面试题-Java多线程基础、实现工具和可见性保证(新更新版)
前言
Java多线程部分的题目,是我根据Java Guide的面试突击版本V3.0再整理出来的,其中,我选择了一些比较重要的问题,并重新做出相应回答,并添加了一些比较重要的问题,希望对大家起到一定的帮助。
系列文章:
Java多线程
多线程基础
-
何为线程,何为进程?
- 进程是程序的一次执行过程
- 线程是比进程更小的执行单位,一个进程中可以创建多个线程
-
说说并发与并⾏的区别?
- 并发:同一时间段内,多个程序都在执行
- 并行:单位时间段内,多个程序同时执行
-
为什么要使⽤多线程呢?
- 单核时代,多线程主要是为了提高cpu和IO设备的综合利用率;
- 多核时代,主要是为了提高CPU的利用率。
-
编写多线程程序可能会存在的一些问题(重要)
- 安全性问题:由于编译器、硬件和运行时的机制是不可预测的,假如没有正确的同步机制,可能会产生安全性问题。
- 原子性:一组操作未必如我们所想的是原子的,中间可能被其他线程干扰。
- 可见性:线程对共享变量的修改,未必对其他线程是可见的。
- 活跃性问题:某个操作无法继续执行下去时,就会出现活跃性问题。比如:死锁饥饿活锁等等
- 性能问题:上下文切换开销;同步机制带来的其他开销等等
- 安全性问题:由于编译器、硬件和运行时的机制是不可预测的,假如没有正确的同步机制,可能会产生安全性问题。
-
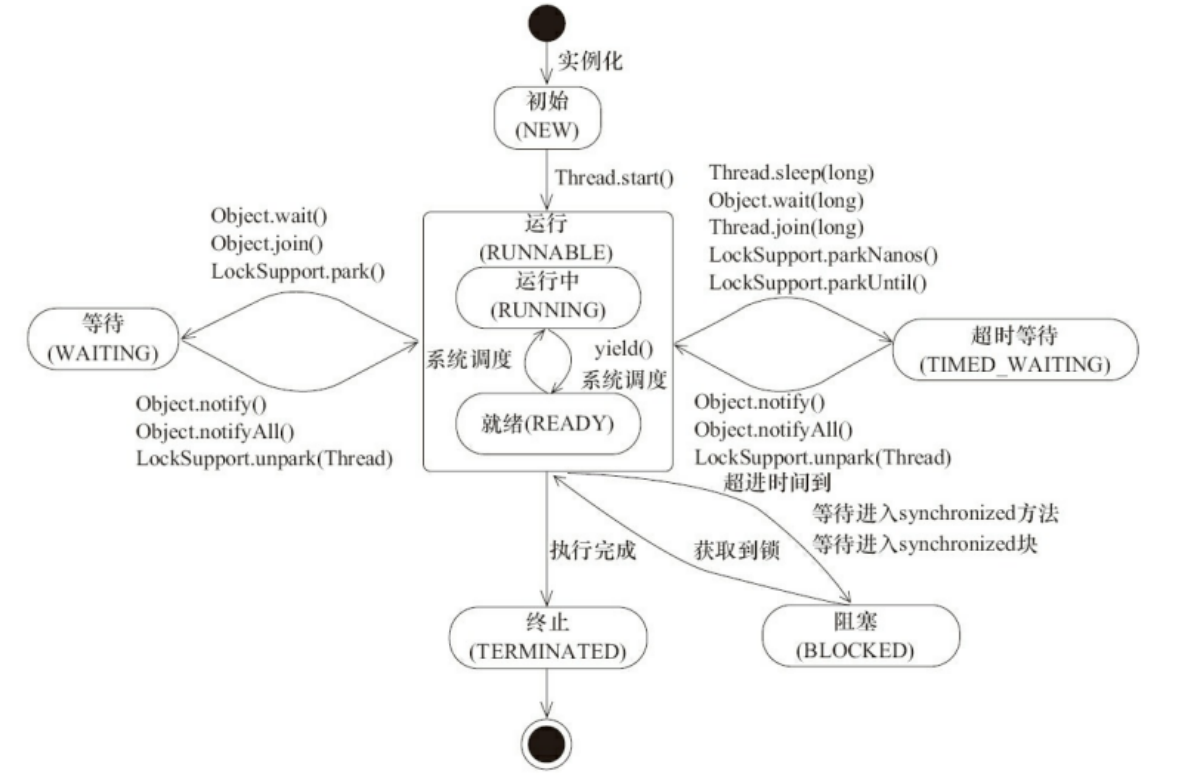
线程生命周期中有哪些状态?(核查线程问题时,了解每种状态代表的含义是基础)
- NEW:一个线程被创建出来时,start()被调用之前,状态为NEW
- Runnable:调用start后,线程状态变为Runnable
- Running:上CPU执行中,外部不可见
- Ready状态:排队等待执行,外部不可见
- IO wait:等待IO操作,外部不可见
- Blocked:线程等待获取锁
- Waiting:
- TIMED_WAITING:有超时时间的等待
- WAITING:没有超时时间的等地啊
- Terminated:执行完毕,进入Terminated状态
-
线程的中断机制:如何正确的干涉线程的执行过程
首先要明确,中断并不是停止,中断可以理解为一种通知机制。
线程在不同的状态时,对中断的响应也不同。
- Runnable状态:线程处于Runnable状态时,调用interrupt方法只会设置线程的中断标记位为true,需要线程在执行代码中自己判断中断标记位来得到通知。
注:判断中断标记位的方法有两种:
- isInterrupted:实例方法
- interrupted:静态方法,会清空标记位
-
Blocked状态:线程处于Blocked状态时,调用interrupt方法只会设置线程的中断标记位,线程什么都不会做,会继续Blocked。
-
Timed_wating或Waiting:线程处于Waiting相关状态时,调用interrupt方法会设置线程的中断标记位,并且线程内部会自动监测这个中断状态,当监测到为true,会抛出InterruptedException,清空标记位,线程会重新变为Runnable状态
总结:中断线程对Blocked方法无效,不会立即响应,线程会一直阻塞。已经在运行中的线程需要自己监测中断标记位;在Waiting状态中的线程可以自动监测标记位,通过抛出异常中断。
特殊情况:
-
当线程处于等待IO(IO wait状态)时,调用interrupt方法会设置标记位
- 如果Channel是可中断的,会抛出ClosedByInterruptException异常
- 如果是不可中断的,比如selector选择器,会从阻塞中立即返回
附,讨论具体方法代码的文章:[java 中断线程的几种方式 interrupt()]
-
什么是上下⽂切换?
当前任务执行完CPU的时间片切换到下一个任务时,会提前保存自己的运行状态,以便下次切换回这个任务时,可以再加载这个状态及时恢复现场。
上下文切换通常是计算密集型的,如果线程数远大于cpu数量,cpu会耗费大量的时间在上下文切换这个操作上,影响实际执行用户代码的时间比例。
-
什么是线程死锁?如何避免死锁?
- 问题一:线程A持有资源2,线程B持有资源1,他们同时都在等待对方的资源,而一直阻塞下去。
- 问题二:产生死锁需要同时具备下面四个条件,我们只需要破坏任意的其中一个,就可以防止死锁。
- 互斥:资源任一时刻只能由一个线程占有;破坏方案:无法破坏
- 请求和保持:一个线程获取不到资源阻塞时,对已经获取的资源保持不放;破坏方案:线程一次性申请全部需要的资源
- 不剥夺:其他线程不能剥夺已经被占有的资源;破坏方案:当线程申请另外的资源阻塞时,对已经申请到的资源及时释放。
- 循环等待:线程形成了首尾相接的循环等待条件;破坏方案:按顺序申请资源
-
说说 sleep() ⽅法和 wait() ⽅法区别和共同点?
-
共同点:两个方法都可以暂停线程的执行
-
不同点:
- sleep不释放锁,等到超时时间自动苏醒
- wait会释放锁,如果不带超时时间,需要其他线程调用notify相关方法唤醒;如果带超时时间自动苏醒
-
-
为什么我们调⽤ start() ⽅法时会执⾏ run() ⽅法,为什么我们不能直接调⽤run() ⽅法?
new一个线程之后,线程进入了NEW状态,调用start方法后会做一些准备工作然后准备上CPU执行时间片,如果直接调用run方法,和普通方法的执行就一样了,是调用者线程去执行run方法中的逻辑。
Java中的保证线程安全性的相关工具
为了解决多线程编程中的线程安全性问题,Java提供了多种工具供我们选择。
synchronized
可以解决什么问题?
synchronized可以保证原子性和可见性。
如何使用
synchronized可以使用在实例方法,静态方法和代码块中。
- 实例方法锁定的是this
- 静态方法锁定的是当前的Class对象。
- 代码块中可以自定义一个对象。
JVM对synchronized的性能优化
-
偏向锁
-
机制:如果一直是同一个线程反复申请锁,那么可以直接进入代码块,不需要做其他同步操作。
-
适用场景:某一个线程会反复进入同步代码块,就省略了加锁操作。
-
-
轻量级锁
- 机制:当申请偏向锁失败时(有其他线程在占用),会升级,申请轻量级锁
- 适用场景:多个线程交替执行同步代码块内容,并且有较短时间的重叠(如果没有重叠,就会一直保持偏向锁,如果重叠较长,就会导致锁升级)
-
重量级锁
- 机制:申请轻量级锁失败,会升级为重量级锁,首先会先自旋若干个空循环,如果循环之后还是无法获取锁,只能等待操作系统挂起
- 适用场景:多个线程同时执行同步代码块,并且每个线程占用锁时间短(自旋一阵大部分可以成功申请到锁)。
-
锁消除
- 机制:JIT会通过逃逸分析自动去除不可能出现竞争的锁
一些问题整理
- 讲⼀下 synchronized 关键字的底层原理?
- 如果是同步代码块,会使用两个JVM指令,monitorenter和monitorexit
- 如果是修饰方法,没有使用上面这两个指令,而是使用了ACC_Synchronized标识,JVM通过这个标识可以在执行方法前进行相关的同步操作。
Reentrant Lock
可以解决什么问题?
和synchronized一样,Reentrant Lock也可以保证原子性和可见性。
Reentrant Lock 和synchronized的区别
首先要明确,synchronized是在JVM层面实现的,而Reentrant Lock是在Java代码层面实现的。
Reentrant Lock的性能在jdk1.5之前是要远远优于synchronized,但是Jdk1.6版本虚拟机对synchronized做了优化(就是上面讲过的偏向锁等等),使得他们的性能几乎差不多了。
既然如此,为什么还需要使用Reentrant Lock呢?因为Reentrant Lock和synchronized相比,提供了更丰富的功能。
可中断锁等待
在前面多线程基础部分,提到过中断。当线程处于BLOCKED状态时(仅指使用synchronized关键字),interrupt函数只能设置中断标记位为true,但是线程依旧保持在阻塞状态。如果使用Reentrant Lock,在interrupt调用后,可以抛出InterruptedException响应通知,并且线程从阻塞状态中返回。
锁申请支持设置超时时间
可以使用tryLock或者待超时参数的tryLock,成功会返回true,失败返回false。不会像synchronized,如果一直申请不到锁,就会持续阻塞。
公平锁
synchronized的实现是非公平的,当锁可用时,会从等待队列中随机选择一个线程。而Reentrant Lock可以设置公平模式,保证不会出现饥饿现象。
可等待不同条件
synchronized的wait方法的实现机制是,把该线程放入锁对象的等待队列中,这个队列只有一个。如果需要区分等待的条件,就无法实现了。Reentrant Lock可以配合Condition使用,区分不同的等待条件,在需要等待的条件上wait就可以。
Volatile
可以解决什么问题?
Volatile只能保证可见性。
可见性保证的实现原理-JMM内存模型
上面提到了锁和volatile工具都可以保证可见性,那么可见性究竟是如何实现的呢?
主内存和线程的本地内存以及通信过程
JMM定义,线程之间的共享变量存储在主内存中,每个线程在自己的本地内存中持有一个共享变量的副本。主内存不仅仅是普通意义上的内存,而是一个抽象的概念,主要包括了编译器缓存、寄存器等硬件相关的优化。当两个线程想要通信,线程A需要把自己本地内存中的共享变量刷新到主内存中,线程B从主内存中获取共享变量的值。示意图如下:
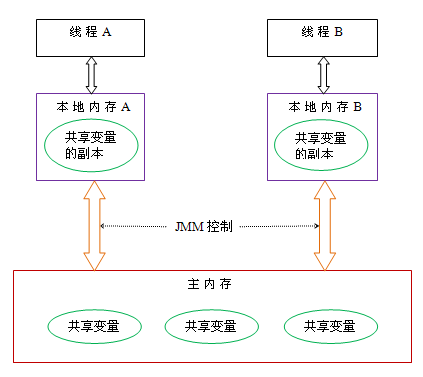
总结:JMM通过控制主内存与每个线程的本地内存之间的交互,来为java程序员提供内存可见性保证。
JMM具体是如何控制主内存和本地内存的交互呢?
我们知道,无法保证可见性的根源源于重排序,在现代PC中,存在着两种重排序。
- 编译器重排序
- 处理器重排序
那么要保证可靠性,禁止重排序就可以了。
对于编译器重排序,JMM的编译器重排序规则会直接禁止编译器重排序。对于处理器重排序,JMM会在某些指令处,插入内存屏障来禁止处理器重排序。
Happens-before-更友好的方式来描述操作之间的内存可见性
假如没有Happens-before原则,那么作为程序员的我们,需要去详细了解JMM的编译器重排序规则和内存屏障相关的细节,Happens-before原则,给程序员提供了一个更加友好易懂的视图,方便理解。
具体来说,如果A存在对于B的Happens-before关系,那么A操作一定对B操作可见。下面是几个比较重要的明细原则:
- 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
- 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
- volatile变量规则:对一个volatile域的写,happens- before 于任意后续对这个volatile域的读。
- 传递性:如果A happens- before B,且B happens- before C,那么A happens- before C。
ThreadLocal
-
ThreadLocal主要解决什么问题?
ThreadLocal可以实现每个线程都有自己的专属本地变量,实现线程的私有数据,从而保证了线程安全性。
-
ThreadLocal的原理?
每一个Thread中都有一个threadLocals引用,这个引用指向的是一个ThreadLocalMap类,这个map简单理解就是一个定制化的HashMap。创建一个threadLocal并调用set方法时,实际会获取当前线程的ThreadLocalMap,然后把这个threadLocal作为key存储到map中。
简单来说,每个线程都有一个Map,这个map里面存储的是以 ThreadLocal为key,当前ThreadLocal的泛型类型为数据类型的value值。真实使用的时候,我们会有很多的ThreadLocal分别存储不同类型的值。
这里会有一个内存泄漏的问题,因为作为key的threadLocal是弱引用,每次垃圾回收都会回收他们,所以会产生很多key为null的value,jdk实现中,在getset等方法中会强制扫描为null的key,并清除他们。
-
项目中如何使用的?
web项目中,会使用ThreadLocal保存当前线程登陆后用户的相关信息,方便后续获取用户的id等信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号