1.5.5 HDFS读写解析-hadoop-最全最完整的保姆级的java大数据学习资料
1.5.5 HDFS读写解析
1.5.5.1 HDFS读数据流程
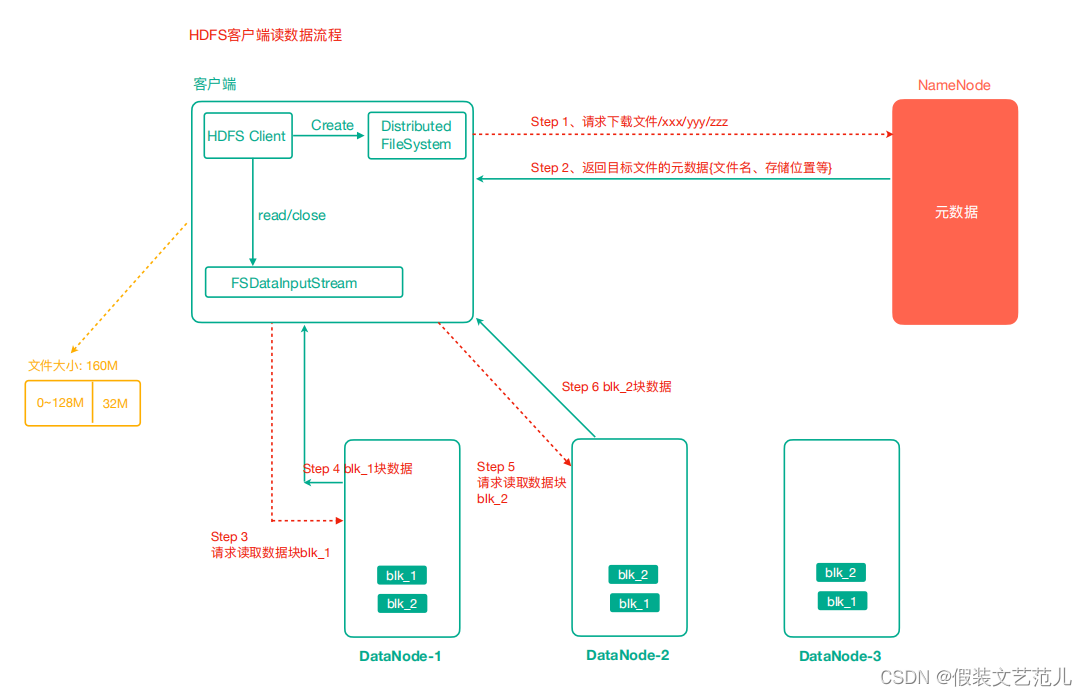
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据, 找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
1.5.5.2 HDFS写数据流程
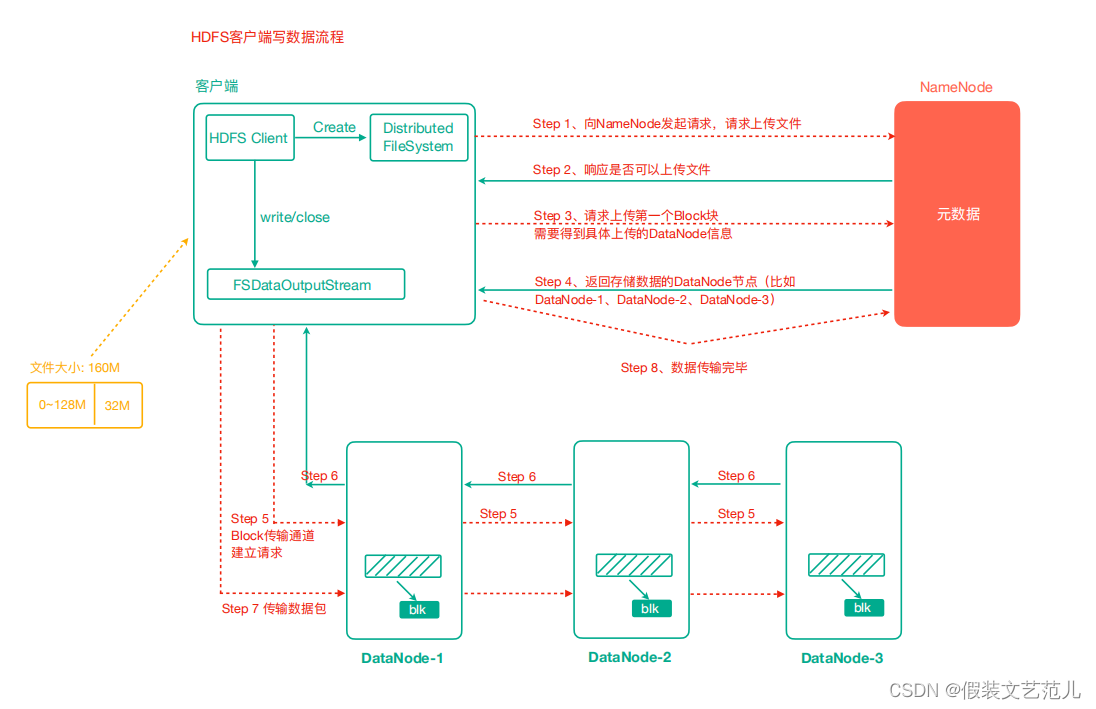
-
客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
-
NameNode返回是否可以上传。
-
客户端请求第一个 Block上传到哪几个DataNode服务器上。
-
NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
-
客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
-
dn1、dn2、dn3逐级应答客户端。
-
客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列等待确认。
-
当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行 3-7步)。
验证Packet代码
@Test
public void testUploadPacket() throws IOException {
//1 准备读取本地文件的输入流
final FileInputStream in = new FileInputStream(new File("e:/lagou.txt"));
//2 准备好写出数据到hdfs的输出流
final FSDataOutputStream out = fs.create(new Path("/lagou.txt"), new Progressable() {
public void progress () { //这个progress方法就是每传输64KB(packet)就会执行一次,
System.out.println("&");
}
});
//3 实现流拷贝
IOUtils.copyBytes(in, out, configuration); //默认关闭流选项是true,所以会自动 关闭
//4 关流 可以再次关闭也可以不关了
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号