分布式学习笔记2
分布式互斥
互斥的场景在实际业务开发中很常见。对于单体应用来说,是线程之间的互斥;对分布式系统来说,是进程之间的互斥。目前,业界主流有三种实现分布式互斥的算法:
- 集中式算法
- 分布式算法
- 令牌环算法
集中式算法
加入一个协调者的角色,来协调所有进程对共享资源的访问,应用最广泛。
- 缺点
- 协调者必须实现高可用
- 当系统规模较大时,对协调者性能要求较高
分布式算法
不引入协调者,进程如果想要访问共享资源,需要询问系统内部其他所有的进程,发送资源访问请求,收到系统中所有其他进程的同意后,方可访问共享资源。
- 缺点:
- 信令风暴:一个进程想要访问共享资源,需要交互2(n-1)条消息,当系统中同时有n个进程需要访问共享资源,系统中会存在2n(n-1)条消息。消息数量会随着需要同时访问临界资源的程序数量呈指数型增加。 同时,因为程序忙于处理同步消息,导致无法处理业务逻辑。
- 增加复杂度:程序需要做故障检测并且维护一个系统内部可用的进程列表,否则整个系统的可用性非常低。
分布式算法目前应用在了分布式文件系统的某些业务场景,比如:
Hadoop中的HDFS,每一个文件都有3份相同的文件块存储与不同的服务器中,当需要修改A服务器上的文件块时
- A服务器向B和C发送修改请求
- B和C同意请求
- A服务器修改完毕后,同步新文件到B和C服务器
令牌环算法
所有进程组成一个环,并且系统中存在一个令牌,令牌在环中依次传递,代表了对资源的访问权力。
-
如果当前进程需要共享资源并且持有令牌,可以直接访问,访问完毕后传递令牌到下一个进程。
-
如果当前进程不需要访问,那么直接传递令牌到下一个进程。
缺点:
- 增加复杂度:程序需要维护一个全部可用的环,用于传递由于下一个节点不可用导致的传递失败问题。
- 延迟较高:当系统内部只有少数节点需要访问共享资源,因为必须要轮换一圈,所以需要等待轮转的时间才能继续访问。
- 通信成本:当系统内部只有少数节点需要访问共享资源,令牌之间传递带来的通信成本较高。
所以,令牌环算法适合于 每个进程对共享资源的访问频率高,并且单次访问时间较小的场景。
实际应用中,多个无人机通信会采取这种方式。
分布式选举
分布式选举的目的是选出集群中的主节点,主节点负责协调集群和管理集群,以保证集群的有序运行。
常见的分布式选举算法有:
- 基于ID的选举算法(Bully算法)
- 多数派算法(Raft算法、ZAB算法)
Bully算法
算法核心:当前存活结点中ID最大的节点为主节点。
Bully算法存在三种类型的消息:
- Election:用于发起选举
- Alive:对Election消息的应答
- Victory:竞选成功的主节点向其他节点宣示主权的消息。
要实现Bully算法需要满足一个假设条件:
- 集群中的每个节点都知道其他节点的id
在这个前提下,Bully算法的选举流程如下:
- 当前节点判断自己是否是所有节点中最大的id
- 如果是,直接发送victory消息给其他节点,宣示主权
- 如果不是,发送election消息给id比自己大的节点,等待回复
- 在给定时间范围内,没有收到其他节点回复的alive消息,则认为自己成为主节点,向下游发送victory消息
- 如果收到了其他节点回复的alive消息,就等待其他节点发送的victory消息
- 如果本节点收到了比自己小的节点的election消息,则发送alive消息给对应节点,告知存活。
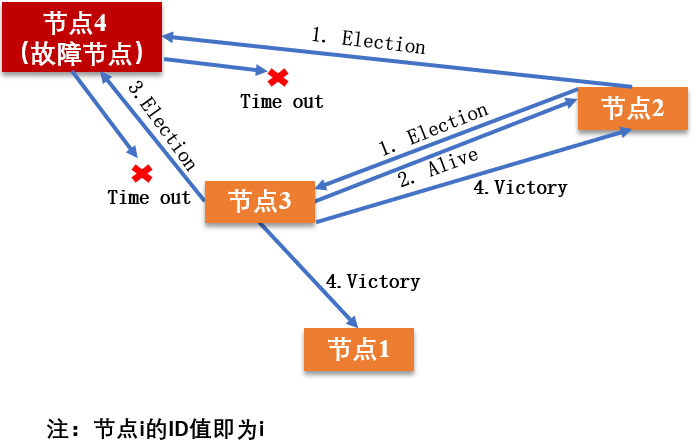
简单来说,如果触发选举,当前节点是否为新主的条件是:
- 如果id最大,直接成为新主
- 否则,发送election探测上游节点是否存活,并告知上游节点重新选举
- 如果上游都down了,直接成为新主;如果上游有一个回复,就不是新主
Raft算法
算法核心:少数服从多数。
raft算法中,节点有三种状态:
- follower跟随者
- candidate候选人
- leader领导者
初始化时,所有节点都是跟随者,一段时间后,第一个到达竞选超时时间的跟随者,那么自己会变成candidate。随后,候选人向其他跟随者发送选举投票请求,节点会响应这次投票(本轮次没投过票的节点就会投票),如果收到大多数赞成票,那么当前候选者就是新的领导人。
关于竞选超时
什么是竞选超时:跟随者成为候选人的时间,这个时间是一个150ms到300ms之间的随机数,所以所有follower节点的竞选超时时间大概率会不一样。
什么时候会重置竞选超时时间?
- follower投票给候选人后
- follower收到leader的心跳包后
这里笔者找到了一个好的图解学习网站,可以参考
ZAB算法
状态和角色
ZAB算法中,每个节点有三种角色:
- follower:跟随者
- leader:主节点
- observer:观察者
每个节点有四种状态:
- following:跟随者状态
- leading:领导者状态
- looking:选举状态(可以类比raft中的candidate)
- observing:观察者状态(没有投票权和选举权)
选主时机
下面几种情况会触发选主:
- 节点启动时:节点启动时默认为looking状态
- leader异常:和raft类似,在选举成功后,leader会定期发送心跳包来维持leader状态,一旦follower超时没有收到leader的消息,就认为leader已经异常,会从following状态进入looking状态
- 多数follower节点异常:这种情况发生在leader和大部分follower之间产生了网络分区(网络分区:简单的理解就是所有节点被划分到了互相不通的多个网络),这时leader节点就不再是合理的leader了,需要触发选主。
核心算法
每一次 选举的 所有投票请求 都包含三个维度的数据:
- 选举轮次
- 节点的消息id(消息id越大代表数据越新)
- 节点的server_id
所有节点会判断 待投票节点三个维度的数据和自己三个维度的数据 大小,以此作为投票的依据。并且,比较的优先级是 轮此 > 消息id > server_id,也就是说,轮次相同时,比较消息id,若消息id相同,比较server_id。大者当选。
最终会根据获得投票是否过半来决定leader(少数服从多数算法)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号