MapReduce实验
1|0MapReduce实验
如何在Eclipse中运行MapReduce程序,参考厦大数据库实验室博客
总体代码:
2|01.编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
输入文件A的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件B的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
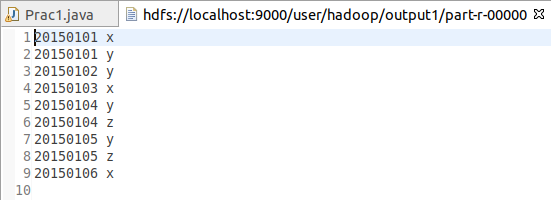
根据输入文件A和B合并得到的输出文件C的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
设计思路:
| 操作 | <key, | value> |
|---|---|---|
| map()读取 | 每一行的行号 | 每一项内容,例如"20150104 z" |
| map()输出 | 读取的value,每一项内容 | 空白Text,只是占位表示一下 |
| reduce()读取 | 独立的每一项内容 | 空白Text的迭代器 |
| reduce()输出 | 独立的每一项内容 | 空白Text,只是占位表示一下 |
Java代码
3|02. 编写程序实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例供参考。
输入文件1的样例如下:
33
37
12
40
输入文件2的样例如下:
4
16
39
5
输入文件3的样例如下:
1
45
25
根据输入文件1、2和3得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
设计思路:
| 操作 | <key, | value> |
|---|---|---|
| map()读取 | 文件每一行的行号 | 每一行的数字 |
| map()输出 | 每一行的数字 | 1,无意义,标识字符 |
| reduce()读取 | 排序好的数字 | 1,无意义,标识字符 |
| reduce()输出 | 序号 | 排序好的数字 |
- 序号:编写的Reducer类中继承了原生的Reducer类中,重载了reduce函数,并且引入了一个记数的全局变量(static标记),每接收一个<key,value>便加一。
- 疑惑之处:在map以后的shuffle是看不到的,MapReduce框架中就包含了shulffle并且在shuffle中就包含了排序,但是按照我的理解在shuffle中的排序应该只是针对一个map的机器或者是任务才对,(模糊记得要先到缓存再到磁盘,所以我在网上看到许多同学都是用了partion归类,我不知道有啥用,我觉得我这个程序能完成任务的原因可能是我才用的是伪分布式安装的hadoop,只有一台机器。(????)
Java代码

4|03. 对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
输入文件内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
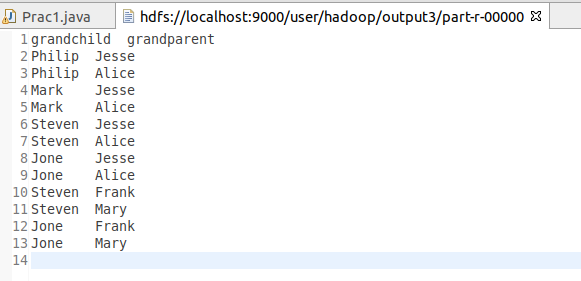
输出文件内容如下:
grandchild grandparent
Steven Alice
Steven Jesse
Jone Alice
Jone Jesse
Steven Mary
Steven Frank
Jone Mary
Jone Frank
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
设计思路:
| 操作 | <key, | value> |
|---|---|---|
| map()读取 | 每一行的行号 | 子辈和父辈的内容 |
| map()输出 | 针对每一行都输出两次,第一次是子辈,第二次是父辈 | 第一次是父辈,第二次是子辈 |
| reduce()读取 | 1.接收到子辈 | 父辈 |
| reduce()读取 | 2.接收到父辈 | 一定有子辈,可能存在祖辈 |
| reduce()读取 | 3.接收到祖辈 | 父辈 |
| reduce()输出 | 子辈 | 祖辈 |
| 上述的子辈、父辈和祖辈都是相较而言的。比如如果四世同堂的话,第三世相较于第一世是子辈,相较于第四世是父辈。 | ||
| 每接收到一份数据,交换顺序输出两次,在shuffle中按照键值归并,这样就能将存在祖辈和子辈的数据找出来,并且为了不将祖辈和子辈混淆,在map输出的value中标记是old还是young。 |
Java代码
人生此处,绝对乐观
__EOF__

本文链接:https://www.cnblogs.com/ginkgo-/p/13273671.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现