
python 爬虫
一. 爬虫需要的模块
1.1 requests模块
1. requests 不仅仅做爬虫用它,后期调用第三方接口,也是要用它的
2. 本质是封装了内置模块urlib3
1. 下载
pip3 install requests
1.2 url编码和解码
1. 导入模块
from urllib import parse # 内置模块
2. 编码
res = parse.quote('美女')
print(res) # %E7%BE%8E%E5%A5%B3
3. 解码
res = parse.unquote('%E7%BE%8E%E5%A5%B3')
print(res) # 美女
1.3 BeautifulSoup4 解析模块
1. 下载
pip3 install beautifulsoup4
2. 内置解析库html.parser
BeautifulSoup('要解析的内容 >>> (res.text)', "html.parser")
3. 速度快 必须要装lxml >>> pip3 install lxml
BeautifulSoup('要解析的内容 >>> (res.text)', "lxml")
1.4 selenium 通过代码控制浏览器的操作
具体见 >>> 目录十二
1. 下载
pip3 install selenium
二. 响应Response的方法
2.1 相应方法
respone = requests.get('请求地址')
print(respone.text) # 响应体的文本内容
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 响应cookie
print(respone.cookies.get_dict()) # cookieJar对象,获得到真正的字段
print(respone.cookies.items()) # 获得cookie的所有key和value值
print(respone.url) # 请求地址
print(respone.history) # 访问这个地址,可能会重定向,放了它冲定向的地址
print(respone.encoding) # 页面编码
2.2 设置响应编码
response.encoding = "utf8"
response.encoding = "gbk"
# 案例
res = requests.get(url=url)
res.encoding = "gbk" # 在这个位置设置
print(res.text)
三. 发送get请求
3.1 发送请求
import requests
res=requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html')
print(res.text) # http响应体的文本内容
3.2 携带参数
""" 1. 地址栏中拼接 """
res=requests.get('https://www.baidu.com/s?wd=美女')
""" 2. 使用params参数携带 """
res=requests.get('https://www.baidu.com/s',params={
'wd':'美女',
})
四. 携带请求头
1. User-Agent:客户端类型:有浏览器,手机端浏览器,爬虫类型,程序,scrapy。一般伪造成浏览器
2. referer:上次访问的地址 >>>> Referer: https://www.lagou.com/gongsi/
2.1 如果要登录,模拟向登录接口发请求,正常操作必须在登录页面上才能干这事,如果没有携带referer,它就认为你是恶意的,拒绝调
2.2 图片防盗链
# 方式一
header={
# 客户端类型
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
# 方式二 定义请求头
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().random
}
res=requests.get('https://dig.chouti.com/',headers=header)
print(res.text)
五. 携带cookie
5.1 方式一: 直接带在请求头中
header={
# 客户端类型
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
#携带cookie
'Cookie':'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9;' # cookie本身很长,只截取了其中的一部分。
}
res=requests.post('https://dig.chouti.com/link/vote',headers=header)
print(res.text)
5.2 方式二: 单独抽取成一个参数
res=requests.post('https://dig.chouti.com/link/vote',cookies={'key':'value'}) # 配成字典
print(res.text)
5.3 Cookie 示例
# 一般的 Cookie
'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiI3MzAyZDQ5Yy1mMmUwLTRkZGItOTZlZi1hZGFmZTkwMDBhMTEiLCJleHBpcmUiOiIxNjYxNjU0
MjYwNDk4In0.4Y4LLlAEWzBuPRK2_z7mBqz4Tw5h1WeqibvkBG6GM3I; __snaker__id=ozS67xizRqJGq819;
YD00000980905869%3AWM_TID=M%2BzgJgGYDW5FVFVAVQbFGXQ654xCRHj8; _9755xjdesxxd_=32;
Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1666756750,1669172745;
gdxidpyhxdE=W7WrUDABQTf1nd8a6mtt5TQ1fz0brhRweB%5CEJfQeiU61%5C1WnXIUkZH%2FrE4GnKkGDX767Jhco%2B7xUMCiiSlj4h%2BRqcaNohAkeHsmj3GCp2%2Fcj4Hm
XsMVPPGClgf5AbhAiztHgnbAz1Xt%5CIW9DMZ6nLg9QSBQbbeJSBiUGK1RxzomMYSU5%3A1669174630494;
YD00000980905869%3AWM_NI=OP403nvDkmWQPgvYedeJvYJTN18%2FWgzQ2wM3g3aA3Xov4UKwq1bx3njEg2pVCcbCfP9dl1RnAZm5b9KL2cYY9eA0DkeJo1zfCWViwVZUm303
JyNdJVAEOJ1%2FH%2BJFZxYgMVI%3D;
YD00000980905869%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee92bb45a398f8d1b34ab5a88bb7c54e839b8aacc1528bb8ad89d45cb48ae1aac22af0fea7c3b92a8d90fc
d1b266b69ca58ed65b94b9babae870a796babac9608eeff8d0d66dba8ffe98d039a5edafa2b254adaafcb6ca7db3efae99b266aa9ba9d3f35e81bdaea4e55cfbbca4d2d
1668386a3d6e1338994fe84dc53fbbb8fd1c761a796a1d2f96e81899a8af65e9a8ba3d4b3398aa78285c95e839b81abb4258cf586a7d9749bb983b7cc37e2a3;
token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNjcxNzY1NzQ3NjczIn0.50e-ROweqV0uSd3-
Og9L7eY5sAemPZOK_hRhmAzsQUk; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1669173865'
六. 发送post请求
6.1 发送 post 请求 >>> 登录 >>> 然后携带 cookie 访问
方式一:
import requests
data = {
'username': '············@qq.com',
'password': '******',
'captcha': 'cccc',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
"""这里需要两步"""
# 第一步访问网站之后, 后端会返回一个 cookie 。
# 第二步这时需要携带第一次返回的 cookie 才能请求数据。
res = requests.post('http://www.aa7a.cn/user.php', data=data) # 1. 获取 cookie
print(res.text)
print(res.cookies)
res2 = requests.get('http://www.aa7a.cn/', cookies=res.cookies) # 2. 携带(1)中的 cookie
print(res2.text)
方式二:
"""request.session的使用:当request使用,它能自动维护cookie"""
import requests
session = requests.session()
data = {
'username': '············@qq.com',
'password': '******',
'captcha': 'cccc',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = session.post('http://www.aa7a.cn/user.php', data=data)
res2 = session.get('http://www.aa7a.cn/') # 无需自己传
print(res2.text)
6.2 post 携带数据
1. data = {}
字典是使用默认编码格式:urlencoded
2. json = {}
字典是使用json 编码格式
七. 获取二进制数据
7.1 图片
import requests
""" 无论什么请求,最好带上请求头(因为这是最简单的校验)"""
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().random
}
res = requests.get('https://img2.baidu.com/it/u=2876866764,2601203893&fm=253&fmt=auto&app=120&f=JPEG?w=1422&h=800', headers=header)
with open('美女.jpg', 'wb') as f:
f.write(res.content)
7.2 视频 >>> 一段一段写
import requests
res=requests.get('https://vd3.bdstatic.com/mda-mk21ctb1n2ke6m6m/sc/cae_h264/1635901956459502309/mda-mk21ctb1n2ke6m6m.mp4')
with open('美女.mp4', 'wb') as f:
for line in res.iter_content(): # 一段一段写
f.write(line)
八. requests高级用法
8.1 使用代理(重要)
一些网站防止爬虫, 会对进行一些限制, >>> 比如: 通过ip,用户id限制, 频率限制,封账号
因此使用代理ip发送请求
# 导入模块
import requests
# 代理ip
proxies = {
'http': '192.168.10.102:9003',
}
respone=requests.get('https://www.baidu.com',proxies=proxies) # 使用代理
print(respone.text)
8.2 ssl认证(了解)
1. https 和http有什么区别
https=http+ssl/tsl # 就是http通过加密传输
2. 不认证证书了
import requests
respone = requests.get('https://www.12306.cn', verify=False) # 不验证证书,报警告,返回200
print(respone.status_code)
3. 手动携带证书访问
import requests
respone=requests.get('https://www.12306.cn',cert=('/path/server.crt','/path/key'))
print(respone.status_code)
8.3 超时设置(了解)
# timeout 也可以是个元组
respone=requests.get('https://www.baidu23.com',timeout=3)
print(respone)
8.4 异常处理(了解)
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型
try:
r=requests.get('http://www.baidu.com', timeout=0.00001)
except ReadTimeout:
print('===:')
except ConnectionError: #网络不通
print('-----')
except Timeout:
print('aaaaa')
except RequestException:
print('Error')
8.5 上传文件(了解)
import requests
files={'file':open('a.txt','rb')}
# http://httpbin.org/post 压力测试网站
res=requests.post('http://httpbin.org/post',files=files)
print(res.text)
九. 代理池搭建与使用
9.1 搭建
地址:https://github.com/jhao104/proxy_pool
1. 将项目拉到本地
git clone https://github.com/jhao104/proxy_pool.git
2. 安装依赖
pip install -r requirements.txt
3. 配置
# 配置API服务
HOST = "0.0.0.0" # IP
PORT = 5000 # 监听端口
4 配置数据库
DB_CONN = 'redis://127.0.0.1:8888/0' # 代理IP存储地址 >>> redis 数据库
5 爬取代理ip的网站 (可修改可不修改)
PROXY_FETCHER = [
"freeProxy01",
"freeProxy02",
······
]
6 启动爬虫,启动web服务
# 启动调度程序
python proxyPool.py schedule
# 启动webApi服务
python proxyPool.py server
9.2 使用
import requests
# 向搭建的ip代理项目地址发送请求, 获取想要的代理 IP ,以及其他数据
res = requests.get('http://127.0.0.1:5010/get/').json()
if res['https']:
http = 'https'
else:
http = 'http'
# 配置代理
proxie = {
http: res['proxy']
}
# 使用代理ip发用请求
_res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005896.html', proxies=proxie)
print(_res.status_code)
十. 爬取案列
10.1 视频网站
示例网站:https://www.pearvideo.com/
# 导入两个模块
import requests
import re
# 像下面的地址发送请求, 就是一个一个 li 标签, 每个标签有大差不差的内容
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0')
# 利用正则解析出每个 a标签(链接)中的地址
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text) # ['video_1782320', 'video_1782323']
for video_item in video_list:
# 这里得到的是 xml 格式 HTML 代码, 里面没有具体的 MP4 地址,但浏览器有 因为浏览器能直接解析 JS 代码
""" 过渡 不做处理
for video_item in video_list:
video_url = 'https://www.pearvideo.com/' + video_item
res_url = requests.get(video_url)
print(res_url.text)
"""
# 截取每个视频的 id
video_id = video_item.split('_')[-1]
# 因为网站反爬虫操作, 所以直接请求 会少一个 'Referer': f'https://www.pearvideo.com/{video_item}'
header = {
'Referer': f'https://www.pearvideo.com/{video_item}'
}
# 因此,请求时加 headers
res = requests.get(f'https://www.pearvideo.com/videoStatus.jsp?contId={video_id}&mrd=0.40049742937422206',
headers=header).json()
mp4_url = res['videoInfo']['videos']['srcUrl']
mp4_url = mp4_url.replace(mp4_url.rsplit('/', 1)[-1].split('-')[0], 'cont-%s' % video_id)
print(mp4_url)
res = requests.get(mp4_url)
with open(f'./video/{video_id}.mp4', 'wb') as f:
for line in res.iter_content(): # 一段一段写
f.write(line)
10.2 新闻网站
示例网站:https://www.autohome.com.cn/news/
import requests
# 解析库;bs4 pip3 install beautifulsoup4
from bs4 import BeautifulSoup
res = requests.get('https://www.autohome.com.cn/news/1/#liststart')
# print(res.text) # 从返回的html中查找,bs是解析html,xml格式的
soup = BeautifulSoup(res.text, 'html.parser')
# 查找:类名等于article的ul标签
ul_list = soup.find_all(name='ul', class_='article')
print(len(ul_list)) # 4 个ul取出来了
for ul in ul_list:
# 找到ul下所有的li标签
li_list = ul.find_all(name='li')
for li in li_list:
h3 = li.find(name='h3')
if h3: # 获取h3标签的文本内容
title = h3.text
desc = li.find(name='p').text
url = 'https:' + li.find(name='a').attrs.get('href')
img = li.find(name='img').attrs.get('src')
if not img.startswith('http'):
img='https:'+img
print('''
文章标题:%s
文章摘要:%s
文章地址:%s
文章图片:%s
''' % (title, desc, url, img))
10.3 淘宝网站
-
按照下面三步找到爬取的内容(需要重新点击刷新按钮)
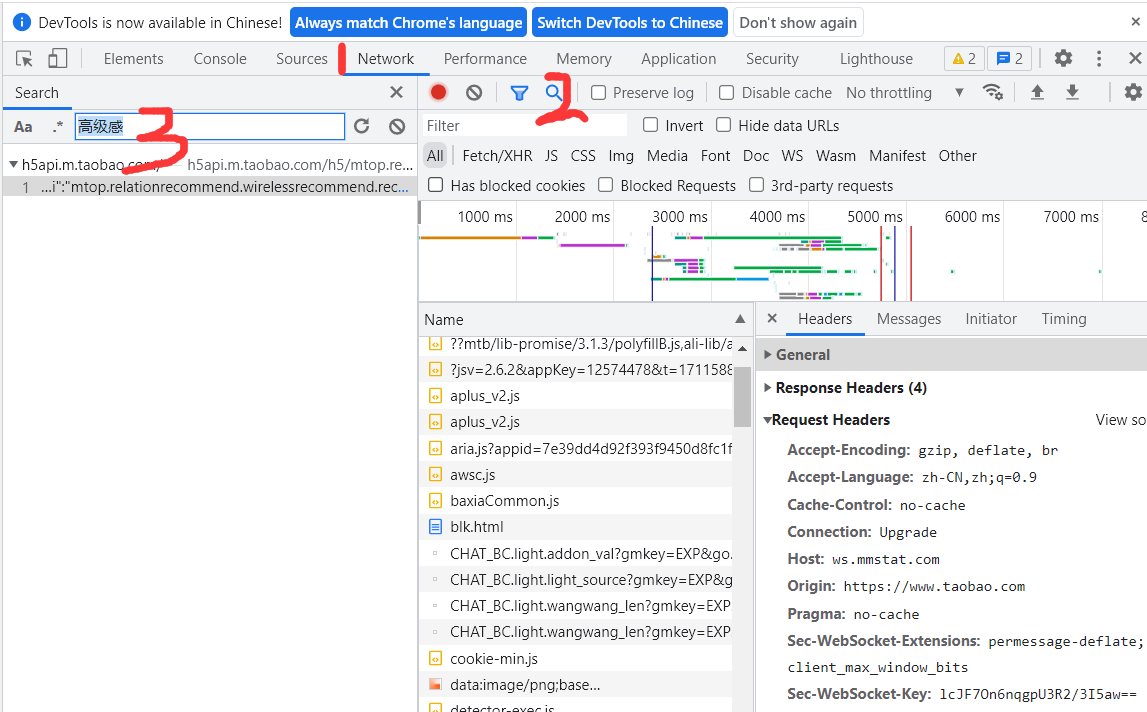
-
点击headers ---> 复制 (Request URL)作为请求地址
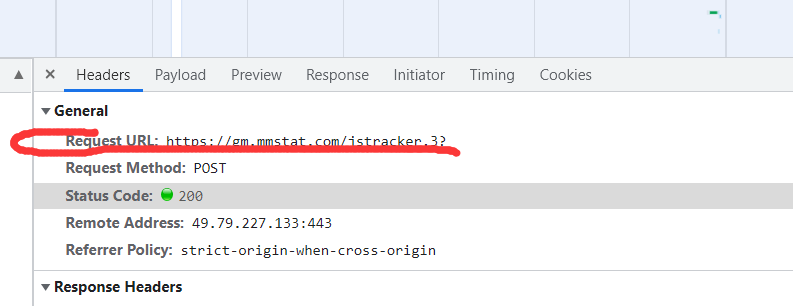
-
伪装请求 需要复制 Request Header 下的一些东西:(cookie, referer, user-agent)
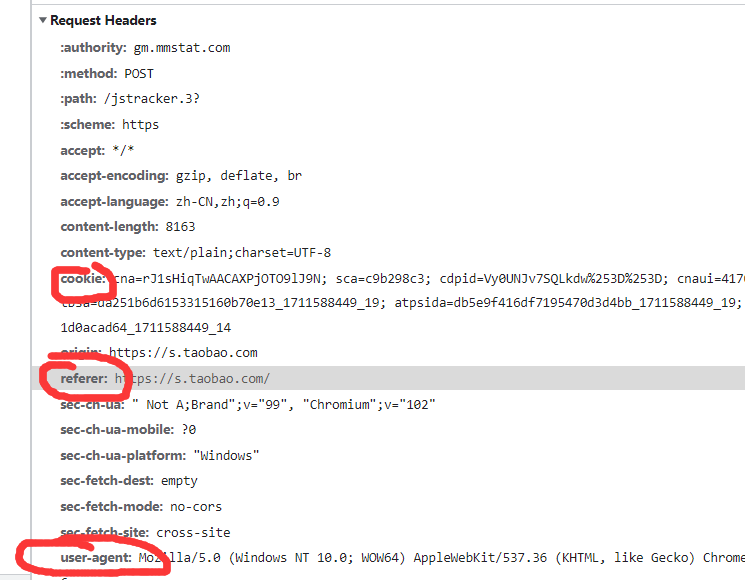
图一:

- 代码示例
1. 发送请求
import requests
url = '...'
cookies = {
'cookie': '...'
}
headers = {
'cookie': '...'
'user-agent': '...'
'referer': '...'
}
data = requests.get(url=url, headers=headers, cookies=cookies)
2. 获取数据
# 需要在运行的控制台中进行搜索,查看是否是需要的数据 (如图一)
res = data.text
3. 解析数据
# 因为数据格式有两种
(1) 结构化数据(json 数据类型的, 比较友好)
(2) 非结构化数据(类似网页源码一样的, 可以利用 css/xpath/re (re万能解析 内置模块))
re 利用 findall('解析规则', 要解析的数据)
g_page_config = (.*); =====> .* 表示全部数据
""" findall() [0] 需要进行索引取值 """
4. 将 json 转 python字典 进行取值即可
十一. bs4( BeautifulSoup4 ) 遍历文档 (lxml)
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id='id_p' name='lqz' xx='yy'>lqz is handsome <b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
相关方法
11.1 遍历文档树
"""-----------------------------------------------------遍历文档树-----------------------------------------------------"""
1. 获取标签
soup.标签名 # 例如: res=soup.p
soup.标签名.子标签名 # 嵌套使用获取
2. 获取标签的名称
res=soup.head.title
print(res.name)
3. 获取标签的属性
res=soup.p
print(res.attrs) # 获取的是 {'属性名1': '属性值1', '属性名2': '属性值2'}
print(res.get('img')) # 获取具体某个属性
4. 获取标签的内容 (文本)
res = soup.p
print(res.text) # 把该标签子子孙孙内容拿出来拼到一起 字符串
print(res.string) # None 必须该标签没有子标签,才能拿出文本内容
print(list(res.strings)) # generator 生成器,把子子孙孙的文本内容放到生成器中
5. 嵌套选择
res=soup.html.body.a
print(res.text)
6、子节点、子孙节点
print(soup.p.contents) # p下所有子节点
print(soup.p.children) # 得到一个迭代器,包含p下所有子节点
7、父节点、祖先节点
print(soup.a.parent) # 获取a标签的父节点,直接父节点
print(list(soup.a.parents)) # 找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
8、兄弟节点
print(soup.a.next_sibling) # 下一个兄弟
print(soup.a.previous_sibling) # 上一个兄弟
print(list(soup.a.next_siblings)) # 下面的兄弟们 >>> 生成器对象
print(list(soup.a.previous_siblings)) # 上面的兄弟们 >>> 生成器对象
11.2 搜索文档树
"""-----------------------------------------------------搜索文档树-----------------------------------------------------"""
通过:
1. find:找一个
2. findAll:找所有
1. 通过 标签名 或 属性名 查找
res=soup.find(name='a',id='link2') # 查找标签为 a 并且 id 为 link2
res=soup.find(href='http://example.com/tillie') # href 属性为 http://example.com/tillie 的标签
res=soup.find(class_='story') # class 属性为 story 的标签
res=soup.body.find('p') # 结合查找
res=soup.body.find(string='Elsie')
res=soup.find(attrs={'class':'sister'}) # 属性查找, 字典形式
# 列表形式查找
res=soup.find_all(class_=['story','sister']) # 或条件
res=soup.find_all(name=['a','p']) # 或条件
2. 正则表达式
import re
res=soup.find_all(name=re.compile('^b'))
3. 布尔型 True/False # 标签名,属性名 等于布尔
res=soup.find_all(name=True) # 有标签名的所有标签
4. 方法 (函数) # 标签名或属性名 = 方法
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find_all(has_class_but_no_id))
11.3 css选择器
支持所有 css 选择语法, 可参考 css 语法来写
# 只需要会了css选择,几乎所有的解析器[bs4,lxml...],都会支持css和xpath
soup = BeautifulSoup(html_doc, 'lxml')
res=soup.select('a')
res=soup.select('#link1')
res=soup.select('.sister')
res=soup.select('body>p>a')
res=soup.select('body>p>a:nth-child(2)')
res=soup.select('body>p>a:nth-last-child(1)')
[attribute=value]
res=soup.select('a[href="http://example.com/tillie"]')
十二. selenium基本使用-(通过代码控制浏览器操作)
1. selenium 本质是通过驱动浏览器, 完成模拟浏览器的操作。
2. selenium 最初是一个自动化测试工具
3. 爬虫中使用它主要是为了解决 requests 无法直接执行 JavaScript 代码的问题。
12.1 基本使用
1. 安装模块
pip3 install selenium
2. 下载浏览器驱动 >>> 以谷歌浏览器为例
2.1 下载地址 https://registry.npmmirror.com/binary.html?path=chromedriver/ >>> 必须下载与浏览器版本对应的驱动
2.2 如何查看浏览器版本 >>> 浏览器右上角三个点---> 帮助 ---> 关于 Google Chrome
12.2 代码展示
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
import time
# 请求的url地址
url = 'http://www.baidu.com'
# 定义chrome驱动去地址
path = Service('./chromedriver.exe')
# 创建浏览器操作对象
browser = webdriver.Chrome(service=path)
browser.get(url)
# 获取请求还回的 html 文档
browser.page_source
time.sleep(3)
# 关闭tab页
browser.close()
browser.quit()
# 关闭浏览器
12.3 无界面浏览器(一些配置)
主要用的是第 5 条配置
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
1. 指定浏览器分辨率
chrome_options.add_argument('window-size=1920x3000')
2. 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--disable-gpu')
3. 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('--hide-scrollbars')
4. 不加载图片, 提升速度
chrome_options.add_argument('blink-settings=imagesEnabled=false')
5. 浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
chrome_options.add_argument('--headless')
6. 手动指定使用的浏览器位置
chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
browser = webdriver.Chrome(executable_path='./chromedriver.exe', options=chrome_options)
12.4 模拟登录 gitee 网站
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium import webdriver
from bs4 import BeautifulSoup
import time
# url地址
url = 'https://gitee.com/'
# 定义chrome驱动去地址
path = Service('./chromedriver.exe')
chrome_option = Options()
# chrome_option.add_argument('--headless')
# 创建浏览器操作对象
browser = webdriver.Chrome(service=path, options=chrome_option)
# 发送 get 请求
browser.get(url)
""" 等待,找一个标签,如果标签没加载出来,等一会 """
browser.implicitly_wait(10)
""" 全屏 """
browser.maximize_window()
# 获取按钮并点击
login_a = browser.find_element(by=By.LINK_TEXT, value='登录')
login_a.click()
# 获取相应的 input 框, 并输入用户名和密码
user_name = browser.find_element(by=By.ID, value='user_login')
user_name.send_keys('**********') # 输入对应网站的用户名
pass_word = browser.find_element(by=By.ID, value='user_password')
pass_word.send_keys('**********') # 输入对应网站的密码
# 获取登录按钮并点击登录
login_button = browser.find_element(by=By.CLASS_NAME, value='submit')
login_button.click()
time.sleep(5)
12.5 常用方法
1. 标签查找
bro.find_element(by=By.ID,value='id号')
bro.find_element(by=By.LINK_TEXT,value='a标签文本内容')
bro.find_element(by=By.PARTIAL_LINK_TEXT,value='a标签文本内容模糊匹配')
bro.find_element(by=By.CLASS_NAME,value='类名')
bro.find_element(by=By.TAG_NAME,value='标签名')
bro.find_element(by=By.NAME,value='属性name')
------"""通用查找"""------
bro.find_element(by=By.CSS_SELECTOR,value='css选择器')
bro.find_element(by=By.XPATH,value='xpath选择器')
2. 获取标签位置,大小
my_tag = bor.find_element(by=By.ID, value="")
print(my_tag.location) # 获取标签所在的位my_tag置
print(my_tag.size) # 获取标签的大小
-------
print(my_tag.tag_name)
print(my_tag.id)
3. 模拟键盘点击
# 导入
from selenium.webdriver.common.keys import Keys
# 使用
my_tag.send_keys(Keys.键盘对用的英文) # ENTER (回车键) TAB (tab键) 。。。
12.6 执行 js 代码 >>> execute_script
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('https://www.jd.com/')
1. 打印了cookie
bro.execute_script('alert(document.cookie)')
2. 滚动页面,到最底部
# 一点点滑动
for i in range(10):
y=400*(i+1)
bro.execute_script('scrollTo(0,%s)'%y)
time.sleep(1)
# 一次性直接滑动到最底部
bro.execute_script('scrollTo(0,document.body.scrollHeight)')
time.sleep(3)
bro.close()
12.7 切换标签页
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('https://www.jd.com/')
# 使用js打开新的选项卡
bro.execute_script('window.open()')
# 切换到这个选项卡上,刚刚打开的是第一个
bro.switch_to.window(bro.window_handles[1])
bro.get('http://www.taobao.com')
time.sleep(2)
bro.switch_to.window(bro.window_handles[0])
time.sleep(3)
bro.close()
bro.quit()
12.8 浏览器前进后退
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
bro.get('https://www.jd.com/')
time.sleep(2)
bro.get('https://www.taobao.com/')
time.sleep(2)
bro.get('https://www.baidu.com/')
# 后退一下
bro.back()
time.sleep(1)
# 前进一下
bro.forward()
time.sleep(3)
bro.close()
12.9 网站案例--> 获取设置cookie
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import json
# bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# bro.get('https://www.cnblogs.com/')
# bro.implicitly_wait(10)
"""-----------------------------获取 cookie-------------------------------------"""
try:
# 找到登录按钮
submit_btn = bro.find_element(By.LINK_TEXT, value='登录')
submit_btn.click()
time.sleep(1)
username = bro.find_element(By.ID, value='mat-input-0')
password = bro.find_element(By.ID, value='mat-input-1')
username.send_keys("********") # 用户名
password.send_keys('********') # 密码
submit = bro.find_element(By.CSS_SELECTOR,
value='body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
time.sleep(20)
submit.click()
# 获取 cookie
cookie = bro.get_cookies()
print(cookie)
with open('cnblogs.json', 'w', encoding='utf-8') as f:
json.dump(cookie, f)
time.sleep(5)
except Exception as e:
print(e)
finally:
bro.close()
"""-----------------------------设置 cookie-------------------------------------"""
time.sleep(3)
# 把本地的cookie写入,就登录了
with open('cnblogs.json', 'r', encoding='utf-8') as f:
cookie = json.load(f)
for item in cookie:
# 设置 cookie
bro.add_cookie(item)
# 刷新一下页面
bro.refresh()
time.sleep(10)
bro.close()
12.10 动态连
方式一: 直接拖动过去
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 动作链
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import time
# 实例化一个浏览器对象
path = Service('./chromedriver.exe')
# 创建浏览器操作对象
bro = webdriver.Chrome(service=path)
# 测试的网址
bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 隐式等待
bro.implicitly_wait(10)
try:
"""
1. 如果定位的标签是存在于iframe标签之中,在定位前必须先执行以下操作
2. iframe 是一个html标签, 里边还可以再放一个 html 文本内容, 所以一般不会遇到
"""
bro.switch_to.frame('iframeResult')
# 获取两个对应的标签
course = bro.find_element(by=By.ID, value='draggable')
target = bro.find_element(by=By.ID, value='droppable')
actions = ActionChains(bro) # 拿到动作链对象
actions.drag_and_drop(course, target) # 将 course 移动到 target 上
actions.perform() # 代表鼠标点击和松开, 即完成动作
except Exception as e:
print(e)
time.sleep(2)
方式二: 慢慢移动过去
具体见方式一
try:
# 如果定位的标签是存在于iframe标签之中,在定位前必须先执行以下操作
# iframe 是一个html标签, 里边还可以再放一个 html 文本内容, 所以一般不会遇到
bro.switch_to.frame('iframeResult')
# 获取两个对应的标签
course = bro.find_element(by=By.ID, value='draggable')
target = bro.find_element(by=By.ID, value='droppable')
ActionChains(bro).click_and_hold(course).perform()
distance = target.location['x'] - course.location['x']
track = 0
while track < distance:
ActionChains(bro).move_by_offset(xoffset=20, yoffset=0).perform()
track += 20
12.11 打码平台
1. pillow 模块下载
pip3 install pillow
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver import ActionChains # 动作链
from selenium.webdriver.common.by import By
from PIL import Image
import time
# 实例化一个浏览器对象
path = Service('./chromedriver.exe')
# 创建浏览器操作对象
bro = webdriver.Chrome(service=path)
bro.get('http://www.chaojiying.com/apiuser/login/')
bro.maximize_window()
bro.implicitly_wait(10)
try:
# 保存浏览器的整张图片
bro.save_screenshot('main.png')
# 2 使用pillow,从整个页面中截取出验证码图片 code.png
img = bro.find_element(by=By.CSS_SELECTOR, value='body > div.wrapper_danye > div > div.content_login > div.login_form > form > div > img')
location = img.location
size = img.size
# 小图片的其实位置和终止位置
img_tu = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
#打开
img = Image.open('./main.png')
# 抠图
fram = img.crop(img_tu)
# 保存截出来的小图
fram.save('code.png')
except Exception as e:
print(e)
time.sleep(2)
12.12 xpath 基本语法
语法规则
| 语法 | 作用 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
标签定位
| 语法 | 作用 |
|---|---|
| /html/body/div | 表示从根节点开始查找 |
| /html//div | 表示多个层级 作用于两个标签之间(也可以理解为在html下进行匹配寻找标签div) |
| //div | 从任意节点开始寻找,也就是查找所有的div标签 |
| ./div | 表示从当前的标签开始寻找div |
| /text() | 获取标签下直系的标签内容 |
| //text() | 获取标签中所有的文本内容 |
| string() | 获取标签中所有的文本内容 |
属性定位
| 语法 | 作用 |
|---|---|
| @属性名=属性值 | 通过属性定位到标签 |
| /a[@href="image1.html"] | 定位属性 href 为 image1.html 的 a 标签 |
12.13 使用案例
文档结构
doc = """
<html>
<head>
<base href='http://example.com/'/>
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html' id='id_a'>Name: My image 1 <br/><img src='image1_thumb.jpg'/></a>
<a href='image2.html'>Name: My image 2 <br/><img src='image2_thumb.jpg'/></a>
<a href='image3.html'>Name: My image 3 <br/><img src='image3_thumb.jpg'/></a>
<a href='image4.html'>Name: My image 4 <br/><img src='image4_thumb.jpg'/></a>
<a href='image5.html' class='li li-item' name='items'>Name: My image 5 <br/><img src='image5_thumb.jpg'/></a>
<a href='image6.html' name='items'><span><h5>test</h5></span>Name: My image 6 <br/><img src='image6_thumb.jpg'/></a>
</div>
</body>
</html>
"""
准备工作
# 下载
pip install lxml
# 导入
from lxml import etree
bro = etree.HTML(doc)
res = bro.xpath('xpath选择器')
print(res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号