MySQL数据库3分组与单表、多表查询
浮华褪尽,人比烟花寂寞…… ——张爱玲
一、表操作的补充
select * from 表名 where 列名 in (值1,值2,。。。);
查出对应值的数据。
1.1null 和 not null
使用null的时候:
当创建的表中有null时我们如果需要查询出来null所对应的信息,需要用select * from 表名 where 字段名 is null;
mysql> create table v1(id int auto_increment primary key,
-> name varchar(32),email varchar(32))charset=utf8;
Query OK, 0 rows affected (0.70 sec)
mysql> insert into v1(email) values('xxx');
Query OK, 1 row affected (0.07 sec)
mysql> select * from v1;
+----+------+-------+
| id | name | email |
+----+------+-------+
| 1 | NULL | xxx |
+----+------+-------+
1 row in set (0.00 sec)
mysql> select * from v1 where name is null;
+----+------+-------+
| id | name | email |
+----+------+-------+
| 1 | NULL | xxx |
+----+------+-------+
1 row in set (0.01 sec)
mysql> select *from v1 where name='';
Empty set (0.00 sec)
使用null会降低数据的查询效率,不推荐使用,在创建表的时候建议把值默认为空。
1.2使用not null的时候
mysql> create table v2(id int auto_increment primary key,
-> name varchar(32) not null default '',email varchar(32)not null default '')charset=utf8;
Query OK, 0 rows affected (0.44 sec)
mysql> insert into v2(email) values('xxx');
Query OK, 1 row affected (0.06 sec)
mysql> select *from v2 where name='';
+----+------+-------+
| id | name | email |
+----+------+-------+
| 1 | | xxx |
+----+------+-------+
1 row in set (0.00 sec)
二、单表的操作(import)
2.1分组
分组:将所标记的某个相同字段进行归类,比如员工信息表的职位分组,或者按照性别进行分组等。
2.1.1聚合函数
max(列)求出列中的最大值
min(列)求出列中的最小值
sum(列)对列中的数据求和
count(列)对列中的数据计数
avg(列)对列中的数据计算平均数
例子见group by
2.1.2group by
用法:
select 聚合函数, 选取的字段 from employee group by 分组的字段;
group by 是分组的关键词,group by 必须和聚合函数(count)一块出现。count(字段名),按照条件对字段中的数据进行计数。
例子:
1.以性别为例, 进行分组, 统计一下男生和女生的人数是多少个。
mysql> create table employee(
-> id int not null unique auto_increment primary key,
-> name varchar(20) not null,
-> gender enum('male','female') not null default 'male',
-> age int(3) unsigned not null default 28,
-> hire_date date not null,
-> post varchar(50),
-> post_comment varchar(100),
-> salary double(15,2),
-> office int,
-> depart_id int
-> )charset=utf8;
Query OK, 0 rows affected (0.61 sec)
mysql> insert into employee(name,gender,age,hire_date,post,salary,office,depart_id) values
-> ('小张','male',73,'20140701','研发部',3500,401,1),
-> ('小李','male',28,'20121101','研发部',2100,401,1),
-> ('小赵','female',18,'20150411','研发部',18000,403,3),
-> ('歪歪','female',48,'20150311','销售部',3000.13,402,2),
-> ('丫丫','female',38,'20101101','销售部',2000.35,402,2),
-> ('丁丁','female',18,'20110312','销售部',1000.37,402,2),
-> ('小明','male',28,'20160311','运营部',10000.13,403,3),
-> ('小华','male',18,'19970312','运营部',20000,403,3),
-> ('小王','female',18,'20130311','运营部',19000,403,3);
Query OK, 9 rows affected (0.09 sec)
Records: 9 Duplicates: 0 Warnings: 0
mysql> select count(id),gender from employee group by gender;
+-----------+--------+
| count(id) | gender |
+-----------+--------+
| 4 | male |
| 5 | female |
+-----------+--------+
2 rows in set (0.10 sec)
mysql> select gender,count(id) as total from employee group by gender;
#这里可以用as重命名显示的列名
+--------+-------+
| gender | total |
+--------+-------+
| male | 4 |
| female | 5 |
+--------+-------+
2 rows in set (0.00 sec)
2.对部门进行分组, 求出每个部门年龄最大的那个人。
mysql> select depart_id , max(age) from employee group by depart_id;
+-----------+----------+
| depart_id | max(age) |
+-----------+----------+
| 1 | 73 |
| 2 | 48 |
| 3 | 28 |
+-----------+----------+
3 rows in set (0.04 sec)
3.对部门进行分组, 求出每个部门年龄求和。
mysql> select depart_id,sum(age) from employee group by depart_id;
+-----------+----------+
| depart_id | sum(age) |
+-----------+----------+
| 1 | 101 |
| 2 | 104 |
| 3 | 82 |
+-----------+----------+
3 rows in set (0.00 sec)
4.对部门进行分组, 求出每个部门年龄求平均数。
mysql> select depart_id,avg(age) from employee group by depart_id;
+-----------+----------+
| depart_id | avg(age) |
+-----------+----------+
| 1 | 50.5000 |
| 2 | 34.6667 |
| 3 | 20.5000 |
+-----------+----------+
3 rows in set (0.02 sec)
2.1.3having
对group by 之后的数据进行二次筛选
例子
5.对部门进行分组, 求出每个部门年龄求平均数,选出平均数最大的部门。
mysql> select depart_id,avg(age) from employee group by depart_id having avg(age)>35;
+-----------+----------+
| depart_id | avg(age) |
+-----------+----------+
| 1 | 50.5000 |
+-----------+----------+
1 row in set (0.00 sec)
mysql> select depart_id,avg(age)as pj from employee group by depart_id having pj>35;
+-----------+---------+
| depart_id | pj |
+-----------+---------+
| 1 | 50.5000 |
+-----------+---------+
1 row in set (0.00 sec)
2.1.4升序和降序
order by 字段名 asc(升序)desc(降序)
升序和降序可以同时使用如age desc, id asc;
表示: 先对age进行降序, 如果age有相同的行, 则对id进行升序。
例子
mysql> select * from employee order by age desc,id desc;
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | name | gender | age | hire_date | post | post_comment | salary | office | depart_id |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 1 | 小张 | male | 73 | 2014-07-01 | 研发部 | NULL | 3500.00 | 401 | 1 |
| 4 | 歪歪 | female | 48 | 2015-03-11 | 销售部 | NULL | 3000.13 | 402 | 2 |
| 5 | 丫丫 | female | 38 | 2010-11-01 | 销售部 | NULL | 2000.35 | 402 | 2 |
| 7 | 小明 | male | 28 | 2016-03-11 | 运营部 | NULL | 10000.13 | 403 | 3 |
| 2 | 小李 | male | 28 | 2012-11-01 | 研发部 | NULL | 2100.00 | 401 | 1 |
| 9 | 小王 | female | 18 | 2013-03-11 | 运营部 | NULL | 19000.00 | 403 | 3 |
| 8 | 小华 | male | 18 | 1997-03-12 | 运营部 | NULL | 20000.00 | 403 | 3 |
| 6 | 丁丁 | female | 18 | 2011-03-12 | 销售部 | NULL | 1000.37 | 402 | 2 |
| 3 | 小赵 | female | 18 | 2015-04-11 | 研发部 | NULL | 18000.00 | 403 | 3 |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
9 rows in set (0.00 sec)
2.1.5limit限制输出
limit offset ,size
limit 起始行索引,向下查询的长度(索引为0代表第一行)
例子
mysql> select * from employee limit 0,3;
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | name | gender | age | hire_date | post | post_comment | salary | office | depart_id |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 1 | 小张 | male | 73 | 2014-07-01 | 研发部 | NULL | 3500.00 | 401 | 1 |
| 2 | 小李 | male | 28 | 2012-11-01 | 研发部 | NULL | 2100.00 | 401 | 1 |
| 3 | 小赵 | female | 18 | 2015-04-11 | 研发部 | NULL | 18000.00 | 403 | 3 |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
3 rows in set (0.00 sec)
2.1.6查询表示需要遵循的顺序(important)
select * from 表名 where 条件 group by 条件 having 条件 order by 条件 limit 条件;
where > group by > having > order by > limit
三、多表操作
外键
主关键字(primary key)是表中的一个或多个字段,它的值用于唯一地标识表中的某一条记录。
公共关键字(Common Key)在关系数据库中,关系之间的联系是通过相容或相同的属性或属性组来表示的。如果两个关系中具有相容或相同的属性或属性组,那么这个属性或属性组被称为这两个关系的公共关键字。
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。外键又称作外关键字。
使用外键的原因:
1.减少占用的内存空间
2.只需要修改主表的数据,从表的数据也会相应的跟着修改
3.1一对多
一对多指一个主表中的数据和从表中的数据是一对多的关系,如下例,一个部门可以有多个员工。
使用方法:
constraint 外键名 foreign key (被约束的字段) references 约束的表(约束的字段)
mysql> create table department(
-> id int auto_increment primary key,
-> name varchar(32) not null default '')
-> charset utf8;
Query OK, 0 rows affected (0.42 sec)
mysql> insert into department(name) values('研发部'),('运维部'),('前台部'),('小卖部');
Query OK, 4 rows affected (0.06 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> create table userinfo(id int auto_increment primary key,
-> name varchar(32) not null default '',
-> depart_id int not null default 1,
-> constraint fk_user_depart foreign key (depart_id) references department(id))
-> charset utf8;
Query OK, 0 rows affected (0.39 sec)
mysql> insert into userinfo (name,depart_id) values('xiaozhu',1),('xiaoyu',1),
-> ('laohe',2),('longge',2),('ludi',3),('xiaoguo',4);
Query OK, 6 rows affected (0.21 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from userinfo;
+----+---------+-----------+
| id | name | depart_id |
+----+---------+-----------+
| 1 | xiaozhu | 1 |
| 2 | xiaoyu | 1 |
| 3 | laohe | 2 |
| 4 | longge | 2 |
| 5 | ludi | 3 |
| 6 | xiaoguo | 4 |
+----+---------+-----------+
6 rows in set (0.00 sec)
mysql> select * from department;
+----+-----------+
| id | name |
+----+-----------+
| 1 | 研发部 |
| 2 | 运维部 |
| 3 | 前台部 |
| 4 | 小卖部 |
+----+-----------+
4 rows in set (0.00 sec)
mysql> insert into userinfo(name,depart_id) values('xiaozhang',5);#depart_id受department.id的约束
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`test2`.`userinfo`, CONSTRAINT `fk_user_depart` FOREIGN KEY (`depart_id`) REFERENCES `department` (`id`))
#联表查询
mysql> select userinfo.name as uname,department.name as dname from userinfo left
-> join department on depart_id = department.id;
+---------+-----------+
| uname | dname |
+---------+-----------+
| xiaozhu | 研发部 |
| xiaoyu | 研发部 |
| laohe | 运维部 |
| longge | 运维部 |
| ludi | 前台部 |
| xiaoguo | 小卖部 |
+---------+-----------+
6 rows in set (0.00 sec)
3.2多对多
多对多指当一个主表有多个从表时,从表之间的每个数据之间的关系就是多对多,如下图,一个boy可以和多个girl约会,一个girl也可以和多个boy约会。
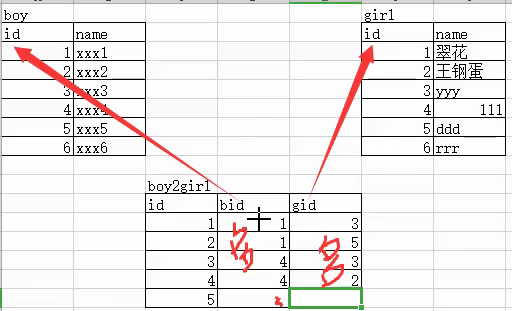
mysql> create table boy(id int auto_increment primary key,
-> bname varchar(32) not null default'')charset utf8;
Query OK, 0 rows affected (0.36 sec)
mysql> insert into boy(bname) values('zhangsan'),('lisi'),('wangwu');
Query OK, 3 rows affected (0.09 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> create table girl(id int auto_increment primary key,
-> gname varchar(32) not null default'')charset utf8;
Query OK, 0 rows affected (0.33 sec)
mysql> insert into girl(gname) values('xiaoli'),('xiaohua'),('xiaomei');
Query OK, 3 rows affected (0.06 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> create table boy_girl(id int auto_increment primary key,
-> bid int not null default 1,
-> gid int not null default 1,
-> constraint fk_boy_girl_boy foreign key(bid) references boy(id),
-> constraint fk_boy_girl_girl foreign key(gid) references girl(id)
-> )charset utf8;
Query OK, 0 rows affected (0.42 sec)
mysql> insert into boy_girl(bid,gid) values(1,1),(2,2),(3,3),(3,1),(2,1),(1,2);
Query OK, 6 rows affected (0.04 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from boy left join boy_girl on boy.id = boy_girl.bid left join girl
-> on girl.id = boy_girl.gid;
+----+----------+------+------+------+------+---------+
| id | bname | id | bid | gid | id | gname |
+----+----------+------+------+------+------+---------+
| 1 | zhangsan | 1 | 1 | 1 | 1 | xiaoli |
| 2 | lisi | 5 | 2 | 1 | 1 | xiaoli |
| 3 | wangwu | 4 | 3 | 1 | 1 | xiaoli |
| 1 | zhangsan | 6 | 1 | 2 | 2 | xiaohua |
| 2 | lisi | 2 | 2 | 2 | 2 | xiaohua |
| 3 | wangwu | 3 | 3 | 3 | 3 | xiaomei |
+----+----------+------+------+------+------+---------+
6 rows in set (0.03 sec)
mysql> select bname,gname from boy left join boy_girl on boy.id = boy_girl.bid
-> left join girl on girl.id = boy_girl.gid;
+----------+---------+
| bname | gname |
+----------+---------+
| zhangsan | xiaoli |
| lisi | xiaoli |
| wangwu | xiaoli |
| zhangsan | xiaohua |
| lisi | xiaohua |
| wangwu | xiaomei |
+----------+---------+
6 rows in set (0.00 sec)
3.3一对一
一对一指的是两个表中的数据是一对一的关系,使用unique(字段名)来约束这种关系。如下例,由于工资属于员工的敏感信息,用单独的表去存储,这时工资和员工信息就是一对一的关系。
mysql> create table priv(
-> id int auto_increment primary key,
-> salary int not null default 0,
-> uid int not null default 1,
-> constraint fk_priv_user foreign key (uid) references userinfo(id),
-> unique(uid)) charset=utf8;
Query OK, 0 rows affected (0.52 sec)
mysql> insert into priv(salary,uid) values (10000,1),(12000,2),(15000,3),(8000,4),(9000,5),(9900,6);
Query OK, 6 rows affected (0.16 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select name,salary from userinfo left join priv on priv.uid = userinfo.id;
+---------+--------+
| name | salary |
+---------+--------+
| xiaozhu | 10000 |
| xiaoyu | 12000 |
| laohe | 15000 |
| longge | 8000 |
| ludi | 9000 |
| xiaoguo | 9900 |
+---------+--------+
6 rows in set (0.00 sec)
3.4多表联查
多表联查就是将多个有关系的表放在一起查,使用的语句有:
left join……on查询时以左边的数据为主
right join ……on查询时以右边的数据为主
mysql> insert into department(name) values('业务部');
Query OK, 1 row affected (0.12 sec)
mysql> select userinfo.name as uname,department.name as dname from userinfo left
-> join department on depart_id = department.id;
+---------+-----------+
| uname | dname |
+---------+-----------+
| xiaozhu | 研发部 |
| xiaoyu | 研发部 |
| laohe | 运维部 |
| longge | 运维部 |
| ludi | 前台部 |
| xiaoguo | 小卖部 |
+---------+-----------+
6 rows in set (0.00 sec)
mysql> select userinfo.name as uname,department.name as dname from userinfo right
-> join department on depart_id = department.id;
+---------+-----------+
| uname | dname |
+---------+-----------+
| xiaozhu | 研发部 |
| xiaoyu | 研发部 |
| laohe | 运维部 |
| longge | 运维部 |
| ludi | 前台部 |
| xiaoguo | 小卖部 |
| NULL | 业务部 |
+---------+-----------+
7 rows in set (0.00 sec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号