推荐系统学习-特征工程(LR,FM)-代码
在一口气看完项亮老师的《推荐系统实践》后,又花费几天看完了王喆老师的《深度学习推荐系统》,虽然学过一门深度学习的课,但是直接看推荐系统的深度学习还是有点不懂的(手动狗头×)。在上一篇的协同过滤后,这一篇来记录协同过滤后推荐系统的发展,也就是特征工程。
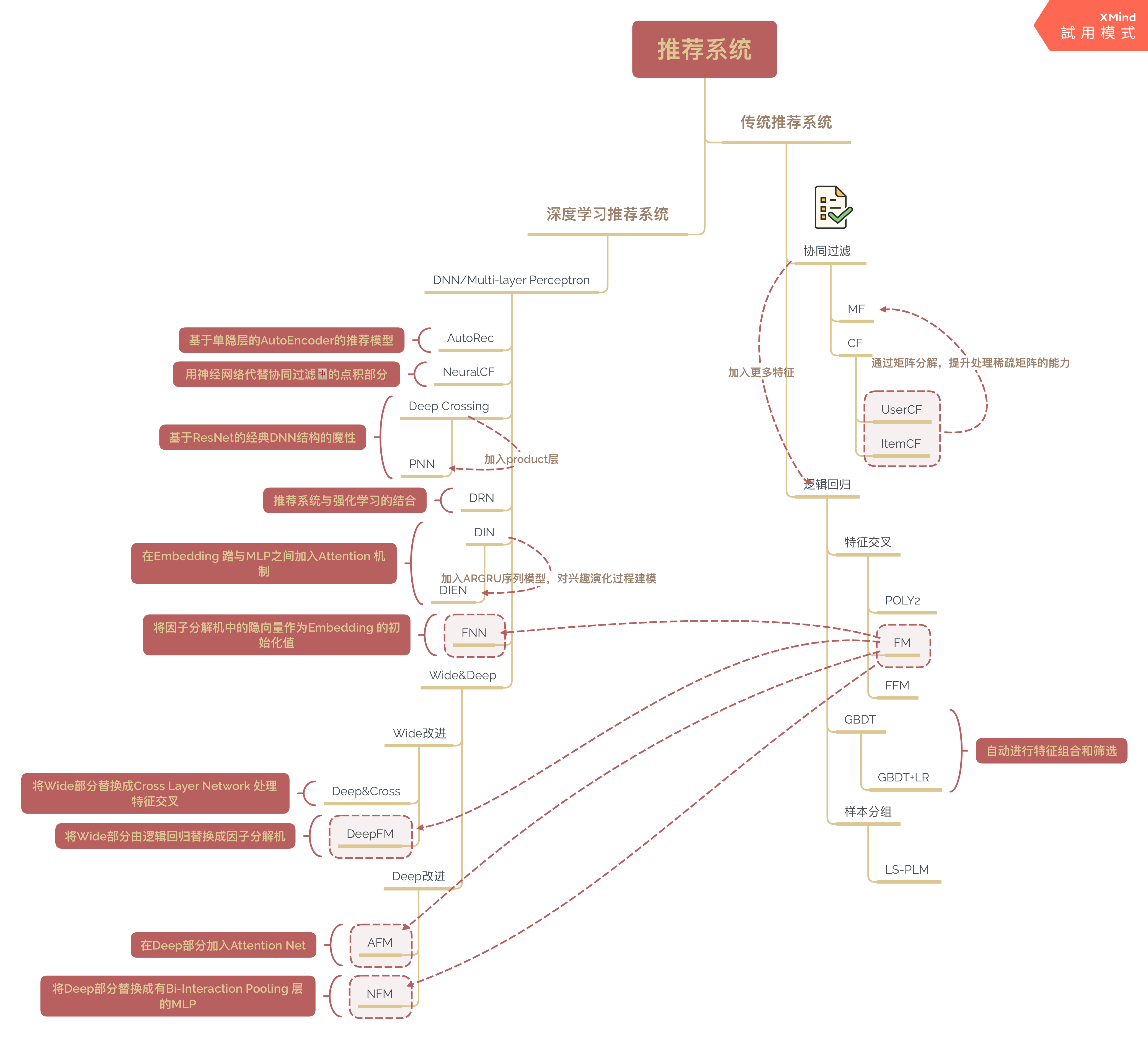
(图片有点大,可右键点击查看)
推荐系统前沿 之 特征工程
协同过滤只使用了用户和物品的信息,缺少了其他的内容、社交、上下文信息,导致推荐结果不理想,所以引入LogisticRegression模型(LR),在预测用户是否点击推荐物品时,加上用户和物品的其他信息。接下来的发展,普通的特征直接构建模型转变成对特征进行交叉处理获得更有表达能力的特征。普通的二阶交叉就是接下来我实现的FM(因子分解机),高阶交叉有GBDT+LR和神经网络(前面几层就相当于是对特征进行处理,最后面一层是利用处理好的特征进行判断)。
基本概念
- CTR:Click Through Rate,点击率问题,用户是否点击为最终目标。对于一条用户、物品和上下文信息的输入,用户若是观看了则真实输出为1。也就是说将推荐问题转换为点击率预估问题。
但是一般说来,用户日志记录中只存在正样本。也就是说对于一名用户,知道他看了什么,换句话说知道了他喜欢看什么,但是对于一个未知的物品,并不能准确判断这名用户的态度,即缺少负样本。 - 负样本抽取:在《推荐系统实践》中介绍了并且评估了四种方法。
| 方法 | 效果 |
|---|---|
| 对于一个用户,用他所没有过行为的物品作为负样本 | 1 |
| 对于一个用户,他所没有过行为的物品中均匀采样出一些物品作为负样本 | 3 |
| 对于一个用户,他所没有过行为的物品中采样出一些物品作为负样本,并保证数目相当 | 4 |
| 对于一个用户,他所没有过行为的物品中采样出一些物品作为负样本,并偏重那些不热门的物品 | 2 |
| 在KDD Cup的Yahoo!Music推荐系统比赛中,发现了负样本抽取的原则:一是要保证对于每个用户,正负样本平衡,二是对于每个用户的负样本采样时要选取那些很热门但是用户却没有行为的物品。 |
逻辑回归
公式:\(\hat{y}=\sum_{i=1}^n w_ix_i\)
代码和过程之前我的理解:将推荐问题转化为CTR问题后,就会发现其实就是一种分类问题。只是相比于常见的分类,输入的特征不同,需要的处理方法不同而已。
推荐过程:
(1) 将用户年龄、性别、物品属性、物品描述、当前时间、当前地点等特征转换成数值型向量。(十分简单的转换,深度学习大部分利用的Embedding技术)
(2) 确定逻辑回归模型的优化目标(以优化“点击率”为例),利用已有样本数据对逻辑回归进行训练,确定逻辑回归模型的内部参数。(这里就要用到负样本抽取)
(3) 在模型服务阶段,将特征向量输入逻辑回归模型,经过逻辑回归模型好的推断,得到用户“点击”物品的概率。(模型输出\(\hat{y}\))
(4) 对于每个用户,利用点击概率进行排序,得到推荐列表。(最终推荐精确率来自于推荐列表的元素有多少在验证集中,因为验证集是用户真实点击了的)
我利用pytorch实现了这个模型。
import pandas as pd
import numpy as np
from tqdm import tqdm
import torch as t
import torch.nn as nn
import torch.nn.functional as F
from datetime import *
import matplotlib.pyplot as plt
import ipdb
import fire
import random
import copy
def Get_occupation2number(file='./ml-100k/u.occupation'):
'''
职业转换成数值方便模型处理
@params
file:职业对应的文件
@return
table:职业转换表
'''
table=pd.read_csv(file,header=None)
table['index']=range(table.shape[0])
table=table.set_index([0])
return table
def Get_movie2number(file='./ml-100k/u.genre'):
'''
电影类型转换成数值方便模型处理
@params
file:电影类型对应的文件
@return
table:电影类型转换表
'''
table=pd.read_csv(file,header=None,delimiter='|')
table=table.set_index([0])
return table
occupation2number=Get_occupation2number()
movie2number=Get_movie2number()
def Get_user_table(file='./ml-100k/u.user',occupation2number=occupation2number):
'''
获得用户信息表,用户id为索引
@params
file:用户信息表对应文件
occupation2number:职业转换表,将user信息中的职业转成数值
@return
table:用户信息表
'''
table=pd.read_csv(file,header=None,delimiter='|')
table.columns=['user','age','gender','occupation','zip_code']
table['gender']=table['gender'].map(lambda x: (1 if x=='M' else 0))
table['occupation']=table['occupation'].map(lambda x:occupation2number.loc[x,'index'])
table['big_mailset']=table['zip_code'].map(lambda x:(int(x[0]) if x.isdigit() else 5))
table['medium_mailset']=table['zip_code'].map(lambda x:(int(x[1:3]) if x.isdigit() else 54))
table['small_emailset']=table['zip_code'].map(lambda x:(int(x[3:]) if x.isdigit() else 14))
table.drop(['zip_code'],axis=1,inplace=True)
table['g_user']=table['user'] # 用户id也是一个重要的特征
table=table.set_index(['user'])
mean=table.mean(axis=0)
std=table.std(axis=0)
table=(table-mean)/std
return table
def Get_item_table(file='./ml-100k/u.item',movie2number=movie2number):
'''
获得物品信息表,物品id为索引
@params
file:物品信息表对应文件
occupation2number:电影类型转换表,将item中的电影类型转成数值
@return
table:物品信息表
'''
table=pd.read_csv(file,header=None,delimiter='|',encoding='unicode-escape')
col=['movie','title','release_date','date','url']
col.extend(list(movie2number.index))
table.columns=col
month_dict={'Jan':1,'Feb':2,'Mar':3,'Apr':4,'May':5,'Jun':6,'Jul':7,'Aug':8,'Sep':9,'Oct':10,'Nov':11,'Dec':12}
table['release_date']=table['release_date'].fillna('01-Jan-1995')
table['month']=table['release_date'].map(lambda x:month_dict[x.split('-')[1]])
table['day']=table['release_date'].map(lambda x:int(x.split('-')[0]))
table['year']=table['release_date'].map(lambda x:int(x.split('-')[2]))
table.drop(['title','date','url','release_date'],axis=1,inplace=True)
table['g_movie']=table['movie'] # 物品id也是一个重要特征
table=table.set_index(['movie'])
mean=table.mean(axis=0)
std=table.std(axis=0)
table=(table-mean)/std
return table
u_table=Get_user_table()
i_table=Get_item_table()
def Get_train_data(train_file,test_file):
'''
获得训练用的数据
@params
train_file:训练数据集文件
test_file:测试数据集文件
@return
train:训练数据,DataFrame格式
test:测试数据,DataFrame格式
'''
train=pd.read_csv(train_file,header=None,delimiter='\t')
test=pd.read_csv(test_file,header=None,delimiter='\t')
col=['user','movie','ratings','timestap']
train.columns=col
test.columns=col
combine=[train,test]
for dataset in combine:
dataset['watch_year']=dataset['timestap'].map(lambda x:date.fromtimestamp(x).year)
dataset['watch_month']=dataset['timestap'].map(lambda x:date.fromtimestamp(x).month)
dataset['watch_day']=dataset['timestap'].map(lambda x:date.fromtimestamp(x).day)
dataset.drop(['timestap'],axis=1,inplace=True)
train,test=combine
return train,test
def Insert_neg_samples(data):
'''
为训练样本插入负样本,这里实现的是对于每个用户,插入差不多相同数量的负样本呢,并没有考虑插入样本热门程度
@params
data:待插入的数据集
@return
res_data:插入后的数据集
'''
# print('插入负样本之前:{}'.format(data.shape))
res_data=data.copy()
for user in data['user'].unique():
watched_movie=list(data.loc[(data['user']==user).tolist(),'movie'])
l=len(watched_movie)
count=0
no_watched={'user':user,'movie':[],'ratings':0}
iindex=copy.copy(list(i_table.index))
random.shuffle(iindex)
for movie in iindex:
if movie in watched_movie:
continue
elif np.random.randint(0,10)>5:
no_watched['movie'].append(movie)
count+=1
if count==l:
break
no_watched_df=pd.DataFrame(no_watched,index=range(len(no_watched['movie'])))
no_watched_df=no_watched_df.loc[:,['user','movie','ratings']]
res_data=res_data.append(no_watched_df,ignore_index=True)
# print('插入负样本之后:{}'.format(res_data.shape))
return res_data
class LR(nn.Module):
'''
逻辑回归单元++
'''
def __init__(self,input_dim):
super(LR,self).__init__()
self.fc1=nn.Linear(input_dim,2)
def forward(self,input):
return self.fc1(input)
class rec_dataset(t.utils.data.Dataset):
def __init__(self,filename,train=True,test=False):
self.train_data,self.test_data=Get_train_data('./ml-100k/u{}.base'.format(filename),'./ml-100k/u{}.test'.format(filename))
self.u_table=u_table
self.i_table=i_table
self.data=None
if train:
self.train_data=self.train_data[['user','movie','ratings']]
self.data=Insert_neg_samples(self.train_data,i_table)
elif test:
self.test_data=self.test_data[['user','movie','ratings']]
self.data=self.test_data
else:
print('未找到合适的数据')
def __len__(self):
return self.data.shape[0]
def __getitem__(self,index):
label=(1 if self.data.loc[index,'ratings']>0 else 0) # 分类问题,而不是预测评分问题。TOPN问题
user=self.data.loc[index,'user']
movie=self.data.loc[index,'movie']
info=Combine(user,movie)
return t.tensor(info,dtype=t.float),t.tensor(np.array(label,dtype=np.int64))
def draw(y):
'''
画出y的变化
@params
y:序列,array结构
'''
plt.plot(np.arange(1,len(y)+1),y,'go-')
plt.xlabel('EPOCH')
plt.ylabel('LOSS')
plt.title('Training Loss')
plt.show()
def Train(filename,batch_size=64,model_path=None,epoches=10,device='cpu'):
'''
利用插入好的样本进行训练
@params
filename:训练的数据文件
batch_size:每次训练的batch大小
model_path:模型路径,判断是否存在训练好的模型
epoches:迭代次数
device:训练的硬件设备
@return
None:但是会保存训练好的模型
'''
# ipdb.set_trace()
train_dataset=rec_dataset(filename,u_table=u_table,i_table=i_table)
# test_dataset=rec_dataset(filename,train=False,test=True,u_table=u_table,i_table=i_table)
train_dataloader=t.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
# test_dataloader=t.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=0)
model=LR(30)
if model_path!=None:
model.load_state_dict(t.load(model_path))
model=model.to(device)
model.train()
criterion=nn.CrossEntropyLoss()
optimizer=t.optim.Adam(model.parameters())
e_loss=[]
for epoch in range(1,epoches+1):
a_loss=0
count=0
for i,(data,label) in tqdm(enumerate(train_dataloader)):
count+=1
data=data.to(device)
label=label.to(device)
optimizer.zero_grad()
pred=model(data)
loss=criterion(pred.squeeze(),label.squeeze())
loss.backward()
optimizer.step()
a_loss+=loss.item()
e_loss.append(a_loss/count)
draw(e_loss)
t.save(model.state_dict(),'./logistic.pth')
print('{}文件训练完成'.format(filename))
@t.no_grad()
def Recommend(model_path,filename,N=50,device='cpu'):
'''
利用训练好的模型,对每个用户进行推荐
@params
model_path:训练好的模型路径
filename:用户点击过的物品,相当于验证集
N:每次推荐的数目大小
device:测试的硬件设备
'''
# ipdb.set_trace()
model=LR(30)
model.load_state_dict(t.load(model_path))
model.to(device)
train_data,test_data=Get_train_data('./ml-100k/u{}.base'.format(filename),'./ml-100k/u{}.test'.format(filename))
test_data=pd.crosstab(index=test_data['user'],columns=test_data['movie'])
rec_dict=dict()
for user in tqdm(list(u_table.index)):
watched=list(train_data.loc[(train_data['user']==user).tolist(),'movie'])
rec_dict[user]=[]
for movie in list(i_table.index):
if movie in watched:
continue
score=model(t.tensor(Combine(user,movie),dtype=t.float)).view(-1,2)
prob=F.softmax(score,dim=1)[:,0].detach()
rec_dict[user].append((movie,prob))
rec_dict[user]=sorted(rec_dict[user],key=lambda x:x[1])[-N:]
pre,rec=Precision_and_Recall(rec_dict,test_data)
print('准确率:{} 召回率:{}'.format(pre,rec))
def Precision_and_Recall(pred_dict,test):
'''
计算精确率和召回率
@params
pred_dict:为每个用户推荐的物品列表
test:crosstab形式,用户真实看过的物品
@return
精确率和召回率
'''
all_pre=0
all_rec=sum(test==1)
shot=0
for user in pred_dict.keys():
if user not in list(test.index):
continue
for info in pred_dict[user]:
all_pre+=1
if info not in list(test.columns):
continue
if test.loc[user,info]==1: # 只有看过才是命中
shot+=1
return 1.0*shot/all_pre,1.0*shot/all_rec
def Combine(user,movie):
'''
user->user_id,movie->movie_id,利用id组合出用于训练的信息
@params
user:user_id
movie:movie_id
@return
info:用于训练的信息
'''
user_info=u_table.loc[user,:].values
movie_info=i_table.loc[movie,:].values
info=np.concatenate([user_info,movie_info],axis=0).squeeze()
return info
因子分解机FM
基础认识氺博客
上述的逻辑回归模型输入的特征无法进行“高级”的操作,比如特征交叉,特征筛选等,造成表达能力不强,不可避免造成信息的损失,故大牛们开始了新的征程--特征工程。
|\|名称|特点|不足|
|--|--|--|--|
|👉|PLOY2|所有特征之间两两进行交叉|参数太多,参数数量\(n^2\)|
|👇|FM|每个特征有一个隐向量,两两交叉的特征的系数为隐向量内积|二阶交叉,过高会出现组合爆炸问题|
|👇|FFM|引入特征域,每个特征有一组隐向量|二阶交叉,过高会出现组合爆炸问题|
|👇|GBDT+LR|拟合GBDT让特征进行高接交叉,最终叶子节点的排列为特征向量|容易过拟合,丢失了大量特征的数值信息|
|👇|DL|利用EMbedding,模型融合等方式提高模型的记忆和泛化能力|复杂|
本次主要介绍FM,使用pytorch或其他框架的话就不需要计算梯度,但是我脑抽了,忘记这回事儿所以自己计算的梯度,也不知道正不正确(哭叽叽🐒
Math Warning
| 公式和参数 | 介绍( |
|---|---|
| \(x_i^k\) | 第k个样本的第i个特征 |
| \(v_i\) | 第i个特征对应的隐向量 |
| \(w\) | 权重,参数 |
| \(\hat{y}=\sigma(w_0+\sum^n_ \limits{i=1}w_ix_i+\sum^n_ \limits{i=1}\sum^n_ \limits{j=1}(v_i\cdot v_j)x_ix_j)=\sigma(f(x^k))\) | 前向传播公式 |
| \(loss=\sum^n_ \limits{k=1}[-y_klog\hat{y}_k)-(1-y_k)log(1-\hat{y}_k)]\) | 损失函数 |
| \(\frac{\partial loss}{\partial w_0}=\sum^n_ \limits{k=1}[\sigma(f(x^k))-y^k]\) | loss对\(w_0\)的偏导 |
| \(\frac{\partial loss}{\partial w_i}=\sum^n_ \limits{k=1}[\sigma(f(x^k))-y^k]x_i^k\) | loss对\(w_i\)的偏导 |
| \(\frac{\partial loss}{\partial v_i}=\sum^n_ \limits{k=1}[[\sigma(f(x^k))-y^k]\sum^n_ \limits{j=1,j\neq i}v_j(x_j^kx_i^k)]\) | loss对\(v_i\)的偏导 |
Code Ending
根据上面公式和介绍,便可以编写代码了++
PS:本博客最开始的第一张图,可以看到接下来发展的深度学习推荐算法中很多都来自于FM的灵感,但是博主在看完书后,书中也提到了后面的深度学习用到的FM中的特征和原始的FM是不同的。不同的点,我举个栗子:原始的FM中,“性别”特征可以取值为0(男生)或者1(女生);而深度学习中的FM“性别”特征是取值为[1,0](男生)或者[0,1](女生),类似于“是否是男生”和“是否是女生”是一个特征。这是引入了特征域方便embedding。
def sigmoid(x):
'''
sigmoid函数,鉴于文中输入的是array而且为了防止溢出而采取的计算方式。
'''
y=[(1.0/(1+np.exp(-i))) if i>=0 else (np.exp(i)/(np.exp(i)+1)) for i in x ]
return np.array(y)
# 防止导入和处理训练和测试集,引入全局变量
g_train=None
g_test=None
gd=False
def Generator(filename,batch_size):
'''
没有采用pytorch框架,只能手动构造生成器
@params
filename:训练集和测试集的文件名
batch_size:每次训练的时候使用的样本大小
'''
# ipdb.set_trace()
# 在函数体内改变全局变量需要在函数体内global声明该全局变量
global g_train
global g_test
global gd
train,test=Get_train_data('./ml-100k/u{}.test'.format(filename),'./ml-100k/u{}.test'.format(filename))
train=train[['user','movie','ratings']]
train=Insert_neg_samples(train)
ii=list(train.index)
random.shuffle(ii)
train=train.loc[ii,:]
data=pd.merge(left=train,right=u_table,left_on='user',right_index=True)
data=pd.merge(left=data,right=i_table,left_on='movie',right_index=True)
label=data['ratings'].apply(lambda x:(1 if x>0 else 0))
data.drop(['ratings'],axis=1,inplace=True)
batches=data.shape[0]//batch_size
if gd==False:
g_test=pd.crosstab(index=test['user'],columns=test['movie'])
g_train=data
gd=True
for i in range(batches+1):
yield data.iloc[i*batch_size:(i+1)*batch_size,2:].T,label[i*batch_size:(i+1)*batch_size] # 训练的时候不传入未标准化的user和movie
def Cross(data,dim=0):
'''
特征交叉
@params
data:用于交叉的数据,输入n,放回n(n-1)/2
dim:指明交叉的维度,因为在整个程序中交叉的方式有可能是两个数相乘,也有可能是两个向量内积
@return
res:交叉好的array
'''
l=data.shape[dim]
res=[]
for i in range(l):
for j in range(i+1,l):
if dim==0:
res.append(data[i,:]*data[j,:])
elif dim==1:
res.append(np.dot(data[:,i],data[:,j]))
return np.array(res).reshape((len(res),-1))
def Initial_args(k):
'''
初始化模型参数
@params
k:隐向量的维度,这是需要人工决定的
@return
args_dict:模型参数字典,包括了w0,wi,vi
'''
args=list(u_table.columns)
args.extend(list(i_table.columns))
nums=len(args)
args_dict=dict()
args_dict['W0']=0
args_dict['Wi']=np.zeros((nums,1))
args_dict['v']=pd.DataFrame(np.random.randn(k,nums),columns=args)
return args_dict
def Forward(x,y,args_dict,epsilon=1e-5):
'''
模型前向传播,计算损失和预估值
@params
x:DataFrame格式的训练数据
y:DataFrame格式的训练标签数据
args_dict:模型参数字典
epsilon:为了防止出现log0,加上的极小的数
@return
loss:该模型参数下的损失值
y_hat:利用该模型参数下的预估值
'''
W0=args_dict['W0']
Wi=args_dict['Wi']
v=args_dict['v']
x=x.values
y=y.values
cross_args=Cross(v.values,dim=1)
cross=Cross(x)
y_hat=sigmoid(W0+np.sum(Wi*x,axis=0).squeeze()+np.sum(cross_args*cross,axis=0).squeeze())
loss=np.sum(-y*np.log(y_hat+epsilon)-(1-y)*np.log(1-y_hat+epsilon))
return loss,y_hat
def Backward(loss,x,y,y_hat,args_dict):
'''
模型反向传播计算梯度
@params
loss:该模型参数下的损失值
x:DataFrame格式的训练数据
y:DataFrame格式的训练标签数据
y_hat:利用该模型参数下的预估值
args_dict:模型参数字典
@return
dera_dict:模型参数梯度字典,包括了dW0,dWi,dv
'''
W0=args_dict['W0']
Wi=args_dict['Wi']
v=args_dict['v']
y=y.values
dera_dict=dict()
error=y_hat-y
dera_dict['dW0']=np.sum(error)
dera_dict['dWi']=(x.values@error).reshape(x.shape[0],1)
dera_dict['dv']=dict()
# 计算的梯度的方式没有按照公式那样一步步的算,那样复杂度太高,而是利用的矩阵计算快的方法,尽量采用矩阵来算
for key in v.columns:
cum=None
temp_x=copy.copy(x)
xi=temp_x.loc[key,:]
temp_x=pd.DataFrame(xi*x,index=x.index)
temp_x.loc[key,:]=0
temp_x=error*temp_x.values
dera_dict['dv'][key]=np.sum(v.values@temp_x,axis=1)
dera_dict['dv']=pd.DataFrame(dera_dict['dv'])
return dera_dict
def Update_parameters(args_dict,dera_dict,lr=0.01):
'''
更新模型参数
@params
args_dict:待更新的模型参数字典
dera_dict:模型参数梯度字典
@return
args_dict:更新完的模型参数字典
'''
args_dict['W0']-=(lr*dera_dict['dW0'])
args_dict['Wi']-=(lr*dera_dict['dWi'])
args_dict['v']-=(lr*dera_dict['dv'])
return args_dict
def Predict(x,args_dict):
'''
预测点击率
@params
x:DataFrame格式的预测数据
args_dict:模型参数字典
@return
y_hat:对于每个样本预测的点击率
'''
W0=args_dict['W0']
Wi=args_dict['Wi']
v=args_dict['v']
cross_args=Cross(v.values,dim=1) # (nums_c,1)
cross=Cross(x)
y_hat=sigmoid(W0+np.sum(Wi*x,axis=0).squeeze()+np.sum(cross_args*cross,axis=0).squeeze())
return y_hat
def FM_train(filename,args_dict,k,batch_size,epoches):
'''
训练模型
@params
filename:训练文件
args_dict:模型参数字典
k:隐向量维度
batch_size:每次梯度下降时样本的数目
epoches:迭代次数
@return
args_dict:训练完的模型参数字典
'''
# ipdb.set_trace()
al_loss=[]
for epoch in range(1,epoches+1):
gen=Generator(filename,batch_size=batch_size)
em_loss=0
for data,label in tqdm(gen):
loss,y_hat=Forward(data,label,args_dict)
dera_dict=Backward(loss,data,label,y_hat,args_dict)
args_dict=Update_parameters(args_dict,dera_dict)
em_loss+=loss
al_loss.append(em_loss)
print('第{}EPOCH LOSS:{}'.format(epoch,em_loss))
draw(al_loss)
return args_dict
def FM(filename='a',k=5,batch_size=64,epoches=10,N=50):
'''
整体的操作main函数
'''
args_dict=Initial_args(k)
args_dict=FM_train(filename,args_dict,k,batch_size,epoches)
# 给每个用户的推荐过程
watched_data=copy.copy(g_train)
pred_dict=dict()
for user in tqdm(list(u_table.index)):
watched=list(watched_data.loc[(watched_data['user']==user).tolist(),'movie'])
not_watched=[i for i in i_table.index if i not in watched]
test_data=np.array([Combine(user,i) for i in not_watched]).T
test_label=Predict(test_data,args_dict)
pred_dict[user]=(pd.Series(test_label,index=not_watched).sort_values(ascending=False).index)[:N]
pre,rec=Precision_and_Recall(pred_dict,g_test)
print('准确率:{} 召回率:{}'.format(pre,rec))
总结一下:有时间用pytorch写下这个FM。推荐系统的基础认识,我几乎都过了一遍了,接下来就是不断地巩固和尝试新的知识了。对于推荐系统的架构,发现自己有很多不懂的地方,不过架构方面的知识可能要缓一缓(感觉深似海)。
数据集
这里将我的数据打包放在百度网盘了,需要自取。密码: gwoa
人生此处,绝对乐观
