RCNN、Fast-RCNN、Faster-RCNN的算法步骤以及其中的难点
写在前面的话
在目标检测的历史中,RCNN的出现使得深度学习和目标检测结合在了一起,RCNN的出现就是这一发展的开端。
在我自己的学习中,结束了Selective Search的学习后,自然就开始学习了RCNN,本来想三个RCNN一个一个学的,后来发现这三个之间的联系非常紧密,并且是一步一步将所有的工作就放入深度学习中,(重点是只有faster-rcnn的开源代码)doge所以我先学习了三种算法的原理和步骤以及区别,后面便是针对一份开源代码进行理解和加深。发现自己水文字的能力挺强🐶
RCNN
算法步骤
Step 1:分割候选区域(一般采用Selective Search方法、Slide Window方法等)我上一篇文章、关于Selective Search
Step 2:每个候选区域进入到CNN网络中提取特征向量
Step 3:对于提取到的特征向量,利用支持向量积进行分类,同时对其进行边界框回归 (难点 为什么要边界框回归和怎么进行?)
RCNN 难点
为什么要边界框回归和怎么进行
答:
1.之所以要进行边界框回归,是因为仅仅靠第一步分割的候选区域和真正的ground truth相比比较粗糙,利用边界框回归可以候选框更加细致。
2.边界框回归的具体可以看我参考博客的第2条,下面说说我的理解:
首先介绍一些名词:
| 名词变量 | 解释 |
|---|---|
| ground truth | 人工标记的目标框,包含四个参数,分别是xmin,ymin,xmax,ymax |
| bounding box | 一般指的是算法中的候选框,简记为bbox,同理也包含相同的参数 |
| (xmin,ymin) | 框的左下角 |
| (xmax,ymax) | 框的右上角 |
| 关于边界框的回归,直观但是错误的理解是根据提取的特征向量学习(xmin,ymin,xmax,ymax)坐标,然后利用平方损失函数梯度下降等等,修改可学习的参数;实际上边界框回归学习的是bbox和ground truth之间的变形比例,变形比例包含了平移变换和缩放变换。 | |
| 为了学习平移变换和缩放变换比例,进行如下变换: | |
| 原来的坐标 | 后来的坐标 |
| -- | -- |
| bbox的坐标\(P(x_{min},y_{min},x_{max},y_{max})\) | \(P(x,y,w,h)\) |
| ground truth的坐标\(G(x_{min},y_{min},x_{max},y_{max})\) | \(G(x,y,w,h)\) |
| 其中\(x = \frac{x_{min}+x_{max}}{2},y = \frac{y_{min}+y_{max}}{2},w = x_{max}-x_{min},h = y_{max}-y_{min}\) | |
| RCNN中的变形转换关系: | |
| \(\hat{G_x} = P_wd_x(P)+P_x\) | |
| \(\hat{G_y} = P_hd_y(P)+P_y\) | |
| \(\hat{G_w} = P_w\exp(d_w(P))\) | |
| \(\hat{G_h} = P_h\exp(d_h(P))\) | |
| 我们的目的就是求的\(d_x(P),d_y(P),d_w(P),d_h(P)\)使得两个框最接近,这四个参数都是通过提取到的特征向量\(\phi(P)\)学习出来的,即\(d_*(P) = w_*\phi(P)\),这里的\(w_*\)就是边界框回归需要学习的参数,而\(d_*(P)\)是学习的结果。 | |
| 学习目标:$w_* = {argmin}{w} \sum_iN(t_*i-w_\phi(P))+\lambda{ | |
| 其中:\(t_x = \frac{G_x-P_x}{P_w},t_y = \frac{G_y-P_y}{P_h},t_w = log(\frac{G_w}{P_w}),t_h = log(\frac{G_h}{P_h})\) | |
| 这就是边界框回归的内容了,通过这个优化问题就可以求出最合适的变形比例。 |
Fast-RCNN
算法步骤
Step 1:分割候选区域,同RCNN第一步
Step 2:将整个图片都放入CNN网路中提取特征图(这里和RCNN就不同了,因为没有将候选区域一个一个放入CNN,所以速度得到了极大的提升)
Step 3:找到原图上的候选区域ROI在特征图上的映射 (难点1 原图和特征图之间的映射?)
Step 4:对于每个ROI映射采用ROI Pooling(简单的说就是使不规则的输入变成规则的输出,可以认为是在根据输出反推pool层的Bins) (难点2 什么是ROIpooling?)
Step 5:接全连接层,预测分类和边界款回归
Fast-RCNN 难点
步骤2中原图和特征图之间的映射?
在介绍原图和特征图之间的映射之前,首先介绍一个重要的概念:
感受野概念
在机器视觉领域的深度神经网络中有一个概念叫做感受野,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。神经元之所以无法对原始图像的所有信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部相连(通过sliding filter)。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。(来自参考资料,第三条)
简单来说,就是一个神经元的输出是由输入图像哪些区域(field)决定
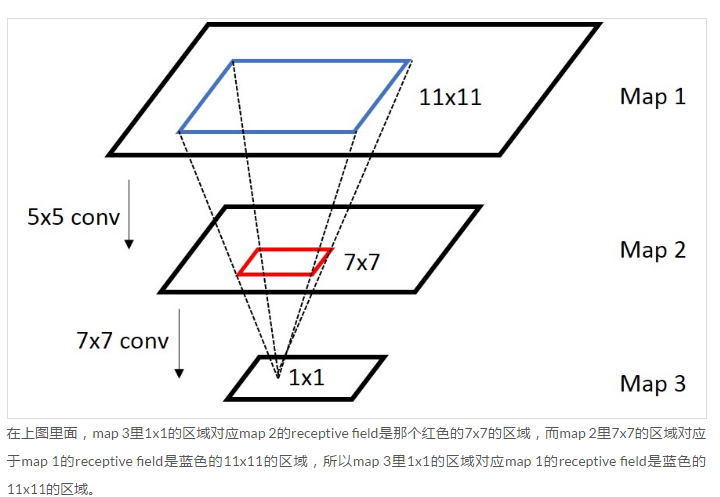
上图中,如果第一层是原图输入的话,那么第二层卷积神经网络的神经元的感受野为11。
感受野计算公式
\(r_n = r_{n-1}\times k_n - (r_{n-1} - \prod_{i=1}^{n-1}s_i)\times(k_n - 1) = r_{n-1} + (k_n - 1)\prod_{i=1}^{n-1}s_i,n\geq 2\)
\(r_i\):表示第i层神经元的感受野大小,\(k_i\):表示第i层的卷积层kernel_size,\(s_i\):表示第i层的步长。
需要注意的是r1计算是没有标明的,而且r0 = 1;同时,只有神经元具有感受野,输出的图像并不具备,但是直观上来讲,总是卷积层的输出的一个像素点对应原图的范围,但是不是该像素点具有感受野,这是我自己经常理解错误的细节,所以r0 = 1也是存在一定争议的,因为并不具备神经元,但是直观上来说输入图像上的一像素点确实只能看见自己。
(具体内容可以见参考资料第三条,不足的就是只有卷积层的计算公式没有其他层的,总觉着这里有缺陷)
感受野上的坐标映射
公式:一般都是中心点的映射(具体内容见参考资料第四条)
\(for\quad conv/pooling\quad layer: p_i = s_ip_{i+1}+\frac{k_i-1}{2}-padding\)
\(for\quad activate\quad cell : p_i = p_{i+1}\)
\(p_i\):表示神经网络中第i张特征图(包括原图)的坐标,
当然如果padding的取值为\(\lfloor \frac{k_i}{2}\rfloor\),对于卷积或者池化层,公式变为\(p_i = s_ip_{i+1}\),同时对公式进行级联,可知第i+1个特征图上任意一点对应于原图的坐标\(p_0 = p_{i+1}\prod_{j=0}^is_j\)
什么是ROIpooling?
一般情况下的pooling层是给定pool层的系数,对特征图进行池化操作,但是在这个fast-rcnn中,每个区域的大小不完全相同,导致通过正常的pool层后,特征向量大小不同无法进行下一步转换。
ROIpooling是一种特殊pool层,特殊的地方在于不要求输入特征图和pool层的大小,但是规定了输出的特征向量大小,也就是说,根据输入特征图的大小和规定的输出尺寸,反推在输入特征图上的Bins,然后在Bins上进行max或者average操作。
ROIpooling过程:根据给定的特征图和ROIs,找到每个ROI在特征图上的映射,然后放入ROIpooling层进行转换操作
Faster-RCNN
算法步骤
Step 1: 将整张图片放入网络的extractor中提出特征图(可以发现没有了独立于网络的提取候选区域)
Step 2:利用RPN网络(Region Proposal Network)提取候选区域ROI(候选区域是针对原图的,而不是提取的特征图),此时候选区域应该称作anchor boxes。(难点 RPN?)
Step 3:ROIpooling
Step 4: 接全连接层,预测分类和边界框回归
这里可以很明显的看到,整个过程都是利用了神经网络和深度学习,没有任何独立的步骤。(在代码中可以发现,网络流程中包含了很多creator,但没有独立于网络)
Faster-RCNN 难点
RPN的网络结构
- 首先看看RPN的整体结构:可以看到是由一个3x3的卷积层,然后分别接上1x1x18的卷积层和1x1x36的卷积层组成。
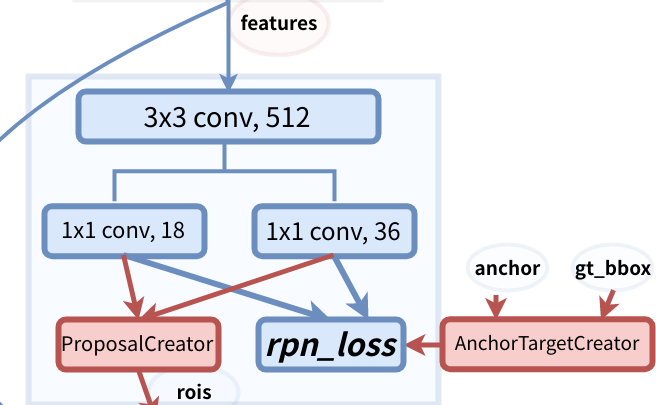
设图中features的大小为(C,H,W),通过3x3卷积层后,特征图为(512,H,W)(至于为什么特征图的H和W没有变化是由于卷积核的巧妙设置),接着分别通过两个卷积层,特征图变为(18,H,W)和(36,H,W)
- 这么设计网络结构的理由是:(来自于CSDN博主懒人元的理解,我觉得很能够接受,参考资料第1条)
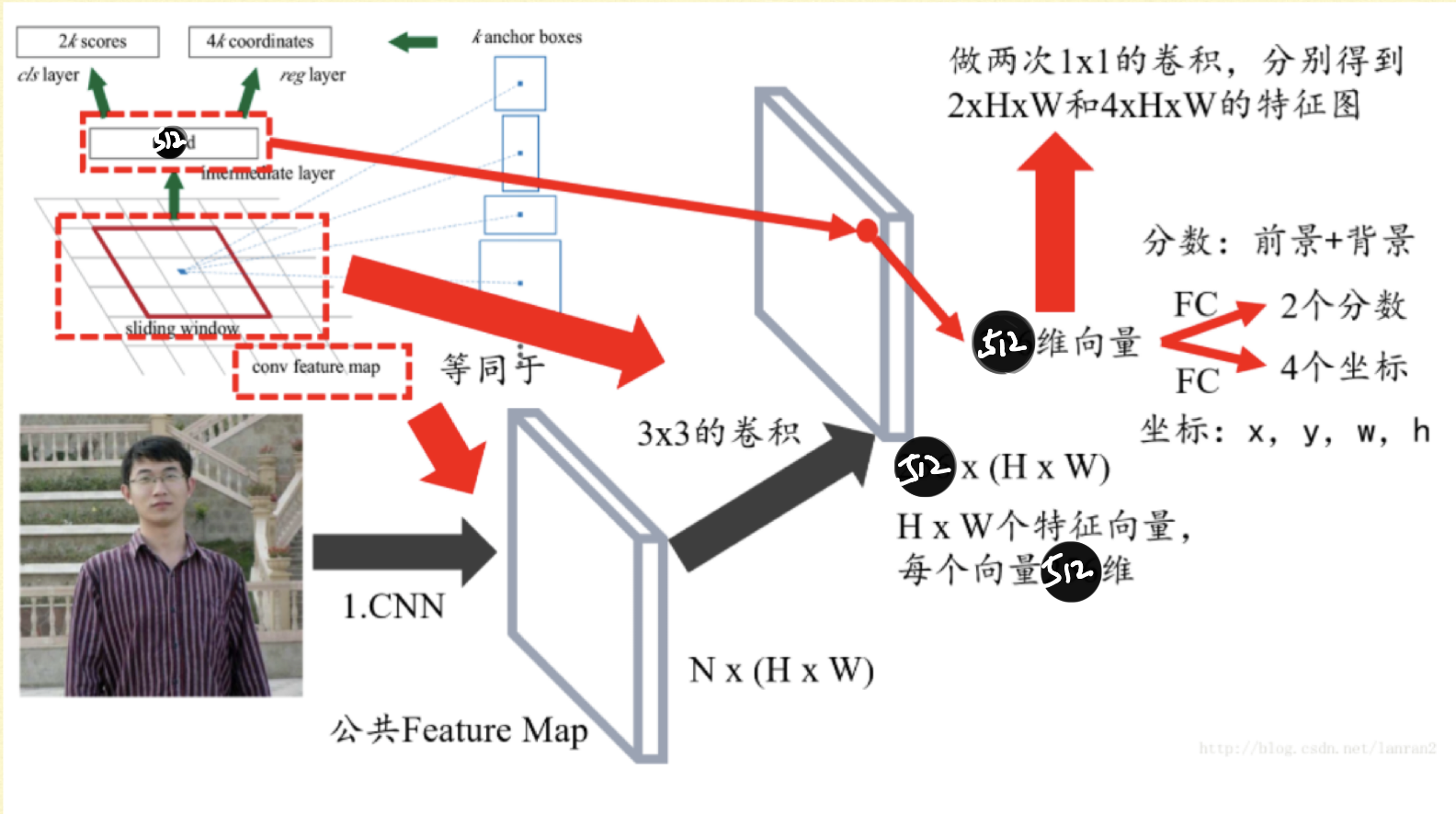
1.首先对特征图进行3x3的卷积(图片左上角),通过调整卷积核的参数,可以相当于在特征图上进行滑动窗口为3x3的滑动窗口分割图像,输出的大小为(512,H,W),相当于H*W个特征向量。
2.在每个位置上,对特征向量接入两个全连接层,大小分别是(512,2)和(512,4),可以得到这个位置在原图上的感受野区域是前景还是背景的得分(2),还有感受野区域的变形比例(4)(图中是x,y,w,h,我觉得应该不是,而且在代码也是求出变形比例)。
3.引入anchor box的内容,在每个像素点上都具有9个固定大小的anchor boxes,那么两个全连接层的大小应该是(512,18)和(512,36),也就是第二点的描述中,感受野区域变为了H*W*9个anchor boxes。
4.同时两个全连接层可以用1x1x18和1x1x36的卷积核代替
5.生成的anchor box可以通过非极大抑制和“加上”变形比例等操作生成我们需要的ROIs,候选区域。
至于RPN的损失和训练方式,在代码中就可以看到,原理层面我不太会用语言描述
参考博客和资料
感谢他们🎉🎉🎉🎉,接下来就是对代码的整体逻辑和重点代码进行描述和理解啦
同一博主我只贴上一份链接
- RPN解析--懒人元--CSDN
- bounding box理解--huapyuan--cnblog
- 深度神经网络中的感受野(Receptive Field)--蓝荣祎--zhihu
- 原始图片中的ROI如何映射到到feature map?--lemon--zhihu

 浙公网安备 33010602011771号
浙公网安备 33010602011771号