数据分析初识、Anaconda安装、Juypyter notebook配置与快捷键
一、数据分析介绍
- 数据分析是什么?
- 数据分析能干什么?
- 为什么利用Python进行数据分析?
- 数据分析过程概述
- 常用库简介
1.1数据分析是什么
在我们如今这个时代,相信大多数人都能明白数据的重要性,数据就是信息,而数据分析就是可以让我们发挥这些信息功能的重要手段。
1.2数据分析能干什么
对于数据分析能干什么其实我们可以简单的举几个例子:
1、淘宝可以观察用户的购买记录、搜索记录以及人们在社交媒体上发布的内容选择商品推荐
2、股票可以根据相应的数据选择买进卖出
3、今日头条可以将数据分析应用到新闻推送排行算法当中
4、爱奇艺可以为用户提供个性化电影推荐服务
其实数据分析不仅可以完成像以上这样的推荐系统,在制药行业也可运用数据分析来预测什么样的化合物更有可能制成高效药物等
所以说数据分析绝对是未来所有公司不可或缺的岗位,目前社会上获取数据方式太多了,这么多的数据,只要我们拥有数据分析的技能,绝对可以应付任何岗位上的工作。
1.3为什么利用Python进行数据分析
- 1、Python的代码语法简单易学
- 2、Python可以很容易的整合C、C++等语言的代码
- 3、Python有大量用于科学计算的库
- 4、Python不仅可以用于研究和原型构建,同时也适用于构建生产系统
1.4数据分析过程概述
1.4.1提出问题
在真正的工作场景下,往往我们需要的处理的是多个庞大的数据集还有可能是类型完全不同的数据,那这个时候一个准确的问题就可以让我们聚集与问题相关的那部分数据,为后续的分析操作提供一个明确的方向,帮助我们得到一个有意义的结论。
1.4.2整理数据
整理数据主要分为三步:
(1)、收集数据
通过多种途径拿到数据,导入到Jupyter Notebook中
(2)、评估数据
这一步主要是需要找出数据是否存在质量或者结构等方面的问题
(3)、清理数据
通过修改、替换、删除等方式保证数据质量高、结构好
1.4.3探索性数据分析
在这一步骤主要可以探索并且扩充数据
1.4.4得出结论
在进行完探索性数据分析之后肯定会得出一个结果或者说是结论,这样我们就可以根据这样一个结论进行相应的操作,就比如说分析股票数据得到那个大盘趋势好可以选择买进,又或者说类似于万达这样的大型商场可以分析那种类型的商品会比较受用户的欢迎,以便针对性的存货。但是具体的操作可能就需要用到机器学习或者推断统计学来实现,这个就与数据分析不一样了
1.4.5传达结果
分析的能力有多强,分析的价值就有多大。
这一步主要是向其他人证明你发现的见解以及传达意义
1.5常用库简介
Numpy
Numpy是Numerical Python的简写,主要可以用来做Python数值计算。它提供了多种数据结构、算法以及大部分涉及Python数值计算所需的接口。
- 快速、高效的多维数组对象ndarray
- 基于元素的数组计算以及直接对数组执行数学运算的函数
- 用于读写硬盘上基于数组的数据集的工具
- 线性代数运算、傅里叶变换,以及随机数生成
- 用于将C、C++、Fortran代码集成到python的工具
Pandas
Pandas使我们进行数据分析的一个主要工具。它所包含的数据结构和数据处理工具的设计使得Python中进行数据清洗和分析非常快捷。pandas一般也是和其他数值计算工具一起使用的,支持大部分Numpy语言风格的数组计算。pandas和numpy最大的区别就是pandas是用来处理表格型或者异质性数据的,而Numpy则刚好相反,它更适合处理同质型的数值类数组数据
matplotlib
matplotlib是最流行的用于绘制数据图表的python库。
Scipy
Scipy是科学计算领域针对不同标准问题域的包集合。提供了强大的科学计算方法(矩阵分析、信号分析、数理分析等)
IPython和Juypyter notebook
IPython是一个加强版的Python解释器,Juypyter notebook是一种基于Web的代码笔记本,最初也是源于IPython项目。
二、开发环境部署
- Anaconda
- 下载安装
- 配置环境变量
- 管理包
- 管理环境
- 运行anaconda
- 补充
2.1Anaconda
Anaconda是Python的一个开源的发行版本,里面包含了很多科学计算相关的包,它和Python的关系就像linux系统中centos和Ubuntu的关系一样,不冲突,你可以同时在电脑上安装这两个东西。那至于为什么我已经在电脑上安装了pycharm还要安装这个Anaconda呢,主要有以下几点原因:
(1)Anaconda附带了一大批常用数据科学包,它附带了conda、Python和 150 多个科学包及其依赖项。因此你可以用Anaconda立即开始处理数据。
(2)管理包。Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的。在数据分析中,你会用到很多第三方的包,而conda(包管理器)可以很好的帮助你在计算机上安装和管理这些包,包括安装、卸载和更新包。
(3)管理环境。为什么需要管理环境呢?比如你在A项目中用到了Python2,而新的项目要求使用Python3,而同时安装两个Python版本可能会造成许多混乱和错误。这时候conda就可以帮助你为不同的项目建立不同的运行环境。还有很多项目使用的包版本不同,比如不同的pandas版本,不可能同时安装两个pandas版本。你要做的应该是在项目对应的环境中创建对应的pandas版本。这时候conda就可以帮你做到。
总结:Anaconda解决了官方Python的两大痛点:
(1)提供了包管理功能,Windows平台安装第三方包经常失败的场景得以解决
(2)提供环境管理功能,解决了多版本Python并存、切换的问题。
接下来就需要了解Anaconda如何进行安装
2.2下载
Anaconda下载入口
按照上面的路径点击下载,下载完成后就可以一路点击下一步完成安装,如果中间需要修改安装路径可以自己改一下(不需要选择添加环境变量)。安装成功之后我们会发现,多出来几个应用
- Anaconda Navigtor :用于管理工具包和环境的图形用户界面,后续涉及的众多管理命令也可以在 Navigator 中手工实现。
- Jupyter notebook :基于web的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程。
- qtconsole :一个可执行 IPython 的仿终端图形界面程序,相比 Python Shell 界面,qtconsole 可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。
- spyder :一个使用Python语言、跨平台的、科学运算集成开发环境。
那以上应用我们简单了解一下就好,不需要管。
2.3配置环境变量
说明:如果安装anaconda,不需要配置环境变量,该软件可通过桌面图标启动
2.3.1windows 系统
如果是Windows环境的话就需要在控制面板\系统和安全\系统\高级系统设置\环境变量\用户变量\PATH当中添加anaconda的安装目录的Scripts文件夹。
验证:
打开CMD输入conda --version,如果能输出版本号就对了
3.2.2Mac系统
在终端输入以下命令
export PATH=~/anaconda/bin:$PATH
2.4管理包
在anaconda当中虽然已经存在了很多科学计算的包,但是我们总有需要安装新的包的需求,有了anaconda就可以很好地管理这些包了
# 管理包在Python解释器中有pip,在anaconda中conda,它的功能和pip是一样的,在anaconda中选择pip也是可以安装包的
1、安装包
conda install requests
2、卸载包
conda remove requests
3、更新包
conda update requests
4、查询已安装的包
conda list
2.5管理环境
可以通过conda创建不同的运行环境
2.5.1创建环境
conda create -n program_test pandas
上面这条指令中的program_test是新创建的环境名称,pandas是指需要安装到环境中的包名称。
当然在安装的时候还可以指定解释器的版本
conda create -n python36 python=3.6 # 创建解释器版本为3.6的环境
conda create -n python27 python=2.7 # 创建解释器版本为2.7的环境
2.5.2进入环境
conda activate program_test
2.5.3退出环境
deactive
2.6运行Anaconda
打开安装的Anaconda文件

点击Anaconda Navigator运行

选择图中圈起来的按钮,会弹出来四个选择,选择最后一个Jupyter Notebook就可以打开代码编辑工具,如果没有打开,请先按照第七步进行配置。
新建文件或文件夹:

以上就是我们本机的根目录,就类似于windows系统的User目录,接下来就可以点击右上角的New按钮选择创建一个Python3文件,这个文件的后缀名是.ipynd.

接下来我们所有的程序都要在这个上面进行编写:

2.7Jupyter notebook配置
配置Jupyter notebook默认打开的浏览器
当我们想通过jupyter notebook编辑器来编写代码的时候,有的时候会发现他默认会打开你的IE浏览器,但是平时我们都是使用chrome浏览器的,接下来就一起来看看怎么修改这个东西
第一步:打开Cmd页面输入activate进入anaconda prompt(在配置好环境变量的情况下,如果没有配置好环境变量就先cd到软件安装文件的Scripts文件夹,或者直接点击anaconda prompt图标进入anaconda prompt环境)
第二步:输入
jupyter notebook --generate-config,查看你配置文件的位置
第三步:通过记事本打开配置文件找到
#c.NotebookApp.browser = ''设置
第四步:在它的下面加上一段代码
import webbrowser
webbrowser.register("chrome",None,webbrowser.GenericBrowser(u"C:\\Users\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe"))
c.NotebookApp.browser = 'chrome'
将其中的路径改为你电脑上chrome启动文件的路径,一定要注意路径中的文件名使用双斜杠分隔的。
如果需要配置jupyter notebook的文件保存路径就找到配置文件的“c.NotebookApp.notebook_dir=……”,把路径改成自己的工作目录。
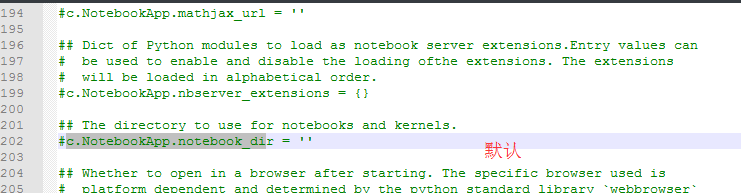
比如,这里要变更为下面内容当然,文件夹 jupyter-notebook 需要自己创建好。
## The directory to use for notebooks and kernels.
c.NotebookApp.notebook_dir = 'D:\jupyter-notebook'
因为大部分数据分析的工作都是需要一步一步做的,不是像我们做Web,搭网站,做后台那样需要大量的代码铺垫。所以说更专业的数据分析操作都是在这个Jupyter Notebook当中完成的。
三、Jupyter Notebook常用快捷键
3.1模式切换
- 当前cell侧边为蓝色时,表示此时为命令模式,按Enter切换为编辑模式
- 当前cell侧边为绿色时,表示此时为编辑模式,按Esc切换为命令模式
3.2命令模式快捷键
- H:显示快捷键帮助
- F:查找和替换
- P:打开命令面板
- Ctrl-Enter:运行当前cell
- Shift-Enter:运行当前cell并跳转到下一cell
- Alt-Enter:运行当前cell并在下方新建cell
- Y:把当前cell内容转换为代码形式
- M:把当前cell内容转换为markdown形式
- **16**:把当前cell内容设置为标题16格式
- Shift+上下键:按住Shift进行上下键操作可复选多个cell
- A:在上方新建cell
- B:在下方新建cell
- X/C/Shift-V/V:剪切/复制/上方粘贴/下方粘贴
- 双击D:删除当前cell
- Z:撤销删除
- S:保存notebook
- L:为当前cell的代码添加行编号
- Shift-L:为所有cell的代码添加行编号
- Shift-M:合并所选cell或合并当前cell和下方的cell
- 双击I:停止kernel
- 双击0:重启kernel
3.3编辑模式快捷键
- Tab:代码补全
- Ctrl-A:全选
- Ctrl-Z:撤销
- Ctrl-Home:将光标移至cell最前端
- Ctrl-End:将光标移至cell末端
3.4.Jupyter Notebook中Matplotlib绘图
若要使用Matplotlib绘图,为确保图形能顺利输出,需在cell开头键入
%matplotlib inline

 浙公网安备 33010602011771号
浙公网安备 33010602011771号