如何为Spark应用程序分配--num-executors,--execuor-cores和--executor-memory
转载于:https://www.cnblogs.com/lestatzhang/p/10611321.html
前言
在我们提交spark程序时,应该如何为Spark集群配置–num-executors, - executor-memory和–execuor-cores 呢?
一些资源参数设置的基本知识
- Hadoop / Yarn / OS Deamons
当我们使用像Yarn这样的集群管理器运行spark应用程序时,会有几个守护进程在后台运行,如NameNode,Secondary NameNode,DataNode,JobTracker和TaskTracker等。因此,在指定num-executors时,我们需要确保为这些守护进程留下足够的核心(至少每个节点约1 CPU核)以便顺利运行。 - Yarn ApplicationMaster(AM)
ApplicationMaster负责协调来自ResourceManager的资源,并与NodeManagers一起执行container并监控其资源消耗。如果我们在YARN上运行Spark,那么我们需要预估运行AM所需要的资源(至少1024MB和1 CPU核)。 - HDFS吞吐量
HDFS客户端遇到大量并发线程会出现一些bug。一般来说,每个executors最多可以实现5个任务的完全写入吞吐量,因此最好将每个executors的核心数保持在该数量之下。 - MemoryOverhead
JVM还需要一些off heap的内存,请参考下图中描绘的Spark和YARN中内存属性的层次结构,
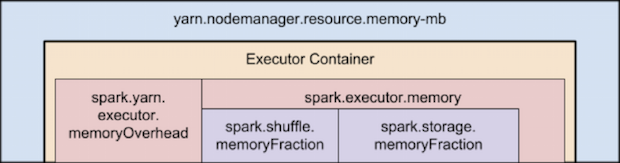
简单来说,有以下两个公式:
例如当我设置 --executor-memory=20时, 我们实际请求了
运行具有executors大内存的通常会导致过多的GC延迟。
运行较小的executors(例如,1G & 1 CPU core)则会浪费 单个JVM中运行多个任务所带来的优点。
不同配置的优劣分析
现在,假设我们的集群配置如下
10 Nodes
16 cores per Node
64GB RAM per Node
第一种方法:使用较小的executors
`--num-executors` = `在这种方法中,我们将为每个核心分配一个executor`
= `集群的总核心数`
= `每个节点的核心数 * 集群的总节点数`
= 16 x 10 = 160
`--executor-cores` = 1 (`每个executor分配的核心数目`)
`--executor-memory` = `每个executor分配的内存数`
= `每个节点内存总数数/每个节点上分配的executor数`
= 64GB/16 = 4GB
分析:
由于每个executor只分配了一个核,我们将无法利用在同一个JVM中运行多个任务的优点。 此外,共享/缓存变量(如广播变量和累加器)将在节点的每个核心中复制16次。 最严重的就是,我们没有为Hadoop / Yarn守护程序进程留下足够的内存开销,我们还忘记了将ApplicationManagers运行所需要的开销加入计算。
第二种方法:使用较大的executors
`--num-executors` = `在这种方法中,我们将为每个节点分配一个executor`
= `集群的总节点数`
= 10
`--executor-cores` = `每个节点一个executor意味着该节点的所有核心都分配给一个执executor`
= `每个节点的总核心数`
= 16
`--executor-memory` = `每个executor分配的内存数`
= `每个节点内存总数数/每个节点上分配的executor数`
= 64GB/1 = 64GB
分析:
每个executor都有16个核心,由于HDFS客户端遇到大量并发线程会出现一些bug,即HDFS吞吐量会受到影响。同时过大的内存分配也会导致过多的GC延迟。
第三种方法:使用优化的executors
- 基于上面提到的建议,让我们为每个执行器分配5个核心, 即
--executor-cores = 5 - 为每个节点留出1个核心用于Hadoop / Yarn守护进程, 即每个节点可用的核心数 = 16-1 = 15。 因此,群集中核心的可用总数= 15 x 10 = 150
- –num-executors =(群集中核心的可用总数/每个executors分配的核心数)= 150/5 = 30
- 为ApplicationManager留下预留1个executors的资源, 即
--num-executors = 29 - 每个节点的executors数目 = 30/10 = 3
- 群集中每个节点的可使用的总内存数 64GB - 1GB = 63GB
- 每个executor的内存= 64GB / 3 = 21GB
- 预留的 off heap overhead = 21GB * 7% ~ 1.47G
- 所以,实际的
--executor-memory = 21 - 1.47G ~ 19GB
参考资料
how-to-tune-your-apache-spark-jobs-part-2
distribution_of_executors_cores_and_memory_for_spark_application

 浙公网安备 33010602011771号
浙公网安备 33010602011771号