视频编码基础_2
一、量化
首先区分采样、量化和编码:
- 采样是指在时间轴上对信号进行数字化。
- 量化是指在幅度轴上对信号数字化,每一个量化都是一个采样,将这么多采样进行存储就叫做编码。
- 所谓编码,就是按照一定的格式记录采样和量化后的数字数据,比如顺序存储或者压缩存储等。
在视频编码中,量化是编码过程中的重要步骤之一,用于将变换系数进行近似和精度降低。
变换系数是频域变换(如DCT或DST)应用后得到的表示图像的频域信息的系数。通过将变换系数量化为离散的整数值,可以减少数据的位数表示,从而减小数据量。

量化的过程涉及确定一个量化步长(Quantization Step Size),即确定将连续值映射到离散级别的间隔大小。较大的量化步长将导致更粗糙的量化结果,而较小的量化步长将提供更细致的量化结果。量化过程通常是不可逆的,因为无法恢复原始精确值。
在视频编码中,量化的目标是在保持图像质量的前提下,尽可能减小数据的表示量。通过选择适当的量化步长,可以实现编码的压缩效果。然而,较高的量化水平会导致图像质量损失,并引入可见的失真,因此需要在压缩率和图像质量之间进行权衡。
二、CABAC
在视频数据压缩中,按照压缩前后图像信息量是否有损失,可以将压缩方法分为两类:一类是无失真编码或熵编码;另一类是有限失真编码。
基于混合编码的视频压缩标准中,变换、预测后的量化处理属于有限失真编码,消除的是信源空间和时间的冗余度。
而对量化后的预测残差变换系数形成的语法元素,采用的熵编码消除的是码字之间的冗余度,属于无失真编码。
1.信息熵
信息熵是指信号源(信源)的信息量。设有一个离散信源

它产生消息的概率是已知的,记为

则信息量定义为:

单位是bit,信息量仅反映了一个符号的信息量的大小,而信源都是由若干个符号所组成,如二进制信源由0和1两个符号,因此,用平均信息量,称为“熵”(entropy)来表示由多个符号所组成信源所携带的信息量,定义为:

上式取以2为底的对数时,单位是比特/符号:

2.定长编码
定长编码也称为等长编码,即为每个编码符号分配一个等长比特的码字。常用的二进制码如表1:

在HEVC中,描述子f(n)表示有一个固定n比特的预定义值。具体到某一具体语法元素forbiden_zero_bit,它是一个f(1)码字,即1比特长度,其值为0。这种定长编码主要用于NAL单元头,slice分割头以及SPS/PPS中。
3.变长编码
变长编码为各个编码符号分配的比特数不一定相等,常见的变长编码有哈夫曼、香浓、指数哥伦布编码等。变长编码的优势是编码的平均长度比定长编码短。例如概率分布为2的负幂次方的序列符号,具体如下:

3.1哈夫曼编码
具体示例如下图,每次选取两个出现概率最小的进行组合,概率较小的一个为0,较大的另一方为1(或者反过来也可以,按你心意),

根据码长公式计算码流的平均码长

相比于定长编码,需要3位二进制等长码。
3.2算术编码
3.2.1传统编码方法
传统编码是通过符号映射实现的。映射包含符号(symbol)与码字(codeword)两个要素,如下面的例子
| symbol | h | e | l | o |
| codeword | 00 | 01 | 10 | 11 |
通过上述的映射表,我们可以把“hello”编码成码流 01 00 10 10 11。而诸如Haffuman,Shannon这些编码方法也没脱离这种编码模式,他们只是通过符号出现的概率对码字进行调优。
3.2.2算术编码
从理论上讲,对信源数据采用哈夫曼熵编码方法可以获得最佳编码效果,但是在实际中,由于在计算机中存储和处理的最小数据单位是1bit,无法表示小数比特。例如两符号信源{x, y},其对应的概率是{1/3, 2/3},根据信息熵计算,x的最佳码长是
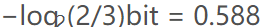
y的最佳码长是

平均码长是
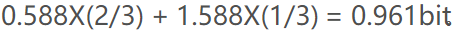
而计算机中不可能有非整数位出现,即采用哈夫曼对x,y编码,得到{x,y}的码字分别为0和1,可见对于出现概率大的符号x并未赋予较短的码字。而算术编码的产生正是为了解决计算机中必须以整数位进行编码的问题。
算术编码的思想是用0到1的区间上的一个数字来表示一个字符输入流,本质是为了整个输入流分配一个码字,而不是给输入流中的每个字符分别指定码字,算术编码是用区间递进的方法来为输入流寻找这个码字的,从第一个符号确定的初始区间0,1开始,逐个字符地读入输入流,在每一个新的字符出现后递归地划分当前区间,划分的根据就是各个字符的概率,将当前区间按照各个字符的概率划分为若干子区间,将当前字符对应的子区间取出,作为下一个字符时的当前区间,当处理完最后一个字符后,得到了最终区间,在最终区间中挑选一个数字作为输出。
算术编码分为浮点算术编码与定点算术编码,例如对浮点算术编码而言:用[0, 1]的概率区间,对一串字符编码后,得到了最终区间,在最终区间挑选一个数字作为编码输出,而这个数字是一个小数,受计算机精度的影响;为了避免这种影响,在实际使用中采用定点算术编码,且根据计算机的精度采用比例缩放的方法la来解决。
在H.264/H.265中,将[0, 1]区间放到至[0, 210],采用32位寄存器实现。
具体流程如下:
1.首先我们需要根据概率设定各符号在[0,1)上的初始区间,其中区间的起点为表中前面的符号的累计概率
| symbol | e | h | l | o |
| sum of probability | 0 | 0.1 | 0.1+0.2 | 0.1+0.2+0.3 |
| interval | [0, 0.1) | [0.1, 0.3) | [0.3, 0.6) | [0.6, 1) |
“hello”的第一个符号为“h”,那么映射的区间为[0.1,0.3)。
2.接下来我们需要根据符号的概率分割[0.1,0.3)上的区间,得到的结果如下
| symbol | e | h | l | o |
| sum of probability | 0 | 0.1 | 0.1+0.2 | 0.1+0.2+0.3 |
| interval | [0.1, 0.12) | [0.12, 0.16) | [0.16, 0.22) | [0.22, 13) |
“hello”的第二个符号为“e”,那么映射的区间为[0.1,0.12)。
3.按照这种方式继续进行区间映射,最终“hello”映射到的区间是[0.10888,0.1096)
| 映射区间 | 区间大小 | 区间长度 |
| 初始值 | [0, 1) | 1 |
| 编码完h后 | [0.1, 0.3) | 0.2 |
| 编码完e后 | [0.1, 0.12) | 0.02 |
| 编码完l后 | [0.106, 0.112) | 0.006 |
| 编码完l后 | [0.1078, 0.1096) | 0.0018 |
| 编码完o后 | [0.10888, 0.1096) | 0.00072 |
4.从区间[0.10888,0.1096)中任取一个代表性的小数,如“0.109”就是编码“hello”后的输出值
算术编码的总体的编码流程可以参考下图

3.2.3二进制算术编码
二进制算术编码的编码方法跟算术编码是一样的,但是输入只有两个符号:“0”,“1”,也就是说输入的是二进制串。
除了是对二进制串进行编码这个特征外,二进制算术编码跟普通的算术编码还有一些区别,总体上可以按照如下进行描述:
1.设输入符号串为S,S中的符号分为两种:MPS(Most Probability Symbol),LPS(Low Probality Symbol),分别代表出现概率大小的符号,需要根据实际情况进行调整。如果输入的二进制串中的“0”较多,“1”较少,那么MPS = “0”,LPS =“1”。
2.LPS出现的概率为pLPS,MPS出现的概率为pMPS=1-pLPS。
3.在编码中进行区间选择时,MPS在前,LPS在后,因此
- LPS的累计概率为PLPS=pMPS=1-pLPS<br>
- MPS的累计概率为PMPS<span class="math">=0

4.区间的大小更新为
- 如果当前编码的是LPS

- 如果当前编码的是MPS;

5.区间的起点更新为
- 如果当前编码的是LPS
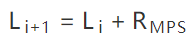
- 如果当前编码的是MPS;
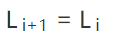
4.CABAC编码
CABAC采用的是二进制算术编码,在编码过程中需要传入二进制串,输出的也是二进制串。
在H.264标准中,CABAC在语法结构中用ae表示,它只用于编码slice_data中的语法元素(包括slice_data内部的子模块的语法元素)
CABAC实现如下图
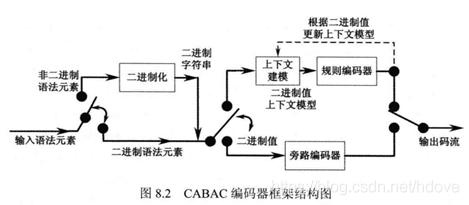
- 待编码语法元素二值化:CABAC使用二进制算数编码,这意味着仅仅有两个数字(1 或 0)被编码。一个非二进制的数值符号,比如一个转换系数或者运动适量,在算术编码之前会首先被二值化或者转化成二进制码字。这个过程类似于将一个数值转化成可变长码字,但是这个二进制码字在传输之前会通过算术编码器进一步的编码。
- 上下文建模(确定上下文索引):上下文模型就是一个概率模型,这个模型是根据最近的被编码的数据符号的统计数字而选择的一个模型。这个模型保存了每个‘bin’是1或者0的概率。
- 算术编码:算术编码器根据选择的概率模型对每一个‘bin’进行编码。
- 概率更新:被选中的上下文模型会根据实际的编码值而去更新。例如,如果bin的值是 1,那么 1 的频率计数会增加。对于被二值化的符号中的每个比特或‘bin’,会重复执行阶段2、3和4。
- 归一化生成最终结果
4.1 二值化
CABAC编码的是slice data中的语法元素,在进行算术编码前,需要把这些语法元素按照一定的方法转换成适合进行二进制算术编码的二进制串,这个转换的过程被称为二值化(binarization)。
二值化的方案共有7种:一元码、截断一元码(TU)、k阶指数哥伦布编码(GEk)、定长编码、4位FL与截断值为2的TU联合二值化方案、TU与EGk的联合二值化方案(UEGk,Unary/kth order Exp-Golomb)
4.2 上下文建模
条件熵理论下,作为条件的已编码符号信息称为上下文——应用要有针对性,
高概率发生的对编码性能影响起主导作用的事件,建立精致的上下文模型,增加上下文概率的阶数以达到精细的条件估计,
低概率发生的对编码性能影响不大的事件,建立简单的上下文模型。
上下文建模是根据上下文信息和概率分布来选择和更新编码过程中的概率,从而实现自适应的熵编码。通过动态调整概率分布,上下文建模可以更准确地估计二进制数据的概率,并生成更紧凑的码流表示。上下文建模的准确性和适应性对于熵编码的性能起着关键作用。具体的上下文建模方法和更新策略可以根据具体的视频编码标准或算法进行定义和优化。
- 在编码过程中,语法元素使用的上下文概率模型都被唯一的上下文索引号r标识,每一个r涉及两个概率模型变量:最大概率符号MPS和概率状态索引。MPS表示待编码的Bin很有可能出现的符号(0或1);与之对应的,待编码的Bin不可能出现的符号即为最小概率符号LPS。
- 在CABAC中,为LPS的概率设置了64个代表值,每一个都与LPS一一对应。
- 编码器会初始化上下文模型的符号变量MPS和δ。
- 在获取初始的概率模型变量后,即可对当前符号(或语法元素)进行二元算数编码和概率模型参数更新,实现上下文自适应的编码。
- 更新的方法:如果编码的符号等于MPS,那么通过查表更新。
4.3 算术编码
使用二进制算术编码,有两种模式:常规模式,旁路模式。
1、常规模式。假设当前编码器的区间长度是R,区间下限是L。
- 计算索引值=(R>>6)&3;
- 查表得到LPS对应的子区间=rangeTabLps[][],那么=R-;
- 如果当前的二进制符号Bin等于MPS,则作为下一个符号的编码区间R,下限L不变;如果Bin等于LPS,那么作为下一个符号的编码区间R,区间下限L要加上的长度。然后更加当前符号值更新上下文。
2、旁路模式。这种模式无需对概率进行自适应更新,而是采用0和1概率各占0.5的固定概率进行编码。为了是区间划分更加简单,才用了保存编码区间长度不变,使下限L值加倍的方法来实现区间划分。
4.4 归一化
在CABAC(Context-Based Adaptive Binary Arithmetic Coding)中,归一化是指将概率范围映射到整数范围内的过程。在二进制算术编码中,符号的概率分布通常表示为一个区间,归一化的目的是将该区间映射到一个整数范围,以便进行更高效的编码和解码操作。
具体来说,在CABAC中,归一化过程涉及到将符号的概率范围映射到0到2^B-1的整数范围,其中B是归一化的位数。这个过程可以分为两个步骤:上界归一化和下界归一化。
上界归一化:
- 在上界归一化阶段,计算上界(Upper Bound)和下界(Lower Bound)的整数表示,这些整数范围在0到2^B-1之间。
- 上界是指概率范围的上边界,下界是指概率范围的下边界。
- 上界归一化的目标是将上界值映射到整数范围内,通常通过乘以2^B的方式来实现。
下界归一化:
- 在下界归一化阶段,将下界值归一化为0,同时将上界值减去下界值,以获得一个新的概率范围。
- 下界归一化的目标是确保概率范围的最低位为0,以保证编码的正确性。
- 通过归一化过程,符号的概率范围被映射到整数范围内,并进行相应的编码和解码操作。归一化后的整数范围可以使用二进制算术编码器进行处理,从而实现高效的编码和解码过程。
三、DCT
在开始讲DCT变换之前,我们来看看DFT的变换公式
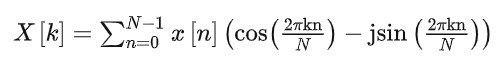
当然,我们可以将上式子拆开来

显而易见的DFT变换的结果,实数部分是

虚数部分是

设

那么,
实数部分:

虚数部分系数为:
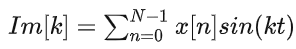
显然的,cos是一个偶函数,sin是一个奇函数,因此有

因此,当x[n]是一个实数函数时,其频域的实部是偶函数,虚部是一个奇函数。
那么,假如原信号x[n]是一个全是实数的偶函数信号会怎么样?
那么显然的,因为偶函数乘以偶函数还是偶函数,奇函数乘以偶函数还是奇函数,因此

就变成一个奇函数了,既然是奇函数那么自然

一变换后虚部不见了,因此,当原时域信号是一个实偶信号时,我们就可以把DFT写成

其实上式就是DCT变换的核心思想了,怎么样是不是超简单,DCT变换实际上就是限定了输入信号的DFT变换,并不是因为在变换的方式上有什么不同。
但光到这里还不够,你发现这和书本上写的DCT变换公式怎么还有点不同呢,我们先看看最常用的DCT变换公式:
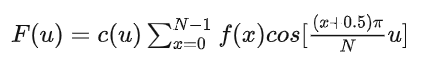
其中当u为0时,c(0)=sqrt(1/N),否则c(u)=sqrt(2/N).
DCT变换就是DFT变换的一种特殊形式,而其特殊点就在于其原始变换信号是一个实偶函数,但是实际应用中不存在大量的实偶函数信号,因此我们就用实信号构造。
设一长度为N的实数离散信号 {x[0],x[1].....x[N−1]} ,首先,我们先将这个信号长度扩大成原来的两倍,并变成2N,定义新信号 x′[m] 为
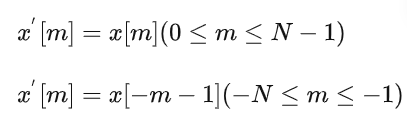
简单来说,这个信号变成了如下图所示的样子
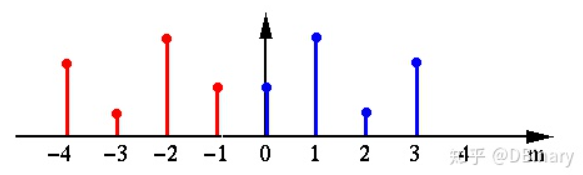
其中,蓝色为原始信号,红色为延拓后的信号这样,我们就将一个实信号变成了一个实偶信号,那么,对这个延拓的信号的DFT变换怎么写呢,显然,信号的区间已经从之前的 [0,N−1] 变成了 [−N,N−1] ,因此,DFT变换公式也变成了

但是,这样的插值之后也随之带来了一个问题,这个信号并不关于m=0偶对称,它关于 m=−1/2 对称,因此,为了让信号仍然关于原点对称,把整个延拓的信号向右平移 12 个单位

为此,式1.3也得做出对应的改变
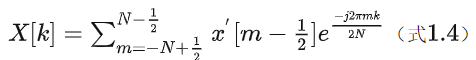
依据欧拉公式对式1.4进行展开,展开时我们只要实数部分就行了,因为之前讨论过了,虚数部分已经是0了

到这一步显然还不够科学,毕竟m算出来居然是一个小数还带负数,作为一个离散序列我去哪找这个值,因此,式1.5我们还需要进一步变形,首先我们知道,这个序列是一个偶对称序列,因此根据式1.5

然后,设n=m-1/2,并且将n代入式1.6中:

实际上这个 c(u) 如果在函数计算中,加不加都无所谓,实际上在DFT变换中,这个值也是存在的因为常常取1,因此没有再进一步写出来,实际上,这个值因为一些工程学上的意义,DFT中也常常会取1/N或sqrt(1/N)
DCT中它的出现,主要是为了在DCT变换变成矩阵运算的形式时,将该矩阵正交化以便于进一步的计算,那么,这个系数就应该取sqrt(1/2N)
将这个系数乘到式1.7中

DCT从DFT转化成功!
那么DCT变换到底哪好用了呢,首先,DCT变换较DFT变换具有更好的频域能量聚集度(说人话就是能够把图像更重要的信息聚集在一块),那么对于那些不重要的频域区域和系数就能够直接裁剪掉(有点像淘金,你把石头里重要的金子都弄到一块,剩下没啥用的石子不就可以扔了么),因此,DCT变换非常适合于图像压缩算法的处理,例如现在大名鼎鼎的jpeg就是使用了DCT作为图像压缩算法。
references
量化:https://blog.csdn.net/m0_60217700/article/details/128778991
CABAC:https://www.cnblogs.com/SoaringLee/p/10532499.html;https://blog.csdn.net/hdove/article/details/107978333
DCT:https://zhuanlan.zhihu.com/p/85299446?from=timeline
