MySQL原理
MySQL基础:
- sql语句的执行过程:
- 连接器:登录连接sql数据库
- 分析器:分析解读sql语句,并检查是否符合SQL语法规则
- 优化器:对实现方式进行优化,比如在查询时决定使用哪个索引。
- 执行器:执行。
- 事务:一系列聚合性操作,一组不可分割的sql语句。要么全部执行,要么全部不执行。
- 原子性:不可分割。undo log保证可以回滚
- 隔离性:事务不可被其他事务干扰。MVCC保证。
- 一致性:数据库处理结果应与其所代表的客观世界中真实状况保持一致。由其他三个特性保证
- 持久性:即便故障也不应该使数据的改变失效。redo log、bin log
- 隔离级别:
- 读未提交:事务未提交,修改就能被其他事务看到。
- 读提交:事务修改后,修改才能被其他事务看到。解决脏读
- 可重复读:事务在执行过程中,数据会保持与开始时一致。mysql默认,解决不可重读。
- 串行化:写锁,读锁。阻塞。解决幻读。
- 行锁:在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
- 一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
- 一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
- 意向XS锁:对整个表加意向锁,表明已有事务正在对此表/此表的某行进行读/写,阻塞其他想要获取表锁的事务,如果没有意向锁,想要获取表锁的事务逐条查看是否有行锁。
- 表锁:很重量级,因此很少使用,通常只在整表的复制、备份中使用
MVCC:mysql实现读提交和可重复读两个隔离级别的方式。
原理:每行数据的三个隐藏属性:回滚指针(指向undo log串成的版本链),自增ID,最近修改该数据的事务ID。
读视图:记录活跃事务列表,也就是还未提交的事务。通过这个列表来判断记录的某个版本是否对当前事务可见。从版本链上的最新记录开始寻找,若更改某条记录的事务id小于读视图中的最小活跃事务id,也就是说当前事务是已提交的,就返回这条记录。
- 如何实现读提交:每次select都创建一个读视图。
- 如何实现可重复读:一个事务只创建一次读视图。
当前读:读取最新记录、update insert delete时用,需要加锁。
快照读:读版本链、读视图,不需要加锁。
MVCC 可以解决什么问题?
- 读写之间阻塞的问题,通过 MVCC 可以让读写互相不阻塞,读不相互阻塞,这样可以提升数据并发处理能力。
- 降低了死锁的概率,读取数据时,不需要加锁,写操作,只需要锁定必要的行。
- 解决了一致性读的问题,当我们朝向某个数据库在时间点的快照是,只能看到这个时间点之前事务提交更新的结果,不能看到时间点之后事务提交的更新结果。
MVCC在可重复读级别下,部分地解决了幻读问题,但这种情况下仍然可能出现幻读:一个事务不光进行查询,还进行update。
a事务先select,b事务insert之后提交。然后a事务update,若a事务再次select就会出现b事务中的新行,并且这个新行已经被update修改了.
上面这样,事务2提交之后,事务1再次执行update,因为这个是当前读,他会读取最新的数据,包括别的事务已经提交的,所以就会导致此时前后读取的数据不一致,出现幻读。
并发事务带来哪些问题?
- 脏读:某事务在修改数据还未提交时,被另一事务读取了这个数据进行了错误的操作。
- 丢失修改:两个事务同时修改某数据而未被阻塞,那么先修改的就会丢失。
- 不可重读:事务在两次读取数据中间某个时刻被其他事务修改了该数据,造成两次不一样。
- 幻读:事务在两次查询中间某个时刻被其他事务添加或删除了数据。比如查询年龄大于20的人,但被其他事务增加了几条记录。
- 日志:
- bin log:属于sever层,写满后重新开一块,记录原始操作逻辑。可用于读写分离主从库
- redo log:属于InnoDB引擎,写满后擦除重写,是物理日志。
- 两段提交:让bin和redo保持一致。
- Undo log:修改记录的链表,版本链、
索引:
- 哈希表只适用于等值查询,使用b+树,具有与二叉排序树相似的特点与性能,但层数更低,更适合于在硬盘中存储。
- 为什么不使用红黑树?
- 红黑树层数高、结点多、访问磁盘IO次数多,B+树索引在设计时,一个结点就是磁盘中的一页,也就是一个结点只需要一次IO。
- B 树& B+树两者有何异同呢?
- B 树的所有节点都存放数据(data),而 B+树只有叶子节点data,其他内节点只存放 key。这样内结点每个页可以存放更多的索引。相同高度b+树能够存放更多记录,也就是能降低树的高度
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,需要进行大量的回溯。而 B+树,从根节点到叶子节点后,因为顺序访问指针,所以范围查找很方便。
- 主键索引:随表建立,建立在主键上,不允许索引值出现空。
- 唯一索引:建立在unique字段上的索引,允许有空。
- 聚集/非聚集索引:是否在索引中存放数据。
- 聚集:定位快,定位到索引就定位到数据。依赖有序索引(主键使用AUTO_INCREMENT的原因)。更新代价大。InnoDB
- 非聚集:叶子结点不存放数据,只存放指向数据的指针 或主键。更新代价小。一般会需要进行回查,也就是找两遍树。MyISAM
- 覆盖索引:覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, 而无需回表查询。可以在常用查询上建立覆盖索引,比如通过电话号码查询姓名。
- 前缀索引:字符串或者二进制作为索引时,只索引部分前缀,以减少计算和存储的开销。但无法order和group
- 全文索引:在需要进行全文检索的场景中
- 最左前缀:多字段建立联合索引是按照最左字段排的索引顺序。因此,在查询时,一定要带上联合索引中的最左字段,否则不会走索引。
- 索引下推:在非主键索引上,查询多个条件的时候,预先对后续条件进行判断,减少回查次数。
建立索引的原则:
- 有序、连续、重复值很少的字段适合建索引,比如自增ID。
- 分布过于离散且数值过大的字段不要建索引:身份证号、uuid
- 重复值太多的列不要建索引
- 区分度太低的列不要建
- 定义为text image bit 的字段不要建立索引
- 频繁更新的字段不要建立索引
- 定义为外键的列一定要创建索引
- 长字符串中,建立前缀索引
- 尽量扩展索引 而不是新建索引。
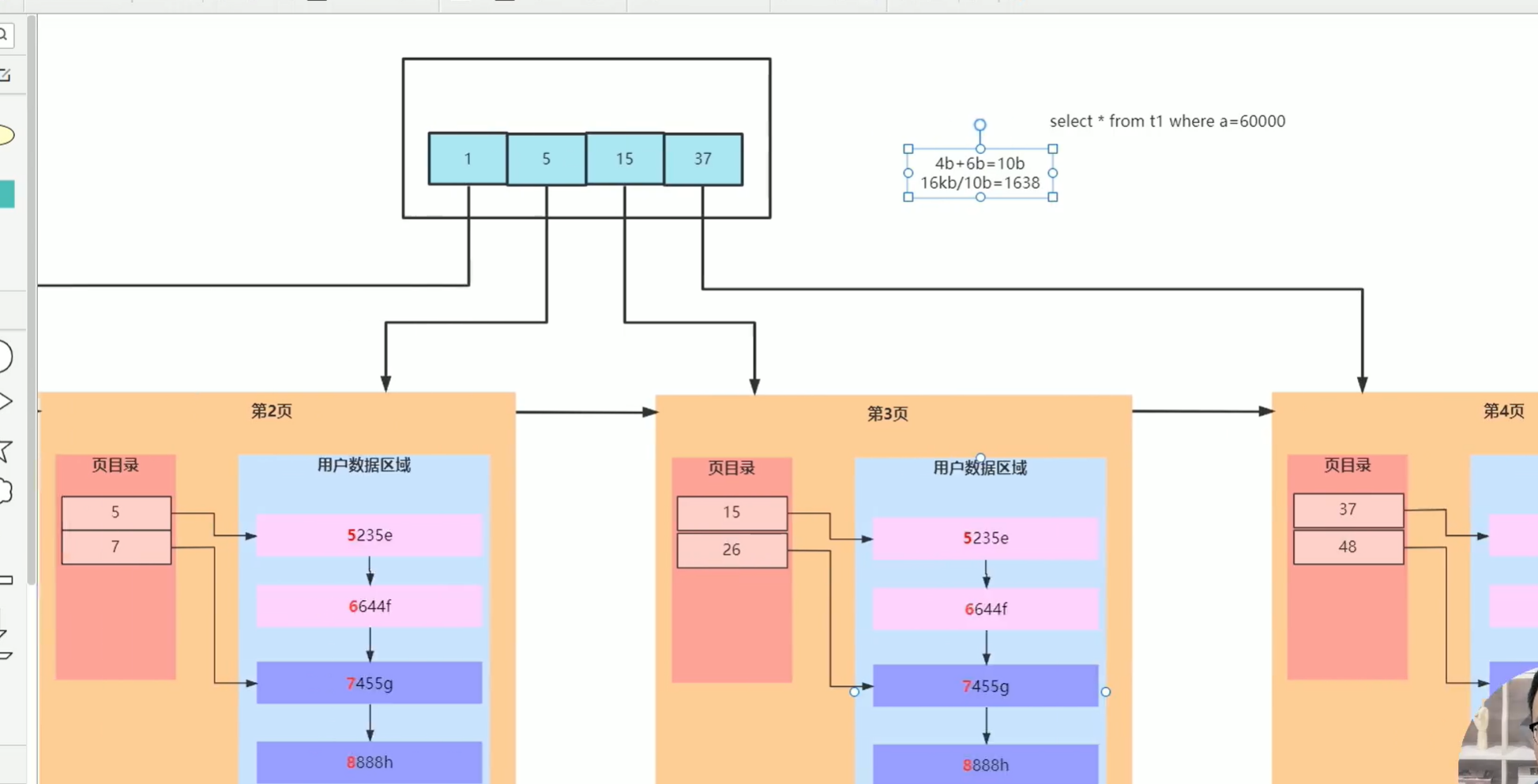
InnoDB页:在存储和查询时按页,从磁盘中存取(默认16kb)。B+树的实现
- 页头:前驱后继指针。
- UserRecord:以链表存储数据。在插入时默认保持主键有序(使用自增ID的原因)。
- 页目录:提高链表查询效率
- 页扩充:开新页增加记录时,用指针指向新页,仍然要保持有序,因此新记录有可能存放于旧页,而旧页中的某记录可能被挪至新页(使用自增ID的原因)
- 建立页目录的目录。(成为B+树了)
其他引擎:
- MyISAM: 不支持行级锁。不支持事务。不支持安全恢复。不支持外键。使用非聚集索引。
- Memory:使用哈希存储数据,存在内存中。
VARCHAR:一个字符占用3个字节,最多2^16=65536个字节。
一条记录中除text、blob外所有字段的字节数和不能超过65536.
如何提高insert性能?


-
-
- 索引失效:
-
- 建立了联合索引,但查询where 没有查最左字段
- 如建立了abc的索引,但只查询bc。因为索引是根据最左前缀原则建立的。
- 在范围查找时,如select的字段没有建立索引,且范围内数据比较多
- 如select * where b>2。可以在b索引中找到b>2的所有主键然后回表,也可以直接在主键索引中全表扫描。若范围内数据比较多,那么走索引因为回表次数很多,并不一定比全表扫描快。
- order by的某字段没有建立索引。
- 在where中对字段进行了类型转换/运算/函数。如索引是用varchar建立的,而where中用得是整型数条件,相当于进行了类型转换。char字母默认转为数字0。 char数字默认转为相应数字。
- where中使用了like '%‘开头。
- 在where中使用or时,两边其中有一个字段没有创建索引,另一个字段有索引也会失效。应当使用union。
Explain select *:执行计划

- id:查询语句的id(自增)
- type:MySQL Explain 之 type 详解 | MySQL 技术论坛 (learnku.com)
- const、唯一索引、范围查找、索引全扫描、全表扫描
- possible_keys:可能会使用的索引(但可能失效而不使用)
- key:使用的索引
- key_len:命中了几个索引
- rows:select会扫描的行数
- filtered:返回行数/rows的百分比
分库分表:
- 主从赋值读写分离:使用多个从库副本(Slaver)负责读,使用主库(Master)负责写。并通过bin log对从库进行同步更新。
- 垂直切分:字段很多,将不常用或字段长度较大的字段拆分出去到扩展表中,实际上是对业务进行解耦合,更便于开发与维护,也能避免跨页问题,一条记录占用空间过大会导致跨页,造成额外的性能开销。另外数据库以行为单位加载到内存中,表中字段长度较短的话,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
- 水平分库:垂直切分后,无法解决数据库或表行数过多,进行水平切分,并可以在不同机器存储。有效缓解单机单库带来的性能瓶颈和压力。范围切分、hash取模切分、时空切分。但需要解决分布式事务、无法跨库使用join



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异