arr[intIndex] | (1<<bitIndex); 15 } 16 }
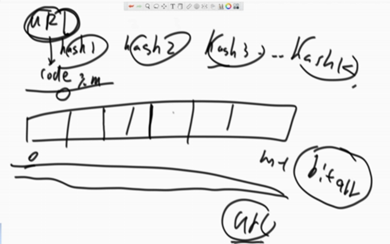
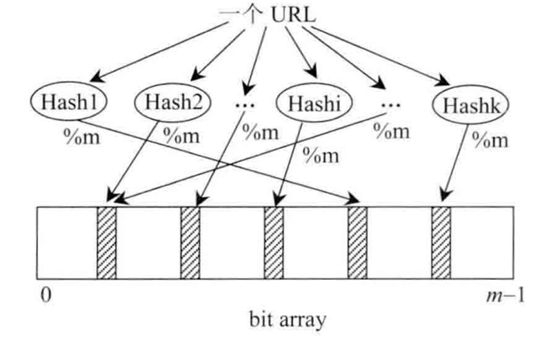
一个URL经过k个不同的hash函数,得到的哈希值再模上m,得到的位置上给涂黑。
给定一个URL如果经过k此比对都是黑的,那么说明是黑名单,如果有一个不是黑的,就说明不在黑名单之内。
M的长度与失误率有关,m越大,失误率越小。
布隆过滤器的大小m公式:
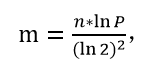
m是bit的长度,n是样本量,P预期失误率。
比如:n=100亿,P=0.0001(万分之一),m=131,571,428,572bit=131,571,428,572/8字节=22.3G,22.3G为实际空间。
Hash函数的个数K:
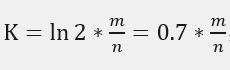
可得K= 0.7*m/n=13个,那么真实失误率p:
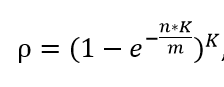
p=6/十万;
在比如:
假设我们的缓存系统,key为userId,value为user。如果我们有10亿个用户,规定失误率不能超过0.01%,通过计算器计算可得m=19.17n,向上取整为20n,也就是需要200亿个bit,换算之后所需内存大小就是2.3G。通过第二个公式可计算出所需哈希函数k=14.因为在计算m的时候用了向上取整,所以真是的误判率绝对小于等于0.01%。
关于BloomFilter,实际使用时不需要我们自己实现,谷歌已经帮我们实现好了,直接引入依赖就好。
- pom依赖:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>25.1-jre</version> </dependency>
- 核心API
1 /** 2 * Returns {@code true} if the element <i>might</i> have been put in this Bloom filter, 3 * {@code false} if this is <i>definitely</i> not the case. 4 */ 5 public boolean mightContain(T object) { 6 return strategy.mightContain(object, funnel, numHashFunctions, bits); 7 }
- 小例子
1 public static void main(String... args){ 2 /** 3 * 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器 4 */ 5 BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001); 6 bloomFilter.put("121"); 7 bloomFilter.put("122"); 8 bloomFilter.put("123"); 9 System.out.println(bloomFilter.mightContain("121")); 10 }
2)union(A,B),A∈Set1,B∈Set2,==》Set。较少元素的集合挂在较多元素的集合下面,
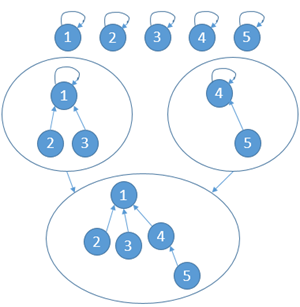
优化之处:在查某个节点的代表节点时,比如1-2-3-4-5,1-6,当查找4的代表节点时,需要把2,3,4都直接关联到1节点,如1-2,1-3,1-4-5,1-6,这样的话,以后再查6就快多了。
结论:假设有N个样本,查询次数+合并次数,整体逼近O(N)及以上,那么,单次操作(不管查询还是合并)平均时间复杂度都是O(1)。
认识一致性哈希
一致性哈希结构可以把数据迁移的代价变得很低,
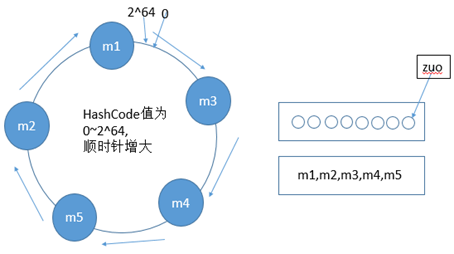
HashCode值为0~2^64;
5台机器,m1~m5;
五台机器的HashCode分别为mc1~mc5;
排序后形成数组mc=[mc3,mc4,mc5,mc2,mc1];
前端所有抗压的每个都有一个mc数组,然后,二分查找找出左边第一个比自己大的位置。
在图中就是求出zuo的hash值后,顺时针从m3开始查找,找到第一个比zuo的hash的、值大的机器,然后就将zuo放入该机器存储。
岛问题
一个矩阵中只有0和1两种值,每个位置都可以和自己的上、下、左、右四个位置相连,如果有一片1连在一起,这个部分叫做一个岛,求一个矩阵中有多少个岛?
举例:
0 0 1 0 1 0
1 1 1 0 1 0
1 0 0 1 0 0
0 0 0 0 0 0
这个矩阵中有三个岛。
思路:单机
1 public class Code_03_Islands { 2 3 public static int countIslands(int[][] m) { 4 if (m == null || m[0] == null) { 5 return 0; 6 } 7 int res = 0; 8 int N = m.length; 9 int M = m[0].length; 10 for (int i = 0; i < N; i++) { 11 for (int j = 0; j < M; j++) { 12 if (m[i][j] == 1) { 13 res++; 14 infect(m, i, j, N, M); 15 } 16 } 17 } 18 return res; 19 } 20 21 private static void infect(int[][] m, int i, int j, int N, int M) { 22 if (i < 0 || i >= N || j < 0 || j >= M || m[i][j] != 1) { 23 return; 24 } 25 m[i][j] = 2; 26 infect(m, i - 1, j, N, M);// 上 27 infect(m, i, j + 1, N, M);// 右 28 infect(m, i + 1, j, N, M);// 下 29 infect(m, i, j - 1, N, M);// 左 30 } 31 32 public static void main(String[] args) { 33 test(); 34 35 } 36 37 private static void test() { 38 int[][] m1 = { 39 { 0, 0, 0, 0, 0, 0, 0, 0, 0 }, 40 { 0, 1, 1, 1, 0, 1, 1, 1, 0 }, 41 { 0, 1, 1, 1, 0, 0, 0, 1, 0 }, 42 { 0, 1, 1, 0, 0, 0, 0, 0, 0 }, 43 { 0, 0, 0, 0, 0, 1, 1, 0, 0 }, 44 { 0, 0, 0, 0, 1, 1, 1, 0, 0 }, 45 { 0, 0, 0, 0, 0, 0, 0, 0, 1 }, }; 46 System.out.println(countIslands(m1)); 47 48 int[][] m2 = { 49 { 0, 0, 0, 0, 0, 0, 0, 0, 0 }, 50 { 0, 1, 1, 1, 1, 1, 1, 1, 0 }, 51 { 0, 1, 1, 1, 0, 0, 0, 1, 0 }, 52 { 0, 1, 1, 0, 0, 0, 1, 1, 0 }, 53 { 0, 0, 0, 0, 0, 1, 1, 0, 1 }, 54 { 0, 0, 0, 0, 1, 1, 1, 0, 0 }, 55 { 0, 0, 0, 0, 0, 0, 0, 0, 1 }, }; 56 System.out.println(countIslands(m2)); 57 58 } 59 60 }
分布式:
用到了union(A,B),边界问题。
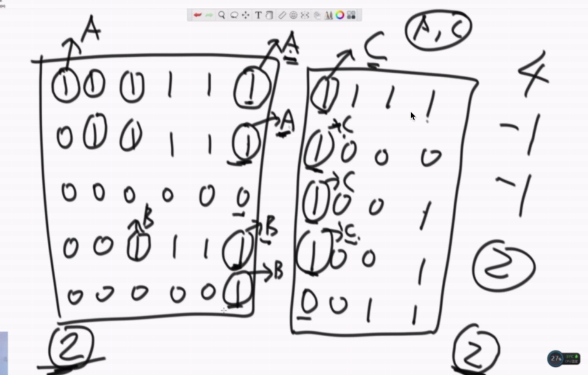
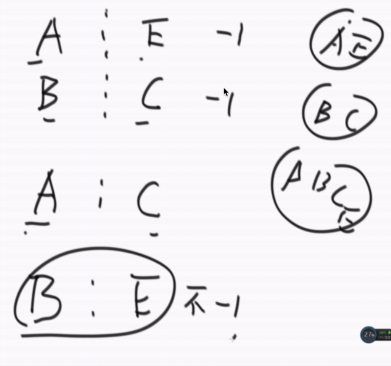
图1. 整体 图2. 边界
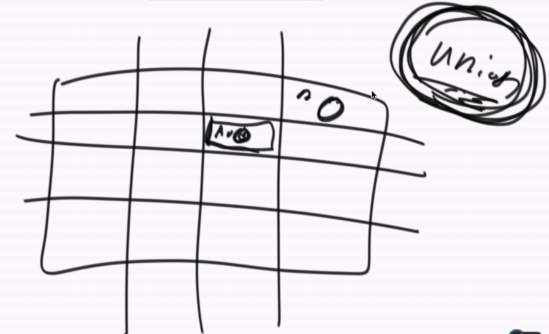
图3. 并行结构,多边界
并查集结构
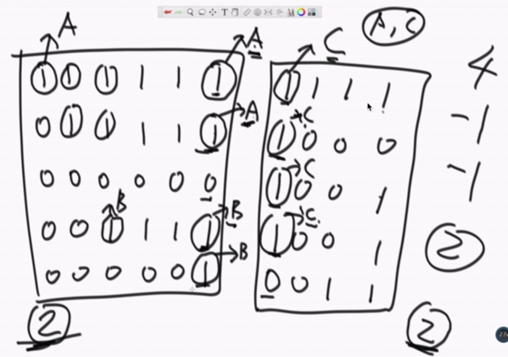
一个矩阵分到两个计算节点上,先遍历各个节点内的子矩阵,找出有多少个岛,以及各岛的头节点,可以发现一共有4个岛,各边界的头结点如箭头所示,当比较第一行的边界时,先判断A和C是否是在同一个集合,如果不是,那么岛的数量4-1=3,并且将AC合并,然后比较第二行发现AC已经同属一个集合,故岛的数量不变,继续比较,第三行左边为0,进行第四行比较,发现BC不是在同一个集合岛的数量3-1=2。以此进行比较,直至最后所有边界都比较完毕。
1 package class_05; 2 3 import java.util.HashMap; 4 import java.util.List; 5 import java.util.Stack; 6 7 public class Code_04_UnionFind { 8 9 public static class Node { 10 // whatever you like String,Int,char... 11 } 12 13 public static class UnionFindSet { 14 public HashMap<Node, Node> fatherMap;//key:child,value:father 15 public HashMap<Node, Integer> sizeMap;//该点所在集合一共有多少节点,谁多并入谁; 16 17 public UnionFindSet(List<Node> nodes) { 18 makeSet(nodes); 19 } 20 21 private void makeSet(List<Node> nodes) { 22 fatherMap = new HashMap<>(); 23 sizeMap = new HashMap<>(); 24 for (Node node : nodes) { 25 fatherMap.put(node, node);//第一次,每一个node自己形成一个集合,故父节点是其本身; 26 sizeMap.put(node, 1);//第一次,各自集合中只有自己一个元素; 27 } 28 } 29 /* 30 * 找到head,并且将node到head路径上的nodes的父节点都指向head; 31 * 递归寻找至根节点,并返回根节点 32 */ 33 public Node findHead(Node node) { 34 Node father = fatherMap.get(node); 35 if (father != node) { 36 father = findHead(father); 37 } 38 fatherMap.put(node, father); 39 return father; 40 } 41 //非递归,并返回根节点 42 public Node findHead2(Node node) { 43 Stack<Node> stack = new Stack<>(); 44 Node father = fatherMap.get(node); 45 while (father != node) { 46 stack.push(node); 47 node = father; 48 father = fatherMap.get(node); 49 } 50 //将路径上每个节点都指向根节点 51 while (!stack.isEmpty()) { 52 fatherMap.put(stack.pop(),father); 53 } 54 return father; 55 } 56 57 /*两个功能: 58 * 1.isSameSet(Node a,Node b); 59 * 2.union(Node a, Node b); 60 */ 61 public boolean isSameSet(Node a, Node b) { 62 return findHead(a) == findHead(b); 63 } 64 65 public void union(Node a, Node b) { 66 if (a == null || b == null) { 67 return; 68 } 69 Node aHead = findHead(a); 70 Node bHead = findHead(b); 71 if (aHead != bHead) { 72 int aSetSize = sizeMap.get(aHead);//通过根节点来求出size,其他节点的信息是错的; 73 int bSetSize = sizeMap.get(bHead); 74 if (aSetSize > bSetSize) { 75 //将b集合合并入a集合内; 76 fatherMap.put(bHead, aHead); 77 sizeMap.put(aHead, aSetSize+bSetSize);//只用改根节点的大小即可,与上方利用根节点求size呼应; 78 }else { 79 //将a集合合并入b集合内; 80 fatherMap.put(aHead, bHead); 81 sizeMap.put(bHead, aSetSize+bSetSize); 82 } 83 } 84 } 85 } 86 87 public static void main(String[] args) { 88 // TODO Auto-generated method stub 89 90 } 91 92 }

