
数据结构
一. 链表
1.1 单链表
# 链表节点
class Node:
def __init__(self, dataVal=None):
self.dataVal = dataVal
self.next = None
# 开始节点
class SLinkedList:
def __init__(self):
self.next = None
# 打印链表
def printLink(self):
pNode = self.next
while pNode is not None:
print(pNode.dataVal)
pNode = pNode.next
# 添加节点(尾部添加)
def addNodeEnd(self, newData):
newNode = Node(newData)
pNode = self.next
while pNode is not None:
if pNode.next is None:
pNode.next = newNode
break
pNode = pNode.next
else:
self.next = newNode
# 添加节点(头部添加)
def addNodeBefore(self, newData):
newNode = Node(newData)
pNode = self.next
if pNode is not None:
self.next = newNode
newNode.next = pNode
else:
self.next = newNode
# 添加节点(顺序添加)
def addNodeOrder(self, newData):
newNode = Node(newData)
pNode = self
if self.next is None:
self.addNodeEnd(newData)
return None
while pNode.next is not None:
pNode = pNode.next
if newData >= pNode.dataVal and pNode.next is None:
pNode.next = newNode
break
elif pNode.dataVal <= newData <= pNode.next.dataVal:
newNode.next = pNode.next
pNode.next = newNode
break
elif newData < self.next.dataVal:
newNode.next = self.next
self.next = newNode
break
# 修改节点
def updateNode(self, oldVal, newVal):
pNode = self.next
while pNode is not None:
if pNode.dataVal == oldVal:
pNode.dataVal = newVal
break
pNode = pNode.next
# 删除节点
def delNode(self, data):
pNode = self
while pNode.next is not None:
if pNode.next.dataVal == data:
pNode.next = pNode.next.next
break
pNode = pNode.next
# 获取有效节点长度
def getLen(self):
pNode = self.next
count = 0
while pNode is not None:
count += 1
pNode = pNode.next
return count
temp = SLinkedList()
e1 = Node("Mon")
e2 = Node("Tue")
e3 = Node("Wed")
temp.next = e1
e1.next = e2
e2.next = e3
temp.addNode("Sun")
temp.delNode('Sun')
temp.updateNode('Wed', 'jfbvjdjfv')
temp.printLink()
1.2 环形链表
环形链表之约瑟夫问题
class Node:
def __init__(self, val, pNext=None):
self.val = val
self.next = pNext
class SLinkedList:
def __init__(self, val):
self.val = val
self.next = self
# 添加节点
def addNodeEnd(self, newData):
newNode = Node(newData)
if self.next is self:
self.next = newNode
newNode.next = self
else:
newNode.next = self.next
self.next = newNode
# 开始节点
def start(self, data):
"""
:param data: int
:return: ListNode
"""
pNode = self.next
while True:
if pNode.next.val == data:
flagNode = pNode
break
pNode = pNode.next
return flagNode
# 进行出局
@staticmethod
def outNode(startNode, interval=5):
"""
:param startNode: ListNode 开始节点
:param interval: int 间隔
"""
# 要删除的节点
delNode = startNode
# 记录出局的前一个节点
delBeforeNode = None
# 记录每隔几个出局一次, 默认间隔5个
index = 0
while True:
# 切换下一个节点
delNode = delNode.next
index += 1
if delNode.next == delNode:
print(delNode.val)
break
# 记录出局的前一个结点
if index == (interval - 1):
delBeforeNode = delNode
# 进行指定节点是时进行出局
if index == interval:
print(delNode.val)
delBeforeNode.next = delNode.next
index = 0
head = SLinkedList(0)
head.addNodeEnd(9)
head.addNodeEnd(8)
head.addNodeEnd(7)
head.addNodeEnd(6)
head.addNodeEnd(5)
head.addNodeEnd(4)
head.addNodeEnd(3)
head.addNodeEnd(2)
head.addNodeEnd(1)
head.outNode(head.start(5), 5)
1.3 双向链表
二. 栈
2.1 基本构造
class Stack:
def __init__(self, maxSize):
self.container = []
self.maxSize = maxSize
self.pTop = -1
# 添加元素
def add(self, data):
if self.pTop == self.maxSize - 1:
print("栈已满!!!")
else:
self.pTop += 1
self.container.append(data)
# 取出元素
def get(self):
if self.pTop == -1:
print("栈已空!!!")
else:
self.container.pop()
self.pTop -= 1
# 打印栈
def printStack(self):
index = 0
if self.pTop == -1:
return None
while True:
print(self.container[index])
if index == self.pTop:
break
index += 1
print(self.container)
stack = Stack(5)
stack.add(1)
stack.add(2)
stack.add(3)
stack.add(4)
stack.add(5)
stack.add(6)
stack.get()
stack.get()
stack.get()
stack.printStack()
2.2 基本使用
2.2.1 栈实现综合计算器
class Stack:
def __init__(self, maxSize):
self.container = []
self.maxSize = maxSize
self.pTop = -1
# 添加元素
def add(self, data):
if self.pTop == self.maxSize - 1:
print("栈已满!!!")
else:
self.pTop += 1
self.container.append(data)
# 取出元素
def get(self):
num = 0
if self.pTop == -1:
print("栈已空!!!")
else:
num = self.container.pop()
self.pTop -= 1
return num
# 打印栈
def printStack(self):
index = 0
if self.pTop == -1:
return None
while True:
print(self.container[index])
if index == self.pTop:
break
index += 1
print(self.container)
stackNum = Stack(20) # 数字栈
stackOpera = Stack(20) # 符号栈
class MyCounter:
def __init__(self, s):
self.s = s
def counter(self): # 计算器
fullNum = ''
for i, item in enumerate(self.s):
if 48 <= ord(item) <= 57: # 判断是否是 number 类型
if i == len(self.s) - 1: # 判断是否是最后一个元素
fullNum += item
stackNum.add(int(fullNum))
elif not 48 <= ord(self.s[i + 1]) <= 57: # 判断下一个元素是否是 number
fullNum += item
stackNum.add(int(fullNum))
fullNum = ''
else:
fullNum += item
else:
if stackOpera.pTop == -1: # 为空的时候,向里添加
stackOpera.add(item)
else:
maxOrMin = self.compare(item, stackOpera.container[stackOpera.pTop])
if maxOrMin: # 判断当前符号是否比栈顶的优先级高
stackOpera.add(item)
else:
self.computer()
# 将优先级小的加入栈中
stackOpera.add(item)
while stackOpera.pTop != -1:
self.computer()
else:
return stackNum.get()
@staticmethod
def computer(): # 对栈中的数据进行计算
# 获取数字栈中的两个数据
num_1 = stackNum.get()
num_2 = stackNum.get()
# 获取符号栈中的字符
opera_1 = stackOpera.get()
# 让数据进行运算
if ord(opera_1) == 43:
sum1 = num_1 + num_2
elif ord(opera_1) == 45:
sum1 = num_2 - num_1
elif ord(opera_1) == 47:
sum1 = num_2 / num_1
else:
sum1 = num_2 * num_1
# 将运算后的数据重新添加到栈中
stackNum.add(sum1)
@staticmethod
def compare(oper1, oper2): # 判断运算符优先级
if (oper1 == '*' or oper1 == '/') and (oper2 == '+' or oper2 == '-'):
return True
else:
return False
o1 = MyCounter('7+20*6-40')
# o1 = MyCounter('7*2*2-5+1-5+3-4')
print(o1.counter())
2.2.2 前序表达式
a) 基本概念
前序表达式计算机 - 波兰表达式
从右至左 扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算(栈顶元素和次顶元素),并将结果入栈;重复上述过程直到表达式最左端,最后运算得出的值即为表达式的结果。
例如: (3+4)×5-6对应的前缀表达式就是- × + 3 4 5 6,针对前缀表达式求值步骤如下:
1) 从右至左扫描,将6、5、4、3压入堆栈。
2) 遇到+运算符,因此弹出3和4 (3为栈顶元素,4为次顶元素),计算出3+4的值,得7,再将7入栈。
3) 接下来是×运算符,因此弹出7和5,计算出7×5=35,将35入栈。
4) 最后是-运算符,计算出35-6的值,即29,由此得出最终结果。
b) 代码实现
...
2.2.3 后序表达式
a) 基本概念
后序表达式计算机 - 逆波兰表达式
中序表达式为人理解的表达式, 计算机实现复杂, 因此一般转为后续表达式。
从左至右 扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算(次顶元素和栈顶元素〉,并将结果入栈;重复上述过程直到表达式最右端,最后运算得出的值即为表达式的结果。
例如:(3+4)×5-6对应的前缀表达式就是3 4 + 5 × 6 -,针对后缀表达式求值步骤如下:
1) 从左至右扫描,将3和4压入堆栈。
2) 遇到+运算符,因此弹出4和3(4为栈顶元素,3为次顶元素),计算出3+4的值,得7,再将7入栈。
3) 将5入栈。
4) 接下来是×运算符,因此弹出5和7,计算出7×5=35,将35入栈。
5) 将6入栈。
6) 最后是-运算符,计算出35-6的值,即29,由此得出最终结果。
b) 代码实现
class Postorder: # 后续表达式
def __init__(self, arr1, stack1):
"""
:param List: 后序表达式
:param stack: 栈
"""
self.arr1 = arr1
self.stack1 = stack1
def compute(self):
"""
:return: int 表达式的最终结果
"""
for i, item in enumerate(self.arr1):
if item.isdigit():
self.stack1.add(int(item))
else:
result = 0
num1 = self.stack1.get()
num2 = self.stack1.get()
if item == '+':
result = num2 + num1
elif item == '-':
result = num2 - num1
elif item == '*':
result = num2 * num1
elif item == '/':
result = num2 / num1
self.stack1.add(result)
return self.stack1.get()
p1 = Postorder(arr, Stack(20))
print(p1.compute())
2.2.4 中序转后序表达式
a) 基本概念
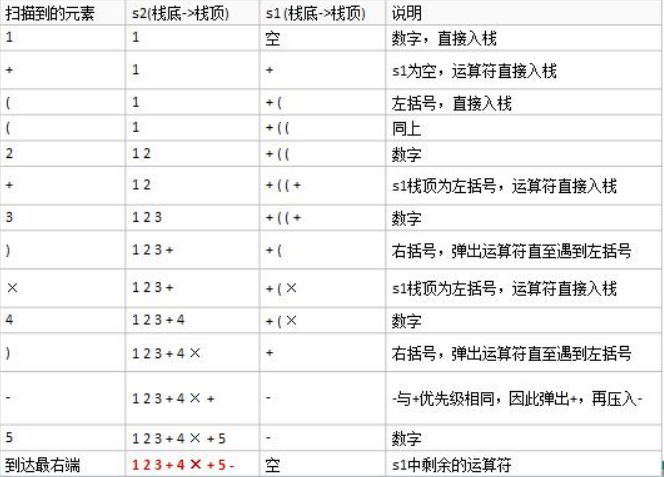
1. 初始化两个栈:运算符栈s1和储存中间结果的栈s2;
2. 从左至右扫描中缀表达式;
3. 遇到数字(number)时,将其压s2;
4. 遇到运算符时,比较其与s1栈顶运算符的优先级:
(1)如果s1为空,或栈顶运算符为左括号“(”,则直接将此运算符入栈;
(2)如果优先级比栈顶运算符的高,也将运算符压入s1;
(3)否则,将s1栈顶的运算符弹出并压入到s2中,再次转到(4-1)与s1中新的栈顶运算符相比较
5. 遇到括号时:
(1) 如果是左括号“(”,则直接压入s1
(2) 如果是右括号“)”,则依次弹出s1栈顶的运算符,并压入s2,直到遇到左括号为止,此时将这一对括号丢弃
6. 重复步骤2至5,直到表达式的最右边
7. 将s1中剩余的运算符依次弹出并压入s2
8. 依次弹出s2中的元素并输出,结果的逆序即为中缀表达式对应的后缀表达式
b) eg: 1+(3+4)×5-6
b) 代码实现
class Stack:
def __init__(self, maxSize):
self.container = []
self.maxSize = maxSize
self.pTop = -1
# 添加元素
def add(self, data):
if self.pTop == self.maxSize - 1:
print("栈已满!!!")
else:
self.pTop += 1
self.container.append(data)
# 取出元素
def get(self):
num = 0
if self.pTop == -1:
print("栈已空!!!")
else:
num = self.container.pop()
self.pTop -= 1
return num
# 打印栈
def printStack(self):
index = 0
if self.pTop == -1:
return None
while True:
print(self.container[index])
if index == self.pTop:
break
index += 1
print(self.container)
class InorderToPostorder: # 中序转后序
def __init__(self, stack1, stack2):
self.stack1 = stack1
self.stack2 = stack2
def convertTo(self, s1):
"""
:param s1: str 要运算的字符串
:return: stack 最终结果的栈
"""
fullNum = ''
for i, item in enumerate(s1):
if item.isdigit(): # 判断是否是数字
# stack2.add(int(item))
if i == len(s1) - 1: # 判断是否是最后一个元素
fullNum += item
self.stack2.add(fullNum)
elif not (s1[i + 1]).isdigit(): # 判断下一个元素是否是 number
fullNum += item
self.stack2.add(fullNum)
fullNum = ''
else:
fullNum += item
elif item == '(' or item == ')': # 判断是否是()
if item == '(':
self.stack1.add(item)
else:
while True:
if self.stack1.container[self.stack1.pTop] == '(':
self.stack1.get()
break
else:
stack1Pop = self.stack1.get()
self.stack2.add(stack1Pop)
else: # 判断是否是运算符
while True:
if self.stack1.pTop == -1 or self.stack1.container[self.stack1.pTop] == '(':
self.stack1.add(item)
break
elif self.precedenceOfOperator(item, self.stack1.container[self.stack1.pTop]):
self.stack1.add(item)
break
else:
self.stack2.add(self.stack1.get())
while True: # 将最后 stack1 中剩余的字符压入到 stack2 中
if self.stack1.pTop == -1:
break
else:
self.stack2.add(self.stack1.get())
return self.stack2
@staticmethod
def precedenceOfOperator(oper1, oper2):
""" 判断两运算符的优先级
:param oper1: 运算符1
:param oper2: 运算符2
:return: bool
如果 oper1 比 oper2 优先级大则返回 True, 否则还回 False
"""
if (oper1 == '*' or oper1 == '/') and (oper2 == '+' or oper2 == '-'):
return True
else:
return False
obj1 = InorderToPostorder(Stack(20), Stack(20))
print(obj1.convertTo('1+((2+32)*4)-50')) # 得到的是一个栈
2.2.5 逆波兰计算器
class Stack:
def __init__(self, maxSize):
self.container = []
self.maxSize = maxSize
self.pTop = -1
# 添加元素
def add(self, data):
if self.pTop == self.maxSize - 1:
print("栈已满!!!")
else:
self.pTop += 1
self.container.append(data)
# 取出元素
def get(self):
num = 0
if self.pTop == -1:
print("栈已空!!!")
else:
num = self.container.pop()
self.pTop -= 1
return num
# 打印栈
def printStack(self):
index = 0
if self.pTop == -1:
return None
while True:
print(self.container[index])
if index == self.pTop:
break
index += 1
print(self.container)
class InorderToPostorder: # 中序转后序
def __init__(self, stack1, stack2):
self.stack1 = stack1
self.stack2 = stack2
def convertTo(self, s1):
"""
:param s1: str 要运算的字符串
:return: stack 最终结果的栈
"""
fullNum = ''
for i, item in enumerate(s1):
if item.isdigit(): # 判断是否是数字
# stack2.add(int(item))
if i == len(s1) - 1: # 判断是否是最后一个元素
fullNum += item
self.stack2.add(fullNum)
elif not (s1[i + 1]).isdigit(): # 判断下一个元素是否是 number
fullNum += item
self.stack2.add(fullNum)
fullNum = ''
else:
fullNum += item
elif item == '(' or item == ')': # 判断是否是()
if item == '(':
self.stack1.add(item)
else:
while True:
if self.stack1.container[self.stack1.pTop] == '(':
self.stack1.get()
break
else:
stack1Pop = self.stack1.get()
self.stack2.add(stack1Pop)
else: # 判断是否是运算符
while True:
if self.stack1.pTop == -1 or self.stack1.container[self.stack1.pTop] == '(':
self.stack1.add(item)
break
elif self.precedenceOfOperator(item, self.stack1.container[self.stack1.pTop]):
self.stack1.add(item)
break
else:
self.stack2.add(self.stack1.get())
while True: # 将最后 stack1 中剩余的字符压入到 stack2 中
if self.stack1.pTop == -1:
break
else:
self.stack2.add(self.stack1.get())
return self.stack2
@staticmethod
def precedenceOfOperator(oper1, oper2):
""" 判断两运算符的优先级
:param oper1: 运算符1
:param oper2: 运算符2
:return: bool
如果 oper1 比 oper2 优先级大则返回 True, 否则还回 False
"""
if (oper1 == '*' or oper1 == '/') and (oper2 == '+' or oper2 == '-'):
return True
else:
return False
class Postorder: # 后续表达式
def __init__(self, length=20):
"""
:param int length: 栈长
"""
# self.arr1 = arr1
self.arr1 = None
self.stack1 = Stack(length)
self.length = length
def compute(self, list1):
"""
:param list1: 中序表达式
:return: 结果
"""
# 中序转后序
obj1 = InorderToPostorder(Stack(self.length), Stack(self.length))
arr1 = obj1.convertTo(list1).container
# 将list存到该对象中
self.arr1 = arr1
for i, item in enumerate(self.arr1):
if item.isdigit():
self.stack1.add(int(item))
else:
result = 0
num1 = self.stack1.get()
num2 = self.stack1.get()
if item == '+':
result = num2 + num1
elif item == '-':
result = num2 - num1
elif item == '*':
result = num2 * num1
elif item == '/':
result = num2 / num1
self.stack1.add(result)
return self.stack1.get()
p1 = Postorder()
print(p1.compute('1+((2+3)*4)-5')) # 16
三. 递归
3.1 基本案例 - 迷宫
3.1.1 基本概述
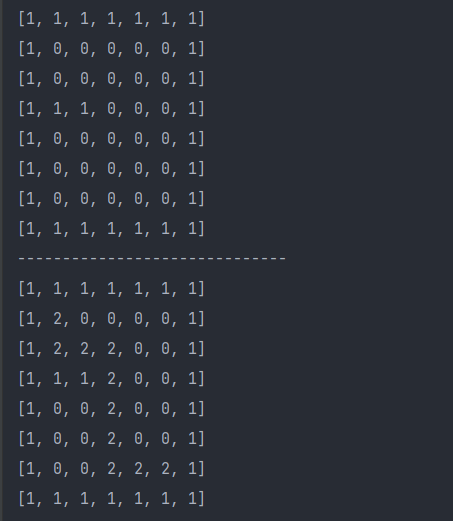
数字 0 为可走路径, 数字 1 为墙, 数字 2 为已走的路径
从[1][1]开始, 到[6][5]结束
3.1.2 代码实现
import copy
class MazeGame:
def __init__(self, row=7, col=8):
self.maze = self.makeMaze(row, col)
@staticmethod
# 设计迷宫
def makeMaze(row, col):
list_1 = []
list_2 = []
for y in range(col):
flag = copy.deepcopy(list_1)
list_2.append(flag)
for m in range(col):
for n in range(row):
if m == 0 or m == col - 1:
list_2[m].append(1)
elif n == 0 or n == row - 1:
list_2[m].append(1)
else:
list_2[m].append(0)
list_2[3][1] = 1
list_2[3][2] = 1
return list_2
# 走迷宫
def playMaze(self, x, y):
if self.maze[6][5] == 2:
return True
else:
if self.maze[x][y] == 0:
self.maze[x][y] = 2
if self.playMaze(x + 1, y):
return True
elif self.playMaze(x, y + 1):
return True
elif self.playMaze(x - 1, y):
return True
elif self.playMaze(x, y - 1):
return True
else:
self.maze[x][y] = 3
return False
else:
return False
maze1 = MazeGame(7, 8)
for i in maze1.maze:
print(i, end='\n')
print('------------------------------')
maze1.playMaze(1, 1)
for i in maze1.maze:
print(i, end='\n')
3.2 基本案例 - 8皇后小游戏
3.2.1 基本概述
3.2.2 代码实现
import math
class Queen: # 8皇后小游戏
def __init__(self, maxVal=8):
self.maxVal = maxVal
self.house = [0, 0, 0, 0, 0, 0, 0, 0]
self.count = 0
def playGame(self, m):
if m == self.maxVal: # 当放满时,结束程序
self.printf()
return
for i in range(self.maxVal):
self.house[m] = i # m是第几个皇后, i是第几列
if self.isTrue(m): # 如果满足条件则放置下一个皇后, 否则i++ 放到下一列
self.playGame(m + 1)
def isTrue(self, n):
for i in range(n):
"""
1. self.house[i] == self.house[n] 判断当前皇后的位置是否与之前的皇后的位置在列上有冲突
2. math.fabs(n - i) == math.fabs(self.house[n] - self.house[i]
判断当前皇后的位置是否与之前的皇后的位置在对角线上有冲突
"""
if self.house[i] == self.house[n] or math.fabs(n - i) == math.fabs(self.house[n] - self.house[i]):
return False
return True
def printf(self):
self.count += 1
for i in range(self.maxVal):
print(self.house[i], end=' ')
print('\n')
l1 = Queen()
l1.playGame(0)
print(l1.count) # 92
四. 算法复杂度
4.1 时间复杂度
4.1.1 复杂度对比
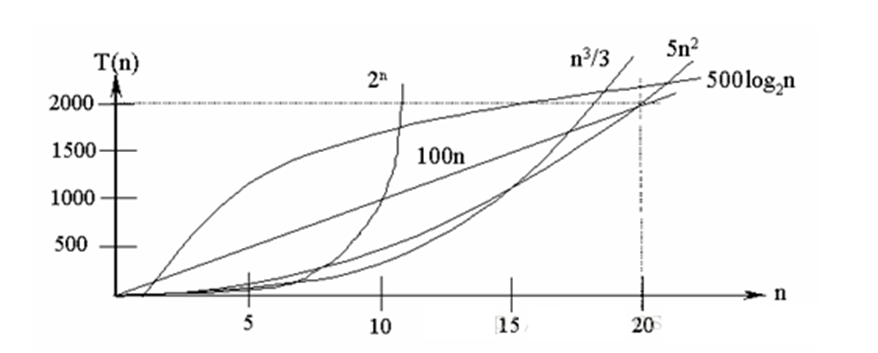
常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2^n)<Ο(n)<Ο(nlog2^n)<Ο(n^2)<Ο(n^3)< Ο(n^k) <Ο(2^n) ,随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低
- 常数阶 O(1)
- 对数阶 O(log2^n)
- 线性阶 O(n)
- 线性对数阶 O(nlog2^n)
- 平方阶 O(n^2)
- 立方阶 O(n^3)
- k次方阶 O(n^k)
- 指数阶 O(2^n)
4.1.2 举例说明
(1)常数阶 O(1)
下面代码在执行的时候,它消耗的时候并不随着某个变量的增长而增长,那么无论这类代码有多长,即使有几万几十万行,都可以用O(1)来表示它的时间复杂度。
i = 1
j = 2
i += 1
j += 1
m = i + j
(2)对数阶 O(log2^n)
在while循环里面,每次都将 i 乘以 2,乘完之后,i 距离 n 就越来越近了。假设循环x次之后,i 就大于 2 了,此时这个循环就退出了,也就是说 2 的 x 次方等于 n,那么 x = log2n也就是说当循环 log2^n 次以后,这个代码就结束了。因此这个代码的时间复杂度为:O(log2^n) 。 O(log2^n) 的这个2 时间上是根据代码变化的,i = i * 3 ,则是 O(log3^n)
i = 1
while i < n:
i *= 2
(3)线性阶 O(n)
下面这段代码,for循环里面的代码会执行n遍,因此它消耗的时间是随着n的变化而变化的,因此这类代码都可以用O(n)来表示它的时间复杂度
for i in range(n):
pass
(4)线性对数阶 O(nlog2^n)
下面这段代码,将时间复杂度为O(logn)的代码循环N遍的话,那么它的时间复杂度就是 n * O(logN),也就是了O(nlogN)
for i in range(n):
m = 1
while i < n:
m *= 2
(5)平方阶 O(n^2)
下面这段代码,把 O(n) 的代码再嵌套循环一遍,它的时间复杂度就是 O(n²),这段代码其实就是嵌套了2层n循环,它的时间复杂度就是 O(n*n),即 O(n²) 如果将其中一层循环的n改成m,那它的时间复杂度就变成了 O(m*n)
for i in range(n):
for j in range(n):
pass
五. 排序算法
(一)算法对比
(二)解释说明
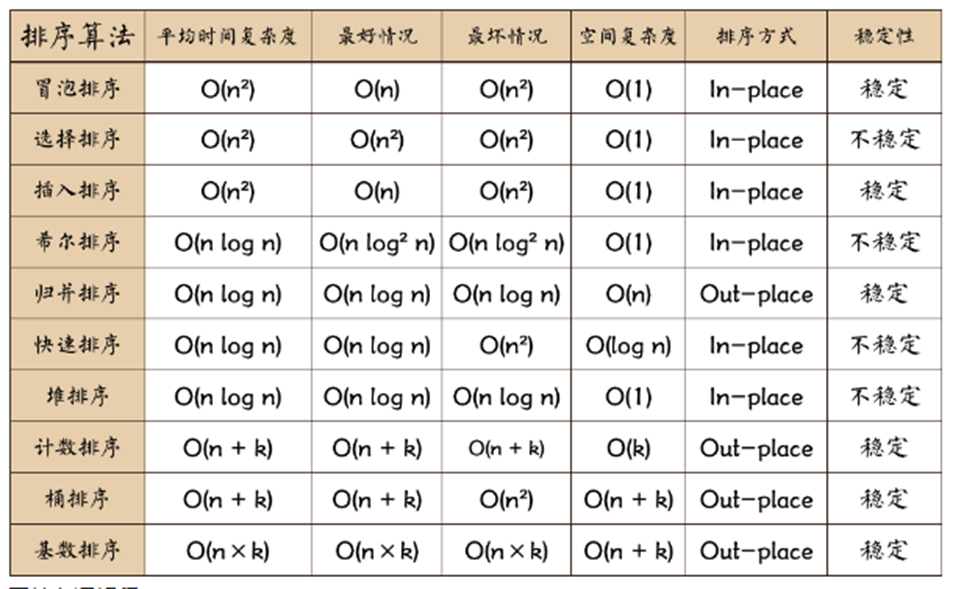
(1)稳定性:假如有两个数 a = b = 1, 排序前 a 在 b 的前面, 如果排序后 a 还是在 b 的前面, 那么就是稳定, 否则不稳定。
(2)内排序:所有排序操作都在内存中完成。
(3)外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行。
(4)时间复杂度:一个算法执行所耗费的时间。
(5)空间复杂度:运行完一个程序所需内存的大小。
(6)n:数据规模。
(7)k:“桶” 的个数。
(8)In-place: 不占用额外内存。
(9)Out-place: 占用额外内存。
5.1 冒泡排序
def bubbleSort(l1):
# 4. 将下列步骤循环 len(l) 次, 即可完成排序
for i in range(len(l1)):
# 1. 对列表进行循环
for j in range(i, len(l1) - 1):
# 2. 判断前一项是否大于后一项
if l1[j] > l1[j + 1]:
# 3 满足条件将两个数字的位置进行置换
temp = l1[j]
l1[j] = l1[j + 1]
l1[j + 1] = temp
return l1
list1 = [3, 44, 38, 5, 47, 15, 36, 26, 27]
print(bubbleSort(list1)) # [3, 5, 15, 26, 27, 36, 38, 44, 47]
5.2 选择排序
def selectSort(l1):
# 8. 重复执行 n(列表长度)次
for i in range(len(l1)):
flag = 0
# 1. 首先定义一个最小值
minVal = 2 ** 31
# 2. 对列表进行遍历
for j in range(i, len(l1)):
# 3. 判断遍历的当前项是否小于minVal
if l1[j] < minVal:
# 4. 如果满足条件则先将当前项记录为最小值
minVal = l1[j]
# 5. 并记录当前项的位置
flag = j
# 6. 当遍历一遍后,此时minVal记录的是待排序的最小值
# 7. 此时将待排序的第一项与最小值进行位置替换
temp = l1[i]
l1[i] = l1[flag]
l1[flag] = temp
return l1
list1 = [3, 44, 38, 5, 47, 15, 36, 26, 27]
print(selectSort(list1)) # [3, 5, 15, 26, 27, 36, 38, 44, 47]
5.3 插入排序
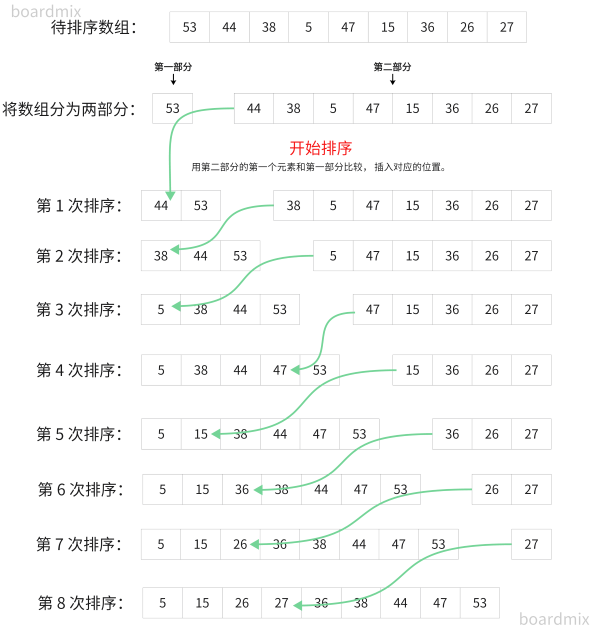
'''-------------------------------------后移法 (效率高)-------------------------------------------'''
"""
1. 将列表划分为两部份
(1) 把第一部份看作有序数列 (开始时第一部分有 1 项, 然后逐渐增加)
(2) 把第二不份看作无序数列 (开始时第二部分有 n-1 项, 然后逐渐减少)
"""
def insertSort(list1):
# 1. 从列表的第二项进行遍历
for j in range(1, len(list1)):
# 2. val:记录第二部份的第一个元素(即当前排序项)
val = list1[j]
# 3. index:记录第一部份的最后一个元素的位置
index = j - 1
# 4.1 index >= 0: 防止越界
# 4.2 val < list1[index]: 将 当前排序项 与第一部份进行对比
while index >= 0 and val < list1[index]:
# 5. 如果 当前排序项 小于 第一部份的元素, 那么就将 第一部份的元素 后移
list1[index + 1] = list1[index]
index -= 1
# 不满足条件之后, 将 当前排序项 插入指定位置。
list1[index + 1] = val
return list1
l1 = [53, 44, 38, 5, 47, 15, 36, 26, 27]
print(insertSort(l1)) # [5, 15, 26, 27, 36, 38, 44, 47, 53]
'''-------------------------------------交换法 (效率低)-------------------------------------------'''
def insertSort(l1):
for m in range(1, len(l1)):
k = m
flag = m
for i in range(k - 1, -1, -1):
if l1[flag] < l1[flag - 1]:
temp = l1[flag]
l1[flag] = l1[flag - 1]
l1[flag - 1] = temp
flag -= 1
return l1
list1 = [53, 44, 38, 5, 47, 15, 36, 26, 27]
print(insertSort(list1))
5.4 希尔排序
-
首先进行分组
1.1 第一次分组: 间隔为:gap = len(list) // 2
1.2 第二次分组: 间隔为:gap = gap // 2
1.3 第三次分组: 间隔为:gap = gap // 2
.
.
1.n 第n次分组: 间隔为:gap = gap // 2 (直到间隔 gap = 1 之后, 不再分组) -
利用插入排序对每一次分完组后的列表进行排序
例如:
list1 = [7, 6, 9, 3, 1, 5, 2, 4]
(1)初始间隔 gap = len(list1)//2 = 4 <==> 第一次排序后为: 1, 5, 2, 3, 7, 6, 9, 4 见(2)
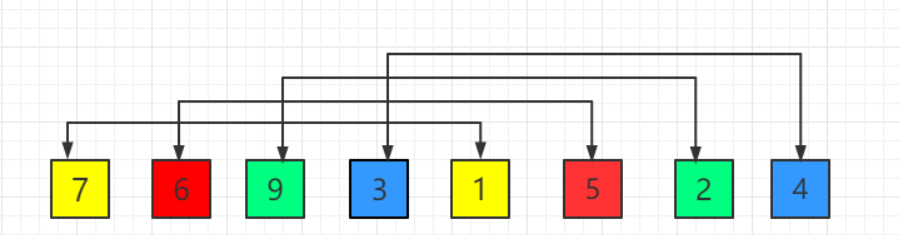
(2)第二次间隔 gap = gap//2 = 2 <==> 第二次排序后为: 1, 3, 2, 4, 7, 5, 9, 6 见 (3)
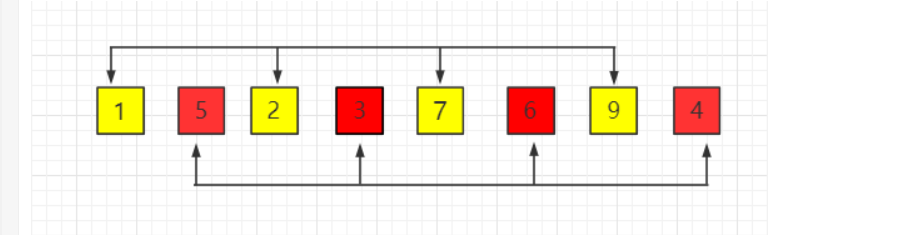
(3)第三次间隔 gap = gap//2 = 1 <==> 第三次排序后为: 1, 2, 3, 4, 5, 6, 7, 9 见(4)

(4) 最终结果:如下

def shellSort(l1):
gap = len(l1) // 2 # 间隔(增量)
while gap: # 用于控制排序几次
for j in range(gap, len(l1)): # 每次开始排序的元素就是以增量为下标的元素, 以下就是插入排序的原理。
val = l1[j]
index = j - gap
while index >= 0 and val < l1[index]:
l1[index + gap] = l1[index]
index -= gap
l1[index + gap] = val
gap //= 2
return l1
list1 = [7, 6, 9, 3, 1, 5, 2, 4]
print(shellSort(list1))
5.5 快速排序
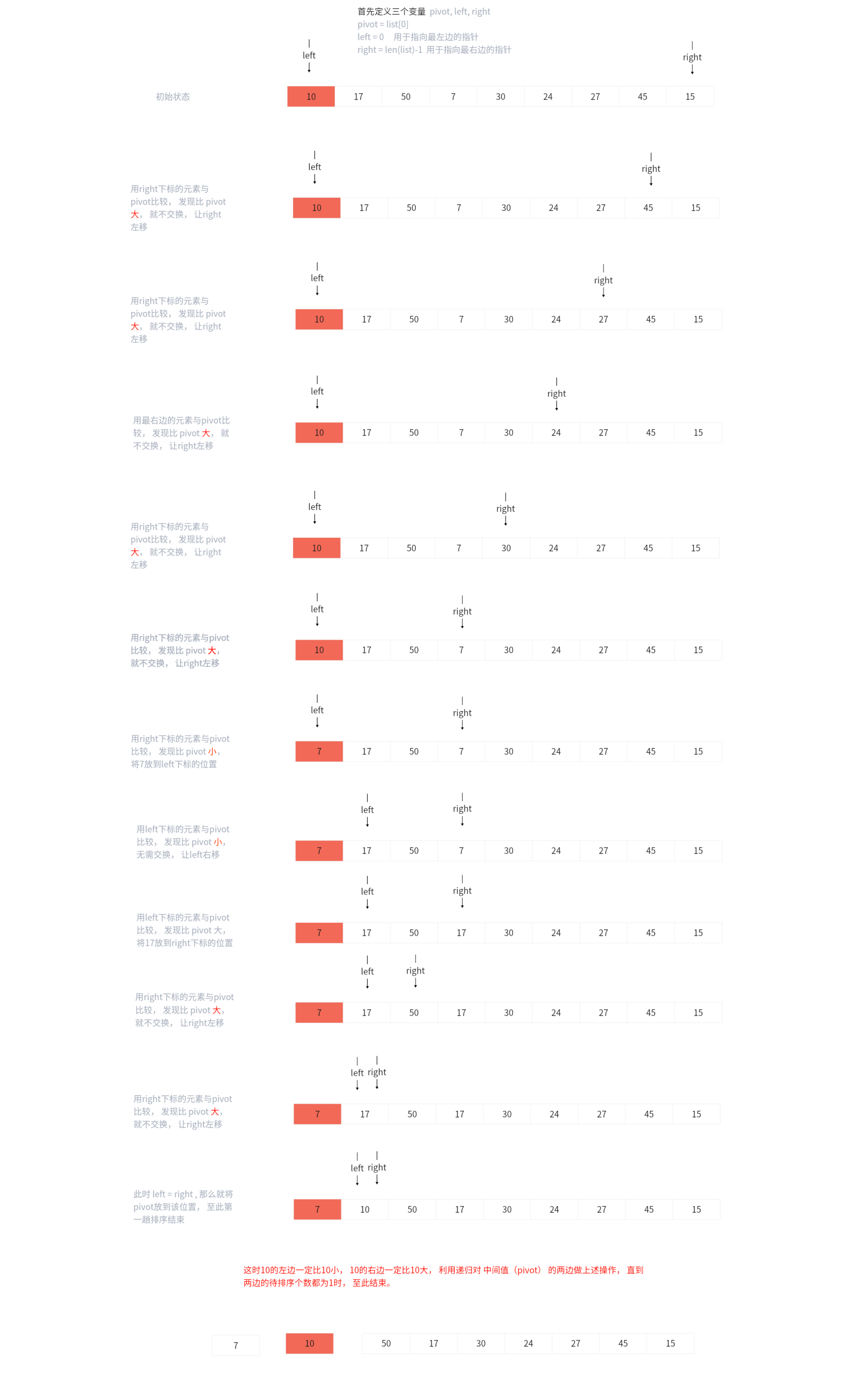
def quickSort(l1, start, end):
if start >= end:
return
pivot, left, right = l1[start], start, end
while left < right:
while l1[right] >= pivot and left < right:
right -= 1
l1[left] = l1[right]
while l1[left] < pivot and left < right:
left += 1
l1[right] = l1[left]
l1[left] = pivot
quickSort(l1, start, left - 1)
quickSort(l1, left + 1, end)
list1 = [10, 17, 50, 7, 30, 24, 27, 45, 15]
quickSort(list1, 0, len(list1) - 1)
print(list1)
5.6 归并排序 ---(分治-递归)
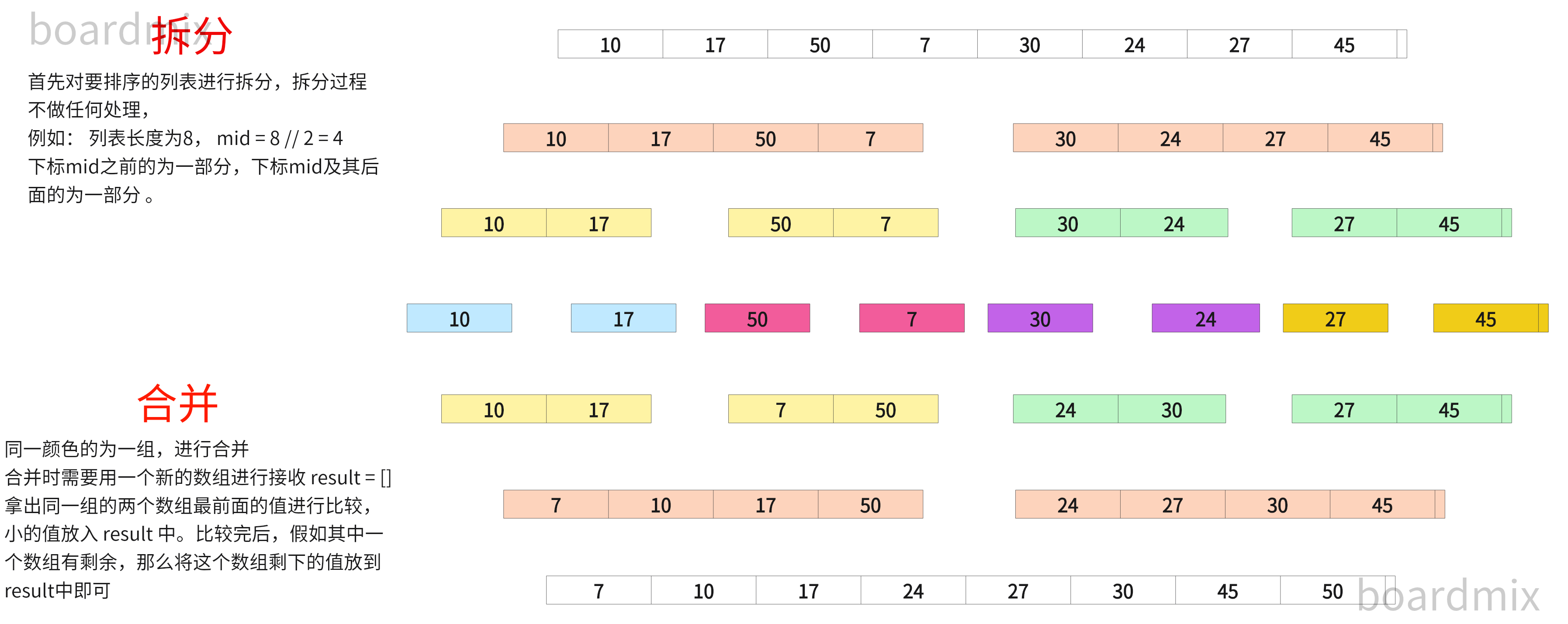
def mergerSort(l1):
# 以下代码为拆分
n = len(l1)
if n == 1:
return l1
mid = n // 2
l_li = mergerSort(l1[0:mid])
r_li = mergerSort(l1[mid:])
# 以下代码为合并
result = []
l_p, r_p = 0, 0
while l_p < len(l_li) and r_p < len(r_li):
if l_li[l_p] <= r_li[r_p]:
result.append(l_li[l_p])
l_p += 1
else:
result.append(r_li[r_p])
r_p += 1
result += l_li[l_p:]
result += r_li[r_p:]
return result
list1 = [10, 17, 50, 7, 30, 24, 27, 45]
print(mergerSort(list1))
5.7 基数排序
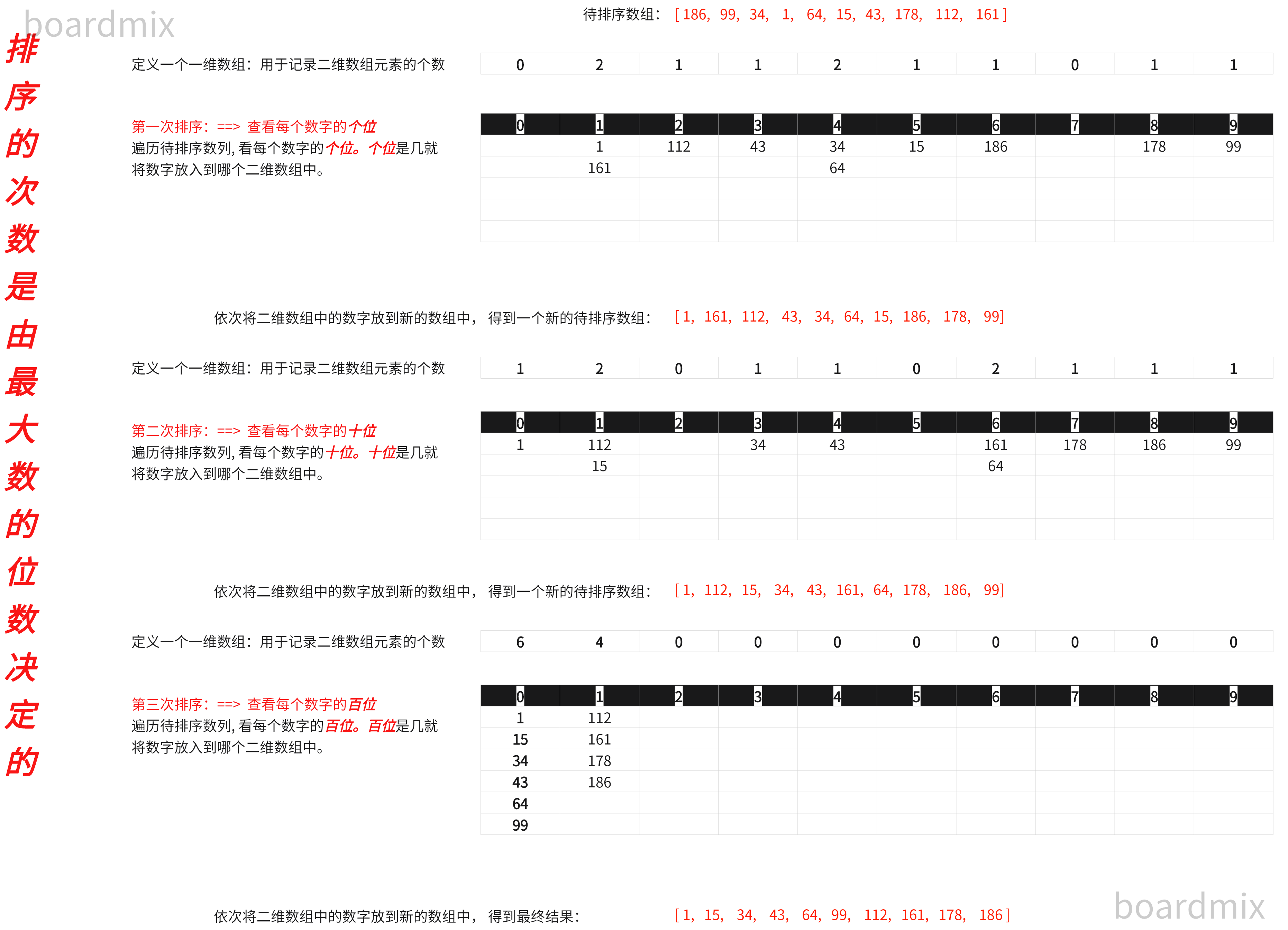
def radixSort(list1):
arr_1 = [] # 初始化一维数组
arr_2 = [] # 初始化二维数组
for k in range(10):
arr_1.append(0)
arr_2.append([])
maxVal = max(list1) # 找出列表中的最大值
n = length = len(str(maxVal)) # length记录最大值是几位数(决定排序需要循环几次)
while length:
result = [] # 用于存放每轮排序的结果
for item in list1:
places = int(item // (10 ** (n - length)) % 10) # places用于记录将要排序元素个位,十位, 百位...的
arr_2[places].append(item) # 将元素存放到二维数组对应的桶中
arr_1[places] += 1
for m in range(len(arr_1)): # 将排好序的元素依次存放到结果列表中
flag = 0
while flag < arr_1[m]:
result.append(arr_2[m][flag])
flag += 1
list1 = result
# 重置一维数组和二维数组
arr_1[0:10] = [0] * 10
arr_2 = []
for k in range(10):
arr_2.append([])
length -= 1
return list1
l1 = [186, 99, 34, 1, 64, 15, 43, 178, 112, 161] # 将要排序的列表
print(radixSort(l1))
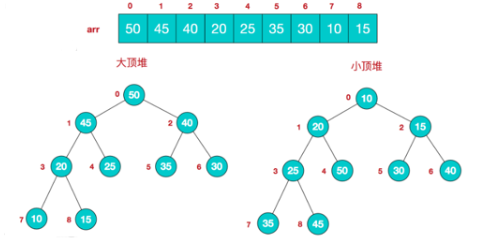
5.8 堆排序
- 首先堆排序分为《大顶堆》《小顶堆》
大顶堆 :每个小树的根节点比两个子节点大
小顶堆 :每个小树的根节点比两个子节点小
def heapify(sortList: list, list_len: int, start_index: int):
"""
:param sortList: 要排序的列表
:param list_len: 例表长度
:param start_index: 开始位置
"""
largest = start_index # 根索引
l_index = 2 * start_index + 1 # 左子树索引
r_index = 2 * start_index + 2 # 右子树索引
if l_index < list_len and sortList[start_index] < sortList[l_index]:
largest = l_index
if r_index < list_len and sortList[largest] < sortList[r_index]:
largest = r_index
if largest != start_index:
sortList[start_index], sortList[largest] = sortList[largest], sortList[start_index] # 交换
heapify(sortList, list_len, largest)
return
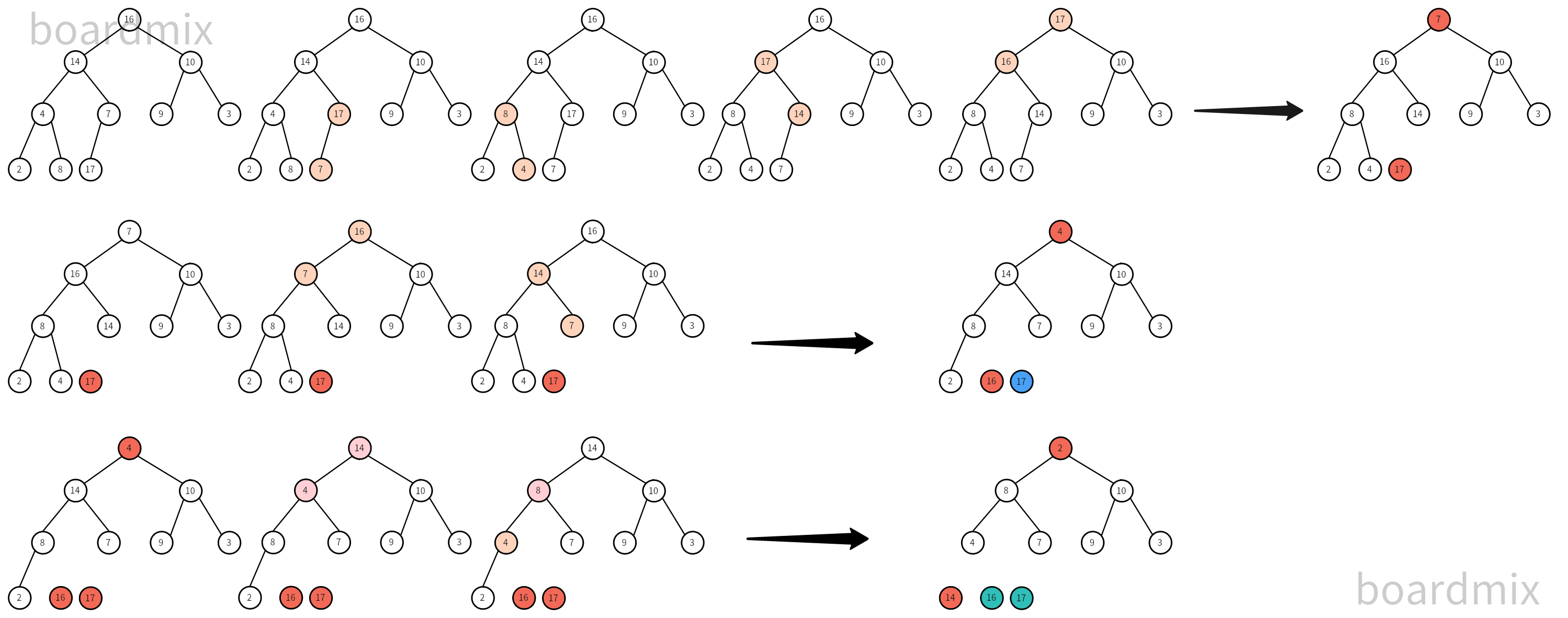
def heapSort(sortList):
length = len(sortList)
for m in range((length - 2) // 2, -1, -1): # 构建二叉树
heapify(sortList, length, m)
# 一个个交换元素
for n in range(length - 1, 0, -1): # 对二叉树进行排序
sortList[n], sortList[0] = sortList[0], sortList[n] # 交换第一个和最后一个位置
heapify(sortList, n, 0)
arr = [16, 14, 10, 4, 7, 9, 3, 2, 8, 17]
heapSort(arr)
print(arr)
六. 查找算法
七. 哈希表
7.1 数组+链表
7.1.1 结构图
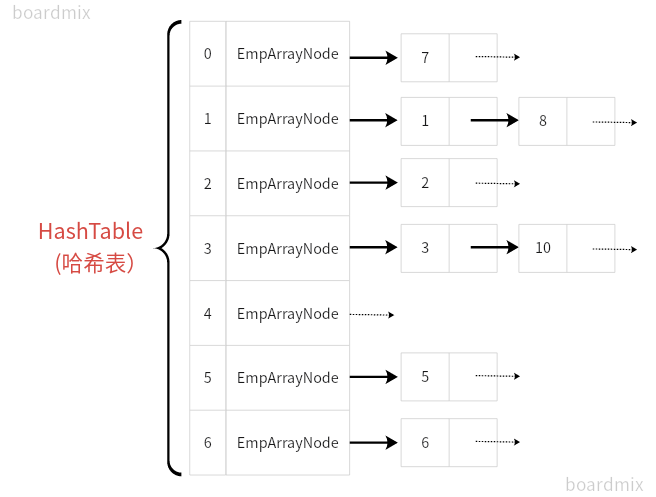
7.1.2 代码
点击查看代码(哈希表)
class HashTable:
def __init__(self, size):
self.storageSpace = []
self.initial(size)
self.size = size
def initial(self, size):
for i in range(size):
empListNode = EmpArrayNode(i)
self.storageSpace.append(empListNode)
# 添加
def add(self, no, name):
mod = no % self.size # 取余
self.storageSpace[mod].add(no, name)
# 打印
def printf(self):
for i in range(self.size):
print(self.storageSpace[i].printf())
# 查找
def find(self, no):
mod = no % self.size # 取余
self.storageSpace[mod].find(no)
class EmpArrayNode:
def __init__(self, no):
self.no = no
self.next = None
# 添加
def add(self, no, name):
newNode = EmpNode(no, name) # 创建一个新的员工节点
head = self.next
if not head:
self.next = newNode
print(f'id: {no}, name: {name} 员工信息添加成功!')
while head:
if head.next is None:
head.next = newNode
print(f'id: {no}, name: {name} 员工信息添加成功!')
break
head = head.next
# 打印
def printf(self):
head = self.next
if head is None:
return '当前链表没有员工信息!'
strInfo = '当前链表员工信息: '
while head:
strInfo += f'《id:{head.no}, name:{head.name}》 '
if head.next is None:
break
head = head.next
return strInfo
# 查找
def find(self, no):
head = self.next
if head is None:
print(f'没有查到id: {no} 员工的信息!')
return None
while head:
if head.no == no:
print(f'id: {head.no}, name: {head.name}')
break
if head.next is None:
print(f'没有查到id: {no} 员工的信息!')
head = head.next
class EmpNode:
def __init__(self, no, name):
self.no = no
self.name = name
self.next = None
hash1 = HashTable(7)
print('---------------添加员工------------------')
hash1.add(1, '张三')
hash1.add(2, '李四')
hash1.add(8, '王五')
hash1.add(3, '麻子')
hash1.add(7, '王二')
hash1.add(6, '小强')
hash1.add(5, '小芳')
hash1.add(10, '小红')
print('---------------打印员工------------------')
hash1.printf()
print('---------------查找员工------------------')
hash1.find(1)
hash1.find(2)
hash1.find(8)
hash1.find(3)
hash1.find(9)
hash1.find(0)
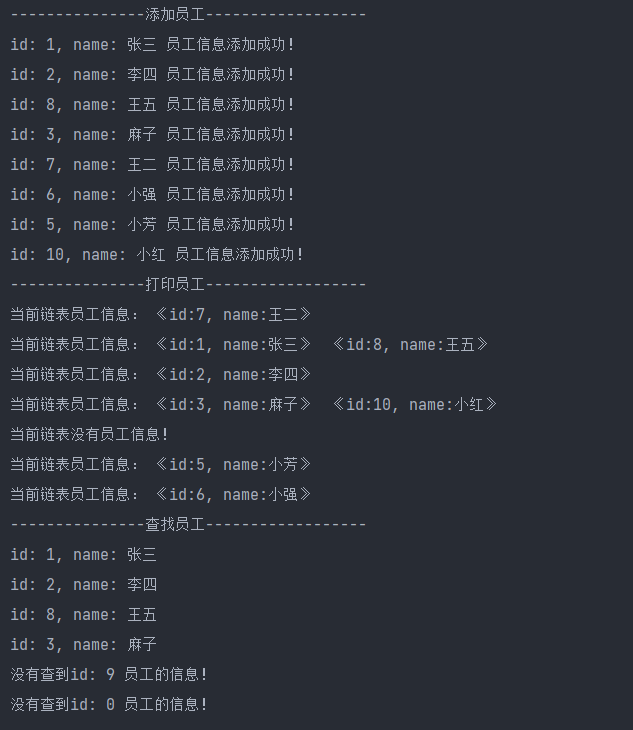
7.1.3 执行结果
八. 二叉树
8.1 二叉树基本认识
8.1.1 常用术语示意图
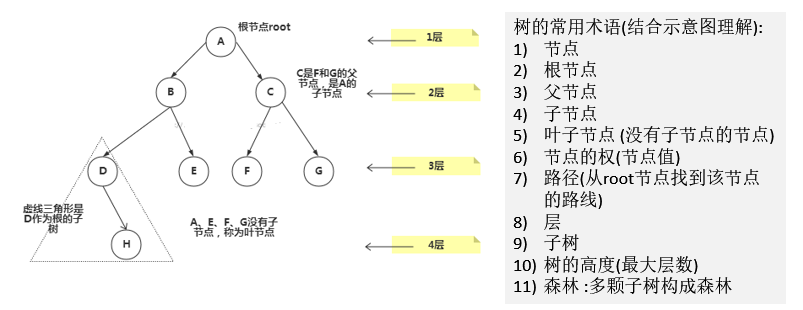
8.1.2 基本概念
- 树有很多种,每个节点最多只能有两个子节点的一种形式称为二叉树。
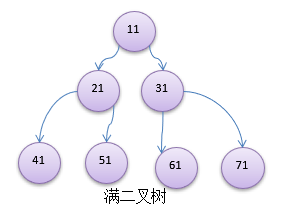
- 如果该二叉树的所有叶子节点都在最后一层,并且结点总数= 2^n -1 , n 为层数,则我们称为满二叉树。
- 如果该二叉树的所有叶子节点都在最后一层或者倒数第二层,而且最后一层的叶子节点在左边连续,倒数第二层的叶子节点在右边连续,我们称为完全二叉树。

8.1.3 二叉树的遍历
- 前序遍历: 根左右
- 中序遍历: 左根右
- 后序遍历: 左右根
8.1.4 代码
-
结构图
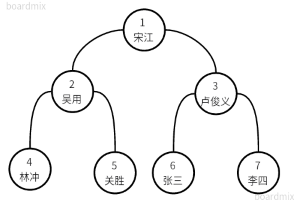
-
运行结果
遍历查找中输出的数字是节点的值, 个数代表查找了几次

点击查看代码(二叉树)
# 节点
class TreeNode:
def __init__(self, no: int, name: str):
self.no = no
self.name = name
self.left = None
self.right = None
def getNo(self):
return self.no
# 前序遍历
def preOrder(self):
print(self.no, self.name, end=' ')
if self.left is not None:
self.left.preOrder()
if self.right is not None:
self.right.preOrder()
# 前序遍历查找
def preOrderSearch(self, no):
print(no)
if self.no == no:
return self
resNode = None
if self.left is not None:
resNode = self.left.preOrderSearch(no)
if resNode is not None:
return resNode
if self.right is not None:
resNode = self.right.preOrderSearch(no)
return resNode
# 中序遍历
def inOrder(self):
if self.left is not None:
self.left.inOrder()
print(self.no, self.name, end=' ')
if self.right is not None:
self.right.inOrder()
# 中序遍历查找
def inOrderSearch(self, no):
resNode = None
if self.left is not None:
resNode = self.left.inOrderSearch(no)
if resNode is not None:
return resNode
print(no)
if self.no == no:
return self
if self.right is not None:
resNode = self.right.inOrderSearch(no)
return resNode
# 后序遍历
def postOrder(self):
if self.left is not None:
self.left.postOrder()
if self.right is not None:
self.right.postOrder()
print(self.no, self.name, end=' ')
# 后序遍历查找
def postOrderSearch(self, no):
resNode = None
if self.left is not None:
resNode = self.left.postOrderSearch(no)
if resNode is not None:
return resNode
if self.right is not None:
resNode = self.right.postOrderSearch(no)
if resNode is not None:
return resNode
print(no)
if self.no == no:
return self
return resNode
# 删除节点
def delNode(self, no):
if self.left is not None and self.left.no == no:
self.left = None
return
if self.right is not None and self.right.no == no:
self.right = None
return
if self.left is not None:
self.left.delNode(no)
if self.right is not None:
self.right.delNode(no)
# 二叉树
class BinaryTree:
def __init__(self, root=None):
self.root = root
# 前序遍历
def preOrder(self):
if self.root is None:
print('二叉树为空, 无法遍历!')
else:
self.root.preOrder()
# 前序遍历查找
def preOrderSearch(self, no):
if self.root is None:
return '没有节点'
res = self.root.preOrderSearch(no)
res = res if res is not None else f'没有id为 {no} 的节点'
return res
# 中序遍历
def inOrder(self):
if self.root is None:
print('二叉树为空, 无法遍历!')
else:
self.root.inOrder()
# 中序遍历查找
def inOrderSearch(self, no):
if self.root is None:
return '没有节点'
res = self.root.inOrderSearch(no)
res = res if res is not None else f'没有id为 {no} 的节点'
return res
# 后序遍历
def postOrder(self):
if self.root is None:
print('二叉树为空, 无法遍历!')
else:
self.root.postOrder()
# 后序遍历查找
def postOrderSearch(self, no):
if self.root is None:
return '没有节点'
res = self.root.postOrderSearch(no)
res = res if res is not None else f'没有id为 {no} 的节点'
return res
# 删除节点
def delNode(self, no):
if self.root is None:
return '没有可删除节点'
if self.root.no == no:
self.root = None
return
self.root.delNode(no)
root1 = TreeNode(1, '宋江')
node2 = TreeNode(2, '吴用')
node3 = TreeNode(3, '卢俊义')
node4 = TreeNode(4, '林冲')
node5 = TreeNode(5, '关胜')
node6 = TreeNode(6, '张三')
node7 = TreeNode(7, '李四')
binaryTree = BinaryTree(root1)
root1.left = node2
root1.right = node3
node2.left = node4
node2.right = node5
node3.left = node6
node3.right = node7
print('-------------前序遍历-------------')
binaryTree.preOrder()
print('\n')
print('-------------中序遍历-------------')
binaryTree.inOrder()
print('\n')
print('-------------后序遍历-------------')
binaryTree.postOrder()
print('\n')
print('-------------前序遍历查找-------------')
result = binaryTree.preOrderSearch(4)
if isinstance(result, TreeNode):
print('查找到 no: %s, name: %s' % (result.no, result.name))
else:
print(result)
print('-------------中遍历查找-------------')
result = binaryTree.inOrderSearch(4)
if isinstance(result, TreeNode):
print('查找到 no: %s, name: %s' % (result.no, result.name))
else:
print(result)
print('-------------后遍历查找-------------')
result = binaryTree.postOrderSearch(4)
if isinstance(result, TreeNode):
print('查找到 no: %s, name: %s' % (result.no, result.name))
else:
print(result)
8.2 顺序二叉树
从数据存储来看,数组存储方式和树的存储方式可以相互转换,即数组可以转换成树,树也可以转换成数组,看右面的示意图。

8.2.1 特点
- 顺序二叉树通常只考虑完全二叉树
- 第n个元素的左子节点为 2 * n + 1
- 第n个元素的右子节点为 2 * n + 2
- 第n个元素的父节点为 (n-1) / 2
- n : 表示二叉树中的第几个元素(按0开始编号*如图所示)
点击查看代码(顺序二叉树)
class SequentialBinaryTree: # 顺序二叉树
def __init__(self):
self.arr = [8, 2, 3, 6, 7, 9, 1, 4]
# self.arr = []
# 前序遍历
def preOrder(self, index=0):
if len(self.arr) == 0:
print('空!')
return
print(self.arr[index], end=' ')
self.leftOrder(index, self.preOrder)
self.rightOrder(index, self.preOrder)
# 中序遍历
def inOrder(self, index=0):
if len(self.arr) == 0:
print('空!')
return
self.leftOrder(index, self.inOrder)
print(self.arr[index], end=' ')
self.rightOrder(index, self.inOrder)
# 后序遍历
def postOrder(self, index=0):
if len(self.arr) == 0:
print('空!')
return
self.leftOrder(index, self.postOrder)
self.rightOrder(index, self.postOrder)
print(self.arr[index], end=' ')
# 左子树遍历
def leftOrder(self, index, method):
if index * 2 + 1 < len(self.arr):
method(index * 2 + 1)
# 右子树遍历
def rightOrder(self, index, method):
if index * 2 + 2 < len(self.arr):
method(index * 2 + 2)
obj1 = SequentialBinaryTree()
obj1.preOrder() # 8 2 6 4 7 3 9 1
print('\t')
obj1.inOrder() # 4 6 2 7 8 9 3 1
print('\t')
obj1.postOrder() # 4 6 7 2 9 1 3 8
8.3 线索化二叉树
8.4 赫夫曼数(哈夫曼树)
8.4.1 基本概念
- 路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。即路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
- 结点的权及带权路径长度:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。 - 树的带权路径长度:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL(weighted path length) 。
权值越大的结点离根结点越近的二叉树才是最优二叉树。
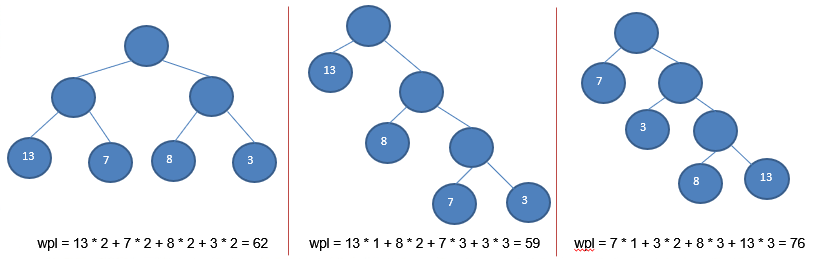
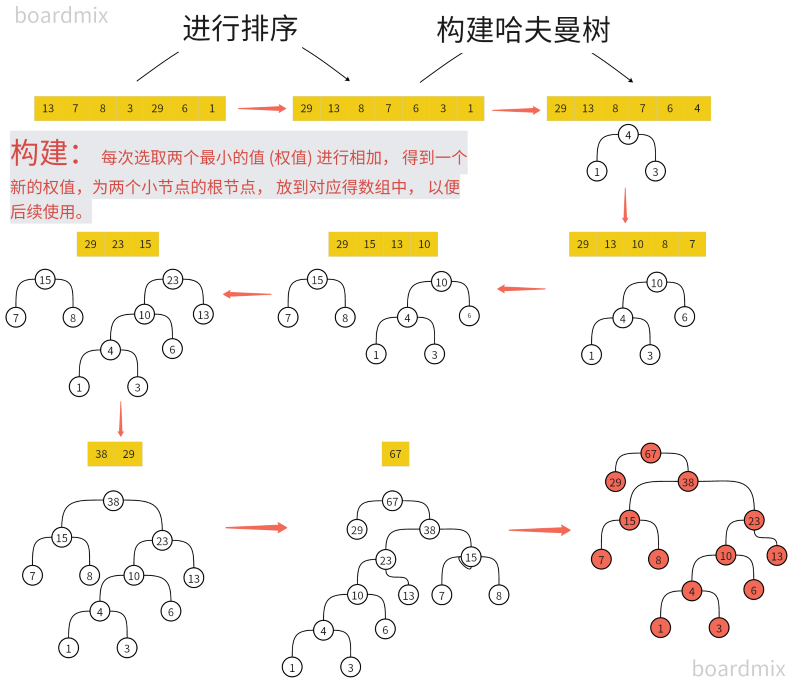
8.4.2 构建哈夫曼树
8.4.3 代码
点击查看代码(哈夫曼树)
class Node:
def __init__(self, value):
self.value = value # 带权值
self.left = None
self.right = None
def preOrder(self): # 前序遍历
print(self.value, end=' ')
if self.left is not None:
self.left.preOrder()
if self.right is not None:
self.right.preOrder()
class HuffmanTree:
def __init__(self, treeList):
self.treeListSort = treeList.sort(reverse=True) # 对列表进行排序
self.treeList = treeList
self.treeNodeList = []
def listConvertNode(self): # 将普通列表转换为节点列表
for i, item in enumerate(self.treeList):
newNode = Node(item)
self.treeNodeList.append(newNode)
def insertAndSort(self, newNode): # 对左右带权和进行插入并重新排序
index = len(self.treeNodeList) - 1
while index >= 0 and newNode.value >= self.treeNodeList[index].value:
index -= 1
index += 1
self.treeNodeList.insert(index, newNode)
def createHuffmanTree(self): # 创建哈夫曼树
self.listConvertNode()
while len(self.treeNodeList) != 1:
leftNode = self.treeNodeList.pop()
rightNode = self.treeNodeList.pop()
newNode = Node(leftNode.value + rightNode.value)
newNode.left, newNode.right = leftNode, rightNode
self.insertAndSort(newNode)
return self.treeNodeList[0]
l1 = [13, 7, 8, 3, 29, 6, 1]
huffmanTree = HuffmanTree(l1)
rootNode = huffmanTree.createHuffmanTree() # 得到的是一个root(根)节点
rootNode.preOrder() # 进行前序遍历 67 29 38 15 7 8 23 10 4 1 3 6 13
8.5 赫夫曼编码
8.6 二叉排序树
8.6.1 图解
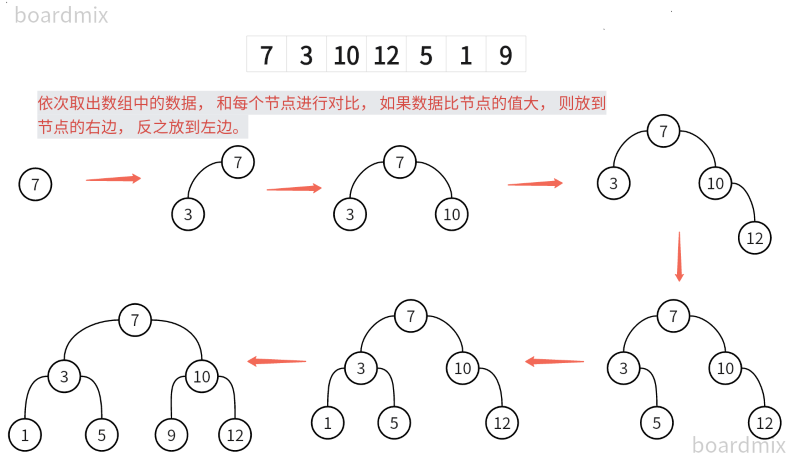
8.6.2 节点删除(原理)
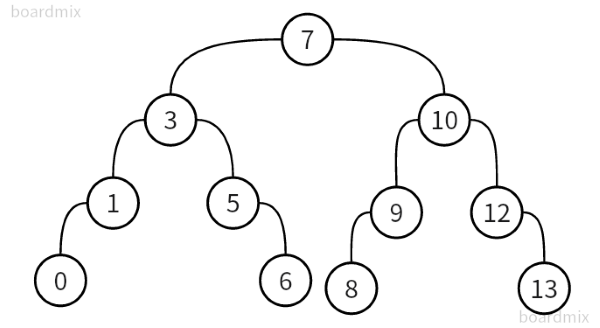
一. 删除叶子节点 (eg: 0, 6, 8, 13)
(1) 先去找到要删除的结点 targetNode
(2) 找到 targetNode 的父结点 parent
(3) 确定 targetNode 是 parent 的左子结点还是右子结点
3.1 如果 targetNode 是左子结点
parent.left = null
3.1 如果 targetNode 是右子结点
parent.right = null
二. 删除只有一颗子树的节点 (eg: 1, 5, 9, 12)
(1)需求先去找到要删除的结点 targetNode
(2)找到 targetNode 的父结点 parent
(3)确定 targetNode 的子结点是左子结点还是右子结点
(4) targetNode是 parent 的左子结点还是右子结点
(5)如果 targetNode 有左子结点
5.1如果 targetNode 是 parent 的左子结点
parent.left = targetNode.left
5.2如果targetNode是 parent的右子结点
parent.right = targetNode.left
(6)如果 targetNode有右子结点
6.1 如果targetNode是parent 的左子结点
parent.left= targetNode.right
6.2如果targetNode 是 parent的右子结点
parent.right = targetNode.right
三. 删除有两个子节点的节点 (eg: 7, 3, 10)
(1)需求先去找到要删除的结点 targetNode
(2)找到 targetNode 的父结点 parent
(3) 如果 targetNode 在 根节点的右边或是根节点
3.1 从 targetNode 的右子树找到最小的结点
3.2 用一个临时变量,将最小结点的值保存到 temp 中
3.3 删除该最小结点
3.4 targetNode.value = temp.value
(4) 如果 targetNode 在 根节点的左边
4.1 从 targetNode 的左子树找到最大的结点
4.2 用一个临时变量,将最大结点的值保存到 temp 中
4.3 删除该最大结点
4.4 targetNode.value = temp.value
8.6.3 代码
点击查看代码(二叉排序树)
class Node:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
# 前序遍历
def preOrder(self):
print(self.value, end=' ')
if self.left is not None:
self.left.preOrder()
if self.right is not None:
self.right.preOrder()
# 中序遍历
def inOrder(self):
if self.left is not None:
self.left.inOrder()
print(self.value, end=' ')
if self.right is not None:
self.right.inOrder()
def searchRightMin(self):
minNode = self.right
flag = 0
while minNode.left:
flag += 1
minNode = minNode.left
return minNode, flag
def searchLeftMax(self):
maxNode = self.left
flag = 0
while maxNode.right:
flag += 1
maxNode = maxNode.right
return maxNode, flag
class BinarySortTree:
def __init__(self, myList):
self.myList = myList
self.rootNode = self.createRootNode()
def createRootNode(self): # 创建根节点
rootNode = Node(self.myList[0])
return rootNode
def addNode(self, appendNode, rootNode): # 添加节点
"""
:param appendNode: 将要添加的节点
:param rootNode: 根节点
"""
if appendNode.value > rootNode.value:
if rootNode.right is not None:
self.addNode(appendNode, rootNode.right)
else:
rootNode.right = appendNode
if appendNode.value < rootNode.value:
if rootNode.left is not None:
self.addNode(appendNode, rootNode.left)
else:
rootNode.left = appendNode
def createBinarySortTree(self): # 创建二叉排序树
for i in range(1, len(self.myList)):
newNode = Node(self.myList[i])
self.addNode(newNode, self.rootNode)
def searchNode(self, value): # 查找结点
findNode = self.rootNode
while findNode is not None:
if findNode.value == value:
return findNode
else:
if value > findNode.value:
findNode = findNode.right
else:
findNode = findNode.left
def searchParentNode(self, value): # 查找父结点
parentNode = None
findNode = self.rootNode
while findNode is not None:
if findNode.value == value:
# print('root没有父节点')
return parentNode
else:
if value > findNode.value:
parentNode = findNode
findNode = findNode.right
else:
parentNode = findNode
findNode = findNode.left
def delNode(self, value):
deleteNode = self.searchNode(value) # 待删除的节点
if deleteNode is None:
return '没有你想删除的节点'
parentNode = self.searchParentNode(value) # 待删除的节点的父节点
"""当删除的是叶子节点时"""
if deleteNode.right is None and deleteNode.left is None:
if deleteNode == self.rootNode:
self.rootNode = None
return
if deleteNode.value > parentNode.value:
parentNode.right = None
else:
parentNode.left = None
"""当删除的节点含有两个子节点时"""
if deleteNode.right is not None and deleteNode.left is not None:
if deleteNode.value >= self.rootNode.value:
temp, flag = deleteNode.searchRightMin()
tempParent = self.searchParentNode(temp.value)
if flag == 0:
tempParent.right = None
else:
tempParent.left = None
deleteNode.value = temp.value
else:
temp, flag = deleteNode.searchLeftMax()
tempParent = self.searchParentNode(temp.value)
if flag == 0:
tempParent.left = None
else:
tempParent.right = None
deleteNode.value = temp.value
else:
"""当删除的节点只含有一个子节点时"""
if deleteNode.left is not None: # 当删除的节点只含有左子节点时
if deleteNode.value < parentNode.value:
parentNode.left = deleteNode.left
else:
parentNode.right = deleteNode.left
elif deleteNode.right is not None: # 当删除的节点只含有右子节点时
if deleteNode.value < parentNode.value:
parentNode.left = deleteNode.right
else:
parentNode.right = deleteNode.right
l1 = [7, 3, 10, 12, 5, 1, 9]
binarySortTree = BinarySortTree(l1)
binarySortTree.createBinarySortTree()
binarySortTree.rootNode.preOrder() # 7 3 1 5 10 9 12
print('\t')
binarySortTree.rootNode.inOrder() # 1 3 5 7 9 10 12
8.7 平衡二叉树
8.7.1 基本介绍
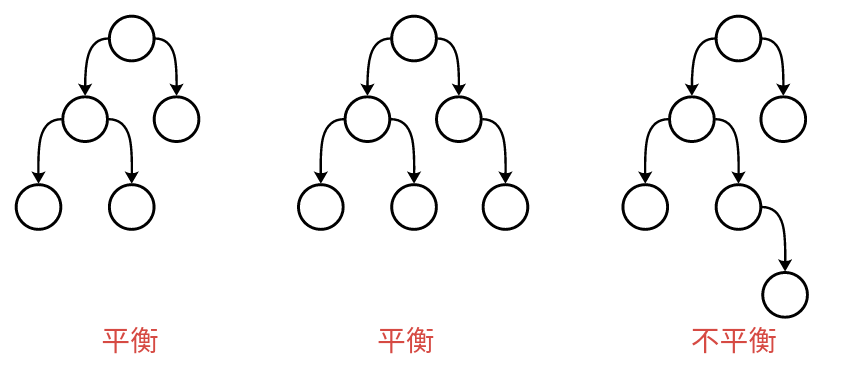
平衡二叉树:又叫平衡二叉搜索树(Self-balancing binary search tree)又被称为AVL树, 可以保证查询效率较高。
特点:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号