BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View阅读小结
BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
BEVDet 高性能多相机鸟瞰视图3D目标检测
论文概述
BEVDet是一种模块化设计的3D目标检测框架,以鸟瞰视图 (Bird-Eye-View, BEV) 执行3D目标检测,通过现有模块构建其框架,并通过定制数据增强策略和优化非极大值抑制策略,大幅提升检测性能。BEVDet在nuScenes验证集上表现出色,BEVDet-Tiny版本仅占用215.3 GFLOPs,速度比FCOS3D快9.2倍。BEVDet-Base版本则在精确度上大幅领先。
相关工作
-
2D感知:
- 图像分类
- 深度学习尤其以AlexNet为起点推动了图像分类任务的发展。
- 后续的研究引入了多种结构,如残差网络、高分辨率网络、注意力机制等,这些进步不仅提升了图像编码能力,还促进了对象检测、语义分割等任务的性能提升。
- Softmax及其衍生方法在图像分类中占据主导地位,网络结构的容量是关键研究焦点。
- 目标检测:
- 介绍两阶段方法(如Faster R-CNN)和一阶段方法(如RetinaNet)的对比,以及它们的衍生工作。
- 强调多任务学习,特别是通过共享骨干网络和联合训练,对于提高效率和任务性能的重要性。
- 指出在自动驾驶场景中,寻找更高效的多任务处理方法的必要性。
-
BEV中的语义分割:
- 自动驾驶中,通过在BEV空间语义分割用于环境的矢量重建。
- 基于视觉的方法通常包括图像视图编码、视图变换到BEV、BEV中的进一步编码和像素级分类(image-view encoder, a view transformer, a BEV encoder and a head)。
- 这一框架的成功促使研究者探索其在3D目标检测中的应用潜力。
-
基于视觉的3D目标检测:
- 从单目3D检测到基于多摄像头系统的转变,以及相关基准(如KITTI、其他大规模数据集)对研究的推动。
- 强调了现有方法的局限性,特别是在计算效率和精度的权衡上。
- FCOS3D:得益于目标与图像外观之间强大的空间相关性,它在预测该方面表现良好,但在感知目标的平移、速度和方向方面相对较差。
- DETR3D:预算只需FCOS3D一半,推理速度和FCOS3D相同。
- PGD:通过搜索和解决突出的缺点(即目标的深度预测)进一步发展FCOS3D范式,提升精读,但计算成本增加推理速度变慢。
- 一些方法如基于Lift-Splat-Shoot的改进,特别是本文提出的改进策略,通过不依赖LiDAR而基于视图转换器解耦效应的专有数据增强策略,优化BEV中的3D对象检测。
主要贡献
- 模块化设计:包括图像视图编码器、视图转换器、BEV编码器及任务特定的检测头。
- 定制的数据增强策略:在图像视图和BEV空间中应用不同的增强策略,应对过拟合问题。
- 改进的非极大值抑制策略 (Scale-NMS):移除顺序执行的运算符sequentially executed operators,加快推理过程。
- 实验验证:在nuScenes数据集上取得了领先的性能,并展开消融实验验证数据增强策略和不同分辨率对模型性能的影响。
在验证可行性时,BEVDet数据处理策略和参数数量被设置为接近image-view-based 3D object detector(FCOS3D, PGD),但在训练时出现过拟合问题。BEVDet在BEV空间中过拟合的部分原因是训练数据的不足。
在没有BEV encoder的情况下,对image view space使用LSS的数据增强策略实现正则化效果有积极作用;而在有BEV encoder的情况反而会降低性能(因为view transformer以像素级的方式将图像视图空间与 BEV 空间连接,从数据增强的角度将它们解耦,image view space的数据增强策略对BEV encoder and the 3D object detection head没有正则化效果)。因此在 BEV Space中进行了翻转、缩放和旋转(flipping, scaling, and rotating)等额外数据增强操作,以提高模型在这些方面的鲁棒性,有助于防止 BEVDet 过度拟合。
方法论
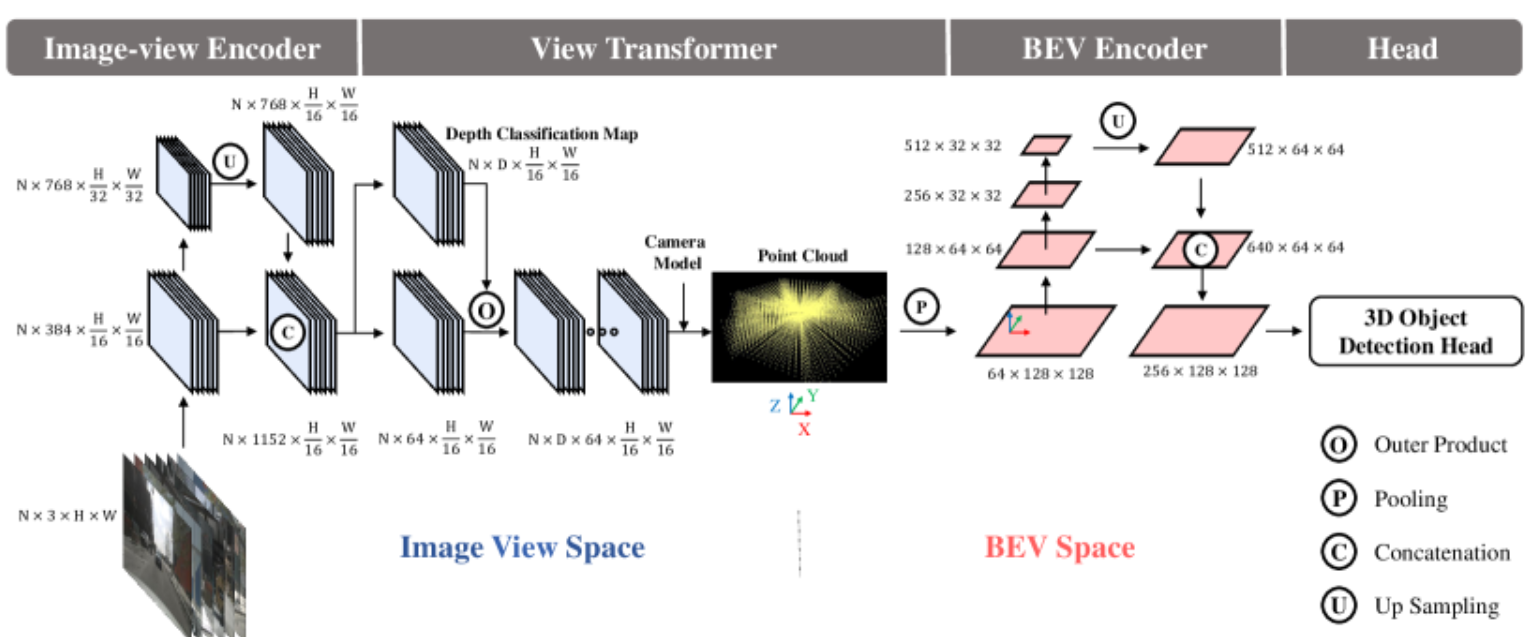
网络结构
- 图像视图编码器Image-view Encoder:采用ResNet(或SwinTransformer)作为主干进行high-level特征提取;颈部FPN(FPN-LSS)用于多分辨率特征融合,将具有 1/32 输入分辨率的特征upsamples 上采样到 1/16 输入分辨率,并将其与主干生成的特征进行concatenates连接。
- 视图转换器View Transformer:将图像视图特征作为输入(LSS,通过分类方式密集预测深度),将分类分数和导出特征用于渲染预定义点云。最后通过Z轴反向(垂直)进行池化来生成BEV特征。
- BEV编码器BEV Encoder:在BEV空间进一步编码特征(ResNet + FPN-LSS),感知目标的尺度、方向和速度等信息(定义在BEV空间)。
- 检测头Head:基于BEV特征执行3D目标检测,使用CenterPoint的第一阶段的3D目标检测头进行原型验证。
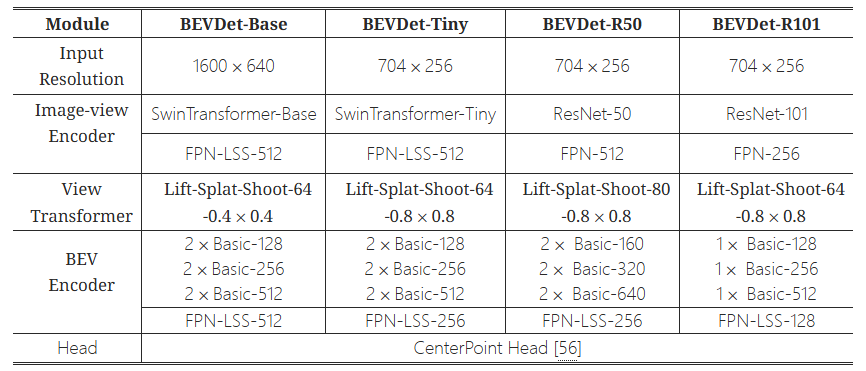
数据增强策略
因为View Transformer能够将Image-view Encoder与后续模块进行解耦,在图像视图空间image view space进行数据增强操作不会改变BEV空间中的特征空间分布。由于多视图图像在BEV进行了特征融合,BEV编码器的学习数据比图像编码器的学习数据少容易过拟合。翻转、缩放和旋转被应用于BEV特征图的数据增广(同时对视图转换器的输出以及检测目标进行操作以保证空间一致性)。
Scale-NMS
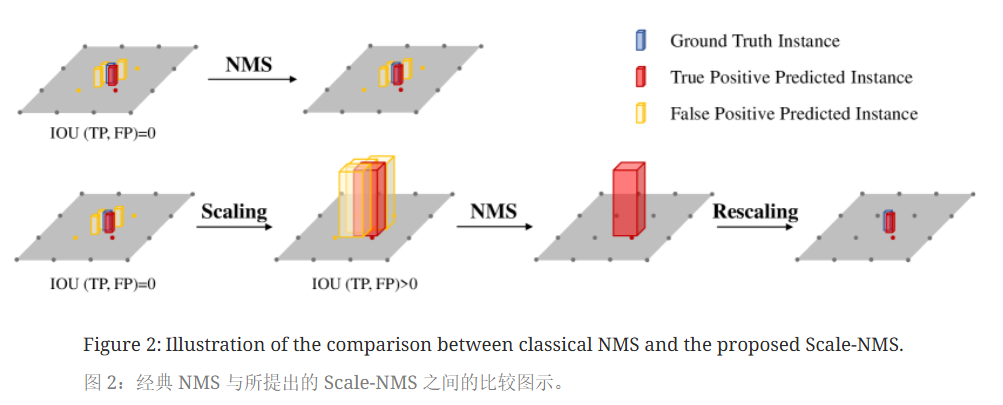
BEV空间中不同类别的空间分布与图像视图空间中的空间分布截然不同。在图像视图空间中,由于相机透视成像机制,所有类别共享相似的空间分布。因此,对于经典的NMS策略对于不同的类别都采用相同的阈值来来筛选预测结果。(例如在2D目标检测中,任何两个实例的bounding box的IOU值总是低于0.5)
然而在BEV空间中各个类的占用面积本质上是不同的,实例之间的重叠应接近于零。因此,预测结果之间的IOU分布因类别而异。
比如行人和锥型交通路标在接地面上占用很小的面积,总是小于算法的输出分辨率。常见的对象检测范式冗余地生成预测。每个物体的占地面积小,可能使冗余结果与真正结果没有交集。这将使依赖正样本和负样本之间空间关系(IOU)的经典NMS失效。
而通过缩放不同类别对象的大小(缩放因子根据类别各异,通过对验证集进行超参数搜索生成),再进行NMS,使经典NMS策略适用BEV空间,显著提升小目标检测性能。
实验结果
- 数据集:使用nuScenes数据集进行训练和验证。
- 性能指标:报告mAP、ATE、ASE、AOE、AVE、AAE和NDS。
- 训练参数:使用AdamW优化器,批次大小64,20周期内结束。
- 数据处理:在训练和测试时应用不同的数据增强。
消融实验
数据增强
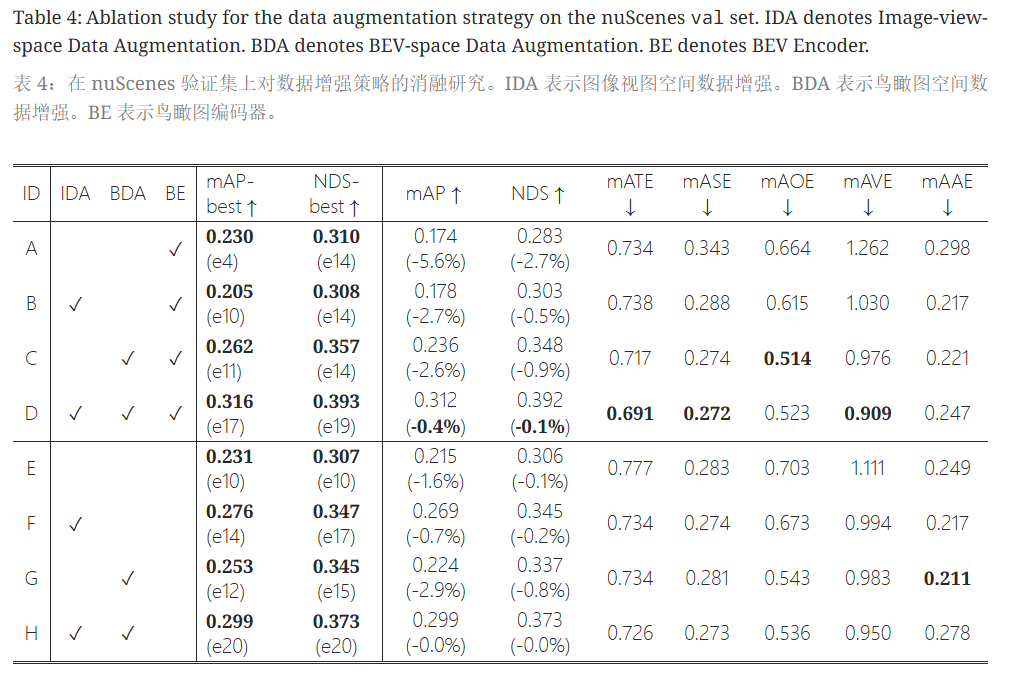
在研究BEVDet-Tiny的过程中,作者分析了定制数据增强策略对性能的影响,使用了20个训练周期,比较了训练过程中的最佳性能与最后一个周期的最终性能。关键数据增强方法包括图像视图空间数据增强(IDA)和BEV空间数据增强(BDA)。
- Baseline配置(Tab. 4 A):采用CenterPoint方法,没有数据增强,训练早期即饱和(mAP为23.0%),最终性能仅为17.4%,远低于FCOS3D的29.5%。
- IDA表现(Tab. 4 B):引入IDA后,饱和时间推迟至第10个周期,最佳结果为20.5%,最终性能为17.8%,仍低于Baseline。
- BDA效果(Tab. 4 C):BDA单独使用时,性能在第15个周期达到26.2%,最终为23.6%,比Baseline高3.2%。
- 组合使用IDA与BDA(Tab. 4 D):两者结合,性能在第17个周期达到31.6%,最终为31.2%,较Baseline提升8.6%。增益有限(-0.4%)的性能退化现象表明IDA在没有BDA时对性能有负面影响,但有助于与BDA结合时的提升。
- BEV编码器的作用(Tab. 4 E-H):去除BEV编码器时,性能下降1.7%,显示其对BEVDet准确度的关键作用。与BDA一同考虑时,IDA表现出不同的影响,证明BDA在构建性能方面的重要性。
总之,研究显示BDA优于IDA,并在组合策略下,BEVDet的性能有显著提升。
Scale-NMS
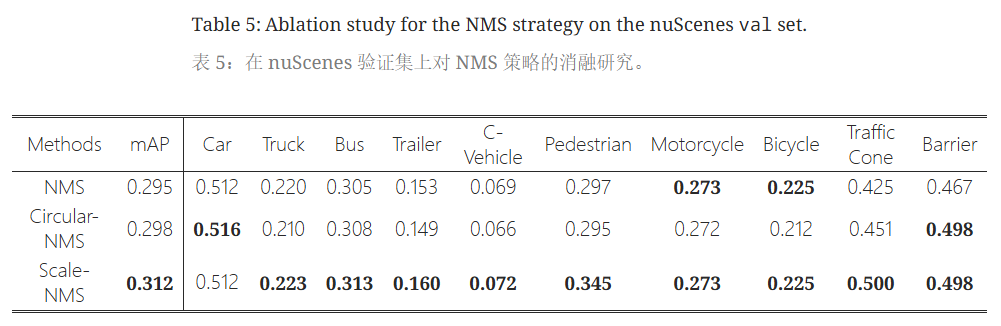
与普通的NMS以及CenterPoint中提出的Circular-NMS(来自CenterPoint,具体就是在鸟瞰中,只有当某中心半径r内没有具有更高置信度的中心时,该对象才被视为正,作者将该方法称为Circular NMS。)比较,Scale-NMS在小物体的检测精度上有很大提升,其余物体也有一定提升。
分辨率
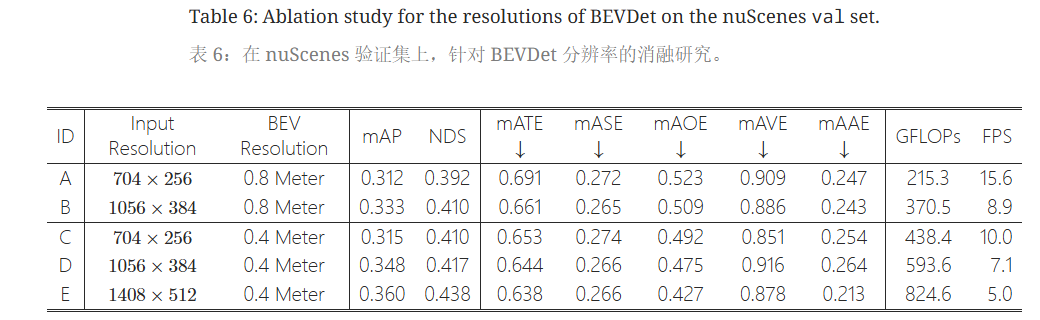
增大输入图像和BEV特征图的分辨率均能带来性能提升,但会带来额外的推断时间。
Backbone Type in the Image-view Encoder
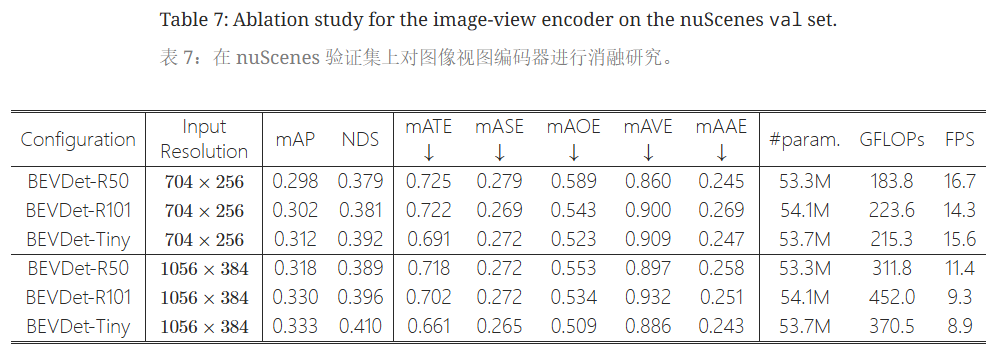
研究分析了不同主干结构对BEVDet性能的影响,构建了三种参数量相似的衍生版本。根据Tab. 7,采用了两种输入分辨率。当将图像视图编码器的主干从ResNet-R50替换为SwinTransformer-Tiny(输入分辨率704×256)时,性能提升了+1.4% mAP和+1.3% NDS(BEVDet-R50:29.8% mAP和37.9% NDS;BEVDet-Tiny:31.2% mAP和39.2% NDS)。
- 性能差异:BEVDet-R50在预测目标速度方面更强,而BEVDet-Tiny在目标平移和方向预测上表现更佳。
- 其他变体表现:在采用704×256的小输入尺寸时,BEVDet-R101仅相较于BEVDet-R50提升了+0.4% mAP和+0.2% NDS;但在分辨率提升至1056×384时,性能提升为+1.2% mAP和+0.7% NDS。
研究推测,更大的感受野在增大输入尺寸时发挥重要作用。
加速
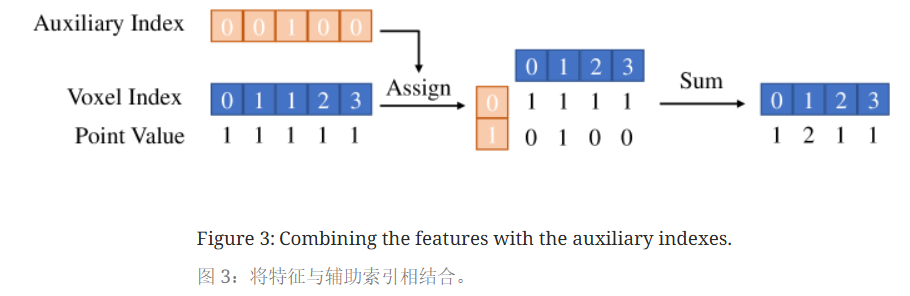
在View Transformer视角转换模块(LSS)中,对同一体素内特征进行累加,从而影响推理延迟。Lift-Splat-Shoot用图像产生的点云形状是固定的,因此每个点可以预先分配一个体素索引Voxel Index,用于指示其属于哪一个体素。引入辅助索引Auxiliary Index记录每个体素索引出现的次数。利用这个辅助索引和体素索引,将点分配到二维矩阵中,并仅通过辅助轴进行特征汇总。在推理阶段,摄像机内外参数固定,使得辅助索引和体素索引可在初始化阶段计算。
通过这一修改,BEVDet-Tiny的推理延迟减少了53.3%(从137ms降至64ms)。但会增加内存使用量,取决于体素数量和辅助索引的最大值。实际中将辅助索引的最大值限制为300并丢弃剩余点,且此操作对模型准确度几乎没有影响。
结论
BEVDet在多相机3D目标检测中展示出色性能,通过模块化设计和改进的数据增强策略,显著提升目标的平移、尺度、方向和速度感知能力。未来研究将集中于提高目标属性预测能力和基于BEVDet的多任务学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号