软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | github初使用,代码规范制定,编写疫情统计程序 |
| 作业正文 | https://www.cnblogs.com/ginphy/p/12318693.html |
| 其他参考文献 | .gitignore配置语法完全版-CSDN |
一、GitHub仓库地址
https://github.com/Ginphy/InfectStatistic-main
##二、PSP表格 PSP2.1 | Personal Software Process Stages | 预估耗时(分钟)| 实际耗时(分钟) --|:--:|--:|--: Planning|计划|30|30 Estimate|估计这个任务需要多少时间|30|30 Development|开发|520|555 Analysis|需求分析 (包括学习新技术)|30|20 Design Spec|生成设计文档|15|30 Design Review|设计复审|15|10 Coding Standard|代码规范 (为目前的开发制定合适的规范)|30|20 Design|具体设计|30|35 Coding|具体编码|360|400 Code Review|代码复审|10|10 Test|测试(自我测试,修改代码,提交修改)|30|30 Reporting|报告|120|160 Test Repor|测试报告|30|30 Size Measurement|计算工作量|30|20 Postmortem & Process Improvement Plan|事后总结, 并提出过程改进计划|60|110 |合计||670|745
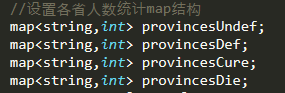
##三、解题思路 一开始看见这个题目,第一反应将其分为统计部分与信息输入/输出两部份来实现;我在编码时是先实现的统计部分再实现IO交互部分,在思考要如何实现统计部分的时候我是从数据结构着手,先想要用什么数据结构来在程序中存储多个地区多个群体类型的数据,因为是人数、地区、群体类型三个不同值之间的对应关系,就觉得使用MAP来实现比较方便(多维数组要人命啊啊啊啊)。设置4个MAP变量来表示4类不同的群体(sp,ip,cure,dead),在每个MAP变量中以String类型为key保存各省名称,value值则是该省该类型群体的人数,这样在编码时也比较直接可以使用MAP的.at("省份")来直接对数据进行操作。
然后在数据统计的时候就根据不同的情况对于各个MAP内对应省份的值进行加减就好了,比如在统计到A省死亡num个人时就在名为provincesDie的MAP变量中使用`provincesDie.at("全国") += num;`与`provincesDef.at(A省) -= num;`对MAP内的数据进行处理就好啦,最后统计的时候就把这四个MAP变量都遍历一遍全部输出也很方便,如果参数指定了省份与类型也只需要根据读入的类型与省份快速定位到对应MAP变量使用.at()函数读取就好了。
计算统计部分设计完然后就是考虑IO交互部分,其实这题主要就是输入部分涉及到多个参数复杂,输出只要正常使用文件IO流fstream类就好了。输入部分的话可以看出这次给出的语句都是符合一定结构的,开头第一个词就是省份,而且每行的的词数都是可知的,所以我就采用了按词读取的方法,设置省份和类型的String变量,将第一个读入的词写入省份变量方便后面使用MAP的.at()函数进行统计,接下来读取第二个词语是类型,使用多个if...else结构对读入的每个词进行处理,比如读取到了死亡时可以预料到下一个词是“xx人”下一个词就读取到一个int变量中,然后剩下一个没读取的必然是一个“人”字,读掉这个词接下来再读取的就是下一行的新省份名了,如此反复。这个时候我们就有了省份名和死亡的两个String变量以及int类型的人数变量。我们就可以再if...else结构中找到对应的代码块根据信息对MAP结构进行操作了!

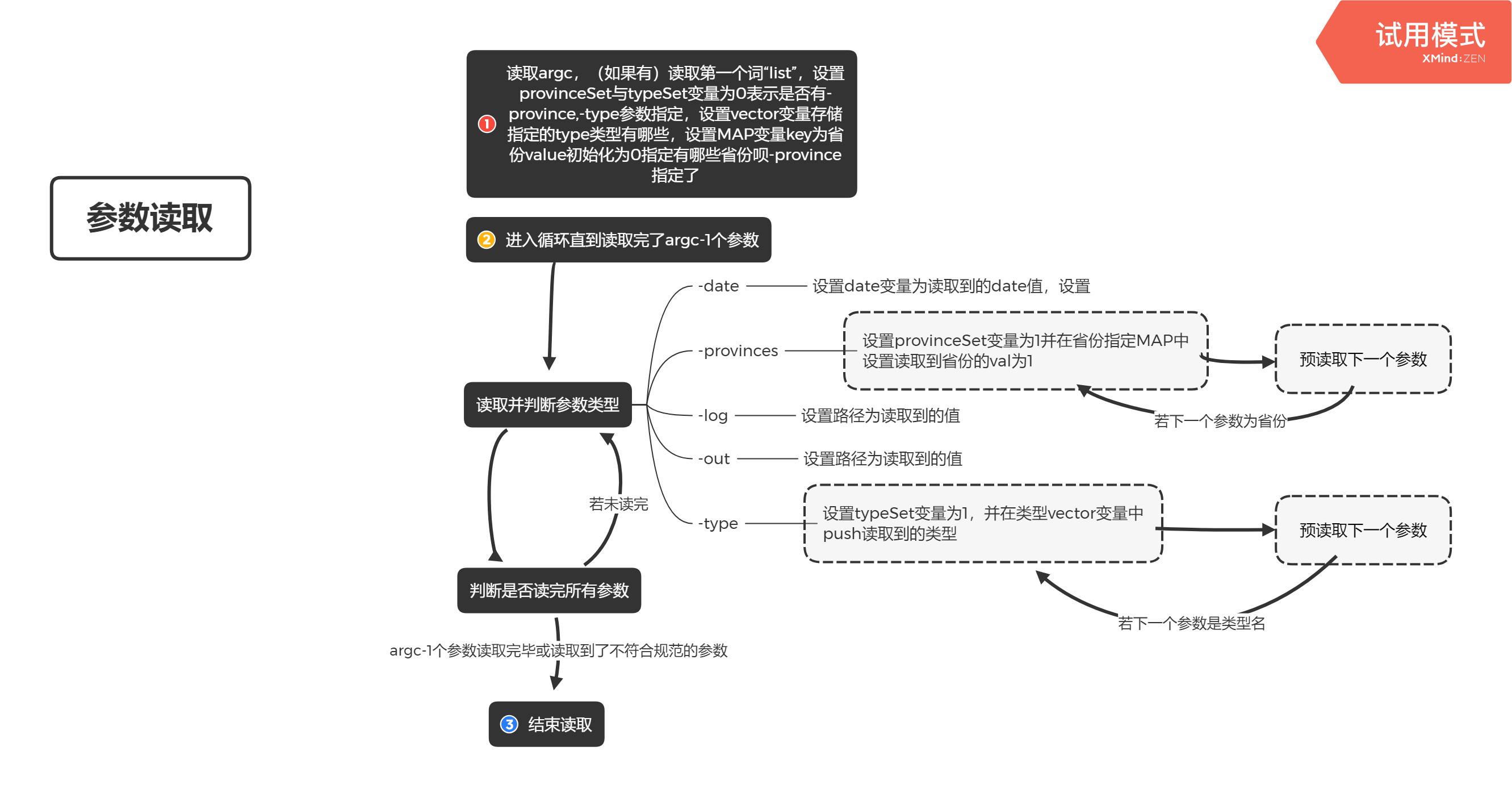
##四、设计实现 因为可以看出在参数开头都必然有一句list所以直接读取掉这第一个词不做任何操作,然后往下读,根据读取到的是"-log","-type","-out","-province","-date"进行不同操作(如图),设置provinceSet与typeSet变量为0表示是否有-province,-type参数指定,设置vector变量存储指定的type类型有哪些,设置MAP变量key为省份value初始化为0指定有哪些省份,-province指定了若读取的参数不在上诉几个词之中就报错。依据argc判断在读取完所有参数之后若未设置-log,-out则也报错。
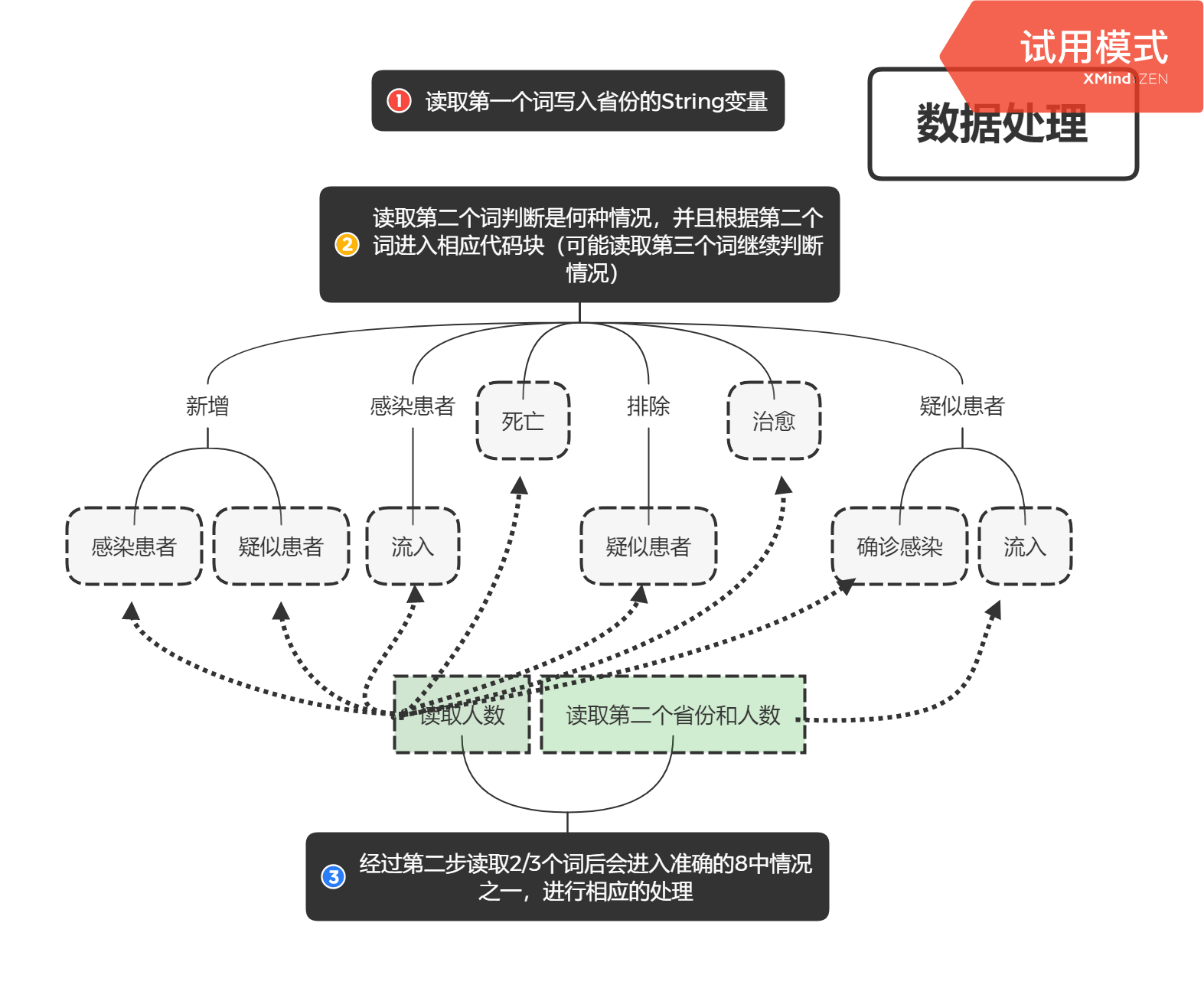
数据统计的实现大致就是解题思路中的那样,如图这是在读取到了一行的数据并在if...else结构中进行判断找到相应代码块进行数据处理整个过程的流程图:
##五、代码说明 以下这些代码是参数读取时的代码,可以看出如果读取到list就不作为,按照argc的数量依次读取各个参数,使用if...else来判断当前读取的哪种参数,并在相应的代码块里进行处理,比如读取到了`-log`那么下一个读取的到的值就付给输出文件名`String outPath`变量,如果读取到的是`-type`就进入一个小循环依次读取后面的群体类型并push到`vector`中,若下一个参数不属于“sp,ip,cure,dead”中任一种则说明下一个词不再是type的参数跳出小循环。如果读取到`-province`与type参数类似也进入一个小循环同时设置provinceSet变量为1表示这次的参数有指定省份,每次循环预读取下一个词,判断如果是省份名则在MAP结构中设置该省的value为1表示应该输出该省的情况。如读取到了`-date`则设置`String date`变量为下一个读取到的值。在后面的程序中会判断,若date值的length为0则表示参数未指定日期,那么在统计时就将处理log指定文件夹下的所有文档记录,若指定了date值则会在读取log指定文件夹下的文档前比照日期,只有早于或等于date参数指定日期的文档才会被统计。在读完所有参数词语后会通过length判断是否指定了out与log这两个必要参数,若没有则报错。 ```cpp char temp[256]; int numTemp; string option,val; for(int i = 1; i < argc; i++){ option = argv[i]; if(option == "-log"){ inPath = argv[++i]; } else if(option == "-out"){ outPath = argv[++i]; } else if(option == "-date"){ date = argv[++i]; } else if(option == "-type"){ outTypeSet = 1; while((i+1) < argc) { val = argv[i+1]; if((val == "ip"||val == "sp"||val == "cure"||val == "dead")){ outType.push_back(val); i++; } else break; } } else if(option == "-province"){ outProvincesSet = 1; map
}
else{
cout<<endl<<endl<<option<<endl<<endl;
cout<<"输出参数错误"<<endl;
return -1;
}
}
if(inPath.length() == 0){
cout<<"-log参数未指定"<<endl;
return -1;
}
if(outPath.length() == 0){
cout<<"-out参数未指定"<<endl;
return -1;
}
以下这些代码是统计部分的代码,逐词读取到String变量中再通过自己写的函数将其转码为Ansi方便C++处理。若读取到的第一个词是`\\`则该行内容被跳过,其他的根据词的不同经if...else结构判断后进入相应代码块进行处理。若处理过程中发现记录中的省份不存在则会报错。
```cpp
//处理文档内容
while(!fin.eof()){
fin >> temp;
string info = Utf8ToAnsi(temp);
if(info == "//"){
fin.getline(temp,255);
continue;
}
targetProvince = info;
fin >> temp;
info = Utf8ToAnsi(temp);
if(info == "排除"){
fin >> temp;
fin >> numTemp;
fin >> temp;
provincesUndef.at(targetProvince) -= numTemp;
provincesUndef.at("全国") -= numTemp;
}
else if(info == "死亡"){
fin >> numTemp;
fin >> temp;
provincesDie.at(targetProvince) += numTemp;
provincesDie.at("全国") += numTemp;
provincesDef.at(targetProvince) -= numTemp;
provincesDef.at("全国") -= numTemp;
}
else if(info == "治愈"){
fin >> numTemp;
fin >> temp;
provincesCure.at(targetProvince) += numTemp;
provincesCure.at("全国") += numTemp;
provincesDef.at(targetProvince) -= numTemp;
provincesDef.at("全国") -= numTemp;
}
else if(info == "新增"){
fin >> temp;
info = Utf8ToAnsi(temp);
if(info == "感染患者") {
fin >> numTemp;
fin >> temp;
provincesDef.at(targetProvince) += numTemp;
provincesDef.at("全国") += numTemp;
}
else if(info == "疑似患者"){
fin >> numTemp;
fin >> temp;
provincesUndef.at(targetProvince) += numTemp;
provincesUndef.at("全国") += numTemp;
}
else{
cout << targetProvince << "相关文档数据错误" << endl;
fin.getline(temp,255);
continue;
}
}
else if(info == "感染患者"){
fin >> temp;
fin >> temp;
string tempProvince = Utf8ToAnsi(temp);
fin >> numTemp;
fin >> temp;
provincesDef.at(targetProvince) -= numTemp;
provincesDef.at(tempProvince) += numTemp;
}
else if(info == "疑似患者"){
fin >> temp;
info = Utf8ToAnsi(temp);
if(info == "确诊感染"){
fin >> numTemp;
fin >> temp;
provincesDef.at(targetProvince) += numTemp;
provincesDef.at("全国") += numTemp;
provincesUndef.at(targetProvince) -= numTemp;
provincesUndef.at("全国") -= numTemp;
}
else if(info == "流入"){
fin >> temp;
string tempProvince = Utf8ToAnsi(temp);
fin >> numTemp;
fin >> temp;
provincesUndef.at(targetProvince) -= numTemp;
provincesUndef.at(tempProvince) += numTemp;
}
else{
cout << targetProvince << "相关文档数据错误" << endl;
fin.getline(temp,255);
continue;
}
}
else{
cout << targetProvince << "相关文档数据错误" << endl;
fin.getline(temp,255);
continue;
}
}
//当个文档处理完毕
以下这些代码是统计完毕后输出到文档的部分。同样也是使用文件流的方法,打开之前out参数指定的文档地址,然后进行输出。会根据outProvincesSet与outTypeSet变量的值来判断是否设置了type或者province参数,从而分成四种输出情况,比如若指定了输出省份则会根据按照拼音排好序的省份数组依次判断该省份名作为key的输出MAP中对应的value是否为1,若为1则说明该省份在参数中被指定要求输出,就会输出该省信息。若指定了人群类型参数则会在输出时访问输出类型vector按照参数指定顺序在一个省中依次输出各个被指定类型的人数。
const char *FILEPATH = const_cast<char *>(outPath.c_str()) ;
ofstream fout(FILEPATH);
if(outProvincesSet == 0 && outTypeSet == 0){
for(int i = 0; i < 32; i++){
fout << provincesList[i] << "\t感染患者" << provincesDef.at(provincesList[i]) << "\t疑似患者";
fout << provincesUndef.at(provincesList[i]) << "\t治愈" << provincesCure.at(provincesList[i]) << "\t死亡";
fout << provincesDie.at(provincesList[i]) << endl;
}
}
else{
if(outProvincesSet != 0 && outTypeSet == 0){
for(int i = 0; i < 32; i++){
if(provincesOut.at(provincesList[i]) == 1)
fout << provincesList[i] << "\t感染患者" << provincesDef.at(provincesList[i]) << "\t疑似患者";
fout << provincesUndef.at(provincesList[i]) << "\t治愈" << provincesCure.at(provincesList[i]) << "\t死亡";
fout << provincesDie.at(provincesList[i]) << endl;
}
}
else if(outProvincesSet == 0 && outTypeSet != 0){
for(int i = 0; i < 32; i++){
fout << provincesList[i];
for (vector<string>::iterator iter = outType.begin(); iter != outType.end(); iter++){
if(*iter == "ip"){
fout << "\t感染患者" << provincesDef.at(provincesList[i]);
}
else if(*iter == "sp"){
fout << "\t疑似患者" << provincesUndef.at(provincesList[i]);
}
else if(*iter == "cure"){
fout << "\t治愈" << provincesCure.at(provincesList[i]);
}
else if(*iter == "dead"){
fout << "\t死亡" << provincesDie.at(provincesList[i]);
}
else{
cout << "-type参数错误" << endl;
return -1;
}
}
fout << endl;
}
}
else{
for(int i = 0; i < 32; i++){
if(provincesOut.at(provincesList[i]) == 1){
fout << provincesList[i];
for (vector<string>::iterator iter = outType.begin(); iter != outType.end(); iter++){
if(*iter == "ip"){
fout << "\t感染患者" << provincesDef.at(provincesList[i]);
}
else if(*iter == "sp"){
fout << "\t疑似患者" << provincesUndef.at(provincesList[i]);
}
else if(*iter == "cure"){
fout << "\t治愈" << provincesCure.at(provincesList[i]);
}
else if(*iter == "dead"){
fout << "\t死亡" << provincesDie.at(provincesList[i]);
}
else{
cout << "-type参数错误" << endl;
return -1;
}
}
fout << endl;
}
}
}
}
fout << "// 该文档并非真实数据,仅供测试使用" << endl;
##六、单元测试截图和描述 - 测试命令:`C:\Users\Gin Yuen>C:\InfectStatistic.exe -log C:\log\ -out C:\result\ListOut5.txt` 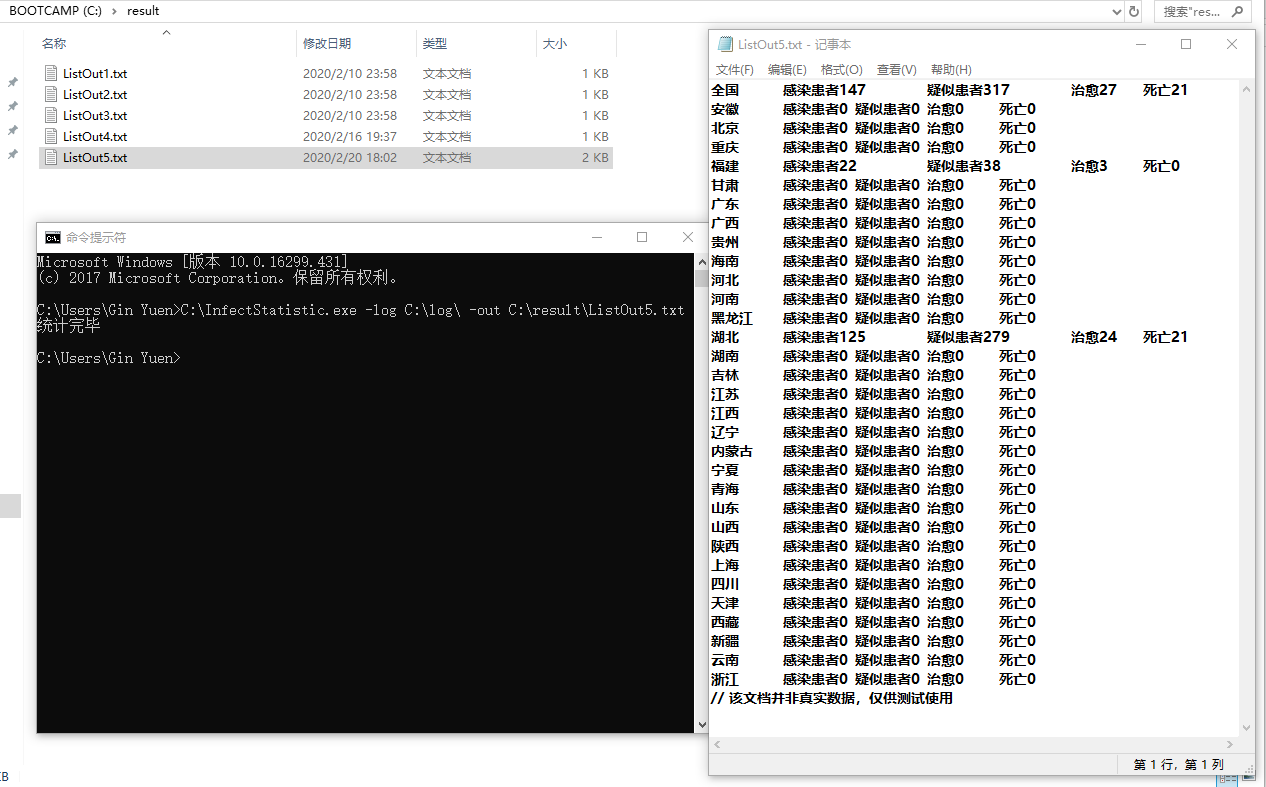
- 测试命令:`C:\Users\Gin Yuen>C:\InfectStatistic.exe -log C:\log\ -out C:\result\ListOut6.txt -date 2020-01-22` 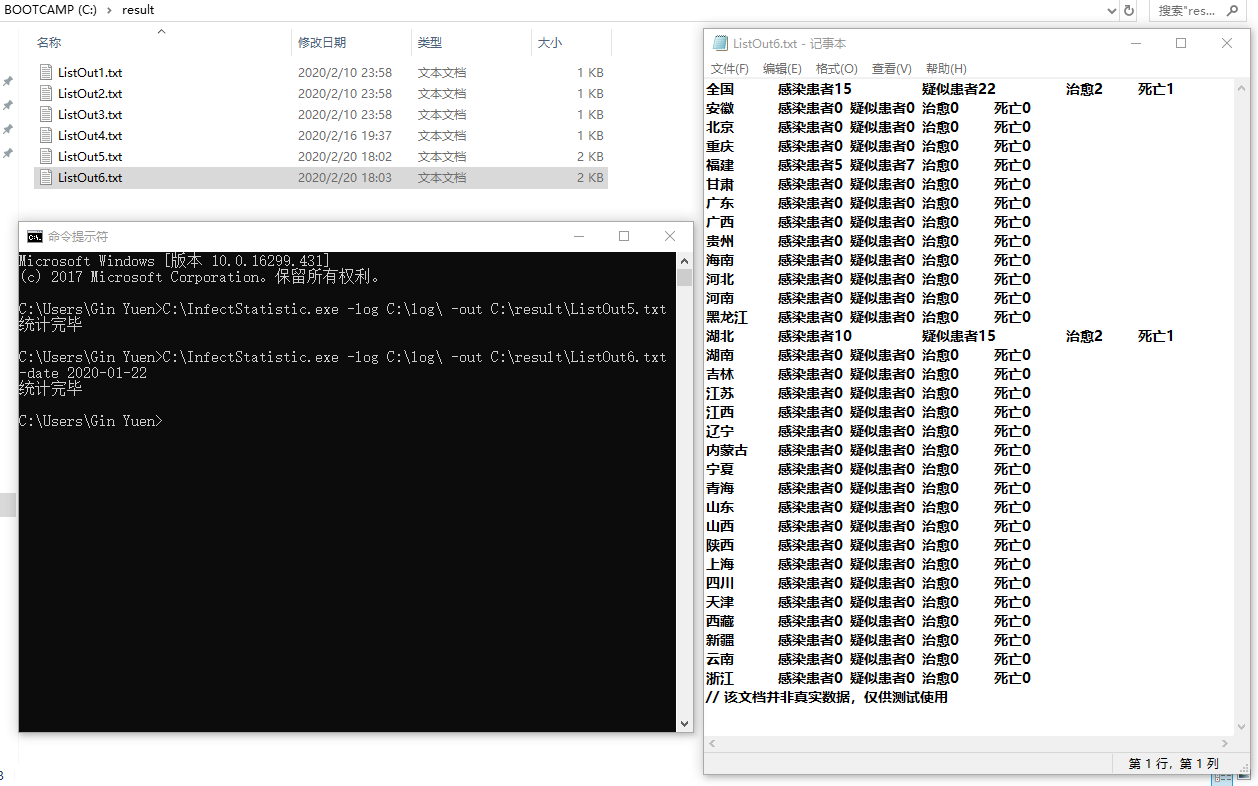
- 测试命令:`C:\InfectStatistic.exe -log C:\log\ -out C:\result\ListOut7.txt -date 2020-01-22 -province 福建 全国 广东 湖北 四川 -type ip` 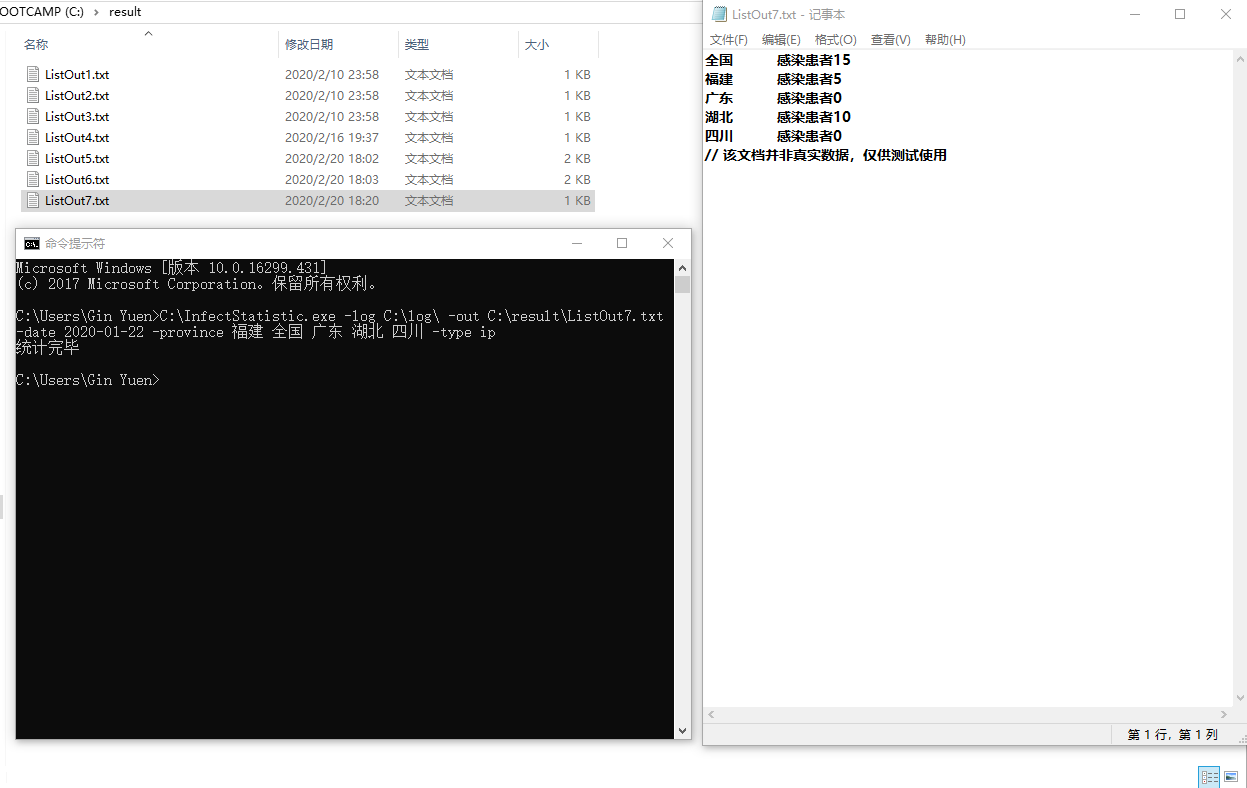
- 测试命令:`C:\InfectStatistic.exe -log C:\log\ -out C:\result\ListOut7.txt -date 2020-01-23 -province 福建 全国 安徽 湖北 重庆 湖南` 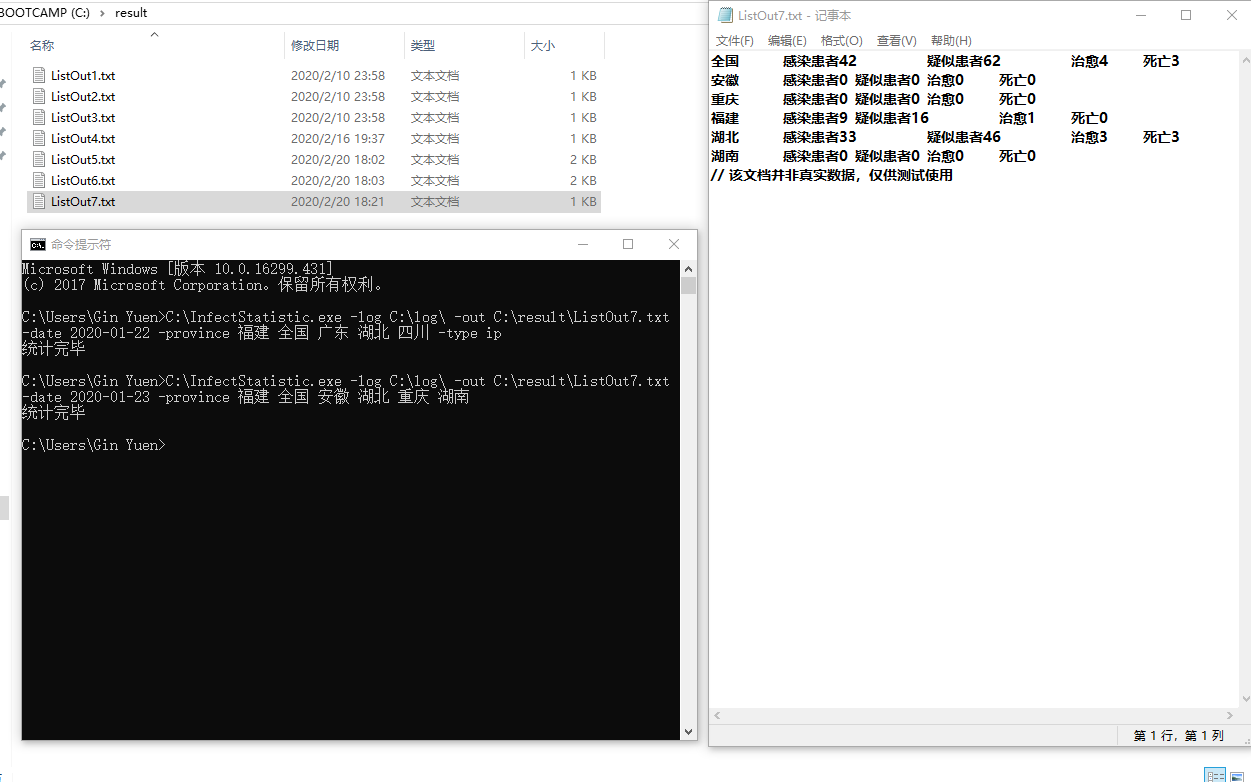
- 测试命令:`C:\InfectStatistic.exe -log C:\log\ -out C:\result\ListOut7.txt -date 2020-01-25 -province 福建 全国 安徽 湖北 新疆 -type ip cure sp` 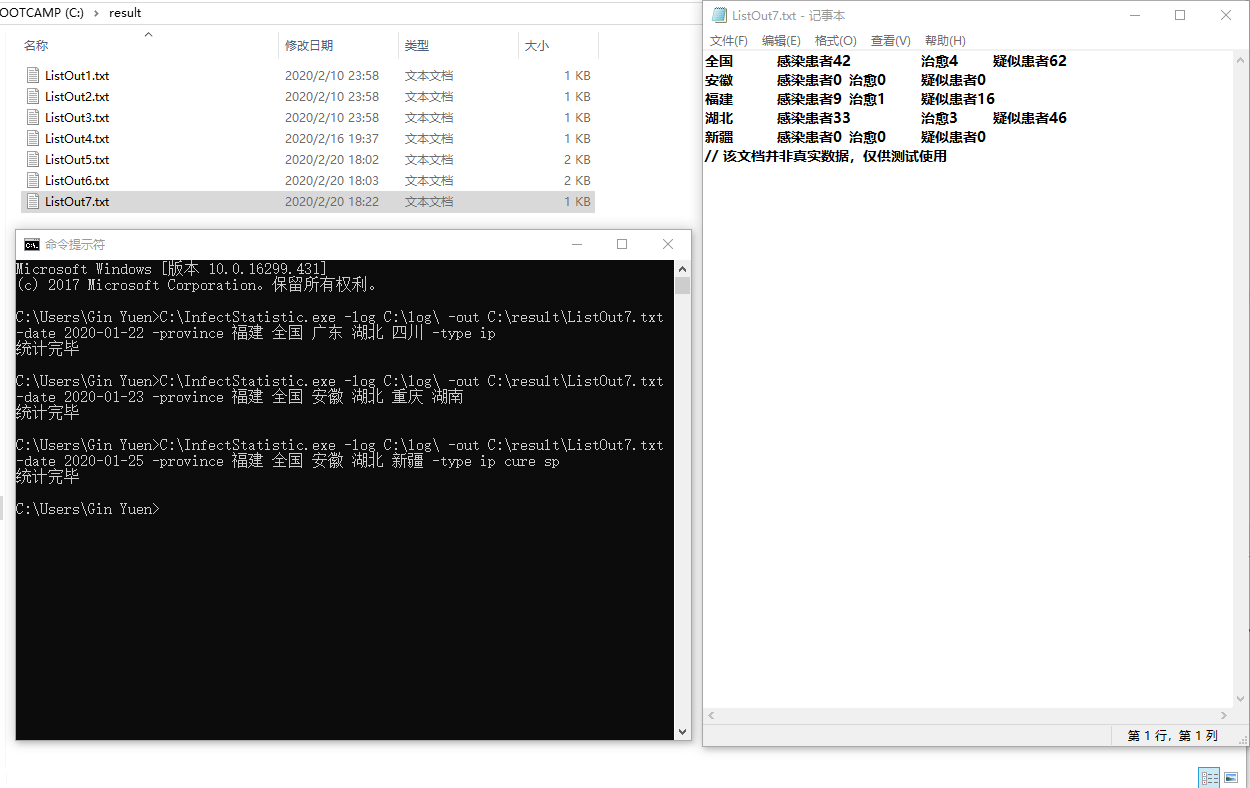
- 测试命令:`C:\InfectStatistic.exe -date 2020-01-29 -province 全国 湖北 -log C:\log\ -out C:\result\ListOut8.txt` 
- 测试命令:`C:\InfectStatistic.exe -date 2020-01-29 -type ip dead -log C:\log\ -out C:\result\ListOut9.txt` 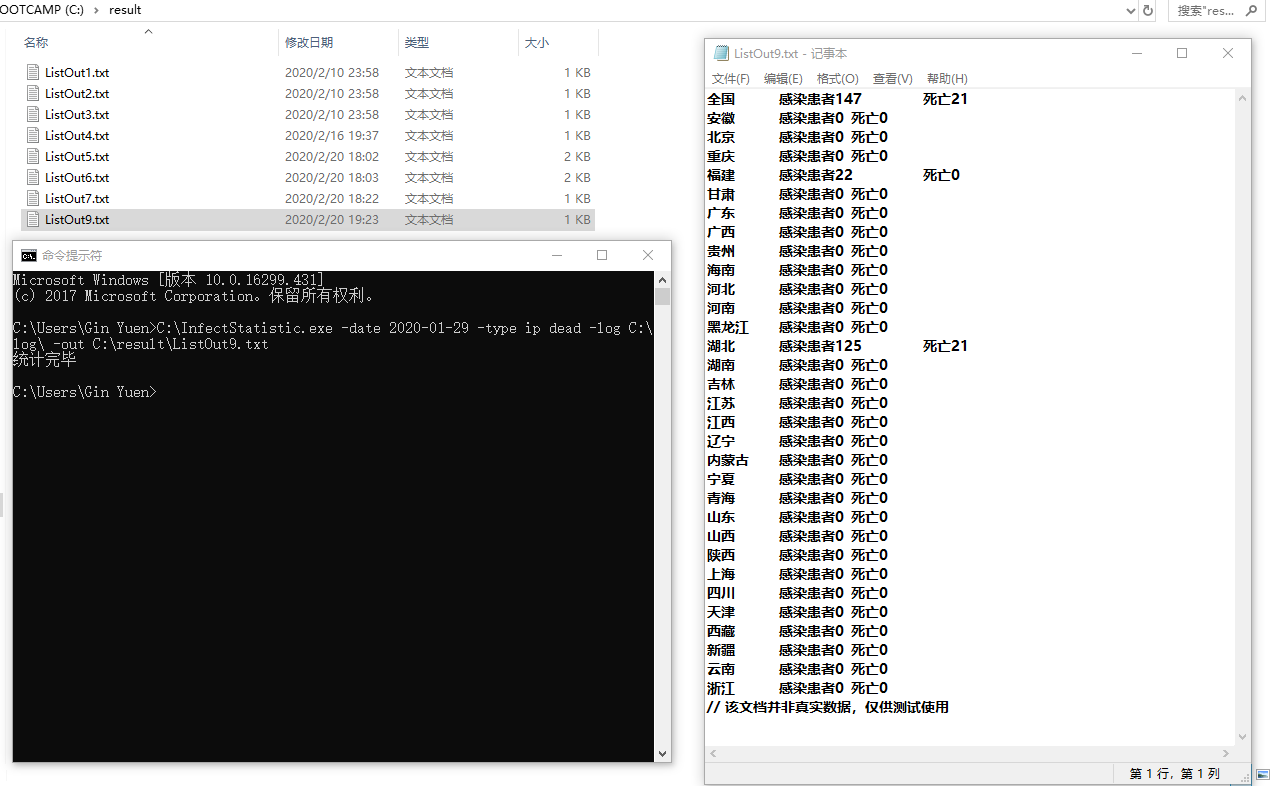
- 测试命令:`C:\InfectStatistic.exe -log C:\log\ -out C:\result\ListOut7.txt -date 2020-01-25 -province 福建 全国 纽约州 -type ip cure sp` 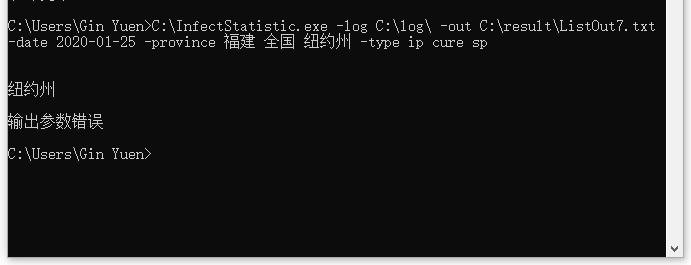
- 测试命令:`C:\InfectStatistic.exe -log C:\log\ -out C:\result\ListOut7.txt -date 2020-02-01 -province 福建 全国 -type ip cure spe sp -unknow wrong` 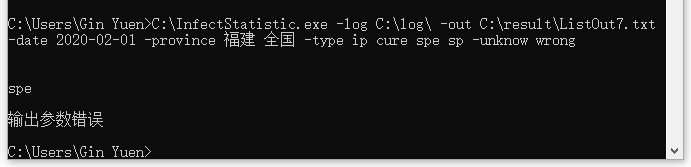
- 测试命令:`C:\InfectStatistic.exe list -out C:\result\ListOut8.txt`与`C:\InfectStatistic.exe list -log C:\log\` 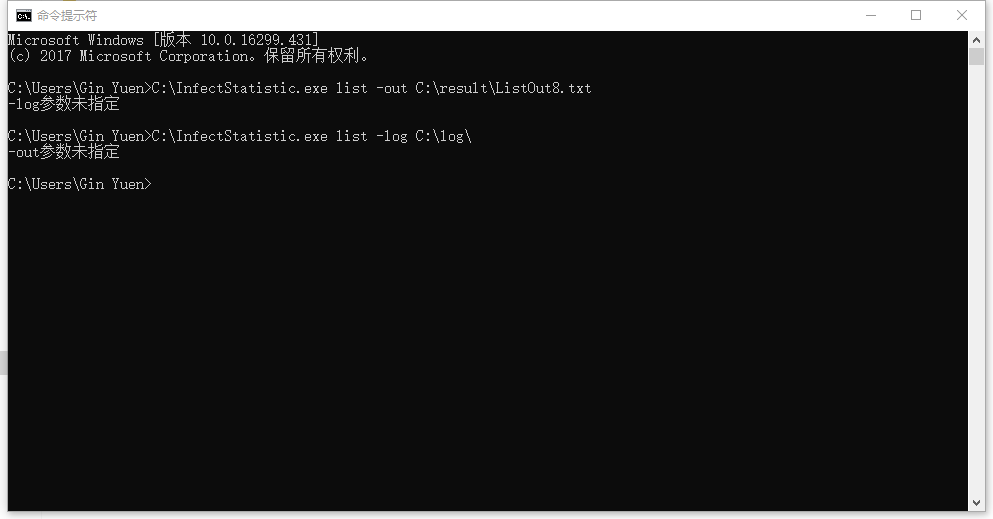
##七、单元测试覆盖率优化和性能测试
##八、Git仓库与代码规范链接 - [Git仓库](https://github.com/Ginphy/InfectStatistic-main/tree/master/example)
- [代码规范](https://github.com/Ginphy/InfectStatistic-main/blob/master/example/codestyle.md)
##九、心路历程和收获 这次的作业一开始看到的时候觉得任务量很大很难,但是自己一点一点的做下来以后还是学到了很多的东西的,体会到了把一个任务结构化模块化化繁为简的处理放方法,这次就是先将作业分为编码部分和文档部分,在编码部分又划分成了统计部分与读写部分,这样一步步的完成还是很有成就感的。在编码过程中回顾了很多以前学过的知识,也在这次作业中学习了Github的基本使用还有PSP表格评估方法,为了这次的作业撰写了很多的文档,初步体会到了软件工程作为一个工程类学科的特性,看了腾讯的编码规范然后写出自己的编码规范,这个过程中感受到了大企业的软件开发真的是好多规矩好复杂啊。这次也在作业的要求下不是一开始就编码而是先分析思路画流程图设计实现过程这样一步步的来进行,这样完成一项作业确实和以前直接上手编码的流程有很大的不同,很重要的就是明显的感觉到了自己的思路比以前清晰了很多,然后因为有PSP表格对每个部分的时间进行控制预期,所以在逐渐完成时也没有时间安排不够的慌乱,感觉有这样一个时间的评估确实会让自己在完成一个软件开发任务的时候有规划很多,不会磨磨蹭蹭赶DDL啦。Github原来这么方便,就是有时候commit次数多了实在想不起来要写什么描述才好。
##十、相关仓库 - 前端学习路径仓库,和一些作者个人经验: https://github.com/qiu-deqing - 前端学习工具集,主要Node方向: https://github.com/nieweidong/fetool - 前端开发书签: https://github.com/zzxadi/frontend-dev-bookmarks - 前端开发规范手册,降低维护代码的成本提升效率: https://github.com/Aaaaaashu/Guide - 前端交互学习教程,包括Js与NodeJs: https://github.com/yujiangshui/fun-front-end-tutorials

 浙公网安备 33010602011771号
浙公网安备 33010602011771号