大数据实战-电信客服-重点记录
写在前面的话
最近不是一直在学习大数据框架和引用嘛(我是按照B站视频先学习过一遍路线,以后找准方向研究),除了自己手动利用Kafka和HDFS写一个简单的分布式文件传输(分布式课程开放性实验,刚好用上了所学的来练练手)以外,还学习这个学习路线一个项目,电信客服实战。在这个项目里面还是学习到了不少内容,包括Java上不足的很多地方、Java工程开发上的要求和少数框架的复习。不排除自己太菜,啥都不知道,认为一些常见的东西不常见的情况(哭
鉴于网上有很多类似的内容,这里我只是将我学习和复code的过程中,学习到的知识和遇到问题的解决方案写下,以作记录和回顾。
1.我的手敲代码,2.老师源码,含数据和笔记(提取码:pfbv)
电信客服
介绍
项目主要是模拟电信中的信息部门,从生产环境中获取通话信息数据,根据业务需求存储和分析数据。
业务需求
统计每天、每月以及每年的每个人的通话次数及时长。
项目架构
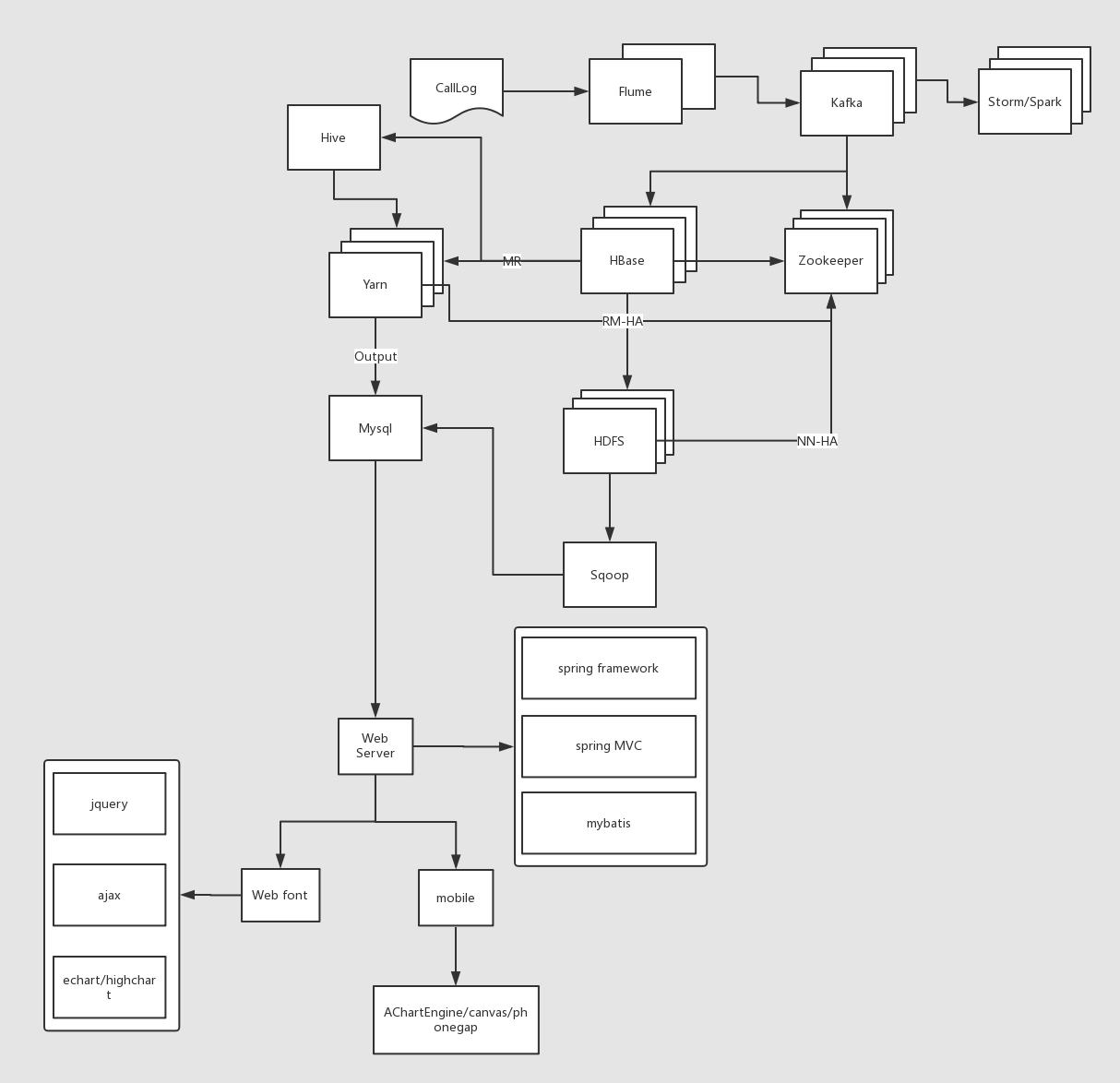
代码流程
编写代码的流程分为四步:①数据生产,②数据消费,③数据分析,④数据展示。我在学习过程中,没有学习数据展示部分。
数据生产
主要任务是利用contact.log(联系人文件)的数据,生成不同联系人之间通话记录的流程。
这个Part,老师有句话我觉得很在理,“大数据开发人员虽然不管数据怎么来的,怎么出去的,但是必须知道和了解这个过程才能按照需求code”。脑海中闪过中间件
面向接口编程 - 项目第一步
在以前的编程学习过程中,总是一股脑儿的猛写代码,虽然我自认为我在我们宿舍已经是模块化思想最为严重的了,但是从未接触到面向接口编程。这学期也学习了软件工程,(虽然我们学得很水),这门课虽然不是在教我们写代码,但却是教我们如何正确的做项目和写代码(晕。
面向接口编程也是如此,在这个项目中,了解了我们的数据来源和需求后,第一步要做的是弄清楚需要的对象和需要的功能,即接口,在共同的模块中确定好接口和接口的方法签名,接下来才是对接口模块的实现和实现业务。
在这个项目中,建立了一个ct-common模块作为公共模块,简单介绍几个:
| 接口或抽象类 | 描述 |
|---|---|
| Val | 一般数据都需要的实现的接口,只包括名称意义上的获取值value()方法 |
| DataIn | 数据输入接口,功能有设置输入路径,读取数据,故存在setPath()和read()方法 |
| Producer | 数据生产者接口,功能有获取输入信息,设置生产输出和生产,故存在setIn()和和setOut()和produce()方法 |
下图是ct-common的代码结构:

封装对象 - 提高扩展性
这个思想其实我在之前的编码过程中就有点领悟了,之所以在这里提出,是因为在这个跟进过程中,更加体会到Java编码就是各种对象组合调用的含义。或许是老师项目拉得太快,让我感觉自己太菜,skrskr
我之前编码过程中,也会不停的封装对象,但一般都是那些很明显的功能集成对象,更别说是对数据进行封装成数据集成对象了。换句话说,就是我之前封装的对象都是含有一定动作的(除了getter&setter)。但是对于一些对象之间传递的数据,如果每次都传相同的数据并且数量>1的话,最好的是封装成对象,提高扩展性。在业务需要增添一个数据传递的情况下,封装数据对象只需要更改对象的属性和对象的构成,否则每个传递的地方(语句)都需要增添传递的数据变量。
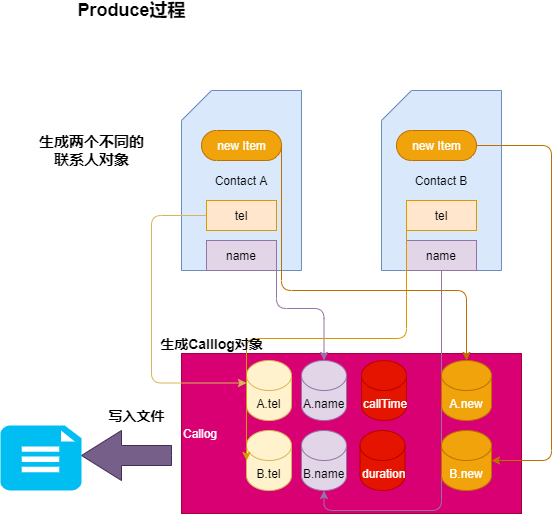
下面用一张图表示,在该项目中封装Calllog和Contact对象的效果:
如果不封装对象,如果联系人对象里面在加入一个new item(比如性别),那么几乎所有的地方都需要修改;反之,只需要在Contact类中增添new item属性和在Calllog中增添A.new&B.new属性,以及修改构造方法就可以了,同时在Producer过程中,没有增添和修改过多代码。
数据生产总结
在这个Part中主要还是熟悉任务就可以完成,没遇到什么问题。如果不用上述的tricks那这不就是一个读入文件和写入文件的代码嘛(我一main方法就能搞定),但是用了之后感觉就明显不同,更加工程化,逻辑感更强。
数据消费
主要操作是利用Flume和Kafka将收集不断生产的数据,并且将数据插入到HBase中。
新概念
主要是学到了一些新的知识,还有知识的简单运用,我并没有深究这些新概念(估计得学到头秃)。
-
类加载器:类加载器是负责将可能是网络上、也可能是磁盘上的class文件加载到内存中。并为其生成对应的java.lang.class对象。
有三种类加载器,分别按照顺序是启动类加载器BootstrapClassLoader、扩展类加载器Extension ClassLoader和系统类加载器App ClassLoader。还存在一种双亲委派模型,简单的意思就是说当一个类加载器收到加载请求时,首先会向上层(父)类加载器发出加载请求。并且每一个类加载器都是如此,所以每个类加载器的请求都会被传递到最顶层的类加载器中,一开始我觉得很麻烦,不过这确实可以避免类的重复加载。
在电信客服的项目中,类加载器被用于加载resource文件夹的配置文件。Properties prop = new Properties(); // 利用类加载器获取配置文件 prop.load(Thread.currentThread().getContextClassLoader().getResourceAsStream("consumer.properties")); -
ThreadLocal:这是一个线程内维护的存储变量数组。举个简单的比方,在Java运行的时候有多个线程,存在一个Map<K,V>,K就是每个线程的Id,V则是每个线程内存储的数据变量。
这是多线程相同的变量的访问冲突问题解决方法之一,是通过给每个线程单独一份存储空间(牺牲空间)来解决访问冲突;而熟悉的Synchronized通过等待(牺牲时间)来解决访问冲突。同时ThreadLocal还具有线程隔离的作用,即A线程不能访问B线程的V。
在电信客服的项目中,ThreadLocal被用来持久化Connection和Admin连接。因为在HBase的DDL和DML操作中,不同的操作都需要用到连接,所以将其和该线程进行绑定,加快获取的连接的速度和减少内存占用。当然也可以直接new 几个对象,最后统一关闭。// 通过ThreadLocal保证同一个线程中可以不重复创建连接和Admin。 private ThreadLocal<Connection> connHolder = new ThreadLocal<Connection>(); private ThreadLocal<Admin> adminHolder = new ThreadLocal<Admin>(); private Connection getConnection() throws IOException { Connection conn = connHolder.get(); if (conn == null) { Configuration conf = HBaseConfiguration.create(); conn = ConnectionFactory.createConnection(conf); connHolder.set(conn); } return conn; } private Admin getAdmin() throws IOException { Admin admin = adminHolder.get(); if (admin == null) { getConnection(); admin = connHolder.get().getAdmin(); adminHolder.set(admin); } return admin; }
分区键和RowKey的设计
分区键的设计一般是机器数量。rowKey的设计基于表的分区数,并且满足长度原则(10~100KB即可,最好是8的倍数)、唯一性原则和散列性原则(负载均衡,防止出现数据热点)
分区键
本项目中共6个分区,故分区号为"0|"、"1|"、"2|"、"3|"、"4|"。举一个例子,3****的第二位无论是任何数字都会小于"|"(第二大的字符),所以"2|"<"3****"<"3|",故分到第四个分区。
RowKey
设计好了分区键后,rowKey的设计主要是根据业务需求哪些数据需要聚集在一起方便查询,那就利用那些数据设计数据的分区号。
数据含有主叫用户(13312341234)、被叫用户(14443214321)、通话日期(20181010)和通话时长(0123)。业务要求我们将经常需要统计一个用户在某一月内的通话记录,即主叫用户和通话日期中的年月是关键数据。根据这些数据计算分区号,保证同一用户在同一月的通话记录在HBase上是紧邻的(还有一个前提要求是rowkey还必须是分,分区号+主叫用户+通话日期+others,否则在一个分区上还是有可能是乱的)。下面是计算分区号的代码:
/**
* 计算得到一条数据的分区编号
*
* @param tel 数据的主叫电话
* @param date 数据的通话日期
* @return regionNum 分区编号
*/
protected int genRegionNum(String tel, String date) {
// 获取电话号码的随机部分
String userCode = tel.substring(tel.length() - 4);
// 获取年月
String yearMonth = date.substring(0, 6);
// 哈希
int userCodeHash = userCode.hashCode();
int yearMonthHash = yearMonth.hashCode();
// crc 循环冗余校验
int crc = Math.abs(userCodeHash ^ yearMonthHash);
// 取余,保证分区号在分区键范围内
int regionNum = crc & ValueConstants.REGION_NUMS;
return regionNum;
}
查询方法
例子:查询13312341234用户在201810的通话记录
startKey <- genRegionNum("13312341234","201810")+"_"+"13312341234"+"_"+"201810"
endKey <- genRegionNum("13312341234","201810")+"_"+"13312341234"+"_"+"201810"+"|"
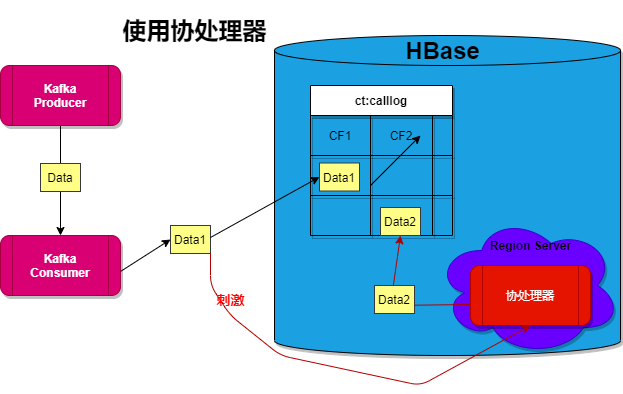
协处理器
引入的原因
电信客服中通常需要计算两个客户之间亲密度,计算的数据来源于两者的通话记录。举个例子,计算A和B的亲密度,那要A和B之间的通话记录,特别注意的是不仅需要A call B的记录,还需要B call A的记录。
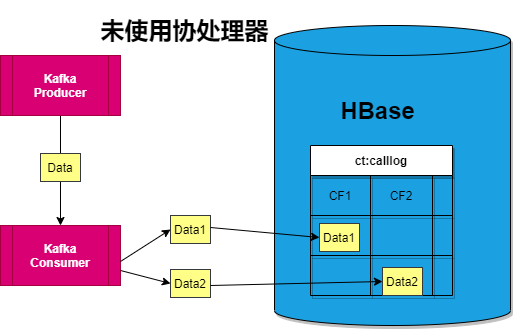
- 第一,最无脑的方法是啥也不做
(憨憨,在查询的时候通过scan中的filter对rowkey进行过滤查询,这样子每需要查询全表,速度过慢。 - 第二,最直观的方法是接收到Kafka的一条数据后,插入两条数据,主叫用户和被叫用户换个位置第二次插入HBase时加上一个标志位Flag,标识第一个电话号码(HBase中的列称为call1)是否是主叫用户。
- 第三,显然一条数据是重复了两次,那么在查询的时候(无关亲密度)出现两次,即影响查询速度。所以优化的方法重复的数据单独新建一个列族,在查询的时候只需要在一个列族中查询。即减少了数据量,毕竟HBase针对表的存一个个store进行存储的。
- 第四,这样子扩展性太低,要是需要重复几十次,那编码效率和插入效率也太低了,故在HBase中引入了协处理相当于MySQL中的触发器,协处理器部署在RegionServer上。
协处理器的设计
就好比MySQL中的触发器一样,MySQL的触发器有针对update、insert和delete的,还有before和after等等,协器也有类似的对应函数。比如,在本项目中,需要的是再插入一条数据后,协处理器被触发插入另外一条“重复数据”,所以复写的方法是postPut。
设计具体逻辑是:根据插入的Put获得插入的数据信息,然后判断插入的标志位Flag是不是1,如果是1,则插入另外一条重复数据。
下面是代码:
public class InsertCalleeCoprocessor extends BaseRegionObserver {
/**
* 这是HBase上的协处理器方法,在一次Put之后接下来的动作
*
* @param e
* @param put
* @param edit
* @param durability
* @throws IOException
*/
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
// 1. 获取表对象
Table table = e.getEnvironment().getTable(TableName.valueOf(Names.TABLE.getValue()));
// 2. 构造Put
// 在rowKey中存在很多数据信息,这一点就不具备普适性
String values = Bytes.toString(put.getRow());
String[] split = values.split("_");
String call1 = split[1];
String call2 = split[2];
String callTime = split[3];
String duration = split[4];
String flag = split[5];
// 在协处理器中也发生了Put操作,但是此时的Put不引发协处理器再次响应
// 必须得关闭表连接
if ("0".equals(flag)) {
table.close();
return;
}
CoprocessorDao dao = new CoprocessorDao();
String rowKey = dao.genRegionNums(call2, callTime) + "_" + call2 + "_" + call1 + "_" + callTime + "_" + duration + "_" + "0";
Put calleePut = new Put(Bytes.toBytes(rowKey));
calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("call1"), Bytes.toBytes(call2));
calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("call2"), Bytes.toBytes(call1));
calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("callTime"), Bytes.toBytes(callTime));
calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("duration"), Bytes.toBytes(duration));
calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("flag"), Bytes.toBytes("0"));
// 3. 插入Put
table.put(calleePut);
// 4. 关闭资源,否则内存会溢出
table.close();
}
private class CoprocessorDao extends BaseDao {
public int genRegionNums(String tel, String date) {
return super.genRegionNum(tel, date);
}
}
}
需要注意的问题:
- 编完协处理器代码后需要修改创建表的数据,在添加的表描述器上添加编写的协处理器类全路径,并且将打包发给集群,记住分发。
- 判断标志位是否为1,为1才被触发,因为协处理器触发发送的“重复”数据也会被协处理器自身感应到。
- 在协处理器上面插入数据后,要关闭表的连接,否则内存会溢出。
遇到的问题和解决方案
- 在老师给的代码,在执行过程中,发现slave1和slave2中RegionServer挂掉了,然后我手动启动并且查看HBase中的数据,观察到数据存在并且无误,然后在master:16010上观察所有的分区都在master的RegionServer上,正常。
但是为什么会我的挂掉呢,明明虚拟机的配置是一样的,果断查看日志发现out of memory,内存溢出了,心念一转怕不是代码有问题。果不其然,在代码中,先是打开的table连接,然后进行标志位的判断,如果为1发送数据后关闭连接,但是在标志位为0的时候没有关闭连接,所以内存才会溢出,修改完事儿! - 这里就是笨逼(没错,就是我)犯下的错误,我在修改完后打包上传......怎么出错了,我几乎整了半天才发现我居然没分发!!!分发后就可以看到较好的效果。这就完了?我讲讲最后我是怎么发现没分发,没分发的过程中slave1和slave2的RegionServer总是挂掉,并且还是内存出错(所以我才懵,当时我觉得是我的机子不行,
换机子,所以直接kill slave1和slave2的RegionServer在开始执行,得到了和之前相同的结果,但是内存的问题我应该是解决了的,所以那只可能是代码的问题了。下载下来一看,不一样,我懂了,Nicer,这就赏自己两嘴巴子!(哭
当然,这也是一次记忆深刻的debug!!!
总结
这个流程是我学习最多的流程,除了复习这个大数据框架的API,更多的是对我的Java有了更多的拓展。除了上述提到的,还有一些注解,泛型和泛型的PECS原则等等。另外就是学习怎么一步步排除错误和寻找自己的(低级)错误的方法了,这种DeBug的方式对于我来说很新鲜。
数据分析
同时利用redis缓存数据,利用MapReduce将HBase中的数据提取到MySQL中。
DeBug分析
出现的问题:MapReduce任务执行成功,但是MySQL中未插入数据,同时查看MapReduce8088端口,看不到日志,显示no log for container available。
问题分析:
1.观察MapReduce的任务,发现Reduce的确是正确输出了字节,但是MySQL没有插入数据,那只可能是编写的OutputFormat出现了问题。
2.no log for container available, 在网上查阅资料提示有可能是内存不足的问题。
3.查看MapReduce的Reduce任务,发现是在nodemanager是在slave1上运行,而slave1只分配了2G内存。
4.kill slave1和slave2的nodemanager,只运行master的nodemanager,因为master我分配了4G内存。
5.查看日志成功,寻找错误。
6.发现是MySQL语句出现了语法错误????????(离谱,就**离谱)
7.修改MySQL语句,任务成功执行。
总结
这是我的一个学习上手的大数据项目,虽然简单但是也学习不少。做这个项目的时候是考试周,也算是忙里偷闲完成了!主要是这个项目和我们小队准备参加的服创大赛的项目很类似,也算是提前练练手,熟悉下基本的流程。不过我们小队的项目最好还是得上Spark和好的机器(虚拟机老拉跨,所以继续学习!!!

