


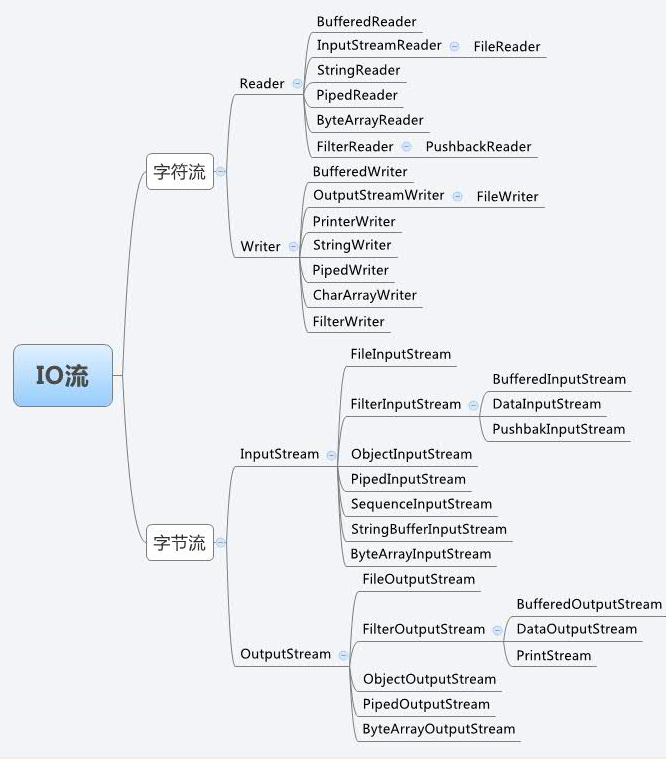
IO流
输入输出流(I/O)
通过数据流、序列化和文件系统提供输入和输出。输入和输出是相对于内存而言,将文件中的数据读取到内存中即为输入;将数据保存到文件中即为输出。
Java流操作有关的类或接口
|
File |
文件类 |
|
RandomAccessFile |
随机存取文件类 |
|
InputStream |
字节输入流 |
|
OutputStream |
字节输出流 |
|
Reader |
字符输入流 |
|
Writer |
字符输出流 |
Java流类图结构
File类
java.io.File
文件和目录路径名的抽象表示形式。
File类是IO包中唯一代表磁盘文件本身的对象。通过File类创建,删除,重命名文件。File类对象的主要作用就是用来获取文本本身的一些信息。如文本的所在的目录,文件的长度,读写权限等等。
路径字符串与抽象路径名之间的转换与系统有关。默认名称分隔符有系统属性File.separator定义。
构造方法
File(File parent, String child)
根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。
File(String pathname)
通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。
File(String parent, String child)
根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。
方法
public boolean createNewFile(); //创建文件,如果存在这样的文件,就不创建了。
public boolean mkdir(); //创建文件夹,如果存在这样的,就不创建了。
public boolean delete(); //删除文件或者文件夹
public boolean isDirectory(); //判断是否是目录
public boolean isFile(); //判断是否是文件
public boolean exists(); //判断是否存在
public String[] list(); //获取指定目录下的所有文件或者文件夹的名称数组
public File[] listFiles(); //获取指定目标下的所有文件或者文件夹的File数组
程序示例:将一句话存入G盘的File文件夹中的Test.txt文件内
public static void main(String[] args) throws Exception{
String str = "这是一句话";
String url = "G:"+File.separator+"File";
File f1 = new File(url);
//判断是否为目录,若不是则创建
if (!f1.isDirectory()) {
f1.mkdir();
}
File f2 = new File(url+File.separator+"Test.txt");
//判断是否存在此文件,若不存在则创建
if (!f2.exists()) {
f2.createNewFile();
}
//获得文件的输出流,后面的true表示文件后面可以追加
FileOutputStream out = new FileOutputStream(f2,true);
byte[] bs = str.getBytes();
out.write(bs);
out.close();
}
字节流FileInputStream和FileOutputStream
read()方法
int read();
从此输入流总读取下一个数据字节,返回一个0到255范围内的int字节值。如果到达末尾没有字节可读,则返回-1.
文件复制
public class Copy {
public static void main(String[] args) throws IOException {
File f = new File("G:"+File.separator+"File"+File.separator+"Test.txt");
File f2 = new File("G:"+File.separator+"File"+File.separator+"复制.txt");
FileInputStream input = new FileInputStream(f);
FileOutputStream output = new FileOutputStream(f2);
int b;
while ((b = input.read()) != -1){
output.write(b);
}
input.close();
output.close();
System.out.println("复制完成");
}
}
高速缓冲流(BufferedInputStream和BufferedOutputStream)
BufferedInputStream中内置了一个缓冲区(数组),从BufferedInputStream中读取一个字节时,BufferedInputStream会一次性从文件中读取8192个,存在缓冲区中,返回给程序一个。程序再次读取时,就不用找文件了,直接从缓冲区中获取。直到缓冲区中所有的都被使用过,才重新从文件中读取8192个。
BufferedOutputStream也内置了一个缓冲区(数组),程序向流中写出字节时,不会直接写到文件,先写到缓冲区中,直到缓冲区写满,BufferedOutputStream才会把缓冲区中的数据一次性写到文件里。
public class Copy02 {
public static void main(String[] args) throws IOException {
File f = new File("G:"+File.separator+"File"+File.separator+"Test.txt");
File f2 = new File("G:"+File.separator+"File"+File.separator+"复制.txt");
BufferedInputStream br = new BufferedInputStream (new FileReader(f));
BufferedOutputStream bw = new BufferedOutputStream (new FileWriter(f2));
int i;
while ((i=br.read())!= -1) {
bw.write(i);
}
br.close();
bw.close();
System.out.println("复制完成");
}
}
字符流FileReader和FileWriter
字符流可以直接读写字符
字符流读取字符,就要先读取到字节数据,然后转为字符。如果要写出字符,需要把字符转为字节再写出。
字符流不能拷贝非纯文本的文件,因为在读的时候会将字节转为字符,在转换过程中,可能找不到对应的字符,就会用?替代,写出的时候会将字符转换成字节写出去,如果是?,直接写出文件后就会乱码。
字符流同样也有高速缓冲流BufferedReader和BufferedWriter。
public static void main(String[] args) throws IOException {
File f = new File("G:"+File.separator+"File"+File.separator+"Test.txt");
File f2 = new File("G:"+File.separator+"File"+File.separator+"复制.txt");
BufferedReader br = new BufferedReader(new FileReader(f));
BufferedWriter bw = new BufferedWriter(new FileWriter(f2));
int i;
while ((i=br.read())!= -1) {
bw.write(i);
}
br.close();
bw.close();
System.out.println("复制完成");
}
字节流和字符流的区别选择
Stream结尾的都是字节流,reader和writer结尾都是字符流两者的区别就是读写的时候,一个按字节读写,一个按字符,实际上使用差不多。
在读写文件需要对内容按行处理,比如比较特定的字符,处理某一行数据的时候一般会选择字符流。只是读写文件,和文件内容无关的,一般选择字节流。
字符流 = 字节流 + 编码集
对象序列化
在分布式环境下,当进行远程通信时,无论是何种类型的数据,都会以二进制序列的形式在网络上传送。序列化是一种将对象以一连串的字节描述的过程,用于解决在对对象流进行读写操作时所引发的问题。序列化可以将对象的状态卸载流里进行网络传输,或者保存到文件、数据库等系统里,并在需要时把该流读取出来重新构造一个相同的对象。
如何实现序列化
①所有实现序列化的类都必须实现Serializable接口,该接口位于java.lang包中,接口中并没有定义任何方法,所以此接口是一个标识接口,表示一个类具备了呗序列化的能力。
②使用一个输出流(例如FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着使用对象的writeObject(Object obj)方法就可以将obj对象写出(即保存其状态),要恢复时可以使用期对应的输入流。
序列化有以下两个特点:
①如果一个类能被序列化,那么他的子类也能够被序列化。
②由于static代表类的成员,transient(关键字,如果使用transient声明一个实例变量,当对象存储时,他的值不需要被维持。)代表对象的临时数据,因为被称声明为这两种类型的数据成员是不能够被序列化的。
Student.java
import java.io.Serializable;
public class Student implements Serializable{
private String name;
private Integer age;
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public Student() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
}
对象序列化
import java.io.File;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
/*
* 对象序列化
* */
public class TestStudent {
public static void main(String[] args) throws Exception {
//创建学生对象
Student stu = new Student("张三",22);
FileOutputStream fos = new FileOutputStream(new File("G:"+File.separator+"stu.txt"));
//使用FileOutputStream构造ObjectOutputStream对象
ObjectOutputStream oos = new ObjectOutputStream(fos);
//将stu对象写入到文件中
oos.writeObject(stu);
oos.close();
}
}
stu.txt文件中

反序列化
使用对象输入流读入对象的过程称为反序列化。
public class TestStudent02 {
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream(new File("G:"+File.separator+"stu.txt"));
ObjectInputStream ois = new ObjectInputStream(fis);
Object object = ois.readObject();
if (object instanceof Student ) {
Student s = (Student)object;
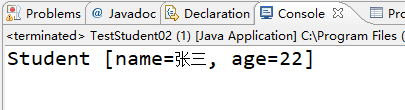
System.out.println(s);
}
ois.close();
fis.close();
}
}
控制台输出的结果为
由于序列化的使用会影响系统的性能,因此如果不是必须要使用系列化,应尽量不要使用。什么情况下需要使用?
①需要通过网络来发送对象,或对象的状态需要被持久化到数据库或文件中。
②序列化可以实现深复制,既可以复制引用的对象。
serialVersionUID
在序列化与反序列化的过程中,serialVersionUID起着非常重要的作用,每个类都有一个特定的serialVersionUID,在反序列化的过程中,通过serialVersionUID来判定类的兼容性。如果待序列化的对象与目标对象的serialVersionUID不同,那么在反序列化时会抛出InvalidClassException异常。作为一个好的编程习惯,最好的被序列化的类中显式的声明serialVersionUID(该字段必须定义为static final)。
自定义serialVersionUID主要有如下三个优点
①提供程序的运行效率。如在类中没有显式的定义serialVersionUID,那么在序列化时会通过计算得到一个serialVersionUID值,显式声明省去了计算过程,提高了效率。
②提高不同平台上的兼容性。由于各个平台的编译器在计算serialVersionUID时完全可能会采用不用的计算方式,导致在一个平台上序列化的对象在另一个平台上无法实现反序列化。
③增强程序各版本的可兼容性。在默认情况下,每个类都有一个唯一的serialVersionUID,因此,当后期对类进行修改时,类的serialVersionUID的值会发生变化,导致无法进行反序列化。
参考博客
[1] Java中IO流,输入输出流概述与总结
http://www.cnblogs.com/biehongli/p/6074713.html
[2] serialVersionUID作用
http://swiftlet.net/archives/1268

