用python做一个C类编译器——语法翻译器
本文2017年首发自本人原独立站点,后来疲于生活,不想折腾个人独立站点,将文章搬运自博客园
编程语言:Python 3.7
项目地址:python做编译器——语法翻译器
编程平台:manjaro
编程环境:vscode
完成的内容:承接上次的词法分析器,将其输出的字符表转成一个语法树,并完成四元式的转换。
采用的方法:自上而下的递归方式
具体实现的语法:
语法树支持:变量声明语句,赋值语句,输出语句,程序块
四元式支持:变量声明语句,四则表达式的赋值语句。
文件结构
词法分析见我的上一篇文章python做编译器——词法分析
除去之前完成的词法分析器,本语法分析程序共涉及1个文件,四元式转化涉及一个文件 现将其说明如下:
- parser.py 语法分析程序
- generate.py 语法分析程序
文法说明
刚开始很难自己写出一个完整的语法产生式,后来借鉴网上的语法产生式,自己对其一点一点扩展,最终形成适合自己程序的语法产生式。下面先给出一个四则运算的文法
Expr -> Term ExprTail
ExprTail -> + Term ExprTail
| - Term ExprTail
| null
Term -> Factor TermTail
TermTail -> * Factor TermTail
| / Factor TermTail
| null
Factor -> (Expr)
| num
将其用python代码实现,用一个字典存储该文法,每个产生式的左部作为字典的“键“,而产生式右部存储在该键值所对应的数组中中。实现如下
grammars = {
"E": ["T ET"],
"ET": ["+ T ET", "- T ET", "null"],
"T": ["F TT"],
"TT": ["* F TT", "/ F TT", "null",],
"F": ["NUMBER", "BRA"],
"BRA": ["( E )",],
"END_STATE":r"(null)|(NUMBER)|(ID)|[+-*/=]|(LBRA)|(RBRA)"
}
可以看出,每个产生式左部键值对应的数组内容为相应的右部内容。END_STATE为终结符集合
之后自己对其进行扩展,改成自己想要的文法。该文法从主函数program开始解析,自上而下分解多条语句,声明语句,赋值语句,四则运算与输出语句
grammars = {
"Program":["keyword M C Pro"],
"C":["( cc )"],
"cc":["null"],
"Pro":["{ Pr }"],
"Pr":["P ; Pr", "null"],
"P":["keyword L", "L","printf OUT"],
"L":["M = E", "M"],
"M":["name"],
"E":["T ET"],
"ET":["+ T ET", "- T ET", "null"],
"T":["F TT"],
"TT":["* F TT", "/ F TT", "null"],
"F":["number", "BRA"],
"BRA": ["( E )"],
"OUT":["( " TEXT " , V )"],
"V":["name VV", "null"],
"VV":[", name VV", "null"],
"END_STATE": r"(null)|(number)|(name)|(keyword)|(operator)|(printf)|(separator)|(TEXT)|[+-*/=;,")({}]"
}
语法分析器
词法分析器接受一个由词法分析器产生的字符表, 之后从全局的文法字典中获取第一个文法根节点,开始自上而下的递归分析, 分析方法是: 对于非终结符, 继续在文法字典中查询相对应的关键字,并切割其所有遍历到的字符串,每个字符串被切割成的字符数组将作为该非终结符的潜在子节点,挨个进行递归并生成语法树子节点。对于终结符,进行匹配,若终结符类型存在于终结符表中,则匹配成功,反之报错。
def build_ast(tokens):
root = Node("Program")
offset = root.build_ast(tokens, token_index=0)
if offset == len(tokens):
return root
else:
raise ValueError("Error Grammar4")
class Node:
def match_token(self, token):
token_type = token["type"]
token_word = token["word"]
if self.type == "null" or self.type == token_type or self.type == token_word:
return True
return False
def __init__(self, type):
self.type = type
self.text = None
self.child = list()
def build_ast(self, tokens: list, token_index=0):
if re.match(grammars["END_STATE"], self.type):
if self.type != "null":
if token_index >= len(tokens):
raise ValueError("Error Grammar1")
if self.match_token(tokens[token_index]):
self.text = tokens[token_index]["word"]
# print(self.text, token_index)
else:
raise ValueError("Error Grammar2")
return 1
return 0
for grammar in grammars[self.type]:
offset = 0
grammar_tokens = grammar.split()
tmp_nodes = list()
try:
for grammar_token in grammar_tokens:
node = Node(grammar_token)
tmp_nodes.append(node)
offset += node.build_ast(tokens, offset+token_index)
else:
self.child = tmp_nodes
return offset
except ValueError:
pass
raise ValueError("Error Grammar3")
四元式产生器
简而言之,对一个语法树进行遍历,遍历过程中遇到相应节点进行相应的处理。我的四元式产生器任然使用递归方法实现,目前仅实现了声明语句,赋值语句和四则混合运算。
class Mnode:
def __init__(self, op="undefined", a1=None, a2=None, re=None):
self.op = op
self.arg1 = a1
self.arg2 = a2
self.re = re
def __str__(self):
return "({0},{1},{2},{3})".format(self.op, self.arg1, self.arg2, self.re)
def __repr__(self):
return self.__str__()
"""
两个全局 mid_result 存放四元式对象
tmp记录零时变量id
"""
mid_result = []
tmp = 0
"""递归遍历语法树"""
def view_astree(root, ft=None):
if root == None or root.text == "(" or root.text == ")":
return
# 返回终结符叶子节点
elif len(root.child) == 0 and root.text != None:
return root.text
global mid_result
global tmp
""" 下面的代码参照该文法
"L":["M = E", "M"],
"M":["name"],
"E":["T ET"],
"ET":["+ T ET", "- T ET", "null"],
"T":["F TT"],
"TT":["* F TT", "/ F TT", "null"],
"""
"""变量声明语句,两种情况(直接赋值,不赋值)"""
if root.type == "L":
if len(root.child) == 1:
mid_result.append(Mnode("=",0,0,view_astree(root.child[0])))
else:
mid_result.append(Mnode("=",view_astree(root.child[2]),0,view_astree(root.child[0])))
"""右递归处理"""
elif root.type == "ET" or root.type == "TT":
if len(root.child) > 1:
"""临时变量"""
t = "T" + str(tmp)
tmp += 1
"""ft 为父节点传入的操作符左边部分临时"""
mid_result.append(Mnode(view_astree(root.child[0]), view_astree(root.child[1]), ft,t))
ct = view_astree(root.child[2], t)
if ct != None:
return ct
return t
elif root.type == "E" or root.type == "T":
if len(root.child[1].child) > 1:
t = "T" + str(tmp)
tmp += 1
mid_result.append(Mnode(view_astree(root.child[1].child[0]), view_astree(root.child[0]), view_astree(root.child[1].child[1]),t))
ct = view_astree(root.child[1].child[2], t)
if ct != None:
return ct
return t
else:
return view_astree(root.child[0])
elif len(root.child) == 1:
return view_astree(root.child[0])
else:
re = ""
for c in root.child:
cre = view_astree(c)
if cre != None:
re = cre
return re
运行代码
运行环境:python3(若使用python2会发生编码错误)
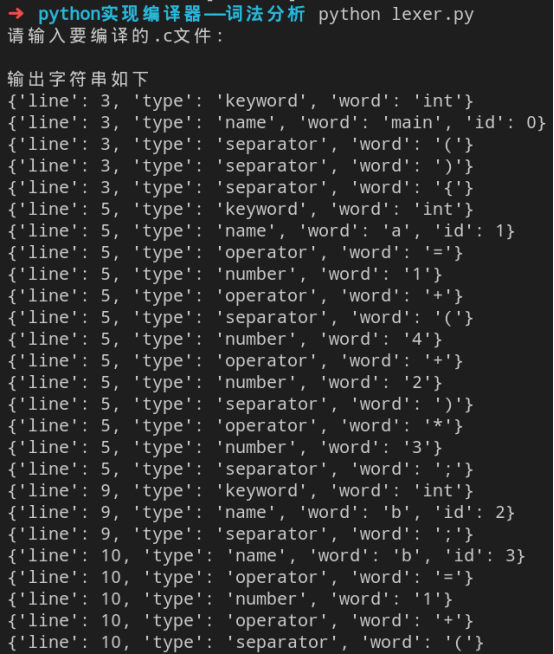
输出词法分析结果
python lexer.py
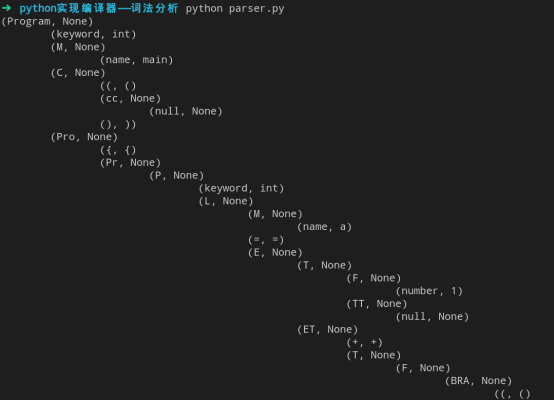
输出语法树
python parser.py
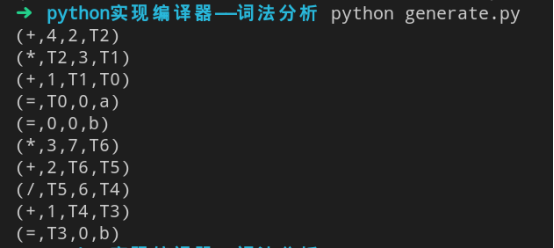
输出四元式
python generate.py
最后
使用自上而下的递归方法做抽象语法树相对来说还是比较简单的,然而对于性能来说确实十分糟糕,虽然目前编译的小代码不会有太大延迟,但是代码量一多肯定还是会有很大的时间代价。
另外四元式的递归生成感觉代码写的还是比较笨重,为了达成目的而写的代码,不优雅,不美观,可读性差,,自己写的时候也把自己绕晕了,递归使用的太多,逻辑上的可读性非常差,需要仔细读才能看懂代码意思,可能过段时间自己也看不懂了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号