

kettle实现整库迁移_mysql 数据库
搬来的东西,太实用了
kettle实现整库迁移
1 背景
- 库与库之间做数据同步
- 结构不变
- 原始是数据库和目标数据库都是MySQL
2 思路
鉴于是整个库进行数据同步,表结构和表名都不需要变化。因此,在转换过程中并不需要做太多的清洗工作,主要是在目标数据库建表和导入操作。需要注意点:
- 1,对于原始库中新的数据表需要在目标库中新建
- 2,数据需要进行全量更新
整体的工作流如下: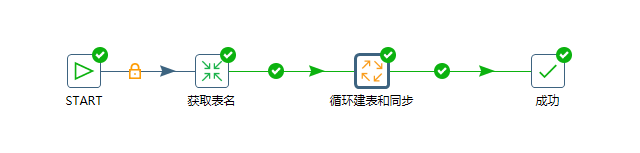
- 获取表名转换处同时获取原始数据库中的表名和建表语句,备用
- 循环建表和同步工作处是对所有表的循环处理
2.1 获取表名

- 必须使用复制记录到结果控件来保存记录
- 获取表名处注意勾选sql语句字段
- 该转换得到了数据库里面所有表的名字和所有建表语句,备用,后面赋值到相关变量中供其他控件使用
2.2 循环建表和同步
2.2.1 如何设置循环

- 双击循环建表和同步job,勾选执行没有一个输入。
2.2.2 建表和同步

- 这是一个完整的job,在整个job流中的循环建表和同步循环的就是这个job
- 这个job主要是获取变量-建表-同步数据
2.2.1 获取变量

- 从以前的结果获取记录,获取的就是2.1步记录中的结果
- 设置环境变量时,直接选择获取字段就行,不用手动输入,变量活动类型默任
2.2.2 建表

- 注意勾选变量替换
- 用${SQL_RESULT}来引用上一步设置的变量
2.2.3 单个表同步

- 表输入时sql语句中的表名用变量代替
- 表输出时注意勾选剪裁表和批量导入
3 数据库连接共享
因为在这整个的工作中,包含了4个ktr和两个job,数据库连接在多个地方出现,因此将数据库连接设置成共享的,避免重复设置数据库连接
这是已经共享完成的,在数据库连接上右键鼠标,在弹出框中就可以看见共享/停止共享的按钮


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具