
apscheduler ---> celery 定时任务平替框架
1. APscheduler简介
APscheduler全称Advanced Python Scheduler,作用为在指定的时间规则执行指定的作业,其是基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个python定时任务系统。
2. APscheduler安装
pip install apscheduler
3. APscheduler 组成部分
1. 触发器(trigger)
包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。
2. 任务存储(job store)
存储被调度的任务,默认的任务存储是简单地把任务保存在内存中,其他的任务存储是将任务保存在数据库中。一个任务的数据讲在保存在持久化任务存储时被序列化,并在加载时被反序列化。调度器不能分享同一个任务存储。
1. MemoryJobStore :没有序列化,任务存储在内存中,增删改查都是在内存中完成。
2. SQLAlchemyJobStore :使用 SQLAlchemy 这个 ORM 框架作为存储方式。
3. MongoDBJobStore :使用 mongodb 作为存储器。
4. RedisJobStore :使用 redis 作为存储器。
3. 执行器(executor)
用于执行任务,可以设定执行模式为单线程或线程池:任务会被执行器放入线程池或进程池去执行,执行完毕后,执行器会通知调度器。>用于执行任务,可以设定执行模式为单线程或线程池:任务会被执行器放入线程池或进程池去执行,执行完毕后,执行器会通知调度器。
处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
1. ThreadPoolExecutor :线程池执行器。
2. ProcessPoolExecutor :进程池执行器。
3. GeventExecutor : Gevent 程序执行器。
4. TornadoExecutor :Tornado 程序执行器。
5. TwistedExecutor :Twisted 程序执行器。
6. AsyncIOExecutor : asyncio 程序执行器。
4. 调度器(scheduler)
把上方三个组件作为参数,通过创建调度器实例来运行: 一个调度器由上方三个组件构成,一般来说,一个程序只要有一个调度器就可以了。开发者也不必直接操作任务储存器、执行器以及触发器,因为调度器提供了统一的接口,通过调度器就可以操作组件,比如任务的增删改查
任务调度器是属于整个调度的总指挥官。他会合理安排作业存储器、执行器、触发器进行工作,并进行添加和删除任务等。调度器通常是只有一个的。开发人员很少直接操作触发器、存储器、执行器等。因为这些都由调度器自动来实现了。
1. BlockingScheduler :适用于调度程序是进程中唯一运行的进程,调用 start 函数会阻塞当前线程,不能立即返回。
2. BackgroundScheduler :适用于调度程序在应用程序的后台运行,调用 start 后主线程不会阻塞。
3. AsyncIOScheduler :适用于使用了 asyncio 模块的应用程序。
4. GeventScheduler :适用于使用 gevent 模块的应用程序。
5. TwistedScheduler :适用于构建 Twisted 的应用程序。
6. QtScheduler :适用于构建 Qt 的应用程序。
4. Scheduler工作流程图
-
4.1 Scheduler添加job流程
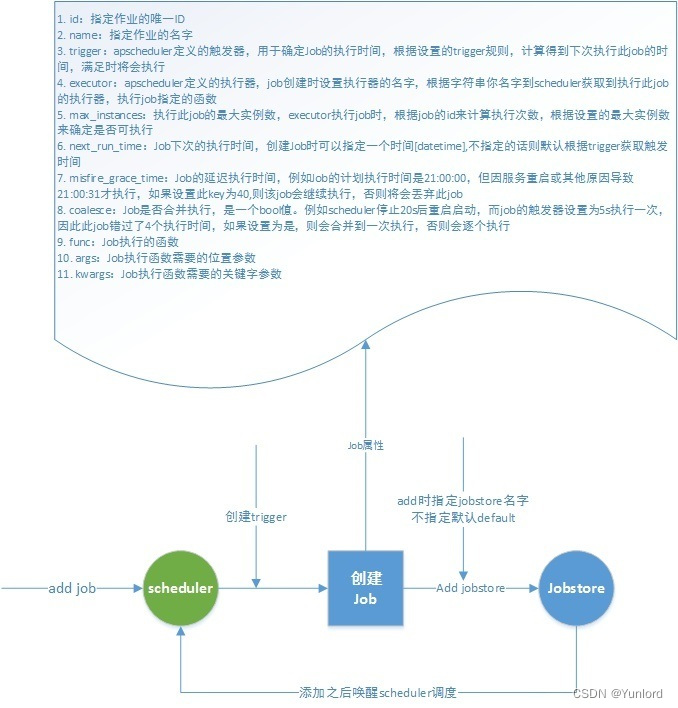
-
4.2 Scheduler调度流程
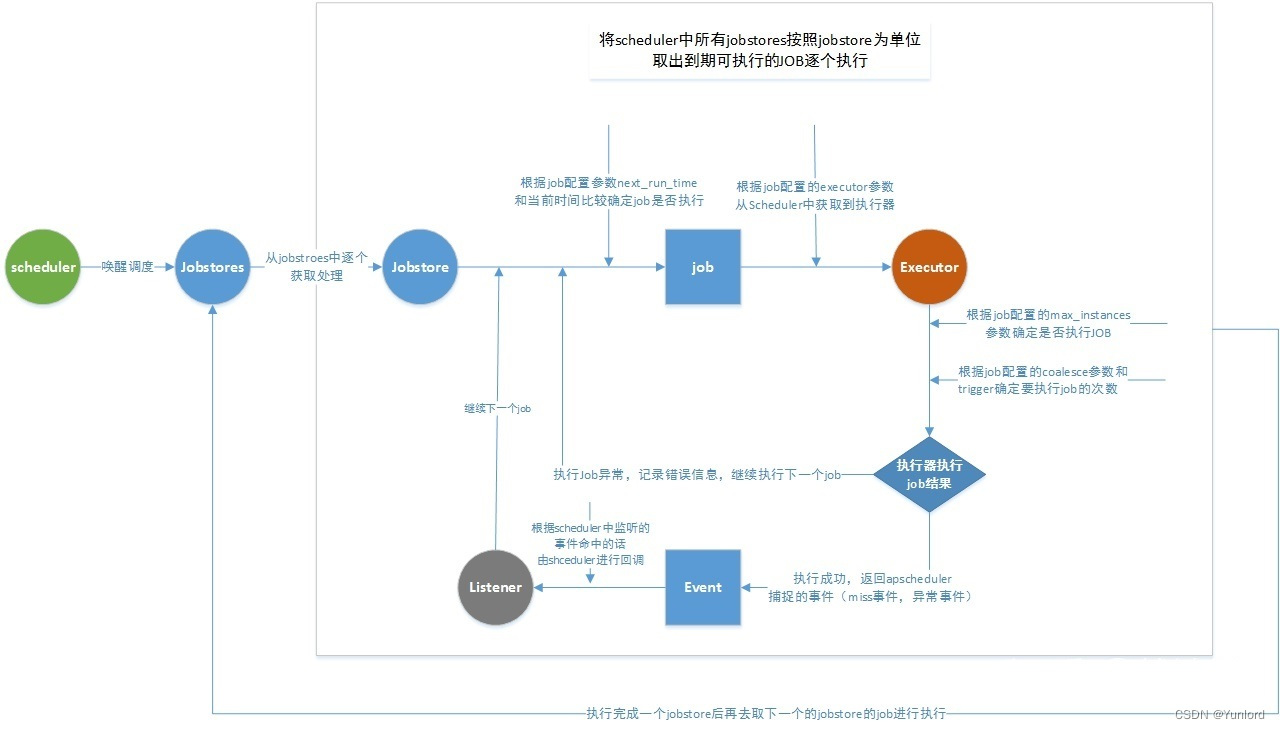
5. APscheduler使用
-
5.1 基本使用
import time
from apscheduler.schedulers.blocking import BlockingScheduler
aps = BlockingScheduler()
def my_job(i):
print(i)
aps.add_job(my_job, 'interval', seconds=2, args=['运行成功!'])
aps.start()
-
5.2 定时任务 调度配置
1、执行器:配置 default 执行器为 ThreadPoolExecutor ,并且设置最多的线程数是x个。
2、存储器:本系统采用默认存储在运行内存中管理
3、任务配置:
3.1 coalesce = True,设置这个目的是,比如由于某个原因导致某个任务积攒了很多次没有执行(比如有一个任务是1分钟跑一次,但是系统原因断了5分钟),如果 coalesce = True ,那么下次恢复运行的时候会只执行一次,而如果设置 coalesce = False ,那么就不会合并会5次全部执行。
3.2 max_instances = 5,同一个任务同一时间最多只能有5个实例在运行。比如一个耗时10分钟的job,被指定每分钟运行1次,如果我 max_instance 值5,那么在第 6 ~ 10 分钟上,新的运行实例不会被执行,因为已经有5个实例在跑了。
6. 触发器
-
6.1 date 内置触发器
| 参数 | 说明 |
|---|---|
| run_date (datetime 或 str) | 作业的运行日期或时间 |
| timezone (datetime.tzinfo 或 str) | 指定时区 |
| coalesce | 解释:见 5.2 |
| max_instances | 解释:见 5.2 |
from datetime import date, datetime
from apscheduler.schedulers.blocking import BlockingScheduler
# timezone 指定时区
aps = BlockingScheduler(timezone='Asia/Shanghai')
# 任务
def my_job(i):
print(i)
# 在 2023-4-30 运行一次 my_job 方法
aps.add_job(my_job, 'date', run_date=date(2022, 4, 9), args=['text1'], id="1", coalesce=True, max_instances=1)
# 在 2023-4-30 13:41:00 运行一次 my_job 方法
aps.add_job(my_job, 'date', run_date=datetime(2023, 4, 30, 13, 41, 00), args=['text2'], id="2", coalesce=True, max_instances=1)
# 在 2023-4-30 13:41:00 运行一次 my_job 方法
aps.add_job(my_job, 'date', run_date='2023-4-30 13:41:00', args=['text3'], id="3", coalesce=True, max_instances=1)
aps.start()
-
6.2 interval 触发器
| 参数 | 说明 |
|---|---|
| weeks (int) | 间隔几周 |
| days (int) | 间隔几天 |
| hours (int) | 间隔几小时 |
| minutes (int) | 间隔几分钟 |
| seconds (int) | 间隔多少秒 |
| start_date (datetime 或 str) | 开始日期 |
| end_date (datetime 或 str) | 结束日期 |
| timezone (datetime.tzinfo 或str) | 时区 |
import time
from apscheduler.schedulers.blocking import BlockingScheduler
def job(text):
t = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print('{} --- {}'.format(text, t))
scheduler = BlockingScheduler()
# 三秒触发一次
scheduler.add_job(job, 'interval', seconds=3, args=["desire"])
scheduler.start()
6.3 cron 触发器 在特定时间周期性地触发,和Linux crontab格式兼容。它是功能最强大的触发器
| 参数 | 说明 |
|---|---|
| year (int 或 str) | 年,4位数字 |
| month (int 或 str) | 月 (范围1-12) |
| day (int 或 str) | 日 (范围1-31) |
| week (int 或 str) | 周 (范围1-53) |
| day_of_week (int 或 str) | 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun) |
| hour (int 或 str) | 时 (范围0-23) |
| minute (int 或 str) | 分 (范围0-59) |
| second (int 或 str) | 秒 (范围0-59) |
| start_date (datetime 或 str) | 最早开始日期(包含) |
| end_date (datetime 或 str) | 最晚结束时间(包含) |
| timezone (datetime.tzinfo 或str) | 指定时区 |
| 表达式 | 参数类型 | 描述 |
|---|---|---|
| * | 所有 | 通配符。例:minutes=*即每分钟触发 |
| */a | 所有 | 可被a整除的通配符 |
| a-b | 所有 | 范围a-b触发 |
| a-b/c | 所有 | 范围a-b,且可被c整除时触发 |
| xth y | 日 | 第几个星期几触发。x为第几个,y为星期几 |
| last x | 日 | 一个月中,最后个星期几触发 |
| last | 日 | 一个月最后一天触发 |
| x,y,z | 所有 | 组合表达式,可以组合确定值或上方的表达式 |
import time
from apscheduler.schedulers.blocking import BlockingScheduler
def job(text):
t = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print('{} --- {}'.format(text, t))
scheduler = BlockingScheduler()
# 在每天22点,每隔 1分钟 运行一次 job 方法
scheduler.add_job(job, 'cron', hour=22, minute='*/1', args=['job1'])
# 在每天22和23点的25分,运行一次 job 方法
scheduler.add_job(job, 'cron', hour='22-23', minute='25', args=['job2'])
# 在每天 8 点,运行一次 job 方法
scheduler.add_job(job, 'cron', hour='8', args=['job2'])
# 在每天 8 点 20点,各运行一次 job 方法 设置最大运行实例数
scheduler.add_job(job, 'cron', hour='8, 20', minute=30, max_instances=4)
scheduler.start()
7. 任务操作
1. 添加任务:
scheduler.add_job(job_obj,args,id,trigger,**trigger_kwargs)。
2. 删除任务:
scheduler.remove_job(job_id,jobstore=None)。
3. 暂停任务:
scheduler.pause_job(job_id,jobstore=None)。
4. 恢复任务:
scheduler.resume_job(job_id,jobstore=None)。
5. 修改某个任务属性信息:
scheduler.modify_job(job_id,jobstore=None,**changes)。
6. 修改单个作业的触发器并更新下次运行时间:
scheduler.reschedule_job(job_id,jobstore=None,trigger=None,**trigger_args)
7. 输出作业信息:
scheduler.print_jobs(jobstore=None,out=sys.stdout)
参考文章:https://blog.csdn.net/qq_25305833/article/details/127169521
参考文章:https://blog.csdn.net/weixin_44301439/article/details/124062178
参考文章:https://blog.csdn.net/kobepaul123/article/details/123616575

 浙公网安备 33010602011771号
浙公网安备 33010602011771号