
直接起飞。
什么是JMM内存模型?
这并不是一个实际存在的东西,并不是一个实际存在的东西,并不是一个实际存在的东西;重要的事情说3遍,只是一种抽象概念。个人理解,JMM内存模型描述的是java线程和硬件通信的一个过程。
标准解释:
Java内存模型(Java Memory Model简称JMM)是一种抽象的概念,并不真实存在,它 描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段 和构成数组对象的元素)的访问方式。JVM运行程序的实体是线程,而每个线程创建时 JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线程私有的数据,而Java 内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问, 但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自 己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作 主内存中的变量,工作内存中存储着主内存中的变量副本拷贝,前面说过,工作内存是每个 线程的私有数据区域,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必 须通过主内存来完成。
图解JMM内存模型

主内存:
主要存储的是Java实例对象,所有线程创建的实例对象都存放在主内存中,不管该实例 对象是成员变量还是方法中的本地变量(也称局部变量),当然也包括了共享的类信息、常 量、静态变量。由于是共享数据区域,多条线程对同一个变量进行访问可能会发生线程安全 问题。(不要理解成是JVM的堆内存或者原空间,这是两个不同概念)
工作内存:
主要存储当前方法的所有本地变量信息(工作内存中存储着主内存中的变量副本拷贝), 每个线程只能访问自己的工作内存,即线程中的本地变量对其它线程是不可见的,就算是两 个线程执行的是同一段代码,它们也会各自在自己的工作内存中创建属于当前线程的本地变 量,当然也包括了字节码行号指示器、相关Native方法的信息。注意由于工作内存是每个线程的私有数据,线程间无法相互访问工作内存,因此存储在工作内存的数据不存在线程安全问题。(不要理解成栈帧,JMM内存模型和JVM内存模型是两码事)
JMM内存模型和JVM内存模型的区别?
JMM与JVM内存区域的划分是不同的概念层次,更恰当说JMM描述的是一组规则,通 过这组规则控制程序中各个变量在共享数据区域和私有数据区域的访问方式,JMM是围绕 原子性,有序性,可见性展开。JMM与Java内存区域唯一相似点,都存在共享数据区域和 私有数据区域,在JMM中主内存属于共享数据区域,从某个程度上讲应该包括了堆和方法 区,而工作内存数据线程私有数据区域,从某个程度上讲则应该包括程序计数器、虚拟机栈 以及本地方法栈。
根据JVM虚拟机规范主内存与工作内存的数据存储类型以及操作方式,对于一个实例对 象中的成员方法而言,如果方法中包含本地变量是基本数据类型 (boolean,byte,short,char,int,long,float,double),将直接存储在工作内存的帧栈结构 中,但倘若本地变量是引用类型,那么该变量的引用会存储在功能内存的帧栈中,而对象实 例将存储在主内存(共享数据区域,堆)中。但对于实例对象的成员变量,不管它是基本数据 类型或者包装类型(Integer、Double等)还是引用类型,都会被存储到堆区。至于static变 量以及类本身相关信息将会存储在主内存中。需要注意的是,在主内存中的实例对象可以被 多线程共享,倘若两个线程同时调用了同一个对象的同一个方法,那么两条线程会将要操作 的数据拷贝一份到自己的工作内存中,执行完成操作后才刷新到主内存。
如果硬要说JMM内存模型和JVM内存模型关系,那就是下图所示:

方法栈帧上的临界资源会到主内存中。
JMM内存模型和硬件内存架构关系?
通过上一篇博客硬件的认知、Java内存模型以及Java多线程的实现原理的了解,我们应该已经意识到,多线程的执行最终都会映射到硬件处理器上进行执行,但Java内存模型和硬 件内存架构并不完全一致。对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没 有工作内存(线程私有数据区域)和主内存(堆内存)之分,也就是说Java内存模型对内存的划分对硬件内存并没有任何影响,因为JMM只是一种抽象的概念,是一组规则,并不实际存在,不管是工作内存的数据还是主内存的数据,对于计算机硬件来说都会存储在计算机主内存中,当然也有可能存储到CPU缓存或者寄存器中,因此总体上来说,Java内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真实物理硬件的交叉。(注意对于Java内存区域划分也是同样的道理)
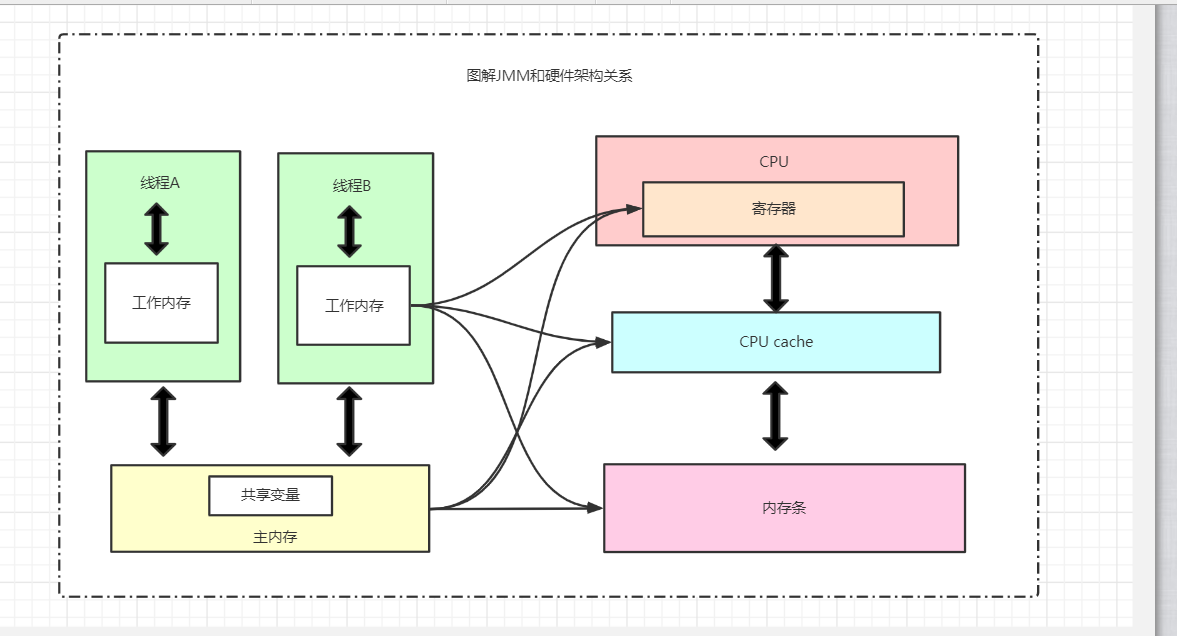
为什么要存在JMM这抽象概念?
由于JVM运行程序的实体是线 程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线 程私有的数据,线程与主内存中的变量操作必须通过工作内存间接完成,主要过程是将变量 从主内存拷贝的每个线程各自的工作内存空间,然后对变量进行操作,操作完成后再将变量 写回主内存,如果存在两个线程同时对一个主内存中的实例对象的变量进行操作就有可能诱 发线程安全问题。
JMM模型可以很清晰的描述多线程带来问题,并且与程序和硬件有很好的契合解释。
数据同步八大原子操作
(1)lock(锁定):作用于主内存的变量,把一个变量标记为一条线程独占状态
(2)unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后 的变量才可以被其他线程锁定
(3)read(读取):作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存 中,以便随后的load动作使用
(4)load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工 作内存的变量副本中
(5)use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎
(6)assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内 存的变量
(7)store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存 中,以便随后的write的操作
(8)write(写入):作用于工作内存的变量,它把store操作从工作内存中的一个变量的值 传送到主内存的变量中
如果要把一个变量从主内存中复制到工作内存中,就需要按顺序地执行read和load操 作,如果把变量从工作内存中同步到主内存中,就需要按顺序地执行store和write操作。但 Java内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。
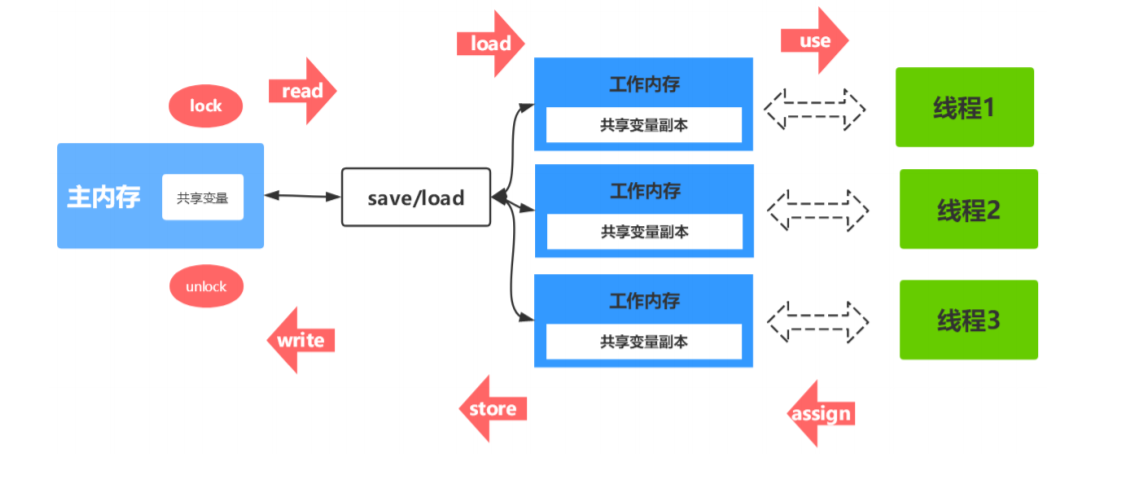
共享变量(临界资源)的同步分析:
1)不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内 存中
2)一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化 (load或者assign)的变量。即就是对一个变量实施use和store操作之前,必须先自行 assign和load操作。
3)一个变量在同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一线程重 复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。lock和unlock必须成对现。
4)如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个 变量之前需要重新执行load或assign操作初始化变量的值。
5)如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去 unlock一个被其他线程锁定的变量。
6)对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write 操作)
学习一时爽,一直学习一直爽。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号