Spark Core实验
按照厦大给出的大数据学习路线,开始了spark的学习,这是spark基础的实验。我们常说的Spark在Spark生态中应该指的是Spark-Core负责批处理的部分,而Spark中还有Spark SQL,Spark Streaming、Spark MLlib和GraphX的组件。
1.pyspark交互式编程
请到教材官网的“下载专区”的“数据集”中下载chapter4-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,8
……
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1)该系总共有多少学生;
data.map(lambda x:x.split(',')).map(lambda x:(x[0],x[1:])).groupByKey().count() # 265
(2)该系共开设了多少门课程;
data.map(lambda x:x.split(',')).map(lambda x:(x[1],'')).groupByKey().count() # 8
(3)Tom同学的总成绩平均分是多少;
data.map(lambda x:x.split(',')).map(lambda x:(x[0],int(x[2]))).filter(lambda x:x[0]=='Tom').mapValues(lambda x:(x,1)).reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).mapValues(lambda x:x[0]/x[1]*1.0).foreach(print) # (Tom,30.8)
(4)求每名同学的选修的课程门数;
data.map(lambda x:x.split(',')).map(lambda x:(x[0],1)).groupByKey().mapValues(lambda x:sum(x)).foreach(print)

(5)该系DataBase课程共有多少人选修;
data.map(lambda x:x.split(',')).map(lambda x:(x[1],1)).groupByKey().mapValues(lambda x:sum(x)).filter(lambda x:x[0]=='DataBase').foreach(print) # ('DataBase',126)
(6)各门课程的平均分是多少;
data.map(lambda x:x.split(',')).map(lambda x:(x[1],(float(x[2]),1))).reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).mapValues(lambda x:x[0]/x[1]).foreach(lambda x:print("({},{:.2f})".format(x[0],x[1])))
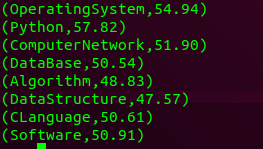
(7)使用累加器计算共有多少人选了DataBase这门课。
data.map(lambda x:x.split(',')).map(lambda x:(x[1],1)).filter(lambda x:x[0]=='DataBase').map(lambda x:x[1]).reduce(lambda a,b:a+b) # 126
2.编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
from pyspark import SparkConf,SparkContext
data = sc.textFile('file:///home/hadoop/Desktop/SparkPractice/practice/dataset2')
data.map(lambda x:(x,'')).\
groupByKey().\
map(lambda x:x[0]).\
repartition(1).\
saveAsTextFile('file:///home/hadoop/Desktop/SparkPractice/practice/dataset2/C')

3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster('local').setAppName('Get Average')
sc = SparkContext(conf = conf)
data = sc.textFile('file:///home/hadoop/Desktop/SparkPractice/practice/dataset3')
data.map(lambda x:x.split(' ')).\
map(lambda x:(x[0],(float(x[1].strip()),1))).\
reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).\
mapValues(lambda x:x[0]/x[1]).\
repartition(1).\
saveAsTextFile('file:///home/hadoop/Desktop/SparkPractice/practice/dataset3/output')

PySpark操作HBase
PySpark从HBase中读入
要注意读出的值是String类型,在转换器那里也说明了,但是看上去很像dict类型。
#!/usr/bin/env python3
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster('local').setAppName('ReadHBase')
sc = SparkContext(conf = conf)
host = 'localhost' # zookeeper主机位置
table = 'student' # 选择读的HBase表
conf = {'hbase.zookeeper.quorum':host,'hbase.mapreduce.inputtable':table}
keyConv = 'org.apache.spark.examples.pythonconverters.ImmutableBytesWritableToStringConverter' # 转换器:HBase中的键转换成Python可读的String类型
valueConv = 'org.apache.spark.examples.pythonconverters.HBaseResultToStringConverter' # 转换器:HBase中的值转换成Python可读的String类型
rdd = sc.newAPIHadoopRDD('org.apache.hadoop.hbase.mapreduce.TableInputFormat','org.apache.hadoop.hbase.io.ImmutableBytesWritable','org.apache.hadoop.hbase.client.Result',keyConverter = keyConv,valueConverter = valueConv,conf = conf).cache()
# 第一个参数是HBase表的输入类型,第2,3个参数是表的键值类型
count = rdd.count()
print("counts : {}".format(count))
rdd.foreach(print)
print(type(rdd.first()[0]))
PySpark写入HBase
#!/usr/bin/env python3
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster('local').setAppName("WriteHBase")
sc = SparkContext(conf = conf)
host = 'localhost' # zookeeper所在的主机名
table = 'student' # 插入的表名
keyConv = 'org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter' # 转换器: 将String类型的值转换为HBase可存储的键类型
valueConv = 'org.apache.spark.examples.pythonconverters.StringListToPutConverter' # 转换器:将StringList类型的值转换为HBase可存储的值类型
conf = {'hbale.zookeeper.quorum':host,'hbase.mapred.outputtable':table,'mapreduce.outputformat.class':'org.apache.hadoop.hbase.mapreduce.TableOutputFormat','mapreduce.job.output.key.class':'org.apache.hadoop.hbase.io.ImmutableBytesWritable','mapreduce.job.output.value.class':'org.apache.hadoop.io.Writable'}
# 第三个参数是表的输出类型,第4,5个参数是表的键值类型
rawData = ['3,info,name,RongCheng','3,info,gender,M','3,info,age,26','4,info,name,Guanhua','4,info,age,27','4,info,gender,M']
sc.parallelize(rawData).map(lambda x:(x[0],x.split(','))).saveAsNewAPIHadoopDataset(conf = conf,keyConverter = keyConv,valueConverter = valueConv)
总结
- 要合理使用分区,当进行全局性的操作时,例如排序,就需要合并分区。
- 不能将所有的内容合在一个分区中的一个元素上进行操作,这样子就失去了并行化的优势。比如求平均数,将所有的数放在一个元素上然后使用Python的sum(array)/len(array)。
- 输出文件一般写的是目录,要想自己自定义输出的各个文件的名称的话就需要自己重写saveAsTextFile函数,否则就是part-0000?。
- .saveAsTextFile对象有几个分区,就会保存下来几个文件
- 注意持久化的保存,上面的实验都是可以一条语句完成的,如果不是则为了加快速度,可以将中间生成并且需要二次使用的RDD放入内存中。persist(),参数有MEMORY_ONLY和MENMORY_AND_DISK,前者相当于.cache(),与之相反对应的就是unpersist()

